
Home » Posts tagged 'IQ' (Page 4)
Tag Archives: IQ
IQ, Interoception, and the Heartbeat Counting Task: What Does It Mean?
1400 words
We’re only one month into the new year and I may have come across the most ridiculous paper I think I’ll read all year. The paper is titled Knowledge of resting heart rate mediates the relationship between intelligence and the heartbeat counting task. They state that ‘intelligence’ is related to heartbeat counting task (HCT), and that HBC is employed as a measure of interoception—which is a ‘sense’ that helps one understand what is going on in their body, sensing the body’s internal state and physiological changes (Craig, 2003; Garfinkel et al, 2015).
Though, the use of HCT as a measure of interoception is controversial (Phillips et al, 1999; Brener and Ring, 2016) mostly because it is influenced by prior knowledge of one’s resting heart rate. The concept of interoception has been around since 1906, with the term first appearing in scientific journals in the 1942 (Ceunen, Vlaeyen, and Dirst, 2016). It’s also interesting to note that interoceptive accuracy is altered in schizophrenics (who had an average IQ of 101.83; Ardizzi et al, 2016).
Murphy et al (2018) undertook two studies: study one demonstrated an association with ‘intelligence’ and HCT performance whereas study 2 demonstrated that this relationship is mediated by one’s knowledge of resting heart rate. I will briefly describe the two studies then I will discuss the flaws (and how stupid the idea is that ‘intelligence’ partly is responsible for this relationship).
In both studies, they measured IQ using the Wechsler intelligence scales, specifically the matrix and vocabulary subtests. In study 1, they had 94 participants (60 female, 33 female, and one ‘non-binary’; gotta always be that guy eh?). In this study, there was a small but positive correlation between HCT and IQ (r = .261).
In study 2, they sought to again replicate the relationship between HCT and IQ, determine how specific the relationship is, and determine whether higher IQ results in more accurate knowledge of one’s heart rate which would then improve their scores. They had 134 participants for this task and to minimize false readings they were asked to forgo caffeine consumption about six hours prior to the test.
As a control task, participants were asked to complete a timing accuracy test (TAT) in which they were asked to count seconds instead of heartbeats. The correlation with HCT performance and IQ was, again, small but positive (r = -.211) with IQ also being negatively correlated with the inaccuracy of resting heart rate estimations (r = .363), while timing accuracy was not associated with the inaccuracy of heart rate estimates, IQ or HCT. In the end, knowledge of average resting heart rate completely mediated the relationship between IQ and HCT.
This study replicated another study by Mash et al (2017) who show that their “results suggest that cognitive ability moderates the effect of age on IA differently in autism and typical development.” This new paper then extends this analysis showing that it is fully mediated by prior knowledge of average resting heart rate, and this is key to know.
This is simple: if one has prior knowledge of their average resting heart rate and their fitness did not change from the time they were aware of their average resting heart rate then when they engage in the HCT they will then have a better chance of counting the number of beats in that time frame. This is very simple! There are also other, easier, ways to estimate your heart rate without doing all of that counting.
Heart rate (HR) is a strong predictor of cardiorespiratory fitness. So it would follow that those who have prior knowledge of their HRs would more fitness savvy (the authors don’t really say too much about the subjects if there is more data when the paper is published in a journal I will revisit this). So Murphy et al (2018) showed that 1) prior knowledge of resting heart rate (RHR) was correlated—however low—with IQ while IQ was negatively correlated with the inaccuracy of RHR estimates. So the second study replicated the first and showed that the relationship was specific (HCT correlated with IQ, not any other measure).
The main thing to keep in mind here is that those who had prior knowledge of their RHR scored better on the task; I’d bet that even those with low IQs would score higher on this test if they, too, had prior knowledge of their HRs. That’s, really, what this comes down to: if you have prior knowledge of your RHR and your physiological state stays largely similar (body fat, muscle mass, fitness, etc) then when asked to estimate your heart rate by, say, using the radial pulse method (placing two fingers along the right side of the arm in line just above the thumb), they, since they have prior knowledge, will more accurately guess their RHR, if they had low or high IQs, regardless.
I also question the use of the HCT as a method of interoception, in line with Brener and Ring (2016: 2) who write “participants with knowledge about heart rate may generate accurate counting scores without detecting any heartbeat sensations.” So let’s say that HCT is a good measure of interoception, then it still remains to be seen whether or not manipulating subjects’ HRs would change the accuracy of the analyses. Other studies have shown that testing HR after one exercises, people underestimate their HR (Brener and Ring, 2016: 2). This, too, is simple. To get your max HR after exercise, subtract your age from 220. So if you’re 20 years old, your max HR would be 200, and after exercise, if you know you’re body and how much energy you have expended, then you will be able to estimate better with this knowledge.
Though, you would need to have prior knowledge, of course, of these effects and knowledge of these simple formulas to know about this. So, in my opinion, this study only shows that people who have a higher ‘IQ’ (more access to cultural tools to score higher on IQ tests; Richardson, 2002) are also more likely to, of course, go to the doctor for checkups, more likely to exercise and, thusly, be more likely to have prior knowledge of their HR and score better than those with lower IQs and less access to these types of facilities where they would have access to prior knowledge and get health assesments to have prior knowledge like those with higher IQs (which are more likely to be middle class and have more access to these types of facilities).
I personally don’t think that HCT is a good measure of interoception due to the criticisms brought up above. If I have prior knowledge of my HR (average HR for a healthy person is between 50-75 BPM depending on age, sex, and activity (along with other physiological components) (Davidovic et al, 2013). So, for example,if my average HR is 74 (I just checked mine last week and I checked it in the morning, and averaged 3 morning tests one morning was 73, the other morning was 75 and the third was 74 for an average of 74 BPM), and I had this prior knowledge before undergoing this so-called HCT interoception task, I would be better equipped to score better than one who does not have the same prior knowledge of his own heart rate as I do.
In conclusion, in line with Brener and Ring (2016), I don’t think that HCT is a good measure for interoception, and even if it were, the fact that prior knowledge fully mediates this relationship means that, in my opinion, other methods of interoception need to be found and studied. The fact that if someone has prior knowledge of their HR can and would skew things—no matter their ‘IQ’—since they know that, say, their HR is in the average range (50-75 BPM). I find this study kind of ridiculous and it’s in the running for most ridiculous things I have read all year. Prior knowledge (both with RHR and PEHR; post-exercise heart rate) of these variables will have you score better and, since IQ is a measure of social class then with the small correlation between HCT and IQ found by Murphy et al (2018), some (but most is not) is mediated by IQ, which is just largely tests for skills found in a narrow social class, so it’s no wonder that they corrrlate—however low—and the reason why the relationship was found is obvious, especially if you have some prior knowledge of this field.
Responding to Jared Taylor on the Raven Progressive Matrices Test
2950 words
I was on Warski Live the other night and had an extremely short back-and-forth with Jared Taylor. I’m happy I got the chance to shortly discuss with him but I got kicked out about 20 minutes after being there. Taylor made all of the same old claims, and since everyone continued to speak I couldn’t really get a word in.
A Conversation with Jared Taylor
I first stated that Jared got me into race realism and that I respected him. He said that once you see the reality of race then history etc becomes clearer.
To cut through everything, I first stated that I don’t believe there is any utility to IQ tests, that a lot of people believe that people have surfeits of ‘good genes’ ‘bad genes’ that give ‘positive’ and ‘negative’ charges. IQ tests are useless and that people ‘fetishize them’. He then responded that IQ is one of, if not the, most studied trait in psychology to which JF then asked me if I contended that statement and I responded ‘no’ (behavioral geneticists need to work to ya know!). He then talked about how IQ ‘predicts’ success in life, e.g., success in college,
Then, a bit after I stated that, it seems that they painted me as a leftist because of my views on IQ. Well, I’m far right (not that my politics matters to my views on scientific matters) and they made it seem like I meant that Jared fetishized IQ, when I said ‘most people’.
Then Jared gives a quick rundown of the same old and tired talking points how IQ is related to crime, success, etc. I then asked him if there was a definition of intelligence and whether or not there was consensus in the psychological community on the matter.
I quoted this excerpt from Ken Richardson’s 2002 paper What IQ Tests Test where he writes:
Of the 25 attributes of intelligence mentioned, only 3 were mentioned by 25 per cent or more of respondents (half of the respondents mentioned `higher level components’; 25 per cent mentioned ‘executive processes’; and 29 per cent mentioned`that which is valued by culture’). Over a third of the attributes were mentioned by less than 10 per cent of respondents (only 8 per cent of the 1986 respondents mentioned `ability to learn’).
Jared then stated:
“Well, there certainly are differing ideas as to what are the differing components of intelligence. The word “intelligence” on the other hand exists in every known language. It describes something that human beings intuitively understand. I think if you were to try to describe sex appeal—what is it that makes a woman appealing sexually—not everyone would agree. But most men would agree that there is such a thing as sex appeal. And likewise in the case of intelligence, to me intelligence is an ability to look at the facts in a situation and draw the right conclusions. That to me is one of the key concepts of intelligence. It’s not necessarily “the capacity to learn”—people can memorize without being particularly intelligent. It’s not necessarily creativity. There could be creative people who are not necessarily high in IQ.
I would certainly agree that there is no universally accepted definition for intelligence, and yet, we all instinctively understand that some people are better able to see to the essence of a problem, to find correct solutions to problems. We all understand this and we all experience this in our daily lives. When we were in class in school, there were children who were smarter than other children. None of this is particularly difficult to understand at an intuitive level, and I believe that by somehow saying because it’s impossible to come up with a definition that everyone will accept, there is no such thing as intelligence, that’s like saying “Because there may be no agreement on the number of races, that there is no such thing as race.” This is an attempt to completely sidetrack a question—that I believe—comes from dishonest motives.”
(“… comes from dishonest motives”, appeal to motive. One can make the claim about anyone, for any reason. No matter the reason, it’s fallacious. On ‘ability to learn’ see below.)
Now here is the fun part: I asked him “How do IQ tests test intelligence?” He then began talking about the Raven (as expected):
“There are now culture-free tests, the best-known of which is Raven’s Progressive Matrices, and this involves recognizing patterns and trying to figure out what is the next step in a pattern. This is a test that doesn’t require any language at all. You can show an initial simple example, the first square you have one dot, the next square you have two dots, what would be in the third square? You’d have a choice between 3 dots, 5 dots, 20 dots, well the next step is going to be 3 dots. You can explain what the initial patterns are to someone who doesn’t even speak English, and then ask them to go ahead and go and complete the suceeding problems that are more difficult. No language, involved at all, and this is something that correlates very, very tightly with more traditonal, verbally based, IQ tests. Again, this is an attempt to measure capacity that we all inherently recognize as existing, even though we may not be able to define it to everyone’s mutual satisfaction, but one that is definitely there.
Ultimately, we will be able to measure intelligence through direct assessment of the brain, that it will be possible to do through genetic analysis. We are beginning to discover the gene patterns associated with high intelligence. Already there have been patent applications for IQ tests based on genetic analysis. We really aren’t at the point where spitting in a cup and analyzing the DNA you can tell that this guy has a 140 IQ, this guy’s 105 IQ. But we will eventually get there. At the same time there are aspects of the brain that can be analyzed, repeatedly, with which the signals are transmitted from one part of the brain to the other, the density of grey matter, the efficiency with which white matter communicates between the different grey matter areas of the brain.
I’m quite confident that there will come a time where you can just strap on a set of electrodes and have someone think about something—or even not think about anything at all—and we will be able to assess the power of the brain directly through physical assessment. People are welcome to imagine that this is impossible, or be skeptical about that, but I think we’re defintely moving in that direction. And when the day comes—when we really have discovered a large number of the genetic patterns that are associated with high intelligence, and there will be many of them because the brain is the most complicated organ in the human body, and a very substantial part of the human genome goes into constructing the brain. When we have gotten to the bottom of this mystery, I would bet the next dozen mortgage payments that those patterns—alleles as they’re called, genetic patterns—that are associated with high intelligence will not be found to be equally distributed between people of all races.”
Then immediately after that, the conversation changed. I will respond in points:
1) First off, as I’m sure most long-time readers know, I’m not a leftist and the fact that (in my opinion) I was implied to be a leftist since I contest the utility of IQ is kind of insulting. I’m not a leftist, nor have I ever been a leftist.
2) On his points on definitions of ‘intelligence’: The point is to come to a complete scientific consensus on how to define the word, the right way to study it and then think of the implications of the trait in question after you empirically verify its reality. That’s one reason to bring up how there is no consensus in the psychological community—ask 50 psychologists what intelligence is, get numerous different answers.
3) IQ and success/college: Funny that gets brought up. IQ tests are constructed to ‘predict’ success since they’re similar already to achievement tests in school (read arguments here, here, and here). Even then, you would expect college grades to be highly correlated with job performance 6 years after graduation from college right? Wrong. Armstrong (2011: 4) writes: “Grades at universities have a low relationship to long-term job performance (r = .05 for 6 or more years after graduation) despite the fact that cognitive skills are highly related to job performance (Roth, et al. 1996). In addition, they found that this relationship between grades and job performance has been lower for the more recent studies.” Though the claim that “cognitive skills are highly related to job performance” lie on shaky ground (Richardson and Norgate, 2015).
4) My criticisms on IQ do not mean that I deny that ‘intelligence exists’ (which is a common strawman), my criticisms are on construction and validity, not the whole “intelligence doesn’t exist” canard. I, of course, don’t discard the hypothesis that individuals and populations can differ in ‘intelligence/intelligence ‘genes’, the critiques provided are against the “IQ-tests-predict-X-in-life” claims and ‘IQ-tests-test-‘intelligence” claims. IQ tests test cultural distance from the middle class. Most IQ tests have general knowledge questions on them which then contribute a considerable amount to the final score. Therefore, since IQ tests test learned knowledge present in some cultures and not in others (which is even true for ‘culture-fair’ tests, see point 5), then learning is intimately linked with Jared’s definition of ‘intelligence’. So I would necessariliy state that they do test learned knowledge and test learned knowledge that’s present in some classes compared to others. Thusly, IQ tests test learned knowledge more present in some certain classes than others, therefore, making IQ tests proxies for social class, not ‘intelligence’ (Richardson, 2002; 2017b).
5) Now for my favorite part: the Raven. The test that everyone (or most people) believe is culture-free, culture-fair since there is nothing verbal thusly bypassing any implicit suggestion that there is cultural bias in the test due to differences in general knowledge. However, this assumption is extremely simplistic and hugely flawed.
For one, the Raven is perhaps one of the most tests, even more so than verbal tests, reflecting knowledge structures present in some cultures more than others (Richardson, 2002). One may look at the items on the Raven and then proclaim ‘Wow, anyone who gets these right must be ‘intelligent”, but the most ‘complicated’ Raven’s items are not more complicated than everyday life (Carpenter, Just, and Shell, 1990; Richardson, 2002; Richardson and Norgate, 2014). Furthermore, there is no cognitive theory in which items are selected for analysis and subsequent entry onto a particular Raven’s test. Concerning John Raven’s personal notes, Carpenter, Just, and Shell (1990: 408) show that John Raven—the creator of the Raven’s Progressive Matrices test—used his “intuition and clinical experience” to rank order items “without regard to any underlying processing theory.”
Now to address the claim that the Raven is ‘culture-free’: take one genetically similar population, one group of them are foraging hunter-gatherers while the other population lives in villages with schools. The foraging people are tested at age 11. They score 31 percent, while the ones living in more modern areas with amenities get 72 percent right (‘average’ individuals get 78 percent right while ‘intellectually defective’ individuals get 47 percent right; Heine, 2017: 188). The people I am talking about are the Tsimane, a foraging, hunter-gatherer population in Bolivia. Davis (2014) studied the Tsimane people and administered the Raven test to two groups of Tsimane, as described above. Now, if the test truly were ‘culture-free’ as is claimed, then they should score similarly, right?
Wrong. She found that reading was the best predictor of performance on the Raven. Children who attend school (presumably) learn how to read (with obviously a better chance to learn how to read if you don’t live in a hunter-gatherer environment). So the Tsimane who lived a more modern lifestyle scored more than twice as high on the Raven when compared to those who lived a hunter-gatherer lifestyle. So we have two genetically similar populations, one is exposed to more schooling while the other is not and schooling is the most related to performance on the Raven. Therefore, this study is definitive proof that the Raven is not culture-fair since “by its very nature, IQ testing is culture bound” (Cole, 1999: 646, quoted by Richardson, 2002: 293).
6) I doubt that we will be able to genotype people and get their ‘IQ’ results. Heine (2017) states that you would need all of the SNPs on a gene chip, numbering more than 500,000, to predict half of the variation between individuals in IQ (Davies et al, 2011; Chabris et al, 2012). Furthermore, since most genes may be height genes (Goldstein, 2009). This leads Heine (2017: 175) to conclude that “… it seems highly doubtful, contra Robert Plomin, that we’ll ever be able to estimate someone’s intelligence with much precision merely by looking at his or her genome.”
I’ve also critiqued GWAS/IQ studies by making an analogous argument on testosterone, the GWAS studies for testosterone, and how testosterone is produced in the body (its indirectly controlled by DNA, while what powers the cell is ATP, adenosine triphosphate (Kakh and Burnstock, 2009).
7) Regarding claims on grey and white matter: he’s citing Haier et al’s work, and their work on neural efficiency, white and grey matter correlates regarding IQ, to how different networks of the brain “talk” to each other, as in the P-FIT hypothesis of Jung and Haier (2007; numerous critiques/praises). Though I won’t go in depth on this point here, I will only say that correlations from images, correlations from correlations etc aren’t good enough (the neural network they discuss also may be related to other, noncognitive, factors). Lastly, MRI readings are known to be confounded by noise, visual artifacts and inadequate sampling, even getting emotional in the machine may cause noise in the readings (Okon-Singer et al, 2015) and since movements like speech and even eye movements affect readings, when describing normal variation, one must use caution (Richardson, 2017a).
8) There are no genes for intelligence (I’d also say “what is a gene?“) in the fluid genome (Ho, 2013), so due to this, I think that ‘identifying’ ‘genes for’ IQ will be a bit hard… Also touching on this point, Jared is correct that many genes—most, as a matter of fact—are expressed in the brain. Eighty-four percent, to be exact (Negi and Guda, 2017), so I think there will be a bit of a problem there… Further complicating these types of matters is the matter of social class. Genetic population structures have also emerged due to social class formation/migration. This would, predictably, cause genetic differences between classes, but these genetic differences are irrelevant to education and cognitive ability (Richardson, 2017b). This, then, would account for the extremely small GWAS correlations observed.
9) For the last point, I want to touch briefly on the concept of heritability (because I have a larger theme planned for the concept). Heritability ‘estimates’ have both group and individual flaws; environmental flaws; genetic flaws (Moore and Shenk, 2017), which arise due to the use of the highly flawed CTM (classical twin method) (Joseph, 2002; Richardson and Norgate, 2005; Charney, 2013; Fosse, Joseph, and Richardson, 2015). The flawed CTM inflates heritabilities since environments are not equalized, as they are in animal breeding research for instance, which is why those estimates (which as you can see are lower than the sky-high heritabilities that we get for IQ and other traits) are substantially lower than the heritabilities we observe for traits observed from controlled breeding experiments; which “surpasses almost anything found in the animal kingdom” (Schonemann, 1997: 104).
Lastly, there are numerous hereditarian scientific fallacies which include: 1) trait heritability does not predict what would occur when environments/genes change; 2) they’re inaccurate since they don’t account for gene-environment covariation or interaction while also ignoring nonadditive effects on behavior and cognitive ability; 3) molecular genetics does not show evidence that we can partition environment from genetic factors; 4) it wouldn’t tell us which traits are ‘genetic’ or not; and 5) proposed evolutionary models of human divergence are not supported by these studies (since heritability in the present doesn’t speak to what traits were like thousands of years ago) (Bailey, 1997). We, then, have a problem. Heritability estimates are useful for botanists and farmers because they can control the environment (Schonemann, 1997; Moore and Shenk, 2017). Regarding twin studies, the environment cannot be fully controlled and so they should be taken with a grain of salt. It is for these reasons that some researchers call to end the use of the term ‘heritability’ in science (Guo, 2000). For all of these reasons (and more), heritability estimates are useless for humans (Bailey, 1997; Moore and Shenk, 2017).
Still, other authors state that the use of heritability estimates “attempts to impose a simplistic and reified dichotomy (nature/nurture) on non-dichotomous processes.” (Rose, 2006) while Lewontin (2006) argues that heritability is a “useless quantity” and that to better understand biology, evolution, and development that we should analyze causes, not variances. (I too believe that heritability estimates are useless—especially due to the huge problems with twin studies and the fact that the correct protocols cannot be carried out due to ethical concerns.) Either way, heritability tells us nothing about which genes cause the trait in question, nor which pathways cause trait variation (Richardson, 2012).
In sum, I was glad to appear and discuss (however shortly) with Jared. I listened to it a few times and I realize (and have known before) that I’m a pretty bad public speaker. Either way, I’m glad to get a bit of points and some smaller parts of the overarching arguments out there and I hope I have a chance in the future to return on that show (preferably to debate JF on IQ). I will, of course, be better prepared for that. (When I saw that Jared would appear I decided to go on to discuss.) Jared is clearly wrong that the Raven is ‘culture-free’ and most of his retorts were pretty basic.
(Note: I will expand on all 9 of these points in separate articles.)
Responding to Criticisms on IQ
2250 words
My articles get posted on the Reddit board /r/hbd and, of course, people don’t like what I write about IQ. I get accused of reading ‘Richardson n=34 studies’ even though that was literally one citation in a 32 page paper that does not affect his overall argument. (I will be responding to Kirkegaard and UnsilencedSci in separate articles.) I’ll use this time to respond to criticisms from the Reddit board.
He’s peddling BS, say this:
“But as Burt and his associates have clearly demonstrated, teachers’ subjective assessments afford even more reliable predictors.”
Well, no, teachers are in fact remarkably poor at predicting student’s success in life. Simple formulas based on school grades predict LIFE success better than teachers, notwithstanding the IQ tests.
You’re incorrect. As I stated in my response to The Alternative Hypothesis, the correlation between teacher’s judgement and student achievement is .66. “The median correlation, 0.66, suggests a moderate to strong correspondence between teacher judgements and student achievement” (Hoge and Coladarci, 1989: 303). This is a higher correlation than what was found in the ‘validation studies’ from. Hunter and Schmidt.
He cherry-picks a few bad studies and ignores entire bodies of evidence with sweeping statements like this:
“This, of course, goes back to our good friend test construction. ”
Test construction is WHOLLY IRRELEVANT. It’s like saying: “well, you know, the ether might be real because Michelson-Morley experiment has been constructed this way”. Well no, it does not matter how MM experiment has been constructed as long as it tests for correct principles. Both IQ and MM have predictive power and it has nothing to do with “marvelling”, it has to do whether the test, regardless of its construction, can effectively predict outcomes or not.
This is a horrible example. You’re comparing the presuppositions of the test constructors who have in their mind who is or is not intelligent and then construct the test to confirm those preconceived notions to an experiment that was used to find the presence and properties of aether? Surely you can think of a better analogy because this is not it.
More BS: “Though a lot of IQ test questions are general knowledge questions, so how is that testing anything innate if you’ve first got to learn the material, and if you have not you’ll score lower?”
Of course the IQ tests do NOT test much of general knowledge. Out of 12 tests in WAIS only 2 deal with general knowledge.

The above screenshot is from Nisbett (2012: 14) (though it’s the WISC, not WAIS they’re similar, all IQ tests go through item analysis, tossing items that don’t conform to the test constructors’ presuppositions).
Either way, our friend test construction makes an appearance here, too. This is how these tests are made and they are made to conform to the constructor’s presuppositions. The WISC and WAIS have similar subtests, either way. Test anxiety, furthermore, leads to a lessened performance on the block design and picture arrangement subtests (Hopko et al, 2005) and moderate to severe stress, furthermore, is related to social class and IQ test performance. Stress affects the growth of the hippocampus and PFC (prefrontal cortex) (Davidson and McEwing, 2012) so does it seem like an ‘intellectual’ thing here? Furthermore, all tests and batteries are tried out on a sample of children, with items not contributing to normality being tossed out, therefore ‘item analysis’ forces what we ‘see’ regarding IQ tests.
Even the great Jensen said in his 1980 book Bias in Mental Testing (pg 71):
It is claimed that the psychometrist can make up a test that will yield any type of score distribution he pleases. This is roughly true, but some types of distributions are easier to obtain than others.
This holds for tbe WAIS, WISC, the Raven, any type of IQ test. This shows how arbitrary the ‘item selection’ is. No matter what type of ‘IQ test’ you attempt to use to say ‘It does test “intelligence” (whatever that is)!!’ the reality of test construction and constructing tests to fit presuppositions and distributions cannot be ran away from.
The other popular test, Raven’s Progressive Matrices does not test for general knowledge at all.
This is a huge misconception. People think that just because there are no ‘general knowledge questions’ or anything verbal regarding the Matrices then it must test an innate power, thus mysterious ‘g’. However, this is wrong and he clearly doesn’t keep up with recent data:
Reading was the greatest predictor of performance Raven’s, despite controlling for age and sex. Attendance was so strongly related with Raven’s performance [school attendance was used as a proxy for motivation]. These findings suggest that reading, or pattern recognition, could be fundamentally affecting the way an individual problem solves or learns to learn, and is somehow tapping into ‘g’. Presumably the only way to learn to read is through schooling. It is, therefore, essential that children are exposed to formal education, have the mother to go/stay in school, and are exposed to consistent, quality training in order to develop the skills associated with your performance. (pg 83) Variable Education Exposure and Cognitive Task Performance Among the Tsimane, Forager- Horticulturalists.
Furthermore, according to Richardson (2002): “Performance on the Raven’s test, in other words, is a question not of inducing ‘rules’ from meaningless symbols, in a totally abstract fashion, but of recruiting ones that are already rooted in the activities of some cultures rather than others.”
The assumption that the Raven is ‘culture free’ because it’s ‘just shapes and rote memory’ is clearly incorrect. James Thompson even said to me that Linda Gottfredson said that people only think the Raven is a ‘test of pure g’ because Jensen said it, which is not true.
This is completely wrong in so many ways. No understanding of normalization. Suggestion that missing heritability is discovering environmentally. I think a distorted view of the Flynn Effect. I’ll just stick to some main points.
I didn’t imply a thing about missing heritability. I only cited the article by Evan Charney to show how populations become stratified.
RR: There is no construct validity to IQ tests
First, let’s go through the basics. All IQ tests measure general intelligence (g), the positive manifold underlying every single measure of cognitive ability. This was first observed over a century ago and has been replicated across hundreds of studies since. Non-g intelligences do not exist, so for all intents and purposes it is what we define as intelligence. It is not ‘mysterious’
Thanks for the history lesson. 1) we don’t know what ‘g’ is. (I’ve argued that it’s not physiological.) So ‘intelligence’ is defined as ‘g’ yet which we don’t know what ‘g’ is. His statement here is pretty much literally ‘intelligence is what IQ tests test’.
It would be correct to say that the exact biological mechanisms aren’t known. But as with Gould’s “reification” argument, this does not actually invalidate the phenomenon. As Jensen put it, “what Gould has mistaken for “reification” is neither more nor less than the common practice in every science of hypothesizing explanatory models or theories to account for the observed relationships within a given domain.” Poor analogies to white blood cells and breathalyzer won’t change this.
It’s not a ‘poor analogy’ at all. I’ve since expanded on the construct validity argument with more examples of other construct valid tests like showing how the breathalyzer is construct valid and how white blood cell count is a proxy for disease. They have construct validity, IQ tests do not.
RR: I said that I recall Linda Gottfredson saying that people say that Ravens is culture-fair only because Jensen said it
This has always been said in the context of native, English speaking Americans. For example it was statement #5 within Mainstream Science on Intelligence. Jensen’s research has demonstrated this. The usage of Kuwait and hunter gatherers is subsequently irrelevant.
Point 5 on the Mainstream Science on Intelligence memo is “Intelligence tests are not culturally biased against American blacks or other native-born, English-speaking peoples in the U.S. Rather, IQ scores predict equally accurately for all such Americans, regardless of race and social class. Individuals who do not understand English well can be given either a nonverbal test or one in their native language.”
This is very vague. Richardson (2002) has noted how different social classes are differentially prepared for IQ test items:
I shall argue that the basic source of variation in IQ test scores is not entire (or even mainly) cognitive, and what is cognitive is not general or unitary. It arises from a nexus or sociocognitive-affective factors determining individuals: relative preparedness for the demands of the IQ test.
The fact of the matter is, all social classes aren’t prepared in the same way to take the IQ test and if you read the paper you’d see that.
RR: IQ test validity
I’ll keep this short. There exist no predictors stronger than g across any meaningful measures of success. Not education, grades, upbringing, you name it.
Yes there are. Teacher assessment which has a higher correlation than the correlation between ‘IQ’ and job performance.
RR: Another problem with IQ test construction is the assumption that it increases with age and levels off after puberty.
The very first and most heavily researched behavioral trait’s heritability has been intelligence. Only through sheer ignorance could the term “assumption” describe findings from over a century of inquiry.
Yes the term ‘assumption’ was correct. You do realize that, of course, the increase in IQ heritability is, again, due to test construction? You can also build that into the test as well, by putting more advanced questions, say high school questions for a 12 year old, and heritability would seem to increase due to just how the test was constructed.
Finally, IanTichszy says:
That article is thoroughly silly.
First, the IQ tests predict real world-performance just fine: http://thealternativehypothesis.org/index.php/2016/04/15/the-validity-of-iq/
I just responded to this article this week. They only ‘predicts real-world performance just fine’ because they’re constructed to and even then, high-achieving children in achievement rarely become high achieving adults whereas low-achieving adults tend to become successful adults. There are numerous problems with TAH’s article which I’ve already covered.
That is the important thing, not just correlation with blood pressure or something biological. Had g not predicted real-world performance from educational achievement to job performance with very high reliability, it would be useless, but it does predict those.
Test construction. You can’t get past that by saying ‘it does predict’ because it only predicts because it’s constructed to (I’d call it ‘post-dict’).
Second, on Raven’s Progressive Matrices test: the argument “well Jensen just said so” is plain silly. If RPM is culturally loaded, a question: just what culture is represented on those charts? You can’t reasonably say that. Orangutans are able to solve simplified versions of RPM, apparently they do not have a problem with cultural loading. Just look at the tests yourself.
Of course it’s silly to accept that the Raven is culture free and tests ‘g’ the best just ‘because Jensen said so’. The culture loading of the Raven is known, there is a ‘hidden structure’ in them. Even the constructors of the Raven have noted this where they state that they transposed the items to read from left to right, not right to left which is a tacit admission of cultural loading. “The reason that some people fail such problems is exactly the same reason some people fail IQ test items like the Raven Matrices tests… It simply is not the way the human cognitive system is used to being engaged” (Richardson, 2017: 280).
Furthermore, when items are familiar to all groups, even young children are capable of complex analogical reasoning. IQ tests “test for the learned factual knowledge and cognitive habits more prominent in some social classes than in others. That is, IQ scores are measures of specific learning, as well as self-confidence and so on, not general intelligence“ (Richardson, 2017: 192).
Another piece of misinformation: claiming that IQs are not normally distributed. Well, we do not really know the underlying distribution, that’s the problem, only the rank order of questions by difficulty, because we do not have absolute measure of intelligence. Still, the claim that SOME human mental traits, other than IQ, do not have normal distribution, in no way impacts the validity of IQ distribution as tests found it and projected onto mean 100 and standard dev 15 since it reflects real world performance well.
Physiological traits important for survival are not normally distributed (of course it is assumed that IQ both tests innate physiological differences and is important for survival so if it were physiological it wouldn’t be normally distributed either since traits important for survival have low heritabilities). It predicts real world performance well because, see above and my other articles on thus matter.
If you know even the basic facts about IQ, it’s clear that this article has been written in bad faith, just for sake of being contrarian regardless of the truth content or for self-promotion.
No, people don’t know the basic facts of IQ (or its construction). My article isn’t written in bad faith nor is it being contrarian regardless of the truth content or for self-promotion. I can, clearly, address criticisms to my writing.
In the future, if anyone has any problems with what I write then please leave a comment here on the blog at the relevant article. Commenting on Reddit on the article that gets posted there is no good because I probably won’t see it.
The Non-Validity of IQ: A Response to The Alternative Hypothesis
1250 words
Ryan Faulk, like most IQ-ists, believes that the correlation with job performance and IQ somehow is evidence for its validity. He further believes that because self- and peer-ratings correlate with one’s IQ scores that that is further evidence for IQ’s validity.
Well too bad for Faulk, correlations with other tests and other IQ tests lead to circular assumptions. The first problem, as I’ve covered before, is that there is no agreed-upon model or description of IQ/intelligence/’g’ and so therefore we cannot reliably and truthfully state that differences in ‘g’ this supposed ‘mental power’ this ‘strength’ is what causes differences in test scores. Unfortunately for Ryan Faulk and other IQ-ists, again, coming back to our good old friend test construction, it’s no wonder that IQ tests correlate around .5—or so is claimed—with job performance, however IQ test scores correlate at around .5 with school achievement, which is caused by some items containing knowledge that has been learned in school, such as “In what continent is Egypt?” and Who wrote Hamlet?” and “What is the boiling point of water?” As Ken Richardson writes in his 2017 book Genes, Brains, and Human Potential: The Science and Ideology of Intelligence (pg 85):
So it should come as no surprise that performance on them [IQ tests] is associated with school performance. As Robert L. Thorndike and Elizabeth P. Hagen explained in their leading textbook, Educational and Psychological Measurement, “From the very way in which the tests were assembled [such correlation] could hardly be otherwise.”
So, obviously, neither of the two tests determine independently that they measure intelligence, this so-called innate power, and because they’re different versions of the same test there is a moderate correlation between them. This goes back to item analysis and test construction. Is it any wonder, then, why correlations with IQ and achievement increase with age? It’s built into the test! And while Faulk does cite high correlations from one of Schmidt and Hunter’s meta-analyses on the subject, what he doesn’t tell you is that one review found a correlation of .66 between teacher’s assessment and future achievement of their students later in life (higher than the correlation with job performance and IQ) (Hoge and Coladarci, 1989.) They write (pg 303): “The median correlation, 0.66, suggests a moderate to strong correspondence between teacher judgments and student achievement.” This is just like what I quoted the other day in my response to Grey Enlightenment where I quoted Layzer (1972) who wrote:
Admirers of IQ tests usually lay great stress on their predictive power. They marvel that a one-hour test administered to a child at the age of eight can predict with considerable interest whether he will finish college. But as Burt and colleagues have clearly demonstrated, teachers subjective assessments afford even more reliable predictors. This is almost a truism.
So the correlation of .5 between occupation level and IQ is self-fulfilling, which are not independent measures. In regard to the IQ and job performance correlation, which I’ve discussed in the past, studies in the 70s showed much lower correlations, between .2 and .3, which Jensen points out in The g Factor.
The problem with the so-called validity studies carried out by Schmidt and Hunter, as cited by Ryan Faulk, is that they included numerous other tests that were not IQ tests in their analysis like memory tests, reading tests, the SAT, university admission tests, employment selection tests, and a variety of armed forces tests. “Just calling these “general ability tests,” as Schmidt and Hunter do, is like reducing a diversity of serum counts to a “general. blood test” (Richardson, 2017: 87). Of course the problem with using vastly different tests is that they tap into different abilities and sources of individual differences. The correlation between SAT scores and high school grades is .28 whereas the correlation between both the SAT and high school grades and IQ is about .2. So it’s clearly not testing the same “general ability” that’s being tested.
Furthermore, regarding job performance, it’s based on one measure: supervisor ratings. These ratings are highly subjective and extremely biased with age and halo effects seen with height and facial attractiveness being seen to sway judgments on how well one works. Measures of job performance are unreliable—especially from supervisors—due to the assumptions and biases that go into the measure.
I’ve also shown back in October that there is little relationship between IQ and promotion to senior doctor (McManus et al, 2013).
Do IQ tests test neural processes? Not really. One of the most-studied variables is reaction time. The quicker they react to a stimulus, supposedly, the higher their IQ is in average as they are quicker to process information, the story goes. Detterman (1987) notes that other factors other than ‘processing speed’ can explain differences in reaction time, including but not limited to, stress, understanding instructions, motivation to do said task, attention, arousal, sensory acuity, confidence, etc. Khodadadi et al (2014) even write “The relationship between reaction time and IQ is too complicated and reveal a significant correlation depends on various variables (e.g. methodology, data analysis, instrument etc.).” Complex cognition in real life is also completely different than the simple questions asked in the Raven (Richardson and Norgate, 2014).
It is easy to look at the puzzles that make up IQ tests and be convinced that they really do test brain power. But then we ignore the brain power thst nearly everyone displays in their everyday lives. Some psychologists have noticed thst people who stumble over formal tests of cognitive can bangle highly complex problems in their real lives all the time. As Michael Eysenck put it in his well-known book Psychology, “There is an apparent contradiction between our ability to deal effectively with out everyday environment and our failure to perform well on many laboratory reasoning tasks.” We can say the same about IQ tests.
[…]
Real-life problems combine many more variables that change over time and interact. It seems that the ability to do pretentious problems in a pencil-and-paper (or computer) format, like IQ test items, is itself a learned, if not-so-complex skill. (Richardson, 2017: 95-96)
Finally, Faulk cites studies showing that how intelligent people and their peers rates themselves and others predicted how well they did on IQ tests. This isn’t surprising. Since they correlate with academic achievement at .5 then if one is good academically then they’d have a high test score more often than not. That friends rate friends high and they end up matching scores is no surprise either as people generally group together with other people like themselves and so therefore will have similar achievements. That is not evidence for test validity though!! See Richardson and Norgate (2015) “In scientific method, generally, we accept external, observable differences as a valid measure of an unseen function when we can mechanistically relate differences in one to diffences in the other …” So even Faulk’s attempt to ‘validate’ IQ tests using peer- and self-ratings of ‘intelligence’ (whatever that is) falls on its face since its not a true measure of validity. It’s not construct validity. (EDIT: Psychological constructs are validated ‘by testing whether they relate to measures of other constructs as specified by theory‘ (Strauss and Smith, 2009). This doesn’t exist for IQ therefore IQ isn’t construct valid.)
In sum, Faulk’s article leaves a ton to be desired and doesn’t outright prove that there is validity to IQ tests because, as I’ve shown in the past, validity for IQ is nonexistent, though some have tried (using correlations with job performance as evidence) but Richardson and Norgate (2015) take down those claims and show that the correlation is between .2 and .3, not the .5+ cited by Hunter and Schmidt in their ‘validation studies’. The criteria laid out by Faulk does not prove that there is true construct validity to IQ tests and due to test construction, we see these correlations with educational achievement.
People Should Stop Thinking IQ Measures ‘Intelligence’: A Response to Grey Enlightenment
1700 words
I’ve had a few discussions with Grey Enlightenment on this blog, regarding construct validity. He has now published a response piece on his blog to the arguments put forth in my article, though unfortunately it’s kind of sophomoric.
People Should Stop Saying Silly Things About IQ
He calls himself a ‘race realist’yet echoes the same arguments used by those who oppose such realism.
1) One doesn’t have to believe in racial differences in mental traits to be a race realist as I have argued twice before in my articles You Don’t Need Genes to Delineate Race and Differing Race Concepts and the Existence of Race: Biologically Scientific Definitions of Race. It’s perfectly possible to be a race realist—believe in the reality of race—without believing there are differences in mental traits—‘intelligence’, for instance (whatever that is).
2) That I strongly question the usefulness and utility of IQ due to its construction doesn’t mean that I’m not a race realist.
3) I’ve even put forth an analogous argument on an ‘athletic abilities test’ where I gave a hypothetical argument where a test was constructed that wasn’t a true test of athletic ability and that it was constructed on the basis of who is or is not athletic, per the constructors’ presuppositions. In this hypothetical scenario, am I really denying that athletic differences exist between races and individuals? No. I’d just be pointing out flaws in a shitty test.
Just because I question the usefulness and (nonexistent) validity of IQ doesn’t mean that I’m not a race realist, nor that I believe groups or individuals are ‘the same’ in ‘intelligence’ (whatever that may be; which seems to be a common strawman for those who don’t bow to the alter of IQ).
Blood alcohol concentration is very specific and simple; human intelligence by comparison is not . Intelligence is polygenic (as opposed to just a single compound) and is not as easy to delineate, as, say, the concentration of ethanol in the blood.
It’s irrelevant how ‘simple’ blood alcohol concentration is. The point of bringing it up is that it’s a construct valid measure which is then calibrated against an accepted and theoretical biological model. The additive gene assumption is false, that is, genes being independent of the environment giving ‘positive charges’ as Robert Plomin believes.
He says IQ tests are biased because they require some implicit understanding if social constructs, like what 1+1 equals or how to read a word problem, but how is a test that is as simple as digit recall or pattern recognition possibly a social construct.
What is it that allows individuals to be better than others on digit recall or pattern recognition (what kind of pattern recognition?)? The point of my 1+1 statement is that it is construct valid regarding one’s knowledge of that math problem whereas for the word problem, it was a quoted example showing how if the answer isn’t worded correctly it could be indirectly testing something else.
He’s invoking a postmodernist argument that IQ tests do not measure an innate, intrinsic intelligence, but rather a subjective one that is construct of the test creators and society.
I could do without the buzzword (postmodernist) though he is correct. IQ tests test what their constructors assume is ‘intelligence’ and through item analysis they get the results they want, as I’ve shown previously.
If IQ tests are biased, how is then [sic] that Asians and Jews are able to score better than Whiles [sic] on such tests; surely, they should be at a disadvantage due to implicit biases of a test that is created by Whites.
If I had a dollar for every time I’ve heard this ‘argument’… We can just go back to the test construction argument and we can construct a test that, say, blacks and women score higher than whites and men respectively. How well would that ‘predict’ anything then, if the test constructors had a different set of assumptions?
IQ tests aren’t ‘biased’, as much as lower class people aren’t as prepared to take these tests as people in higher classes (which East Asians and Jews are in). IQ tests score enculturation to the middle class, even the Flynn effect can be explained by the rise in the middle class, lending credence to the aforementioned hypothesis (Richardson, 2002).
Regarding the common objection by the left that IQ tests don’t measures [sic] anything useful or that IQ isn’t correlated with success at life, on a practical level, how else can one explain obvious differences in learning speed, income or educational attainment among otherwise homogeneous groups? Why is it in class some kids learn so much faster than others, and many of these fast-learners go to university and get good-paying jobs, while those who learn slowly tend to not go to college, or if they do, drop out and are either permanently unemployed or stuck in low-paying, low-status jobs? In a family with many siblings, is it not evident that some children are smarter than others (and because it’s a shared environment, environmental differences cannot be blamed).
1) I’m not a leftist.
2) I never stated that IQ tests don’t correlate with success in life. They correlate with success in life since achievement tests and IQ tests are different versions of the same test. This, of course, goes back to our good friend test construction. IQ is correlated with income at .4, meaning 16 percent of the variance is explained by IQ and since you shouldn’t attribute causation to correlations (lest you commit the cum hoc, ergo propter hoc fallacy), we cannot even truthfully say that 16 percent of the variation between individuals is due to IQ.
3) Pupils who do well in school tend to not be high-achieving adults whereas children who were not good pupils ended up having good success in life (see the paper Natural Learning in Higher Education by Armstrong, 2011). Furthermore, the role of test motivation could account for low-paying, low-status jobs (Duckworth et al, 2011; though I disagree with their consulting that IQ tests test ‘intelligence’ [whatever that is] they show good evidence that in low scorers, incentives can raise scores, implying that they weren’t as motivated as the high scorers). Lastly, do individuals within the same family experience the same environment the same or differently?
As teachers can attest, some students are just ‘slow’ and cannot grasp the material despite many repetitions; others learn much more quickly.
This is evidence of the uselessness of IQ tests, for if teachers can accurately predict student success then why should we waste time and money to give a kid some test that supposedly ‘predicts’ his success in life (which as I’ve argued is self-fulfilling)? Richardson (1998: 117) quotes Layzer (1973: 238) who writes:
Admirers of IQ tests usually lay great stress on their predictive power. They marvel that a one-hour test administered to a child at the age of eight can predict with considerable accuracy whether he will finish college. But as Burt and his associates have clearly demonstrated, teachers’ subjective assessments afford even more reliable predictors. This is almost a truism.
Because IQ tests test for the skills that are required for learning, such as short term memory, someone who has a low IQ would find learning difficult and be unable to make correct inferences from existing knowledge.
Right, IQ tests test for skills that are required for learning. Though a lot of IQ test questions are general knowledge questions, so how is that testing anything innate if you’ve first got to learn the material, and if you have not you’ll score lower? Richardson (2002) discusses how people in lower classes are differentially prepared for IQ tests which then affects scores, along with psycho-social factors that do so as well. It’s more complicated than ‘low IQ > X’.
All of these sub-tests are positively correlated due to an underlying factor –called g–that accounts for 40-50% of the variation between IQ scores. This suggests that IQ tests measure a certain factor that every individual is endowed with, rather than just being a haphazard collection of questions that have nothing to do with each other. Race realists’ objection is that g is meaningless, but the literature disagrees “… The practical validity of g as a predictor of educational, economic, and social outcomes is more far-ranging and universal than that of any other known psychological variable. The validity of g is greater the complexity of the task.[57][58]”
I’ve covered this before. It correlates with the aforementioned variables due to test construction. It’s really that easy. If the test constructors have a different set of presuppositions before the test is constructed then completely different outcomes can be had just by constricting a different test.
Then what about ‘g’? What would one say then? Nevertheless, I’ve heavily criticized ‘g’ and its supposed physiology, and if physiologists did study this ‘variable’ and if it truly did exist, 1) it would not be rank ordered because physiologists don’t rank order traits, 2) they don’t assume normal variations, they don’t estimate heritability and attempt to untangle genes from environment, 3) they don’t assume that normal variation is related to genetic variation (except in rare cases, like down syndrome, for instance), and 4) nor do they assume within the normal range of physiological differences that a higher level is ‘better’ than a lower. My go-to example here is BMR (basal metabolic rate). It has a similar heritability range as IQ (.4 to .8; which is most likely overestimated due to the use of the flawed twin method, just like the heritability of IQ), so is one with a higher BMR somehow ‘better’ than one with a lower BMR? This is what logically follows from assuming that ‘g’ is physiological and all of the assumptions that come along with it. It doesn’t make logical, physiological sense! (Jensen, 1998: 92 further notes that “g tells us little if anything about its contents“.)
All in all, I thank Grey Enlightenment for his response to my article, though it leaves a lot to be desired and if he responds to this article then I hope that it’s much more nuanced. IQ has no construct validity, and as I’ve shown, the attempts at giving it validity are circular, and done by correlating it with other IQ tests and achievement tests. That’s not construct validity.
IQ and Construct Validity
1550 words
The word ‘construct’ is defined as “an idea or theory containing various conceptual elements, typically one considered to be subjective and not based on empirical evidence.” Whereas the word ‘validity’ is defined as “the quality of being logically or factually sound; soundness or cogency.” Is there construct validity for IQ tests? Are IQ tests tested against an idea or theory containing various conceptual elements? No, they are not.
Cronbach and Meehl (1955) define construct validity, which they state is “involved whenever a test is to be interpreted as a measure of some attribute or quality which is not “operationally defined.”” Though, the construct validity for IQ tests has been fleeting to investigators. Why? Because there is no theory of individual IQ differences to test IQ tests on. It is even stated that “there is no accepted unit of measurement for constructs and even fairly well-known ones, such as IQ, are open to debate.” The ‘fairly well-known ones’ like IQ are ‘open to debate’ because no such validity exists. The only ‘validity’ that exists for IQ tests is correlations with other tests and attempted correlations with job performance, but I will show that that is not construct validity as is classicly defined.
Construct validity can be easily defined as the ability of a test to measure the concept or construct that it is intended to measure. We know two things about IQ tests: 1) they do not test ‘intelligence’ (but they supposedly do a ‘good enough job’ so that it does not matter) and 2) it does not even test the ‘construct’ that it is intended to measure. For example, the math problem ‘1+1’ is construct valid regarding one’s knowledge and application of that math problem. Construct validity can pretty much be summed up as the proof that it is measuring what the test intends…but where is this proof? It is non-existent.
Richardson (1998: 116) writes:
Psychometrists, in the absence of such theoretical description, simply reduce score differences, blindly to the hypothetical construct of ‘natural ability’. The absence of descriptive precision about those constructs has always made validity estimation difficult. Consequently the crucial construct validity is rarely mentioned in test manuals. Instead, test designers have sought other kinds of evidence about the valdity of their tests.
The validity of new tests is sometimes claimed when performances on them correlate with performances on other, previously accepted, and currently used, tests. This is usually called the criterion validity of tests. The Stanford-Binet and the WISC are often used as the ‘standards’ in this respect. Whereas it may be reassuring to know that the new test appears to be measuring the same thing as an old favourite, the assumption here is that (construct) validity has already been demonstrated in the criterion test.
Some may attempt to say that, for instance, biological construct validity for IQ tests may be ‘brain size’, since brain size is correlated with IQ at .4 (meaning 16 percent of the variance in IQ is explained by brain size). However, for this to be true, someone with a larger brain would always have to be ‘more intelligent’ (whatever that means; score higher on an IQ test) than someone with a smaller brain. This is not true, so therefore brain size is not and should not be used as a measure of construct validity. Nisbett et al (2012: 144) address this:
Overall brain size does not plausibly account for differences in aspects of intelligence because all areas of the brain are not equally important for cognitive functioning.
For example, breathalyzer tests are construct valid. There is a .93 correlation (test-retest) between 1 ml/kg bodyweight of ethanol in 20, healthy male subjects. Furthermore, obtaining BAC through gas chromatography of venous blood, the two readings were highly correlated at .94 and .95 (Landauer, 1972). Landauer (1972: 253) writes “the very high accuracy and validity of breath analysis as a correct estimate of the BAL is clearly shown.” Construct validity exists for ad-libitum taste tests of alcohol in the laboratory (Jones et al, 2016).
There is a casual connection between what one breathes into the breathalyzer and his BAC that comes out of the breathalyzer and how much he had to drink. For example, for a male at a bodyweight of 160 pounds, 4 drinks would have him at a BAC of .09, which would make him unfit to drive. (‘One drink’ being 12 oz of beer, 5 oz of wine, or 1.25 oz of 80 proof liquor.) He drinks more, his BAC reading goes up. Someone is more ‘intelligent’ (scores higher on an IQ test), then what? The correlations obtained from so-called ‘more intelligent people’, like glucose consumption, brain evoked potentials, reaction time, nerve conduction velocity, etc have never been shown to determine higher ‘ability’ to score higher on IQ tests. That, too, would not even be construct validation for IQ tests, since there needs to be a measure showing why person A scored higher than person B, which needs to hold one hundred percent of the time.
Another good example of the construct validity of an unseen construct is white blood cell count. White blood cell count was “associated with current smoking status and COPD severity, and a risk factor for poor lung function, and quality of life, especially in non-currently smoking COPD patients. The WBC count can be used, as an easily measurable COPD biomarker” (Koo et al, 2017). In fact, the PRISA II test has white blood cell count in it, which is a construct valid test. Even elevated white blood cell count strongly predicts all-cause and cardiovascular mortality (Johnson et al, 2005). It is also an independent risk factor for coronary artery disease (Twig et al, 2012).
A good example of tests supposedly testing one thing but testing another is found here:
As an example, think about a general knowledge test of basic algebra. If a test is designed to assess knowledge of facts concerning rate, time, distance, and their interrelationship with one another, but test questions are phrased in long and complex reading passages, then perhaps reading skills are inadvertently being measured instead of factual knowledge of basic algebra.
Numerous constructs have validity—but not IQ tests. It is assumed that they test ‘intelligence’ even though an operational definition of intelligence is hard to come by. This is important, as if there cannot be an agreement on what is being tested, how will there be construct validity for said construct in question?
Richardson (2002) writes that Detterman and Sternberg sent out a questionnaire to a group of theorists which was similar to another questionnaire sent out decades earlier to see if there was an agreement on what ‘intelligence’ is. Twenty-five attributes of intelligence were mentioned. Only 3 were mentioned by more than 25 percent of the respondents, with about half mentioning ‘higher level components’, one quarter mentioned ‘executive processes’ while 29 percent mentioned ‘that which is valued by culture’. About one-third of the attributes were mentioned by less than 10 percent of the respondents with 8 percent of them answering that intelligence is ‘the ability to learn’. So if there is hardly any consensus on what IQ tests measure or what ‘intelligence’ is, then construct validity for IQ seems to be very far in the distance, almost unseeable, because we cannot even define the word, nor actually test it with a test that’s not constructed to fit the constructors’ presupposed notions.
Now, explaining the non-existent validity of IQ tests is very simple: IQ tests are purported to measure ‘g’ (whatever that is) and individual differences in test scores supposedly reflect individual differences in ‘g’. However, we cannot say that it is differences in ‘g’ that cause differences in individual test scores since there is no agreed-upon model or description of ‘g’ (Richardson, 2017: 84). Richardson (2017: 84) writes:
In consequence, all claims about the validity of IQ tests have been based on the assumption that other criteria, such as social rank or educational or occupational acheivement, are also, in effect, measures of intelligence. So tests have been constructed to replicate such ranks, as we have seen. Unfortunately, the logic is then reversed to declare that IQ tests must be measures of intelligence, because they predict school acheivement or future occupational level. This is not proper scientific validation so much as a self-fulfilling ordinance.
Construct validity for IQ does not exist (Richardson and Norgate, 2015), unlike construct validity for breathalyzers (Landauer, 1972) or white blood cell count as a disease proxy (Wu et al, 2013; Shah et al, 2017). So, if construct validity is non-existent, then that means that there is no measure for how well IQ tests measure what it’s ‘purported to measure’, i.e., how ‘intelligent’ one is over another because 1) the definition of ‘intelligence’ is ill-defined and 2) IQ tests are not validated against agreed-upon biological models, though some attempts have been made, though the evidence is inconsistent (Richardson and Norgate, 2015). For there to be true validity, evidence cannot be inconsistent; it needs to measure what it purports to measure 100 percent of the time. IQ tests are not calibrated against biological models, but against correlations with other tests that ‘purport’ to measure ‘intelligence’.
(Note: No, I am not saying that everyone is equal in ‘intelligence’ (whatever that is), nor am I stating that everyone has the same exact capacity. As I pointed out last week, just because I point out flaws in tests, it does not mean that I think that people have ‘equal ability’, and my example of an ‘athletic abilities’ test last week is apt to show that pointing out flawed tests does not mean that I deny individual differences in a ‘thing’ (though athletic abilities tests are much better with no assumptions like IQ tests have.))
Athletic Ability and IQ
1150 words
Proponents of the usefulness of IQ tests may point to athletic competitions as an analogous test/competition that they believe may reinforce their belief that IQ tests ‘intelligence’ (whatever that is). Though, there are a few flaws in their attempted comparison. Some may say that “Lebron James and Usain Bolt have X morphology/biochemistry and therefore that’s why they excel! The same goes foe IQ tests!” People then go on to ask if I ‘deny human evolution’ because I deny the usefulness (that is built into the test by way of ‘item analysis; Jensen, 1980: 137) of IQ tests and point out flaws in their construction.
People who accept the usefulness of IQ tests and attempt to defend their flaws may attempt to make sports competition, like, say, a 100m sprint, an analogous argument. They may say that ‘X is better than Y, and the reason is ‘genetic’ in nature!’. Though, nature vs. nurture is a false dichotomy and irrelevant (Oyama, 1985, 2000; Oyama, 1999; Oyama, 2000; Moore, 2003). Behavior is neither ‘genetic’ nor ‘environmental’. with that out of the way, tests of athletic ability as mentioned above are completely different from IQ tests.
Tests of athletic ability do not have any arbitrary judgments as IQ tests do in their construction and analysis of the items to be put on the test. It’s a simple, cut-and-dry explanation: on this instance in this test, runner X was better than runner Y. We can then test runner X and see what kind of differences he has in his physiology and somatype, along with asking him what drives him to succeed. We can then do the same for the other athlete and discover that, as hypothesized, there are inherent differences in their physiology that make runner X be better than runner Y, say the ability to take deeper breaths, take longer strides per step due to longer legs, having thinner appendages as to be faster and so on. In regard to IQ, the tests are constructed on the prior basis of who is or is not intelligent. Basically, as is not the case with tests of athletic ability, the ‘winners and losers’, so to speak, are already chosen on the prior suppositions of who is or is not intelligent. Therefore, the comparison of athletic abilities tests and IQ tests are not good because athletic abilities tests are not constructed on the basis of who the constructors believe are athletic, like IQ tests are constructed on the basis of who the testers believe is ‘intelligent’ or not.
Some people are so far up the IQ-tests-test-intelligence idea that due to the critiques I cite on IQ tests, I actually get asked if I ‘deny human evolution’. That’s ridiculous and I will explain why.
Imagine an ‘athletic abilities’ test existed. Imagine that this test was constructed on the basis of who the test constructor believed who is or is not athletic. Imagine that he constructs the test to show that people who had previously low ability in past athletic abilities tests had ‘high athletic ability’ in this new test that he constructed. Then I discover the test. I read about it and I see how it is constructed and what the constructors did to get the results they wanted, because they believed that the lower-ability people in the previous tests had higher ability and therefore constructed an ‘athletic abilities’ test to show they were more ‘athletic’ than the former high performers. I then point out the huge flaws in the construction of such a test. The logic of people who claim that I deny human evolution because I blast the validity and construction of IQ tests would, logically, have to say that I’m denying athletic differences between groups and individuals, when in actuality I’m only pointing out huge flaws in the ‘athletic abilities’ test that was constructed. The athletic abilities example I’ve conjured up is analogous to the IQ test construction tirade I’ve been on recently. So, if a test of ‘athletic ability’ exists and I come and critique it, then no, I am not denying athletic differences between individuals I am only pointing out flawed tests.
The basic structure of my ‘athletic abilities’ argument is this: that test that would be constructed would not test true ‘athletic abilities’ just like IQ tests don’t test ‘intelligence’ (Richardson, 2002). Pointing out huge flaws in tests does not mean that you’re a ‘blank slatist’ (whatever that is; it’s a strawman for people who don’t bow down to the IQ alter). Pointing out flaws in IQ tests does not mean that you believe that everyone and every group is ‘equal’ in a psychological and mental sense. Pointing out the flaws in IQ tests does not mean that one is a left-wing egalitarian that believes that all humans—individuals and groups—are equal and that the only cause of their differences comes down to the environment (whether SES or the epigenetic environment, etc). Pointing out flaws in these tests is needed; lest people truly think that they do test, say, ability for complex cognition (they don’t). Indeed, it seems that everyday life is more complicated than the hardest Raven’s item. Richardson and Norgate (2014) write:
Indeed, typical IQ test items seem remarkably un-complex in their cognitive demands compared with, say, the cognitive demands of ordinary social life and other everyday activities that the vast majority of children and adults can meet. (pg 3)
On the other hand abundant cognitive research suggests that everyday, “real life”
problem solving, carried out by the vast majority of people, especially in social-cooperative situations, is a great deal more complex than that required by IQ test items, including those in the Raven. (pg 6)
Could it be possible that ‘real-life’ athletic ability, such as ‘walking’ or whatnot be more ‘complex’ than the analog of athletic ability? No, not at all. Because, as I previously noted, athletic abilities tests test who has the ‘better’ physiology or morphology for whichever competition they choose to compete in (and of course there will be considerable self-selection since people choose things they’re good at). It’s clear that there is absolutely no possibility of ‘real-life’ athletic ability possibly being more complex than tests of athletic ability.
In sum, no, I do not deny human evolution because I critique IQ tests. Just because I critique IQ tests doesn’t mean that I deny human evolution. My example of the ‘athletic test’ is a sound and logical analog to the IQ critiques that I cite. Just framing it in the way of a false test of athletic ability and then pointing out the flaws is enough to show that I don’t deny human evolution. Because if such an ‘athletic abilities’ test did exist and I pointed out its flaws, I would not be denying differences between groups or individuals due to evolution, I’d simply be critiquing a shitty test, which is what I do with IQ tests. Actual tests of athletic ability are not analogous to IQ tests because tests of athletic ability are not ‘constructed’ in the way that IQ tests are.
IQ Test Construction
1550 words
No one really discusses how IQ tests are constructed; people just accept the numbers that are spit out and think that it shows one’s intelligence level relative to others who took the test. However, there are huge methodological flaws in regard to IQ tests—one of the largest, in my opinion, being that they are constructed to fit a normal curve and based on the ‘prior knowledge’ of who is or is not intelligent.
What people don’t understand about test construction is that the behavior genetic (BG) method must assume a normal distribution. IQ tests have been constructed to display this normal distribution, so we cannot say whether or not it exists in nature, though few human traits fall on the normal distribution. The fact of the matter is this: The normal curve is achieved through keeping more items that people get right while keeping the smaller proportion of items that people get right and wrong. This forces the normal curve and all of the assumptions that come along with this so-called IQ bell curve.
Even then, the fact that the normal distribution is forced doesn’t mean as much as the assumptions and conclusions drawn from the forced curve. It is assumed that individual test score differences arise out of ‘biology’, however with how test questions are manipulated to get the results that the test constructors want, it is then assumed that the cause for individual test score differences are ‘biological’ in nature, however we don’t know if these distributions are ‘biological’ in nature due to how the tests are constructed.
The fact of the matter is, the tests are constructed based off of the prior knowledge of who is or is not intelligent. This means that we can ‘build the test’ to fit these preconceived notions. The problem of item selection was discussed by Richardson (1998) who discussed boys scoring a few points higher than girls, and wondering whether or not these differences should be ‘allowed to persist’ or not. Richardson (1998: 114) writes (12/26/17 Edit: I’ll also provide the quote that precedes this one):
“One who would construct a test for intellectual capacity has two possible methods of handling the problem of sex differences.
1 He may assume that all the sex differences yielded by his test items are about equally indicative of sex differences in native ability.
2 He may proceed on the hypothesis that large sex differences on items of the Binet type are likely to be factitious in the sense that they reflect sex differences in experience or training. To the extent that this assumption is valid, he will be justified in eliminating from his battery test items which yield large sex differences.
The authors of the New Revision have chosen the second of these alternatives and sought to avoid using test items showing large differences in percents passing.” (McNemar 1942:56)This is, of course, a clear admission of the subjectivity of such assumptions: while ‘preferring’ to see sex differences as undesirable artefacts of test composition, other differences between groups or individuals, such as different social classes or, at various times, different ‘races’, are seen as ones ‘truly’ existing in nature. Yet these, too, could be eliminated or exaggerated by exactly the same process of assumption and manipulation of test composition.
And further writes on page 121:
Suffice it to say that investigators have simply made certain assumptions about ‘what to expect’ in the patterns of scores, and adjusted their analytical equations accordingly: not surprisingly, that pattern emerges!
The only ‘assumption’ that the test constructors have is the biases they already have on who is or is not ‘intelligent’ and then they construct the test through item selection, excising items that don’t fit their desired distribution. Is that supposed to be scientific? You can ask a group of children a bunch of questions and then construct a test to get the conclusion you want based on item selection.
The BG method needs to assume that IQ test scores lie on a normal curve and that it is a quantitative trait that exhibits a normal distribution, though Micceri (1989) showed that normal distributions for measurable traits are the exception, rather than the rule, for numerous measurable traits. Richardson (1998: 113) further writes:
The same applies to many other ‘characteristics’ of IQ. For example, the ‘normal distribution, or bell-shaped curve, reflects (misleadingly as I have suggested in Chapters 1 to 3) key biological assumptions about the nature of cognitive abilities. It is also an assumption crucial to many statistical analyses done on test scores. But it is a property built into a test by the simple device of using relatively more items on which about half the testees pass, and relatively few items on which either many or only a few of them pass. Dangers arise, of course, when we try to pass this property off as something happening in nature instead of contrived by test constructors.
So with the knowledge of test construction, then there is something very obvious here: we can construct IQ tests that, say, show blacks scoring higher than whites and women scoring higher than men. We can then make the assumption that there are genes that are responsible for this distribution and then ‘find genes’ that supposedly cause these differences in test scores (which are constructed to show the differences!). What then? Let’s say that someone did do that, would the logical conclusion be that there are genes ‘driving’ the differences in IQ test scores?
Richardson (2017: 3) writes:
In summary, either directly or indirectly, IQ and related tests are calibrated against social class background, and score differences are inevitably consequences of that social stratification to some extent. Through that calibration, they will also correlate with any genetic cline within the social strata. Whether or not, and to what degree, the tests also measure “intelligence” remains debateable because test validity has been indirect and circular. … Such circularity is also reflected in correlations between IQ and adult occupational levels, income, wealth, and so on. As education largely determines the entry level to the job market, correlations between IQ and occupation are, again, at least partly, self-fullfilling. … CA [cognitive ability], as measured by IQ-type tests, is intrinsically inter-twined with social stratification, and its associated genetic background, by the very nature of the tests.
This, again, falls back on the non-existent construct validity that IQ tests have. Construct validity “defines how well a test or experiment measures up to its claims.” No such construct validity exists for IQ tests. If breathalyzers didn’t test someone’s fitness to drive, would they still be a good measure? If they had no construct validity, if there was no biological model to calibrate the breathalyzer against, would we still accept it as a realistic model to test people against and judge their fitness to drive? Still yet another definition of construct validity comes from Strauss and Smith (2009) who write that psychological constructs are “validated by testing whether they relate to measures of other constructs as specified by theory.” No such biological model exists for IQ; why expect some type of biological model like this when there are other perfectly well-reasoned response to how and why individuals differ in IQ test scores (Richardson, 2002)?
The normal distribution is forced, which IQ-ists claim to know. Richardson (1998) notes that Jensen “noted how ‘every item is carefully edited and selected on the basis of technical procedures known as “item analysis”, based on tryouts of the items on large samples and the test’s target population’ (1980:145).” These ‘tryouts’ are what force the normal curve, and no matter how ‘technical’ the procedures are, there are still huge biases, which then make people draw huge assumptions, again, based on who is or is not intelligent.
Simon (1997: 204) writes (emphasis mine):
There is another, and completely irrefutable, reason why the bell-shaped curve proves nothing at all in the context of H-M’s book: The makers of IQ tests consciously force the test into such a form that it produces this curve, for ease of statistical analysis. The first versions of such tests invariably produce odd-shaped distributions. The test-makers then subtract and add questions to find those that discriminate well between more-successful and less-successful test-takers. For this reason alone the bell-shaped IQ curve must be considered an artifact rather than a fact, and therefore tells us nothing about human nature or human society.
Simon (1997) rightly notes, as I have numerous times, how biased (against certain classes) the excision of items during their analysis and selection (of test items). This shows that both the so-called normal curve and the outcomes they supposedly show aren’t “natural”, but are chosen and forced by the test constructors and their biased and presuppositions about what “intelligence” is. John Raven, for example, also stated in his personal notes how he used his “intuition” to rank-order items, while others further noted that there was no “underlying processing theory” to guide item difficulty and retain old items on newer versions of the test (Carpenter, Just, and Shell: 408).
In sum, IQ tests are constructed to fit a normal curve on the basis of an assumption of a normal distribution, and on the presupposed basis of who is or is not ‘intelligent’ (whatever that means). The BG method needs to assume that IQ is a quantitative trait which exhibits a normal distribution. IQ is assumed to be like height, or weight, but which physiological process in the body does it mimick? I have argued that there is no physiological basis to ‘IQ’ or what they test and that they can be explained not by biology, but through test construction. I wonder what the distributions of IQ test scores would look like without forced normal distributions? Since it is assumed that IQ tests something directly measurable—like height and weight as is normally used—then they must fall on a normal distribution, which all other measurable psychological traits do not show (Micceri, 1989; Buzsaki and Mizseki, 2014).
Some may argue that ‘they know this’ (they being psychometricians). However, ‘they’ must know that most of their assumptions and conclusions about ‘good and bad genes’ lie on the huge assumption of the normal distribution. IQ test scores do not show a normal distribution, they were designed to create it. The fact that most psychological traits show a strong skew to one side and so that’s why a normal distribution is forced is meaningless. The fact of the matter is, just through how the tests are constructed means that we should be cautious as to what these tests test with the assumptions that we currently have about them.
Action Video Games, Reaction Time, and Cognitive Ability
1350 words
Research into neural plasticity has been fruitful the past few decades. However, people like Steven Pinker in his book The Blank Slate attempt to undermine the effects of neural plasticity in regards to TBI and IQ, for instance. However, the plasticity of our brains is how our brains evolved (Skoyles and Sagan, 2002). So since our brains are so plastic, then doing certain tasks may help in terms of ‘processing speed’, reaction time and overall cognitive ability, right?
Science Daily reported on a new meta-analysis that took 15 years to complete that looked at how action video games affect reaction time and cognitive performance. What they found was something that I have talked about a bit: that playing these types of games increases one’s reaction time and even their cognitive ability. Unfortunately, the paper is not on Sci-Hub yet, but when it is released on Sci-Hub I will go more in depth on it.
The authors (Benoit et al, 2017) looked at 15 years of papers on action video games and cognitive performance from the year 2000-2015. They focused on war and shooting video games to gauge whether or not there was a causal effect on action video game playing and cognitive performance. They got two meta-analyses out of all of the research they did.
They studied 8,790 people between the ages of 6-40 and gave them a battery of cognitive tests. These tests included spatial attention tasks as well as testing how well one could multi-task while changing their plans in-line with the rules of the game. “It was found that the cognition of gamers was better by one-half of a standard deviation compared to non-gamers.” Though this meta-analysis failed to answer one question: do people who play games have higher cognitive ability or do people with higher cognitive ability play more games? The classic chicken-and-the-egg problem.
They then looked at other studies of 2,883 individuals and partitioned them into 2 groups: groups of people who played action games like war and shooter games whereas the second group played games like SIMS, Tetris and Puzzle (I would loosely term these strategy games as well). They found that both groups played for 8 hours per week, netting 50 hours of gameplay over 12 weeks.
What they found was that the results were overwhelmingly in favor of war and shooting games improving cognition. The interesting thing about these analyses was that it took years to get the data and it is from all over the world, so it doesn’t only hold in America, for instance. Though, in the abstract of the paper (all I have access to at the moment) Benoit et al (2017) write:
Publication bias remains, however, a threat with average effects in the published literature estimated to be 30% larger than in the full literature. As a result, we encourage the field to conduct larger cohort studies and more intervention studies, especially those with more than 30 hours of training.
This is in-line with numerous other papers on the matter of cognitive abilities and action video games. Green and Bavelier (2007) showed that video game players “could tolerate smaller target-distractor distances” whereas “similar effects were observed in non-video-game players who were trained on an action video game; this result verifies a causative relationship between video-game play and augmented spatial resolution.” They found that action video games ‘sharpened vision’ by up to 20 percent. Green and Bavelier (2012) also show that playing action video games may enhance the ability to learn new tasks and that what is learned from playing these types of games “transfers well beyond the training task.”
Green and Bavelier (2003) show that playing action video games showed better visual attention in comparison to those who did not play games. Even those who did not game saw improvement in visual attention which, again, shows that video games have an actual causal effect on these phenomena and it’s not just ‘people with higher cognitive ability choosing to play video games’. (See also Murphy and Spencer, 2009 who show that “There were no other group differences for any task suggesting a limited role for video game playing in the modification of visual attention.“)
Dye, Green, and Bavelier (2009) show that action video games increase reaction time (RT). Variables like videogame-playing when testing cognitive abilities are a huge confound, as can be seen, since people who play action video games have a quicker reaction time than those who do not—which, as I’ve shown, has a causal relationship with game playing since even the controls who did not play action games saw an increase in their RT. Achtman, Green, and Bavelier (2008) show yet again that action video game playing enhances visual attention and overall visual processing.
Green (2008: iii-iv) in an unpublished doctoral dissertation (the first link on Google should be the dissertation) showed the video game players “acquire sensory information more rapidly than NVGPs [non-videogame players]”.
Applebaum et al (2013) showed that action game playing “may be related to enhancements in the initial sensitivity to visual stimuli, but not to a greater retention of information in iconic memory buffers.” Bejjanki et al (2014) show that action video game playing “establish[es] … the development of enhanced perceptual templates following action game play.” Cardoso-Leite and Bavelier (2014) show that video games enhance “behavior in domains as varied as perception, attention, task switching, or mental rotation.”
Boot, Blakely, and Simons (2011) show that there may be a ‘file-drawer effect’ (publication bias)in terms of action video games increasing cognition, which Benoit et al (2017) acknowledge and push for more open studies.
Unsworth et al (2015) state that “nearly all of the relations between video-game experience and cognitive abilities were near zero.” So, there are numerous studies both for and against this (most of the studies for this being done by Green and Bavelier), and so this meta-analysis done by Benoit et al (2017) may finally begin to answer the question: Does playing action video games increase cognitive ability, increase visual attention and increase reaction time? The results of this new meta-analysis suggest yes, and it may have implications for IQ testing.
Richardson and Norgate (2014) in their paper Does IQ Really Predict Job Performance? state that there are numerous other reasons why some individuals may have slower RTs, one of the variables being action video game playing, along with anxiety, motivation, and familiarity with the equipment used, meaning that if one is experienced in video game playing—action games specifically—it may cause differences between individuals that do not come down to ‘processing speed’ or native ability, as is usually claimed (and with such low correlations of .2-.3 for reaction time and IQ, other factors must mediate the relationship that are not genetic in nature).
Now, let’s say the effect is as large as Benoit et al (2017) say it is at one-third of a SD. Would this mean that one would need to attempt to control for video game playing while testing, say, IQ or RT? I believe the answer is definitely pointing in that direction because it is clear—with the mounting evidence—that action video games can reduce RT and thusly confound certain tests. Action video game playing may be a pretty large confound in terms of the outcomes of IQ tests if these new meta-analyses from Benoit et al (2017) hold up. If this does hold up and playing action video games does affect both RT and cognitive ability at one-third of an SD (about 5 points), then the case can be made that this must be controlled for due to confounding the relationship.
In sum, if these effects from this new meta-analysis hold and can be replicated by other studies, then that’s a whole other variable that needs to be accounted for when testing IQ and RT. RT is a complicated variable and, according to Khodaddi et al (2014) “The relationship between reaction time and IQ is too complicated and revealing a significant correlation depends on various variables (e.g. methodology, data analysis, instrument etc.).” This, is in my view, one reason why RT should be tossed out as a ‘predictor of g‘ (whatever that is), as it is not a reliable measure and does not ‘test’ what it is purported to test.
Find the Genes: Testosterone Version
1600 words
Testosterone has a similar heritability to IQ (between .4 and .6; Harris, Vernon, and Boomsma, 1998; Travison et al, 2014). To most, this would imply a significant effect of genes on the production of testosterone and therefore we should find a lot of SNPs that affect the production of testosterone. However, testosterone production is much more complicated than that. In this article, I will talk about testosterone production and discuss two studies which purport to show a few SNPs associated with testosterone. Now, this doesn’t mean that the SNPs cause high/low testosterone, just that they were associated. I will then speak briefly on the ‘IQ SNPs’ and compare it to ‘testosterone SNPs’.
Testosterone SNPs?
Complex traits are ‘controlled’ by many genes and environmental factors (Garland Jr., Zhao, and Saltzman, 2016). Testosterone is a complex trait, so along with the heritability of testosterone being .4 to .6, there must be many genes of small effect that influence testosterone, just like they supposedly do for IQ. This is obviously wrong for testosterone, which I will explain below.
Back in 2011 it was reported that genetic markers were discovered ‘for’ testosterone, estrogen, and SHGB production, while showing that genetic variants in the SHGB locus, located on the X chromosome, were associated with substantial testosterone variation and increased the risk of low testosterone (important to keep in mind) (Ohlsson et al, 2011). The study was done since low testosterone is linked to numerous maladies. Low testosterone is related to cardiovascular risk (Maggio and Basaria, 2009), insulin sensitivity (Pitteloud et al, 2005; Grossman et al, 2008), metabolic syndrome (Salam, Kshetrimayum, and Keisam, 2012; Tsuijimora et al, 2013), heart attack (Daka et al, 2015), elevated risk of dementia in older men (Carcaillon et al, 2014), muscle loss (Yuki et al, 2013), and stroke and ischemic attack (Yeap et al, 2009). So this is a very important study to understand the genetic determinants of low serum testosterone.
Ohlsson et al (2011) conducted a meta-analysis of GWASs, using a sample of 14,429 ‘Caucasian’ men. To be brief, they discovered two SNPs associated with testosterone by performing a GWAS of serum testosterone concentrations on 2 million SNPs on over 8,000 ‘Caucasians’. The strongest associated SNP discovered was rs12150660 was associated with low testosterone in this analysis, as well as in a study of Han Chinese, but it is rare along with rs5934505 being associated with an increased risk of low testosterone(Chen et al, 2016). Chen et al (2016) also caution that their results need replication (but I will show that it is meaningless due to how testosterone is produced in the body).
Ohlsson et al (2011) also found the same associations with the same two SNPs, along with rs6258 which affect how testosterone binds to SHGB. Ohlsson et al (2011) also validated their results: “To validate the independence of these two SNPs, conditional meta-analysis of the discovery cohorts including both rs12150660 and rs6258 in an additive genetic linear model adjusted for covariates was calculated.” Both SNPs were independently associated with low serum testosterone in men (less than 300ng/dl which is in the lower range of the new testosterone guidelines that just went into effect back in July). Men who had 3 or more of these SNPs were 6.5 times more likely to have lower testosterone.
Ohlsson et al (2011) conclude that they discovered genetic variants in the SHGB locus and X chromosome that significantly affect serum testosterone production in males (noting that it’s only on ‘Caucasians’ so this cannot be extrapolated to other races). It’s worth noting that, as can be seen, these SNPs are not really associated with variation in the normal range, but near the lower end of the normal range in which people would then need to seek medical help for a possible condition they may have.
In infant males, no SNPs were significantly associated with salivary testosterone levels, and the same was seen for infant females. Individual variation in salivary testosterone levels during mini-puberty (Kurtoglu and Bastug, 2014) were explained by environmental factors, not SNPs (Xia et al, 2014). They also replicated Carmaschi et al (2010) who also showed that environmental factors influence testosterone more than genetic factors in infancy. There is a direct correlation between salivary testosterone levels and free serum testosterone (Wang et al, 1981; Johnson, Joplin, and Burin, 1987), so free serum testosterone was indirectly tested.
This is interesting because, as I’ve noted here numerous times, testosterone is indirectly controlled by DNA, and it can be raised or lowered due to numerous environmental variables (Mazur and Booth, 1998; Mazur, 2016), such as marriage (Gray et al, 2002; Burnham et al, 2003; Gray, 2011; Pollet, Cobey, and van der Meij, 2013; Farrelly et al, 2015; Holmboe et al, 2017), having children (Gray et al, 2002; Gray et al, 2006; Gettler et al, 2011); to obesity (Palmer et al, 2012; Mazur et al, 2013; Fui, Dupuis, and Grossman, 2014; Jayaraman, Lent-Schochet, and Pike, 2014; Saxbe et al, 2017) smoking is not clearly related to testosterone (Zhao et al, 2016), and high-carb diets decrease testosterone (Silva, 2014). Though, most testosterone decline can be ameliorated with environmental interventions (Shi et al, 2013), it’s not a foregone conclusion that testosterone will sharply decrease around age 25-30.
Studies on ‘testosterone genes’ only show associations, not causes, genes don’t directly cause testosterone production, it is indirectly controlled by DNA, as I will explain below. These studies on the numerous environmental variables that decrease testosterone is proof enough of the huge effects of environment on testosterone production and synthesis.
How testosterone is produced in the body
There are five simple steps to testosterone production: 1) DNA codes for mRNA; 2) mRNA codes for the synthesis of an enzyme in the cytoplasm; 3) luteinizing hormone stimulates the production of another messenger in the cell when testosterone is needed; 4) this second messenger activates the enzyme; 5) the enzyme then converts cholesterol to testosterone (Leydig cells produce testosterone in the presence of luteinizing hormone) (Saladin, 2010: 137). Testosterone is a steroid and so there are no ‘genes for’ testosterone.
Cells in the testes enzymatically convert cholesterol into the steroid hormone testosterone. Quoting Saladin (2010: 137):
But to make it [testosterone], a cell of the testis takes in cholesterol and enzymatically converts it to testosterone. This can occur only if the genes for the enzymes are active. Yet a further implication of this is that genes may greatly affect such complex outcomes as behavior, since testosterone strongly influences such behaviors as aggression and sex drive. [RR: Most may know that I strongly disagree with the fact that testosterone *causes* aggression, see Archer, Graham-Kevan and Davies, 2005.] In short, DNA codes only for RNA and protein synthesis, yet it indirectly controls the synthesis of a much wider range of substances concerned with all aspects of anatomy, physiology, and behavior.
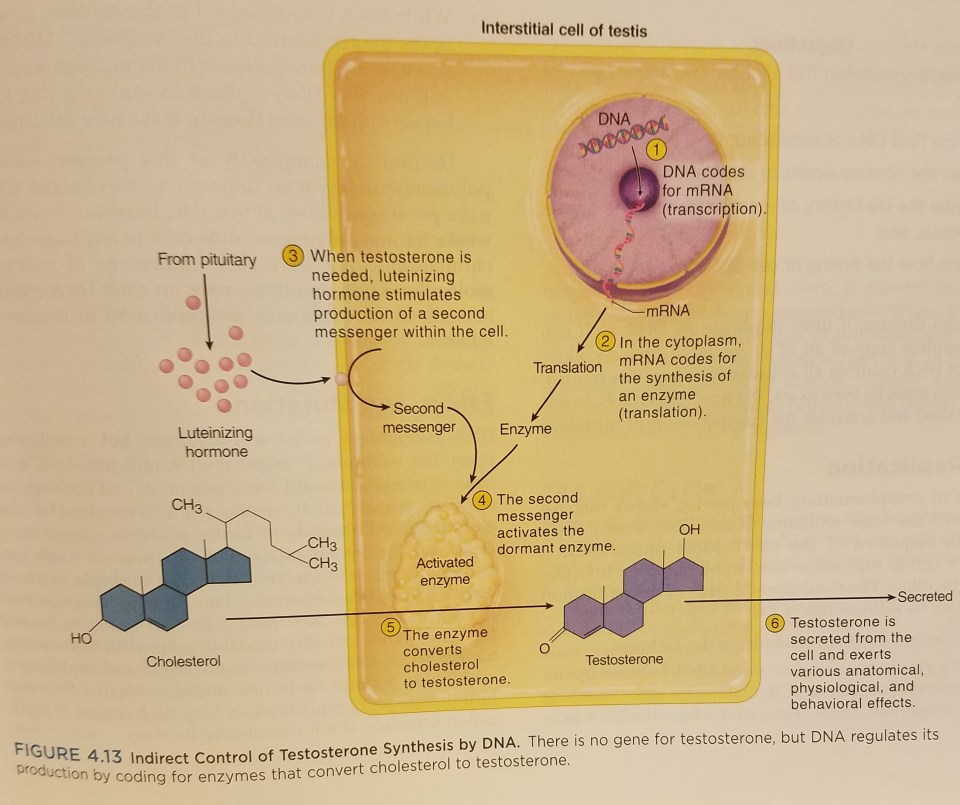
(Figure from Saladin (2010: 137; Anatomy and Physiology: The Unity of Form and Function)
Genes only code for RNA and protein synthesis, and thusly, genes do not *cause* testosterone production. This is a misconception most people have; if it’s a human trait, then it must be controlled by genes, ultimately, not proximately as can be seen, and is already known in biology. Genes, on their own, are not causes but passive templates (Noble, 2008; Noble, 2011; Krimsky, 2013; Noble, 2013; Also read Exploring Genetic Causation in Biology). This is something that people need to understand; genes on their own do nothing until they are activated by the system.
What does this have to do with ‘IQ genes’?
My logic here is very simple: 1) Testosterone has the same heritability range as IQ. 2) One would assume—like is done with IQ—that since testosterone is a complex trait that it must be controlled by ‘many genes of small effect’. 3) Therefore, since I showed that there are no ‘genes for’ testosterone and only ‘associations’ (which could most probably be mediated by environmental interventions) with low testosterone, may the same hold true for ‘IQ genes/SNPS’? These testosterone SNPs I talked about from Ohlsson et al (2011) were associated with low testosterone. These ‘IQ SNP’ studies (Davies et al, 2017; Hill et al, 2017; Savage et al, 2017) are the same—except we have an actual idea of how testosterone is produced in the body, we know that DNA is indirectly controlling its production, and, most importantly, there is/are no ‘gene[s] for’ testosterone.
Conclusion
Testosterone has the same heritability range as IQ, is a complex trait like IQ, but, unlike how IQ is purported to be, it [testosterone] is not controlled by genes; only indirectly. My reasoning for using this example is simple: something has a moderate to high heritability, and so most would assume that ‘numerous genes of small effect’ would have an influence on testosterone production. This, as I have shown, is false. It’s also important to note that Ohlsson et al (2011) showed associated SNPs in regards to low testosterone—not testosterone levels in the normal range. Of course, only when physiological values are outside of the normal range will we notice any difference between men, and only then will we find—however small—genetic differences between men with normal and low levels of testosterone (I wouldn’t be surprised if lifestyle factors explained the lower testosterone, but we’ll never know that in regards to this study).
Testosterone production is a real, measurable physiologic process, as is the hormone itself; which is not unlike the so-called physiologic process that ‘g’ is supposed to be, which does not mimic any known physiologic process in the body, which is covered with unscientific metaphors like ‘power’ and ‘energy’ and so on. This example, in my opinion, is important for this debate. Sure, Ohlsson et al (2011) found a few SNPs associated with low testosterone. That’s besides the point. They are only associated with low testosterone; they do not cause low testosterone. So, I assert, these so-called associated SNPs do not cause differences in IQ test scores; just because they’re ‘associated’ doesn’t mean they ’cause’ the differences in the trait in question. (See Noble, 2008; Noble, 2011; Krimsky, 2013; Noble, 2013.) The testosterone analogy that I made here buttresses my point due to the similarities (it is a complex trait with high heritability) with IQ.
