
Should We End Sex Segregation in Sports? Should Athletes Be Assessed by Anatomy And Physiology?
1400 words
An opinion piece by sociologist Roslyn Kerr, senior lecturer in sociology of sport, from Lincoln University wrote an article on January 18th for The Conversation titled Why it might be time to eradicate sex segregation in sports where she argues against sex segregation in sports. She does publish articles on sports history, leisure studies and sports management and used to be a gymnast so she should have good knowledge—perhaps better than the general public—on anatomy and physiology and how they interact during elite sporting performances. Though is there anything to the argument she provides in her article? Maybe.
The paper is pretty good, though it, of course, uses sociological terms and cites feminist theorists talking about gender binaries in sports and how they’re not ‘fair’. One thing continously brought up in the paper is how there is no way to discern sex regarding sporting competitions (Simpson et al, 1993; Dickinson et al, 2002; Heggie, 2010), with even chromosome-based testing being thrown out (Elsas et al, 2000). which can be seen with the Olympics “still struggling to define gender“. They state that women are put through humiliating tests to discern their sex.
They use this to buttress their own arguments which are based off of what bodies of disables athletes did: whether or not one competed in a particular sport was not on their disability, per se, but the functionality of their own bodies. As an example, sporting bodies used to group people with, say, a similar spinal injury even though they had different physical abilities. Call me crazy, but I most definitely see the logic that these authors are getting at, and not only because I ruminated on something similar back in the summer in an article on transgendered athletes in sports, writing:
This then brings up some interesting implications. Should we segregate competitions by race since the races have strength and weaknesses due to biology and anatomy, such as somatype? It’s an interesting question to consider, but I think we can all agree on one thing: Women should compete with women, and men should compete with men. Thus, transgenders should compete with transgenders.
Of course I posed the question regarding different races since they have different strengths and weaknesses on average due to evolution in different environments. Kerr and Obel (2017) conclude (pg 13):
Numerous authors have noted that the current two-sex classification system is problematic. They argued that it does not include all bodies, such as intersex bodies, and more importantly, does not work to produce fair competition. Instead, some argued that other traits that we know influence sporting success should be used to classify bodies. In this article, we extended this idea through using the ANT concepts of assemblage and black box. Specifically, we interpreted the current understanding of the body that sex segregation is based on as a black box that assumes the constant superiority of the male body over the female. But we argued that with the body understood as an assemblage, this classification could be reassembled so that this black box is no longer given. Instead we argued that by identifying the multiple traits that make up the assemblage of sporting success, sex classification becomes irrelevant and that it is these traits that we should use to classify athletes rather than sex. Drawing on the example of disability sport we noted that the black box of a medical label was undone and replaced with an emphasis on functionality with different effects for each sport. This change had the effect of undoing rigid medical disability label and enabling athletes’ bodies to be viewed as assemblages consisting of various functional and potentially changing physical abilities. We used this discussion to propose a model of classified that eliminated the need for sex segregation and instead used physical measures such as LBM and VO2 capabilities to determine an athlete’s competitive class.
All of their other arguments aside that I disagree with in their paper (their use of ‘feminist theory’, gendered divisions, short discussions and quotes from other authors on the ‘power structure’ of males), I definitely see the logic here and, in my opinion, it makes sense. Anyway, those shortcomings aside, the actual argument of using anatomy and physiology and seeing which different parts work in concert to produce elite athletic performance in certain sports then having some kind of test, say, the Heath-Carter method for somatype (Wilmore, 1970) to a test of Vo2 max (Cureton et al, 1986) to even lean body mass (LBM).
Healy et al (2014) studied 693 elite athletes in a post-competition setting. They assesed testosterone, among other variables such as aerobic performance. They observed a difference of 10 of between men and women’s LBM and that it exclusively accounts for the “observed diffences in strength and aerobic performance seen between the sexes” while they conclude:
We have shown that despite differences in mean testosterone level between genders, there is complete overlap of the range of concentrations seen. This shows that the recent decision of the IOC and IAAF to limit participation in elite events to women with ‘normal’ serum testosterone is unsustainable.
Yes, this testosterone-influences-sports-performance is still ongoing. I’ve covered it a bit last year, and while I believe there is a link between testosterone and athletic ability and have provided some data and a few anecdotes from David Epstein, I do admit that the actual literature is scant with conclusive evidence that testosterone positively influences sport performance. Either way, if testosterone truly does infer an advantage then, of course, the model (which Kerr and Obel admit is simple at the moment) will need to be slightly revised. Arguments and citations can be found in this article written back in the summer on whether or not transgender MtFs should compete with women. This is also directly related to the MtF who dominated women a few months back.
Either way, the argument that once we better identify anatomic and physiologic causes for differences in certain sporting competition, this could, in theory, be used instead of sex segregation. I think it’s a good idea personally and to see how effective it could be there should be a trial run on it. Kerr and Obel state that it would make competition more ‘fair’. However, Sanchez et al, 2014 cite Murray (2010) who writes “fair sports competition does not require that athletes be equal in every imaginable respect.”
At the end of the day, what a lot of this rests on is whether or not testosterone infers athletic advantage at the elite level and there is considerable data for both sides. It’ll be interesting to see how the major sporting bodies handle the question of testosterone in sports and transgenders and hyperandrogenic females.
Personally, I think there may be something to Kerr and Obel’s arguments in their paper (feminist/patriarchy garbage aside) since it’s based on anatomy and physiology which is what we see on the field. However, it can also be argued that sex/gender is manifested in the brain which then infers other advantages/disadvantages in sports. Nonetheless, I think the argument in the paper is sound (the anatomy and physiology arguments only). For instance, we can look at one sport, say, 100 m dash, and we can say “OK, we know that sprinters have meso-ecto somatypes and that combined with the RR ACTN3 genotype, that confers elite athletic performance (Broos et al, 2016).” We could use those two variables along with leg length, foot length etc and then we can test—both in the lab and on the field—which variables infer advantages in certain sports. Another sport we can think of is swimming. Higher levels of body fat with wide clavicles and chest cavity are more conducive to swimming success. We could use those types of variables for swimming and so on.
Of course, this method may not work or it may only work in theory but not work in practice. Using lean body mass, Vo2 max etc etc based on which sport is in question may be better than using the ‘sex binary’, since some women (trust me, I’ve trained hundreds) would be able to compete head-to-head with men and, if for nothing else, it’d be good entertainment.
However, in my opinion, the logic on using anatomy and physiology instead of sex to segregate in sports is intriguing and, if nothing else, would finally give feminists (and non-feminists) the ‘equality’ they ask for.
Race, Testosterone, Aggression, and Prostate Cancer
4050 words
Race, aggression, and prostate cancer are all linked, with some believing that race is the cause of higher testosterone which then causes aggression and higher rates of crime along with maladies such as prostate cancer. These claims have long been put to bed, with a wide range of large analyses.
The testosterone debate regarding prostate cancer has been raging for decades and we have made good strides in understanding the etiology of prostate cancer and how it manifests. The same holds true for aggression. But does testosterone hold the key to understanding aggression, prostate cancer and does race dictate group levels of the hormone which then would explain some of the disparities between groups and individuals of certain groups?
Prostate cancer
For decades it was believed that heightened levels of testosterone caused prostate cancer. Most of the theories to this day still hold that large amounts of androgens, like testosterone and it’s metabolic byproduct dihydrotestosterone, are the two many factors that drive the proliferation of cells and therefore, if a male is exposed to higher levels of testosterone throughout their lives then they are at a high risk of prostate cancer compared to a man with low testosterone levels, so the story goes.
In 1986 Ronald Ross set out to test a hypothesis: that black males were exposed to more testosterone in the womb and this then drove their higher rates of prostate cancer later in life. He reportedly discovered that blacks, after controlling for confounds, had 15 percent higher testosterone than whites which may be the cause of differential prostate cancer mortality between the two races (Ross et al, 1986) This is told in a 1997 editorial by Hugh McIntosh. First, the fact that black males were supposedly exposed to more testosterone in the womb is brought up. I am aware of one paper discussing higher levels of testosterone in black women compared to white women (Perry et al, 1996). Though, I’ve shown that black women don’t have high levels of testosterone, not higher than white women, anyway (see Mazur, 2016 for discussion). (Yes I changed my view on black women and testosterone, stop saying that they have high levels of testosterone it’s just not true. I see people still link to that article despite the long disclaimer at the top.)
Alvarado (2013) discusses Ross et al (1986), Ellis and Nyborg (1992) (which I also discussed here along with Ross et al) and other papers discussing the supposed higher testosterone of blacks when compared to whites and attempts to use a life history framework to explain higher incidences of prostate cancer in black males. He first notes that nutritional status influences testosterone production which should be no surprise to anyone. He brings up some points I agree with and some I do not. For instance, he states that differences in nutrition could explain differences in testosterone between Western and non-Western people (I agree), but that this has no effect within Western countries (which is incorrect as I’ll get to later).
He also states that ancestry isn’t related to prostate cancer, writing “In summation, ancestry does not adequately explain variation among ethnic groups with higher or lower testosterone levels, nor does it appear to explain variation among ethnic groups with high or low prostate cancer rates. This calls into question the efficacy of a disease model that is unable to predict either deleterious or protective effects.”
He then states that SES is negatively correlated with prostate cancer rates, and that numerous papers show that people with low SES have higher rates of prostate cancer mortality which makes sense, since people in a lower economic class would have less access to and a chance to get good medical care to identify problems such as prostate cancer, including prostate biopsies and checkups to identify the condition.
He finally discusses the challenge hypothesis and prostate cancer risk. He cites studies by Mazur and Booth (who I’ve cited in the past in numerous articles) as evidence that, as most know, black-majority areas have more crime which would then cause higher levels of testosterone production. He cites Mazur’s old papers showing that low-class men, no matter if they’re white or black, had heightened levels of testosterone and that college-educated men did not, which implies that the social environment can and does elevate testosterone levels and can keep them heightened. Alvarado concludes this section writing: “Among Westernized men who have energetic resources to support the metabolic costs associated with elevated testosterone, there is evidence that being exposed to a higher frequency of aggressive challenges can result in chronically elevated testosterone levels. If living in an aggressive social environment contributes to prostate cancer disparities, this has important implications for prevention and risk stratification.” He’s not really wrong but on what he is wrong I will discuss later on this section. It’s false that testosterone causes prostate cancer so some of this thesis is incorrect.
I rebutted Ross et al (1986) December of last year. The study was hugely flawed and, yet, still gets cited to this day including by Alvarado (2013) as the main point of his thesis. However, perhaps most importantly, the assay times were done ‘when it was convenient’ for the students which were between 10 am and 3 pm. To not get any wacky readings one most assay the individuals as close to 8:30 am as possible. Furthermore, they did not control for waist circumference which is another huge confound. Lastly, the sample was extremely small (50 blacks and 50 whites) and done on a nonrepresentative sample (college students). I don’t think anyone can honestly cite this paper as any evidence for blacks having higher levels of testosterone or testosterone causing prostate cancer because it just doesn’t do that. (Read Race, Testosterone and Prostate Cancer for more information.)
What may explain prostate cancer rates if not for differences in testosterone like has been hypothesized for decades? Well, as I have argued, diet explains a lot of the variation between races. The etiology of prostate cancer is not known (ACA, 2016) but we know that it’s not testosterone and that diet plays a large role in its acquisition. Due to their dark skin, they need more sunlight than do whites to synthesize the same amount of vitamin D, and low levels of vitamin D in blacks are strongly related to prostate cancer (Harris, 2006). Murphy et al (2014) even showed, through biopsies, that black American men had higher rates of prostate cancer if they had lower levels of vitamin D. Lower concentrations of vitamin D in blacks compared to whites due to dark pigmentation which causes reduced vitamin D photoproduction and may also account for “much of the unexplained survival disparity after consideration of such factors as SES, state at diagnosis and treatment” (Grant and Peiris, 2012).
Testosterone
As mentioned above, testosterone is assumed to be higher in certain races compared to others (based on flawed studies) which then supposedly exacerbates prostate cancer. However, as can be seen above, a lot of assumptions go into the testosterone-prostate cancer hypothesis which is just false. So if the assumptions are false about testosterone, mainly regarding racial differences in the hormone and then what the hormone actually does, then most of their claims can be disregarded.
Perhaps the biggest problem is that Ross et al is a 32-year-old paper (which still gets cited favorably despite its huge flaws) while our understanding of the hormone and its physiology has made considerable progress in that time frame. So it’s in fact not so weird to see papers like this that say “Prostate cancer appears to be unrelated related to endogenous testosterone levels” (Boyle et al, 2016). Other papers also show the same thing, that testosterone is not related to prostate cancer (Stattin et al, 2004; Michaud, Billups, and Partin, 2015). This kills a lot of theories and hypotheses, especially regarding racial differences in prostate cancer acquisition and mortality. So, what this shows is that even if blacks did have 15 percent higher serum testosterone than whites as Ross et al, Rushton, Lynn, Templer, et al believed then it wouldn’t cause higher levels of prostate cancer (nor aggression, which I’ll get into later).
How high is testosterone in black males compared to white males? People may attempt to cite papers like the 32-year-old paper by Ross et al, though as I’ve discussed numerous times the paper is highly flawed and should therefore not be cited. Either way, levels are not as high as people believe and meta-analyses and actual nationally representative samples (not convenience college samples) show low to no difference, and even the low difference wouldn’t explain any health disparities.
One of the best papers on this matter of racial differences in testosterone is Richard et al (2014). They meta-analyzed 15 studies and concluded that the “racial differences [range] from 2.5 to 4.9 percent” but “this modest difference is unlikely to explain racial differences in disease risk.” This shows that testosterone isn’t as high in blacks as is popularly misconceived, and that, as I will show below, it wouldn’t even cause higher rates of aggression and therefore criminal behavior. (Rohrmann et al 2007 show no difference in testosterone between black and white males in a nationally representative sample after controlling for lifestyle and anthropometric variables. Whereas Mazur, 2009 shows that blacks have higher levels of testosterone due to low marriage rates and lower levels of adiposity, while be found a .39 ng/ml difference between blacks and whites aged 20 to 60. Is this supposed to explain crime, aggression, and prostate cancer?)
However, as I’ve noted last year (and as Alvarado, 2013 did as well), young black males with low education have higher levels of testosterone which is not noticed in black males of the same age group but with more education (Mazur, 2016). Since blacks of a similar age group have lower levels of testosterone but are more highly educated then this is a clue that education drives aggression/testosterone/violent behavior and not that testosterone drives it.
Mazur (2016) also replicated Assari, Caldwell, and Zimmerman’s (2014) finding that “Our model in the male sample suggests that males with higher levels of education has lower aggressive behaviors. Among males, testosterone was not associated with aggressive behaviors.” I know this is hard for many to swallow that testosterone doesn’t lead to aggressive behavior in men, but I’ll cover that in the last and final section.
So it’s clear that the myth that Rushton, Lynn, Templer, Kanazawa, et al pushed regarding hormonal differences between the races are false. It’s also with noting, as I did in my response to Rushton on r/K selection theory, that the r/K model is literally predicated on 1) testosterone differences between races being real and in the direction that Rushton and Lynn want because they cite the highly flawed Ross et al (1986) and 2) testosterone does not cause higher levels of aggression (which I’ll show below) which then lead to higher rates of crime along with higher rates of incarceration.
A blogger who goes by the name of ethnicmuse did an analysis of numerous testosterone papers and he found:
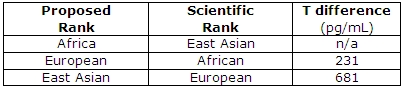 Which, of course, goes against a ton of HBD theory, that is, if testosterone did what HBDers believed it does (it doesn’t). This is what it comes down to: blacks don’t have higher levels of testosterone than whites and testosterone doesn’t cause aggression nor prostate cancer so even if this relationship was in the direction that Rushton et al assert then it still wouldn’t cause any of the explanatory variables they discuss.
Which, of course, goes against a ton of HBD theory, that is, if testosterone did what HBDers believed it does (it doesn’t). This is what it comes down to: blacks don’t have higher levels of testosterone than whites and testosterone doesn’t cause aggression nor prostate cancer so even if this relationship was in the direction that Rushton et al assert then it still wouldn’t cause any of the explanatory variables they discuss.
Last year Lee Ellis published a paper outlining his ENA theory (Ellis, 2017). I responded to the paper and pointed out what he got right and wrong. He discussed strength (blacks aren’t stronger than whites due to body type and physiology, but excel in other areas); circulating testosterone, umbilical cord testosterone exposure; bone density and crime; penis size, race, and crime (Rushton’s 1997 claims on penis size don’t ‘size up’ to the literature as I’ve shown two times); prostate-specific antigens, race, and prostate cancer; CAG repeats; intelligence and education and ‘intelligence’; and prenatal androgen exposure. His theory has large holes and doesn’t line up in some places, as he himself admits in his paper. He, as expected, cites Ross et al (1986) favorably in his analysis.
Testosterone can’t explain all of these differences, no matter if it’s prenatal androgen exposure or not, and a difference of 2.5 to 4.9 percent between blacks and whites regarding testosterone (Richard et al, 2014) won’t explain differences in crime, aggression, nor prostate cancer.
Other authors have attempted to also implicate testosterone as a major player in a wide range of evolutionary theories (Lynn, 1990; Rushton, 1997; Rushton, 1999; Hart, 2007; Rushton and Templer, 2012; Ellis, 2017). However, as can be seen by digging into this literature, these claims are not true and therefore we can discard the conclusions come to by the aforementioned authors since they’re based on false premises (testosterone being a cause for aggression, crime, and prostate cancer and r/K meaning anything to human races, it doesn’t)
Finally, to conclude this section, does testosterone explain racial differences in crime? No, racial differences in testosterone, however small, cannot be responsible for the crime gap between blacks and whites.
Testosterone and aggression
Testosterone and aggression, are they linked? Can testosterone tell us anything about individual differences in aggressive behavior? Surprisingly for most, the answer seems to be a resounding no. One example is the castration of males. Does it completely take away the urge to act aggressively? No, it does not. What is shown when sex offenders are castrated is that their levels of aggression decrease, but importantly, they do not decrease to 0. Robert Sapolsky writes on page 96 of his book Behave: The Biology of Humans at Our Best and Worst (2017) (pg 96):
… the more experience a male has being aggressive prior to castration, the more aggression continues afterward. In other words, the less his being aggressive in the future requires testosterone and the more it’s a function of social learning.
He also writes (pg 96-97):
On to the next issue that lessens the primacy of testosterone: What do individual levels of testosterone have to do with aggression? If one person higher testosterone levels than another, or higher levels this week than last, are they more likely to be aggressive?
Initially the answer seemed to be yes, as studies showed correlation between individual differences in testosterone levels and levels of aggression. In a typical study, higher testosterone levels would be observed in those male prisoners with higher rates of aggression. But being aggressive stimulates testosterone secretion; no wonder more aggressive individuals had higher levels. Such studies couldn’t disentangle chickens and eggs.
Thus, a better question is whether differences in testosterone levels among individuals predict who will be aggressive. And among birds, fish, mammals, and especially other primates, the answer is generally no. This has been studied extensively in humans, examining a variety of measures of aggression. And the answer is clear. To quote British endocrinologist John Archer in a definitive 2006 review, “There is a weak and inconsistent association between testosterone levels and aggression in [human] adults, and . . . administration of testosterone to volunteers typically does not increase aggression.” The brain doesn’t pay attention to testosterone levels within the normal range.
[…]
Thus, aggression is typically more about social learning than about testosterone, differing levels of testosterone generally can’t explain why some individuals are more aggressive than others.
Sapolsky also has a 1997 book of essays on human biology titled The Trouble With Testosterone: And Other Essays On The Biology Of The Human Predicament and he has a really good essay on testosterone titled Will Boys Just Be Boys? where he writes (pg 113 to 114):
Okay, suppose you note a correlation between levels of aggression and levels of testosterone among these normal males. This could be because (a) testosterone elevates aggression; (b) aggression elevates testosterone secretion; (c) neither causes the other. There’s a huge bias to assume option a while b is the answer. Study after study has shown that when you examine testosterone when males are first placed together in the social group, testosterone levels predict nothing about who is going to be aggressive. The subsequent behavioral differences drive the hormonal changes, not the other way around.
Because of a strong bias among certain scientists, it has taken do forever to convince them of this point.
[…]
As I said, it takes a lot of work to cure people of that physics envy, and to see interindividual differences in testosterone levels don’t predict subsequent differences in aggressive behavior among individuals. Similarly, fluctuations in testosterone within one individual over time do not predict subsequent changes in the levels of aggression in the one individual—get a hiccup in testosterone secretion one afternoon and that’s not when the guy goes postal.
And on page 115 writes:
You need some testosterone around for normal levels of aggressive behavior—zero levels after castration and down it usually goes; quadruple it (the sort of range generated in weight lifters abusing anabolic steroids), and aggression typically increases. But anywhere from roughly 20 percent of normal to twice normal and it’s all the same; the brain can’t distinguish among this wide range of basically normal values.
Weird…almost as if there is a wide range of ‘normal’ that is ‘built in’ to our homeodynamic physiology…
So here’s the point: differences in testosterone between individuals tell us nothing about individual differences in aggressive behavior; castration and replacement seems to show that, however broadly, testosterone is related to aggression “But that turns out to not be true either, and the implications of this are lost on most people the first thirty times you tell them about it. Which is why you’d better tell them about it thirty-one times, because it’s the most important part of this piece” (Sapolsky, 1997: 115).
Later in the essay, Sapolsky discusses a discusses 5 monkeys that were given time to form a hierarchy of 1 through 5. Number 3 can ‘throw his weight’ around with 4 and 5 but treads carefully around 1 and 2. He then states to take the third-ranking monkey and inject him with a ton of testosterone, and that when you check the behavioral data that he’d then be participating in more aggressive actions than before which would imply that the exogenous testosterone causes participation in more aggressive behavior. But it’s way more nuanced than that.
So even though small fluctuations in the levels of the hormone don’t seem to matter much, testosterone still causes aggression. But that would be wrong. Check out number 3 more closely. Is he now raining aggression and terror on any and all in the group, frothing in an androgenic glaze of indiscriminate violence. Not at all. He’s still judiciously kowtowing to numbers 1 and 2 but has simply become a total bastard to number 4 and 5. This is critical: testosterone isn’t causing aggression, it’s exaggerating the aggression that’s already there.
The correlation between testosterone and aggression is between .08 and .14 (Book, Starzyk, and Quinsey, 2001; Archer, Graham-Kevan, and Davies, 2005; Book and Quinsey, 2005). Therefore, along with all of the other evidence provided in this article, it seems that testosterone and aggression have a weak positive correlation, which buttresses the point that aggression concurrent increases in testosterone.
Sapolsky then goes on to discuss the amygdala’s role in fear processing. The amygdala has its influence on aggressive behavior through the stria terminalis, which is a bunch of neuronal connections. How the amygdala influences aggression is simple: bursts of electrical excitation called action potentials go up and down the stria terminalis which changes the hypothalamus. You can then inject testosterone right into the brain and will it cause the same action potentials that surge down the stria terminalis? No, it does not turn on the pathway at all. This only occurs only if the amygdala is already sending aggression-provoking action potentials down the stria terminalis with testosterone increasing the rate of action potentials you’re shortening the rest time between them. So it doesn’t turn on this pathway, it exaggerates the preexisting pattern, which is to say, it’s exaggerating the response to environmental triggers of what caused the amygdala to get excited in the first place.
He ends this essay writing (pg 119):
Testosterone is never going to tell us much about the suburban teenager who, in his after-school chess club, has developed a particularly aggressive style with his bishops. And it certainly isn’t going to tell us much about the teenager in some inner-city hellhole who has taken to mugging people. “Testosterone equals aggression” is inadequate for those who would offer a simple solution to the violent male—just decrease levels of those pesky steroids. And “testosterone equals aggression” is certainly inadequate for those who would offer a simple excuse: Boys will be boys and certain things in nature are inevitable. Violence is more complex than a single hormone. This is endocrinology for the bleeding heart liberal—our behavioral biology is usually meaningless outside of the context of social factors and the environment in which it occurs.
Injecting individuals with supraphysiological doses of testosterone as high as 200 and 600 mg per week does not cause heightened anger or aggression (Tricker et al, 1996; O’Connor et, 2002). This, too, is a large blow for the testosterone-induces-aggression hypothesis. Because aggressive behavior heightens testosterone, testosterone doesn’t heighten aggressive behavior. (This is the causality that has been looked for, and here it is. The causality is not in the other direction.) This tells us that we need to be put into situations for our aggression to rise and along with it, testosterone. I don’t even see how people could think that testosterone could cause aggression. It’s obvious that the environmental trigger needs to be there first in order for the body’s physiology to begin testosterone production in order to prepare for the stimulus that caused the heightened testosterone production. Once the trigger occurs, then it can and does stay heightened, especially in areas where dominance contests would be more likely to occur, which would be low-income areas (Mazur, 2006, 2016).
(Also read my response to Batrinos, 2012, my musings on testosterone and race, and my responses to Robert Lindsay and Sean Last.)
Lastly, one thing that gets on my nerves that people point to to attempt to show that testosterone and its derivatives cause violence, aggression etc is the myth of “roid rage” which is when an individual objects himself with testosterone, anabolic steroids or another banned substance, and then the individual becomes more aggressive as a result of more free-flowing testosterone in their bloodstream.
The problem here is that people believe what they hear on the media about steroids and testosterone, and they’re largely not true. One large analysis was done to see the effects of steroids and other illicit drug use on behavior, and what was found was that after controlling for other substance use “Our results suggest that it was not lifetime steroid use per se, but rather co-occurrring polysubstance abuse that most parsimoniously explains the relatively strong association of steroid use and interpersonal violence” (Lundholm et al, 2015). So after controlling for other drugs used, men who use steroids do not go to prison and be convicted of violence after other polysubstance use was controlled for, implying that is what’s driving interpersonal violence, not the substance abuse of steroids.
Conclusion
Numerous myths about testosterone have been propagated over the decades, which are still believed in the new millennium despite numerous other studies and arguments to the contrary. As can be seen, the myths that people believe about testosterone are easily debunked. Numerous papers (with better methodology than Ross et al) attest to the fact that testosterone levels aren’t as high as was believed decades ago between the races. Diet can explain a lot of the variation, especially vitamin D intake. Injecting men with supraphysiological doses of testosterone does not heighten anger nor aggression. It does not even heighten prostate cancer severity.
Racial differences in testosterone are also not as high as people would like to believe, there is even an opposite relationship with Asians having higher levels and whites having lower (which wouldn’t, on average, imply femininity) testosterone levels. So as can be seen, the attempted r/K explanations from Rushton et al don’t work out here. They’re just outright wrong on testosterone, as I’ve been arguing for a long while on this blog.
Testosterone doesn’t cause aggression, aggression causes heightened testosterone. It can be seen from studies of men who have been castrated that the more crime they committed before castration, the more crime they will commit after which implies a large effect of social learning on violent behavior. Either way, the alarmist attitudes of people regarding testosterone, as I have argued, are not needed because they’re largely myths.
Donald Trump, His Health, Diet, and ‘Good Genes’
Much has been written about the health of our President Donald Trump recently. He reportedly eats a meal at McDonald’s worth a whooping 2420 kcal in one sitting. It comes out to 112 grams of fat. His order, during his campaign trail, was 2 filet-o-fishes, two Big Macs and a chocolate shake. It’s been well documented that his diet is full of garbage, so you’d think he’d get a bad bill of health from his doctor, right?
Wrong.
The White House doctor recently stated that the President was in good health. How could he be in good health if he eats McDonald’s garbage? He is 6 foot 3 inches and weighs about 239 pounds giving him a BMI of 29.9—literally one point under obesity. He reportedly eats a lot of garbage ‘food’ and even reportedly drinks up to 12 cans of Diet Coke per day. It seems that Big Food is going to love our President even more because he gives them more free advertisements.
Renowned nutritionist Zoe Harcombe says “If true, this is a terrible diet” … “Twelve cans of Diet Coke contain far more than an adults daily recommended dose of caffeine. Consuming too much if it induces energy highs followed by crashing lows and potentially manic behaviour, which could explain his enraged tweets.” I’m not interested in attempting to ‘explain’ his behavior in a psychological manner due to his diet, though, I’m only interested in his overall health and how his diet does or does not affect it.
He also scored 30 out of 30 in the Montreal Cognitive Assessment which tests for mild cognitive dysfunctioning—the test being requested by Trump himself. However, two mental health experts state that the Montreal Cognitive Assessment is only used to determine whether or not further Alzheimer’s or cognitive screening is needed. Either way, they state that he should get a PET or MRI scan to assess any possible damage to his brain.
Interestingly, here is the President’s health report.



A few things to note here. Trump’s total cholesterol puts him into the borderline range. His triglycerides are at a good level, below average. HDL cholesterol being 67 mg/dL is in the good range while his LDL cholesterol level puts him at borderline risk. Trump’s cholesterol to HDL level, however, is good implying that he’s not at an increased risk of heart attack.
Regarding his white blood cell count, he’s slightly below the values for a man of his age, and white blood cell count is a good predictor of mortality in the elderly (Nilsson, Hedberg, and Ohrvik, 2014) and since he’s on the lower end there, he doesn’t have to worry about that.
For hemoglobin (HGB) he’s in the normal range. His HCT levels (hematocrit tests measure the percentage of red blood cells in the blood) and since he’s at 48.7% this puts him in the normal range of 38.8 to 50 percent. His platelet count (PLT) is in the normal range (241 K/uL), with the normal range being between 140 to 400 K/uL. His fasting blood glucose is normal (he had a value of 89 mg/dL with the average being 70 to 100 mg/dL implying that Trump is at no risk of developing type II diabetes.
His BUN level (blood urea nitrogen) was 19.0 mg/dL with the normal range being 7 to 20 mg/dL so he’s at the high end there. His blood creatinine level being .98 mg/dL is in the normal range of .84 to 1.21 mg/dL. His ALT levels were 27 U/L with the normal range being 7 to 56 units per literally. His AST levels were 19 U/L with the normal range being 10 to 40 U/L. His hemoglobin A1C level is normal at 5.0%. A level between 5.7 and 6.4 indicates pre-diabetes indicating that he is not at risk for diabetes.
Regarding vitamin D levels, Trump is right at the edge of good levels, at 20 ng/ml however others state that for the elderly their levels should be around 32 to lessen the chance of fracture. His PSA level (prostate specific antigen) is extremely low at .12 ng/dl with medical professionals advising that PSA levels over 10 ng/dl are at risk for prostate cancer. Finally his TSH (thyroid stimulating hormone level) was 1.76 uIU/ml with the normal range being .4 to 5.0 uIU/ml.
The only thing wrong looking at this report are his LDL cholesterol levels. Regarding the summary of the report, it states that he should lower his intake of fat and carbohydrates. Ravnskov et al (2016) state that “High LDL-C is inversely associated with mortality in most people over 60 years.” So it seems he’s fine there.
He should drop carbs for more fat. Of course, it seems like the doctors at the White House are still living in the 70s where fat is demonized, despite saturated fat consumption showing no risk for higher all cause mortality (de Sousa et al, 2015; Dehghan et al, 2017). In my opinion, it’s the carbohydrates driving up his cholesterol levels, not fat consumption.
Trump claims that he “gets more exercise than people think“, though his doctor himself said that Trump was dealt a hand of “good genes”, so well these “good genes” protect him for the rest of his life as he eats a shitty diet? In short, no.
A medical doctor and geneticist stated that “Even if Trump has been dealt a good genetic hand, he’s certainly not helping himself.” Also stating that people who have genes that lower their risk of disease “can mess that up.” Kera et al (2016) showed that “Among participants at high genetic risk, a favorable lifestyle was associated with 50% lower relative risk of coronary artery disease than was an unfavorable lifestyle.”
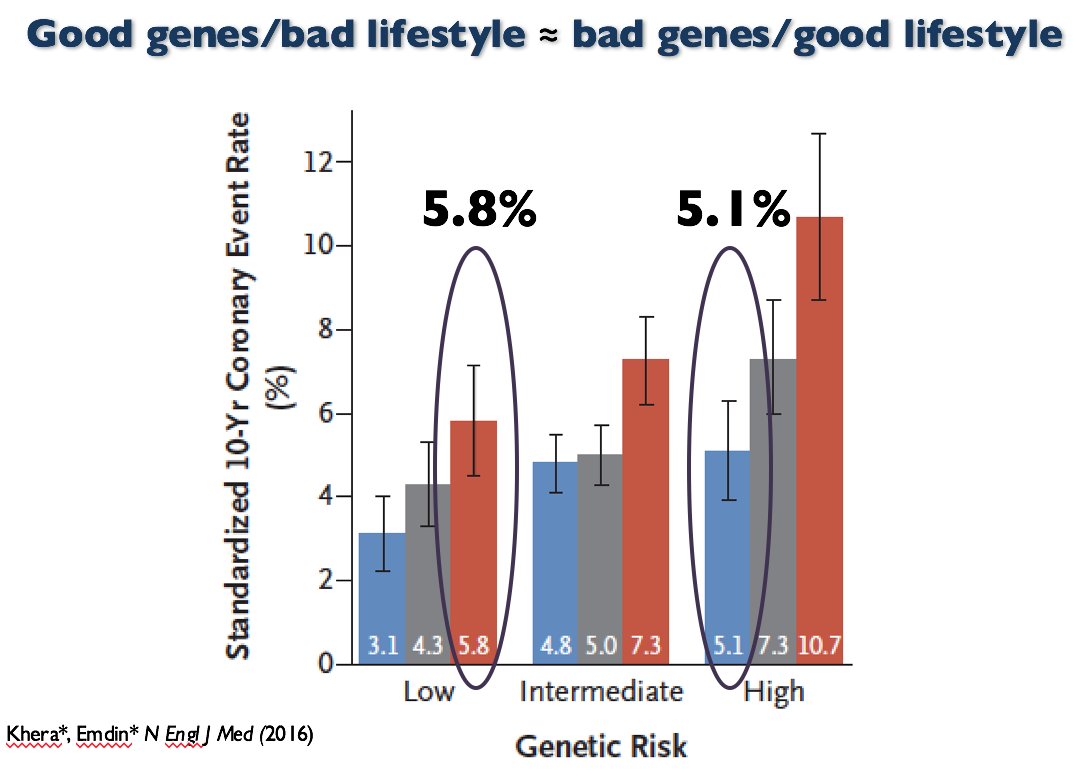
So ‘good genes’ and bad diet is the same as ‘bad genes’ and good diet. ‘Good genes’ doesn’t mean you should (and are able to) eat garbage like fast food every day of your life. Your diet affects your health, no matter if you have “good” or “bad” genes.
In sum, Trump may have ‘good genes’ to eat the garbage he eats and have a relatively good blood panel. However, as can be seen with the data I have provided here, ‘good genes’ and a bad diet isn’t ‘better’ than ‘bad genes’ and a good diet. No matter which genetic hand you were dealt, your diet needs to be kept in check it you want to have a good metabolic and blood panel and be healthy into old age. It seems that Trump will need to put away the Diet Cokes, and 2420 kcal McDonald’s meals if he wants to live into old age. Though the shitty advice for him to ‘lower fat and carbs’ doesn’t make sense; just lower carbs, no need to lower fat at all.
Responding to Criticisms on IQ
2250 words
My articles get posted on the Reddit board /r/hbd and, of course, people don’t like what I write about IQ. I get accused of reading ‘Richardson n=34 studies’ even though that was literally one citation in a 32 page paper that does not affect his overall argument. (I will be responding to Kirkegaard and UnsilencedSci in separate articles.) I’ll use this time to respond to criticisms from the Reddit board.
He’s peddling BS, say this:
“But as Burt and his associates have clearly demonstrated, teachers’ subjective assessments afford even more reliable predictors.”
Well, no, teachers are in fact remarkably poor at predicting student’s success in life. Simple formulas based on school grades predict LIFE success better than teachers, notwithstanding the IQ tests.
You’re incorrect. As I stated in my response to The Alternative Hypothesis, the correlation between teacher’s judgement and student achievement is .66. “The median correlation, 0.66, suggests a moderate to strong correspondence between teacher judgements and student achievement” (Hoge and Coladarci, 1989: 303). This is a higher correlation than what was found in the ‘validation studies’ from. Hunter and Schmidt.
He cherry-picks a few bad studies and ignores entire bodies of evidence with sweeping statements like this:
“This, of course, goes back to our good friend test construction. ”
Test construction is WHOLLY IRRELEVANT. It’s like saying: “well, you know, the ether might be real because Michelson-Morley experiment has been constructed this way”. Well no, it does not matter how MM experiment has been constructed as long as it tests for correct principles. Both IQ and MM have predictive power and it has nothing to do with “marvelling”, it has to do whether the test, regardless of its construction, can effectively predict outcomes or not.
This is a horrible example. You’re comparing the presuppositions of the test constructors who have in their mind who is or is not intelligent and then construct the test to confirm those preconceived notions to an experiment that was used to find the presence and properties of aether? Surely you can think of a better analogy because this is not it.
More BS: “Though a lot of IQ test questions are general knowledge questions, so how is that testing anything innate if you’ve first got to learn the material, and if you have not you’ll score lower?”
Of course the IQ tests do NOT test much of general knowledge. Out of 12 tests in WAIS only 2 deal with general knowledge.

The above screenshot is from Nisbett (2012: 14) (though it’s the WISC, not WAIS they’re similar, all IQ tests go through item analysis, tossing items that don’t conform to the test constructors’ presuppositions).
Either way, our friend test construction makes an appearance here, too. This is how these tests are made and they are made to conform to the constructor’s presuppositions. The WISC and WAIS have similar subtests, either way. Test anxiety, furthermore, leads to a lessened performance on the block design and picture arrangement subtests (Hopko et al, 2005) and moderate to severe stress, furthermore, is related to social class and IQ test performance. Stress affects the growth of the hippocampus and PFC (prefrontal cortex) (Davidson and McEwing, 2012) so does it seem like an ‘intellectual’ thing here? Furthermore, all tests and batteries are tried out on a sample of children, with items not contributing to normality being tossed out, therefore ‘item analysis’ forces what we ‘see’ regarding IQ tests.
Even the great Jensen said in his 1980 book Bias in Mental Testing (pg 71):
It is claimed that the psychometrist can make up a test that will yield any type of score distribution he pleases. This is roughly true, but some types of distributions are easier to obtain than others.
This holds for tbe WAIS, WISC, the Raven, any type of IQ test. This shows how arbitrary the ‘item selection’ is. No matter what type of ‘IQ test’ you attempt to use to say ‘It does test “intelligence” (whatever that is)!!’ the reality of test construction and constructing tests to fit presuppositions and distributions cannot be ran away from.
The other popular test, Raven’s Progressive Matrices does not test for general knowledge at all.
This is a huge misconception. People think that just because there are no ‘general knowledge questions’ or anything verbal regarding the Matrices then it must test an innate power, thus mysterious ‘g’. However, this is wrong and he clearly doesn’t keep up with recent data:
Reading was the greatest predictor of performance Raven’s, despite controlling for age and sex. Attendance was so strongly related with Raven’s performance [school attendance was used as a proxy for motivation]. These findings suggest that reading, or pattern recognition, could be fundamentally affecting the way an individual problem solves or learns to learn, and is somehow tapping into ‘g’. Presumably the only way to learn to read is through schooling. It is, therefore, essential that children are exposed to formal education, have the mother to go/stay in school, and are exposed to consistent, quality training in order to develop the skills associated with your performance. (pg 83) Variable Education Exposure and Cognitive Task Performance Among the Tsimane, Forager- Horticulturalists.
Furthermore, according to Richardson (2002): “Performance on the Raven’s test, in other words, is a question not of inducing ‘rules’ from meaningless symbols, in a totally abstract fashion, but of recruiting ones that are already rooted in the activities of some cultures rather than others.”
The assumption that the Raven is ‘culture free’ because it’s ‘just shapes and rote memory’ is clearly incorrect. James Thompson even said to me that Linda Gottfredson said that people only think the Raven is a ‘test of pure g’ because Jensen said it, which is not true.
This is completely wrong in so many ways. No understanding of normalization. Suggestion that missing heritability is discovering environmentally. I think a distorted view of the Flynn Effect. I’ll just stick to some main points.
I didn’t imply a thing about missing heritability. I only cited the article by Evan Charney to show how populations become stratified.
RR: There is no construct validity to IQ tests
First, let’s go through the basics. All IQ tests measure general intelligence (g), the positive manifold underlying every single measure of cognitive ability. This was first observed over a century ago and has been replicated across hundreds of studies since. Non-g intelligences do not exist, so for all intents and purposes it is what we define as intelligence. It is not ‘mysterious’
Thanks for the history lesson. 1) we don’t know what ‘g’ is. (I’ve argued that it’s not physiological.) So ‘intelligence’ is defined as ‘g’ yet which we don’t know what ‘g’ is. His statement here is pretty much literally ‘intelligence is what IQ tests test’.
It would be correct to say that the exact biological mechanisms aren’t known. But as with Gould’s “reification” argument, this does not actually invalidate the phenomenon. As Jensen put it, “what Gould has mistaken for “reification” is neither more nor less than the common practice in every science of hypothesizing explanatory models or theories to account for the observed relationships within a given domain.” Poor analogies to white blood cells and breathalyzer won’t change this.
It’s not a ‘poor analogy’ at all. I’ve since expanded on the construct validity argument with more examples of other construct valid tests like showing how the breathalyzer is construct valid and how white blood cell count is a proxy for disease. They have construct validity, IQ tests do not.
RR: I said that I recall Linda Gottfredson saying that people say that Ravens is culture-fair only because Jensen said it
This has always been said in the context of native, English speaking Americans. For example it was statement #5 within Mainstream Science on Intelligence. Jensen’s research has demonstrated this. The usage of Kuwait and hunter gatherers is subsequently irrelevant.
Point 5 on the Mainstream Science on Intelligence memo is “Intelligence tests are not culturally biased against American blacks or other native-born, English-speaking peoples in the U.S. Rather, IQ scores predict equally accurately for all such Americans, regardless of race and social class. Individuals who do not understand English well can be given either a nonverbal test or one in their native language.”
This is very vague. Richardson (2002) has noted how different social classes are differentially prepared for IQ test items:
I shall argue that the basic source of variation in IQ test scores is not entire (or even mainly) cognitive, and what is cognitive is not general or unitary. It arises from a nexus or sociocognitive-affective factors determining individuals: relative preparedness for the demands of the IQ test.
The fact of the matter is, all social classes aren’t prepared in the same way to take the IQ test and if you read the paper you’d see that.
RR: IQ test validity
I’ll keep this short. There exist no predictors stronger than g across any meaningful measures of success. Not education, grades, upbringing, you name it.
Yes there are. Teacher assessment which has a higher correlation than the correlation between ‘IQ’ and job performance.
RR: Another problem with IQ test construction is the assumption that it increases with age and levels off after puberty.
The very first and most heavily researched behavioral trait’s heritability has been intelligence. Only through sheer ignorance could the term “assumption” describe findings from over a century of inquiry.
Yes the term ‘assumption’ was correct. You do realize that, of course, the increase in IQ heritability is, again, due to test construction? You can also build that into the test as well, by putting more advanced questions, say high school questions for a 12 year old, and heritability would seem to increase due to just how the test was constructed.
Finally, IanTichszy says:
That article is thoroughly silly.
First, the IQ tests predict real world-performance just fine: http://thealternativehypothesis.org/index.php/2016/04/15/the-validity-of-iq/
I just responded to this article this week. They only ‘predicts real-world performance just fine’ because they’re constructed to and even then, high-achieving children in achievement rarely become high achieving adults whereas low-achieving adults tend to become successful adults. There are numerous problems with TAH’s article which I’ve already covered.
That is the important thing, not just correlation with blood pressure or something biological. Had g not predicted real-world performance from educational achievement to job performance with very high reliability, it would be useless, but it does predict those.
Test construction. You can’t get past that by saying ‘it does predict’ because it only predicts because it’s constructed to (I’d call it ‘post-dict’).
Second, on Raven’s Progressive Matrices test: the argument “well Jensen just said so” is plain silly. If RPM is culturally loaded, a question: just what culture is represented on those charts? You can’t reasonably say that. Orangutans are able to solve simplified versions of RPM, apparently they do not have a problem with cultural loading. Just look at the tests yourself.
Of course it’s silly to accept that the Raven is culture free and tests ‘g’ the best just ‘because Jensen said so’. The culture loading of the Raven is known, there is a ‘hidden structure’ in them. Even the constructors of the Raven have noted this where they state that they transposed the items to read from left to right, not right to left which is a tacit admission of cultural loading. “The reason that some people fail such problems is exactly the same reason some people fail IQ test items like the Raven Matrices tests… It simply is not the way the human cognitive system is used to being engaged” (Richardson, 2017: 280).
Furthermore, when items are familiar to all groups, even young children are capable of complex analogical reasoning. IQ tests “test for the learned factual knowledge and cognitive habits more prominent in some social classes than in others. That is, IQ scores are measures of specific learning, as well as self-confidence and so on, not general intelligence“ (Richardson, 2017: 192).
Another piece of misinformation: claiming that IQs are not normally distributed. Well, we do not really know the underlying distribution, that’s the problem, only the rank order of questions by difficulty, because we do not have absolute measure of intelligence. Still, the claim that SOME human mental traits, other than IQ, do not have normal distribution, in no way impacts the validity of IQ distribution as tests found it and projected onto mean 100 and standard dev 15 since it reflects real world performance well.
Physiological traits important for survival are not normally distributed (of course it is assumed that IQ both tests innate physiological differences and is important for survival so if it were physiological it wouldn’t be normally distributed either since traits important for survival have low heritabilities). It predicts real world performance well because, see above and my other articles on thus matter.
If you know even the basic facts about IQ, it’s clear that this article has been written in bad faith, just for sake of being contrarian regardless of the truth content or for self-promotion.
No, people don’t know the basic facts of IQ (or its construction). My article isn’t written in bad faith nor is it being contrarian regardless of the truth content or for self-promotion. I can, clearly, address criticisms to my writing.
In the future, if anyone has any problems with what I write then please leave a comment here on the blog at the relevant article. Commenting on Reddit on the article that gets posted there is no good because I probably won’t see it.
The Native American Genome and Dubious Interpretations
1100 words
A recent paper was published on the origins of Native Americans titled Terminal Pleistocene Alaskan genome reveals first founding population of Native Americans (Moreno-Mayar et al, 2018). An infant genome was studied and it was found that group of people the infant belonged to was similar to modern Native Americans but not a direct ancestor. The infant’s group and modern Native Americans share the same common ancestors, however. This, of course, supports the hypothesis that Native Americans are descended from Asian migrants.
The infant is also related to both North and South Natives, which implies they’re descended from a single migration. (Though I am aware of a hypothesis that states that there were three waves of migration into the Americas from Beringia, along with back migrations from South America back into Asia.)
Moreno-Mayar et al (2018) write in the abstract: “Our findings further suggest that the far-northern North American presence of northern Native Americans is from a back migration that replaced or absorbed the initial founding population of Ancient Beringians.” And they conclude (pg 5):
The USR1 results provide direct genomic evidence that all Native Americans can be traced back to the same source population from a single Late Pleistocene founding event. Descendants of that population were present in eastern Beringia until at least 11.5 ka. By that time, however, a separate branch of Native Americans had already established itself in unglaciated North America, and diverged into the two basal groups that ultimately became the ancestors of most of the indigenous populations of the Americas.
This is a highly interesting paper which shows that, as we’ve known for decades, that the ancestors of the Native Americans crossed the Bering Land Bridge around 11 kya. Though, my reason for writing this article is not for this very interesting paper, but the ‘conclusions’ that people that people are drawing from it.
Dubious ‘interpretations’
Of course, whenever a study like this gets published you get a whole slew of people who read the popular articles on the matter and don’t read the actual journal article. The problem here is that some people took the chance to attempt to say that this paper showed that the origins of Man were in Europe, not Africa as can be seen in the tweet below.
Black Pigeon Speaks, YouTuber, purportedly shows a quotation from the Nature article which said:
“…represent a growing body of evidence being discovered across the world that suggests the origins of the human race may have been Europe and not Africa as once believed.”
So I read the paper, read it again and even cntrl f’d it and didn’t see the phrase. So where did the phrase come from?
I did some digging and I found the source for the quote, which, of course, was not in the Nature article. The quote in question comes from an article titled Scientists discover DNA proving original Native Americans were White. Oh, wow. Isn’t that interesting? Maybe he read a different paper then I did.
The author stated that the infant was “more closely related to modern white Europeans“, though of course this too wasn’t stated anywhere in the article. He also quoted an evolutionary biologist who stated “This is a new population of Native Americans — the white Native American.” Wow, this is interesting. Now let’s look at what else this author writes:
Working with scientists at the University of Alaska and elsewhere, Willerslev compared the genetic makeup of the baby, named Xach’itee’aanenh t’eede gaay or “sunrise child-girl” by the local community, with genomes from other ancient and modern people. They found that nearly half of the girls DNA came from the ancient North Europeans who lived in what is no Scandinavia. The rest of her genetic makeup was a roughly even mixed of DNA now carried by northern and southern Native Americans. Using evolutionary models, the researchers showed the ancestors of the first Native Americans started to emerge as a distinct population about 35,000 years ago.
Isn’t that weird? This is nowhere in the original article. So I did some digging and what do I find? I found that the author of this article literally plagiarized almost word for word from another article from The Guardian!
Working with scientists at the University of Alaska and elsewhere, Willerslev compared the genetic makeup of the baby, named Xach’itee’aanenh t’eede gaay or “sunrise child-girl” by the local community, with genomes from other ancient and modern people. They found that nearly half of the girls DNA came from the ancient north Eurasians who lived in what is now Siberia. The rest of her genetic makeup was a roughly even mixed of DNA now carried by northern and southern Native Americans.
Using evolutionary models, the researchers showed the ancestors of the first Native Americans started to emerge as a distinct population about 35,000 years ago.
This is not only an example of straight up plagiarism, the author of the other article literally only switched “Siberia” with “Scandinavia” and “ancient north Eurasians” with “ancient North Europeans”. Ancient north Eurasians are NOT WHITE! Where do you gather this from?! There is NO INDICATION that they were ‘ancient north Europeans!
In sum, if you ever see articles like this that purport to show that Native Americans were white European and that it supposedly calls the OoA model into question, always ALWAYS check the claims and don’t fall for plagiarist bullshit. This is truly incredible that not only did the author literally copy and past a full article, he also snipped a few words to fit the narrative he was pushing! I will be notifying the author of the Guardian article of this plagiarism. You can check it out yourself, read the first article cited above then read the Guardian article. Do people really think they can get away with literally plagiarizing and article like that word for word?
This article is on a whole other level compared to the claims that modern Man began in Europe and that a few teeth upend the OoA model. This guy didn’t even read the paper, it seems like he read the Guardian article and then copy and pasted it and changed a few words for his own ‘gain’ to ‘show’ that the first Native Americans were white. There is no way that one can interpret this paper in this manner if they’ve truly read and understood it. Always, always read original journal articles and, if you must read popular science articles then read it from a reputable website, not kooky websites with an agenda to push who literally plagiarize other people’s work. You can tell who’s gullible and who’s not just by what they say about new papers that can possibly be misinterpreted.
The Non-Validity of IQ: A Response to The Alternative Hypothesis
1250 words
Ryan Faulk, like most IQ-ists, believes that the correlation with job performance and IQ somehow is evidence for its validity. He further believes that because self- and peer-ratings correlate with one’s IQ scores that that is further evidence for IQ’s validity.
Well too bad for Faulk, correlations with other tests and other IQ tests lead to circular assumptions. The first problem, as I’ve covered before, is that there is no agreed-upon model or description of IQ/intelligence/’g’ and so therefore we cannot reliably and truthfully state that differences in ‘g’ this supposed ‘mental power’ this ‘strength’ is what causes differences in test scores. Unfortunately for Ryan Faulk and other IQ-ists, again, coming back to our good old friend test construction, it’s no wonder that IQ tests correlate around .5—or so is claimed—with job performance, however IQ test scores correlate at around .5 with school achievement, which is caused by some items containing knowledge that has been learned in school, such as “In what continent is Egypt?” and Who wrote Hamlet?” and “What is the boiling point of water?” As Ken Richardson writes in his 2017 book Genes, Brains, and Human Potential: The Science and Ideology of Intelligence (pg 85):
So it should come as no surprise that performance on them [IQ tests] is associated with school performance. As Robert L. Thorndike and Elizabeth P. Hagen explained in their leading textbook, Educational and Psychological Measurement, “From the very way in which the tests were assembled [such correlation] could hardly be otherwise.”
So, obviously, neither of the two tests determine independently that they measure intelligence, this so-called innate power, and because they’re different versions of the same test there is a moderate correlation between them. This goes back to item analysis and test construction. Is it any wonder, then, why correlations with IQ and achievement increase with age? It’s built into the test! And while Faulk does cite high correlations from one of Schmidt and Hunter’s meta-analyses on the subject, what he doesn’t tell you is that one review found a correlation of .66 between teacher’s assessment and future achievement of their students later in life (higher than the correlation with job performance and IQ) (Hoge and Coladarci, 1989.) They write (pg 303): “The median correlation, 0.66, suggests a moderate to strong correspondence between teacher judgments and student achievement.” This is just like what I quoted the other day in my response to Grey Enlightenment where I quoted Layzer (1972) who wrote:
Admirers of IQ tests usually lay great stress on their predictive power. They marvel that a one-hour test administered to a child at the age of eight can predict with considerable interest whether he will finish college. But as Burt and colleagues have clearly demonstrated, teachers subjective assessments afford even more reliable predictors. This is almost a truism.
So the correlation of .5 between occupation level and IQ is self-fulfilling, which are not independent measures. In regard to the IQ and job performance correlation, which I’ve discussed in the past, studies in the 70s showed much lower correlations, between .2 and .3, which Jensen points out in The g Factor.
The problem with the so-called validity studies carried out by Schmidt and Hunter, as cited by Ryan Faulk, is that they included numerous other tests that were not IQ tests in their analysis like memory tests, reading tests, the SAT, university admission tests, employment selection tests, and a variety of armed forces tests. “Just calling these “general ability tests,” as Schmidt and Hunter do, is like reducing a diversity of serum counts to a “general. blood test” (Richardson, 2017: 87). Of course the problem with using vastly different tests is that they tap into different abilities and sources of individual differences. The correlation between SAT scores and high school grades is .28 whereas the correlation between both the SAT and high school grades and IQ is about .2. So it’s clearly not testing the same “general ability” that’s being tested.
Furthermore, regarding job performance, it’s based on one measure: supervisor ratings. These ratings are highly subjective and extremely biased with age and halo effects seen with height and facial attractiveness being seen to sway judgments on how well one works. Measures of job performance are unreliable—especially from supervisors—due to the assumptions and biases that go into the measure.
I’ve also shown back in October that there is little relationship between IQ and promotion to senior doctor (McManus et al, 2013).
Do IQ tests test neural processes? Not really. One of the most-studied variables is reaction time. The quicker they react to a stimulus, supposedly, the higher their IQ is in average as they are quicker to process information, the story goes. Detterman (1987) notes that other factors other than ‘processing speed’ can explain differences in reaction time, including but not limited to, stress, understanding instructions, motivation to do said task, attention, arousal, sensory acuity, confidence, etc. Khodadadi et al (2014) even write “The relationship between reaction time and IQ is too complicated and reveal a significant correlation depends on various variables (e.g. methodology, data analysis, instrument etc.).” Complex cognition in real life is also completely different than the simple questions asked in the Raven (Richardson and Norgate, 2014).
It is easy to look at the puzzles that make up IQ tests and be convinced that they really do test brain power. But then we ignore the brain power thst nearly everyone displays in their everyday lives. Some psychologists have noticed thst people who stumble over formal tests of cognitive can bangle highly complex problems in their real lives all the time. As Michael Eysenck put it in his well-known book Psychology, “There is an apparent contradiction between our ability to deal effectively with out everyday environment and our failure to perform well on many laboratory reasoning tasks.” We can say the same about IQ tests.
[…]
Real-life problems combine many more variables that change over time and interact. It seems that the ability to do pretentious problems in a pencil-and-paper (or computer) format, like IQ test items, is itself a learned, if not-so-complex skill. (Richardson, 2017: 95-96)
Finally, Faulk cites studies showing that how intelligent people and their peers rates themselves and others predicted how well they did on IQ tests. This isn’t surprising. Since they correlate with academic achievement at .5 then if one is good academically then they’d have a high test score more often than not. That friends rate friends high and they end up matching scores is no surprise either as people generally group together with other people like themselves and so therefore will have similar achievements. That is not evidence for test validity though!! See Richardson and Norgate (2015) “In scientific method, generally, we accept external, observable differences as a valid measure of an unseen function when we can mechanistically relate differences in one to diffences in the other …” So even Faulk’s attempt to ‘validate’ IQ tests using peer- and self-ratings of ‘intelligence’ (whatever that is) falls on its face since its not a true measure of validity. It’s not construct validity. (EDIT: Psychological constructs are validated ‘by testing whether they relate to measures of other constructs as specified by theory‘ (Strauss and Smith, 2009). This doesn’t exist for IQ therefore IQ isn’t construct valid.)
In sum, Faulk’s article leaves a ton to be desired and doesn’t outright prove that there is validity to IQ tests because, as I’ve shown in the past, validity for IQ is nonexistent, though some have tried (using correlations with job performance as evidence) but Richardson and Norgate (2015) take down those claims and show that the correlation is between .2 and .3, not the .5+ cited by Hunter and Schmidt in their ‘validation studies’. The criteria laid out by Faulk does not prove that there is true construct validity to IQ tests and due to test construction, we see these correlations with educational achievement.
Toward a Theory of Individual and Group Differences in Athleticism
1500 words
I am aware that there is no theory of individual or group differences in athleticism. People have used that against the arguments against IQ I have used. However, athleticism and IQ are two different things. One is easily observable (have someone, say, run a race vs another and see who’s faster) while the other is not and takes up a lot of time (over an hour to administer a test then you have to, say, use a fMRI scan). On one of these tests we can get a good idea just by looking at the one who won in comparison to the other and assess somatype and use that as a proxy, what can we do for IQ? Just look at head size? The fact of the matter is, just because there is no ‘theory of athleticism’ doesn’t mean that because there is no ‘theory of intelligence differences’ that it doesn’t matter, because it clearly does. Either way, I will articulate a theory of individual and group athletic differences, and meld them into a coherent theory.
Everyone is different, no one is a perfect clone of their parents. This is common knowledge. Each and every individual has different physiology and anatomy, one person may have a certain organ while another does not. One person may have physiological advantages that another does not. These are the how’s and why’s of athletic differences between individuals and groups. Talking about just individuals, individual A may have a more mesomorphic somatype with more fast twitch fibers while individual B may have an endomorphic somatype with more slower twitch fibers. Let’s say these two individuals didn’t know about their advantages/disadvantages. They then race. You look at them and you automatically say “Individual A won because of his longer legs in comparison to individual B”, and you’d be right. When speaking about sports performance these physical differences are noticeable by the naked eye.
The theory
Individuals have different somatypes and different physiological variables unevenly distributed within and between populations that infer different capacity for athletic ability. To understand and formulate a theory of individual and group athletic differences you must know some basic anatomy and physiology. Differences in biomechanics and physiology explain individual differences in athletic competition. Now all you need to do is extrapolate the individual who is more athletic (faster 40 yd dash time, say) and find the population with similar phenotype. The argument for individuals carries over to groups, too. Though I have already elucidated on the theory for type II muscle fibers and athletic success in some West African populations (Morrison and Cooper, 2006), and that is good enough for group differences (at least between whites, blacks, and Asians regarding sports in America). The point is that there is no theory for individual differences in athletic ability and one is not needed therefore one is not needed for IQ is clearly wrong. Theories do exist, but I believe they don’t need to be articulated because it truly is obvious.
Why do other groups have differing somatypes and fiber distribution? The answer is, clearly, due to evolution in different environments. The cause for most African running success can be attributed to fast twitch muscle fibers which may have been brought on by malaria-infected mosquitoes which then changed the physiology of the groups affected.
Either way, there are theories of athletic ability. We know what makes someone faster than someone else. Say they take longer strides, deeper breaths, higher Vo2 max, etc and they have the correct morphology, along with the ACTN3 gene and right morphology and we can then compare them to others who did less well and even other groups who don’t exceed as well as the group with the somatype in question and then attempt to formulate a theory from there.
The RR ACTN3 genotype infers an advantage when coupled with the correct morphology (Broos et al, 2016). We know that certain populations excel over others when it comes to sprinting and distance competition, and at least regarding West Africa and its diaspora, there is a good theory for how and why they excel in these competitions. Regarding Kenyans and Ethiopians, it comes down to their low body fat, ecto-meso somatype and the altitude they live and train at. You need to take a system’s view of running and sports success as a whole and not attempt to reduce things down to, say, only muscle fibers or only somatype or pulmonary differences or Vo2 max etc etc because the whole system works together and if you take one variable out, say type II fibers, one part of the system that made it run is now out of the equation and that system will not work as it used to when all cogs were together.
Nevertheless, we don’t need a theory of individual athletic differences but one is extremely easy to articulate. We know how one’s body begins to cope as they are running at maximal speed or as they are hitting their stride on a distance competition. Take someone who’s ecto, and has type I fibers and more body fat compared to someone who’s ecto and has type II fibers and less body fat. How could we articulate how and why the ecto outperforms the endo in a sprint? It’s easy. The ecto somatype is conducive to running success and due to longer limbs can cover more ground and since he has less body fat he will be quicker, too.
This is in stark contrast to IQ. There is no agreed-upon theory and the one model there is is highly flawed. We don’t need a theory of athletic differences but we do need a theory of IQ. The correlates that people attempt to use to say that there is a theory and that they do test something meaningful are nowhere near good enough because it could just show life experiences, for instance the size of different parts of the brain while in the MRI machine (which, even then, has problems; Rutter and Pickles, 2016). There is no theory of individual intelligence differences, to quote Ian Deary “There is no such thing as a theory of human intelligence differences—not in the way that grown-up sciences like physics or chemistry have theories (quote from Richardson, 2012). Well it seems that according to Deary, psychology isn’t a ‘grown-up science’ since there is no agreed-upon theory of individual differences in ‘intelligence’.
One paper people point to is Jung and Haier (2007) who propose the theory ‘P-FIT’—the Parieto-frontal integration theory—where they show that in more 40 percent of voxel-based morphometry that tissue density and white matter integrity correlate substantially with IQ. Though that only means that 60 percent of the time it did not correlate substantially at all, with the same being noted for fMRI and PET. They also note that neuroimaging is ‘correlational by nature‘, so post hoc, ergo propter hoc. This is the problem: we can reliably state how and why people are more athletic then others, but when it comes to IQ/’intelligence’, these differences are fleeting and there is a ton of contradictory evidence, as noted by Jung and Haier (2007).
All in all, we don’t need a theory of athletic differences for both individuals and populations, though one is easily articulated because we actually—and reliably—know how and why individuals are, say, faster than one another and how and why different people succeed in different athletic competitions, the same cannot be said for IQ, the ‘unseen construct’. Attempting to use a nonexistent theory of athletic ability as an analog to no theory for individual differences in IQ does not make sense because they’re two wildly different things, one is an actual measurable thing (with actual reliable physiological/physical differences), while IQ is a reified construct. Explaining these athletic differences between groups and individuals is extremely easy: differing body type along with differing physiology and, of course—and perhaps most importantly—the mind matters way more than one thinks. One can have all of the physical gifts in the world, but if they don’t have the right mindset then they will not succeed (Lippi, Favoloro, and Guidi, 2008).
Combining all of these factors, we get: individuals and groups differ in morphology, physiology and mindsets which then causes differences in sporting competition. When it comes to differences between races, such as the West African diaspora vs the rest of the world, the hypothesis of sickle cell anemia causing a shift to type II fibers is currently the best hypothesis for group differences and explaining why Africans dominate. Though when it comes to individuals, clearly, variation in the aforementioned traits end up causing these differences as no two individuals are the same in regard to body type, physiology and mindset. Of course no two brains are also the same, and I don’t fall prey to simplistic assumptions that ‘everyone is equal’, criticizing IQ tests and their nonexistent, agreed-upon theories doesn’t mean that I believe that ‘everyone is the same’. Athletic ability and IQ, as I’ve shown, are two different things and they do not form an analogous argument.
People Should Stop Thinking IQ Measures ‘Intelligence’: A Response to Grey Enlightenment
1700 words
I’ve had a few discussions with Grey Enlightenment on this blog, regarding construct validity. He has now published a response piece on his blog to the arguments put forth in my article, though unfortunately it’s kind of sophomoric.
People Should Stop Saying Silly Things About IQ
He calls himself a ‘race realist’yet echoes the same arguments used by those who oppose such realism.
1) One doesn’t have to believe in racial differences in mental traits to be a race realist as I have argued twice before in my articles You Don’t Need Genes to Delineate Race and Differing Race Concepts and the Existence of Race: Biologically Scientific Definitions of Race. It’s perfectly possible to be a race realist—believe in the reality of race—without believing there are differences in mental traits—‘intelligence’, for instance (whatever that is).
2) That I strongly question the usefulness and utility of IQ due to its construction doesn’t mean that I’m not a race realist.
3) I’ve even put forth an analogous argument on an ‘athletic abilities test’ where I gave a hypothetical argument where a test was constructed that wasn’t a true test of athletic ability and that it was constructed on the basis of who is or is not athletic, per the constructors’ presuppositions. In this hypothetical scenario, am I really denying that athletic differences exist between races and individuals? No. I’d just be pointing out flaws in a shitty test.
Just because I question the usefulness and (nonexistent) validity of IQ doesn’t mean that I’m not a race realist, nor that I believe groups or individuals are ‘the same’ in ‘intelligence’ (whatever that may be; which seems to be a common strawman for those who don’t bow to the alter of IQ).
Blood alcohol concentration is very specific and simple; human intelligence by comparison is not . Intelligence is polygenic (as opposed to just a single compound) and is not as easy to delineate, as, say, the concentration of ethanol in the blood.
It’s irrelevant how ‘simple’ blood alcohol concentration is. The point of bringing it up is that it’s a construct valid measure which is then calibrated against an accepted and theoretical biological model. The additive gene assumption is false, that is, genes being independent of the environment giving ‘positive charges’ as Robert Plomin believes.
He says IQ tests are biased because they require some implicit understanding if social constructs, like what 1+1 equals or how to read a word problem, but how is a test that is as simple as digit recall or pattern recognition possibly a social construct.
What is it that allows individuals to be better than others on digit recall or pattern recognition (what kind of pattern recognition?)? The point of my 1+1 statement is that it is construct valid regarding one’s knowledge of that math problem whereas for the word problem, it was a quoted example showing how if the answer isn’t worded correctly it could be indirectly testing something else.
He’s invoking a postmodernist argument that IQ tests do not measure an innate, intrinsic intelligence, but rather a subjective one that is construct of the test creators and society.
I could do without the buzzword (postmodernist) though he is correct. IQ tests test what their constructors assume is ‘intelligence’ and through item analysis they get the results they want, as I’ve shown previously.
If IQ tests are biased, how is then [sic] that Asians and Jews are able to score better than Whiles [sic] on such tests; surely, they should be at a disadvantage due to implicit biases of a test that is created by Whites.
If I had a dollar for every time I’ve heard this ‘argument’… We can just go back to the test construction argument and we can construct a test that, say, blacks and women score higher than whites and men respectively. How well would that ‘predict’ anything then, if the test constructors had a different set of assumptions?
IQ tests aren’t ‘biased’, as much as lower class people aren’t as prepared to take these tests as people in higher classes (which East Asians and Jews are in). IQ tests score enculturation to the middle class, even the Flynn effect can be explained by the rise in the middle class, lending credence to the aforementioned hypothesis (Richardson, 2002).
Regarding the common objection by the left that IQ tests don’t measures [sic] anything useful or that IQ isn’t correlated with success at life, on a practical level, how else can one explain obvious differences in learning speed, income or educational attainment among otherwise homogeneous groups? Why is it in class some kids learn so much faster than others, and many of these fast-learners go to university and get good-paying jobs, while those who learn slowly tend to not go to college, or if they do, drop out and are either permanently unemployed or stuck in low-paying, low-status jobs? In a family with many siblings, is it not evident that some children are smarter than others (and because it’s a shared environment, environmental differences cannot be blamed).
1) I’m not a leftist.
2) I never stated that IQ tests don’t correlate with success in life. They correlate with success in life since achievement tests and IQ tests are different versions of the same test. This, of course, goes back to our good friend test construction. IQ is correlated with income at .4, meaning 16 percent of the variance is explained by IQ and since you shouldn’t attribute causation to correlations (lest you commit the cum hoc, ergo propter hoc fallacy), we cannot even truthfully say that 16 percent of the variation between individuals is due to IQ.
3) Pupils who do well in school tend to not be high-achieving adults whereas children who were not good pupils ended up having good success in life (see the paper Natural Learning in Higher Education by Armstrong, 2011). Furthermore, the role of test motivation could account for low-paying, low-status jobs (Duckworth et al, 2011; though I disagree with their consulting that IQ tests test ‘intelligence’ [whatever that is] they show good evidence that in low scorers, incentives can raise scores, implying that they weren’t as motivated as the high scorers). Lastly, do individuals within the same family experience the same environment the same or differently?
As teachers can attest, some students are just ‘slow’ and cannot grasp the material despite many repetitions; others learn much more quickly.
This is evidence of the uselessness of IQ tests, for if teachers can accurately predict student success then why should we waste time and money to give a kid some test that supposedly ‘predicts’ his success in life (which as I’ve argued is self-fulfilling)? Richardson (1998: 117) quotes Layzer (1973: 238) who writes:
Admirers of IQ tests usually lay great stress on their predictive power. They marvel that a one-hour test administered to a child at the age of eight can predict with considerable accuracy whether he will finish college. But as Burt and his associates have clearly demonstrated, teachers’ subjective assessments afford even more reliable predictors. This is almost a truism.
Because IQ tests test for the skills that are required for learning, such as short term memory, someone who has a low IQ would find learning difficult and be unable to make correct inferences from existing knowledge.
Right, IQ tests test for skills that are required for learning. Though a lot of IQ test questions are general knowledge questions, so how is that testing anything innate if you’ve first got to learn the material, and if you have not you’ll score lower? Richardson (2002) discusses how people in lower classes are differentially prepared for IQ tests which then affects scores, along with psycho-social factors that do so as well. It’s more complicated than ‘low IQ > X’.
All of these sub-tests are positively correlated due to an underlying factor –called g–that accounts for 40-50% of the variation between IQ scores. This suggests that IQ tests measure a certain factor that every individual is endowed with, rather than just being a haphazard collection of questions that have nothing to do with each other. Race realists’ objection is that g is meaningless, but the literature disagrees “… The practical validity of g as a predictor of educational, economic, and social outcomes is more far-ranging and universal than that of any other known psychological variable. The validity of g is greater the complexity of the task.[57][58]”
I’ve covered this before. It correlates with the aforementioned variables due to test construction. It’s really that easy. If the test constructors have a different set of presuppositions before the test is constructed then completely different outcomes can be had just by constricting a different test.
Then what about ‘g’? What would one say then? Nevertheless, I’ve heavily criticized ‘g’ and its supposed physiology, and if physiologists did study this ‘variable’ and if it truly did exist, 1) it would not be rank ordered because physiologists don’t rank order traits, 2) they don’t assume normal variations, they don’t estimate heritability and attempt to untangle genes from environment, 3) they don’t assume that normal variation is related to genetic variation (except in rare cases, like down syndrome, for instance), and 4) nor do they assume within the normal range of physiological differences that a higher level is ‘better’ than a lower. My go-to example here is BMR (basal metabolic rate). It has a similar heritability range as IQ (.4 to .8; which is most likely overestimated due to the use of the flawed twin method, just like the heritability of IQ), so is one with a higher BMR somehow ‘better’ than one with a lower BMR? This is what logically follows from assuming that ‘g’ is physiological and all of the assumptions that come along with it. It doesn’t make logical, physiological sense! (Jensen, 1998: 92 further notes that “g tells us little if anything about its contents“.)
All in all, I thank Grey Enlightenment for his response to my article, though it leaves a lot to be desired and if he responds to this article then I hope that it’s much more nuanced. IQ has no construct validity, and as I’ve shown, the attempts at giving it validity are circular, and done by correlating it with other IQ tests and achievement tests. That’s not construct validity.
Smoking and Race Part II
1750 words
Almost two years ago, I wrote an article on smoking and race, discussing racial differences in smoking, the brains smoked, and biochemical differences brought on by different physiological differences when smoke is inhaled. In this article, I will look at how smoking can be prevented for all race/ethnies, the contribution of smoking to the black/white difference in mortality, and certain personality traits that may have one more likely to pick up the habit.
Tobacco and poverty are “inextricably linked“, with smoking contributing to more than 10 percent of household income among those in poverty. Tobacco has even been said to be a ‘social justice issue‘ since tobacco use is more prevalent in lower-income communities.
It is true that advertisements are concentrated around certain areas to target certain sociodemographic communities (Seidenberg et al, 2010). They looked at two communities in Boston, Massachusets, one high -income non-minority population, and the other a minority low-income population. They found that the low-income community was more likely to have stores which had larger advertisements, have more stores selling tobacco, promote menthol cigarettes (which low-income people are more likely to smoke, mainly blacks), and finally that advertisements for cigarettes would be more likely to be found 1000 feet away from a school zone in low-income communities compared to high-income communities.
They say that their study shows “evidence that features of tobacco advertising are manipulated to attract youth or racial minority sub-groups, and these features are disproportionately evident in low income, minority communities.” So, according to analysis, at least in the urban area of Dorchester, near Boston, if advertisements were to be lessened near schools, along with fewer overall advertisements, the percentage of minority smokers would decrease. (This same effect of low SES affecting the odds of smoking was also seen in a sample of Argentine children; Linetzky et al, 2012).
Higher SES communities have fewer tobacco advertisements than lower SES communities (Barbeau et al, 2005; Hillier et al, 2015). Big Tobacco (along with Big Food and Big Soda) advertise the most in lower-income communities, which then have deleterious health consequences in those populations, further increasing national health spending per year.
Among Americans, as income increases, smoking decreases:
Nationwide, the Gallup-Healthways Well-Being Index reveals that 21% of Americans say they smoke. As the accompanying graph illustrates, the likelihood of smoking generally increases as annual incomes decrease. One exception to this pattern occurs among those making less than $6,000 per year, an income bracket often skewed because many in that bracket are students. Among those making $6,000 to $11,999 per year, 34% say they smoke, while only 13% in the top two income brackets (those with incomes of at least $90,000 per year) say the same — a 21 percentage-point gap.
The Well-Being Index also confirms distinctions in U.S. smoking rates relating to gender and race. Among respondents, 23% of men and 19% of women say they smoke. Blacks are the most likely to smoke (23%) and Asians are least likely to smoke (12%). Hispanics and whites fall in between, at 17% and 20%, respectively.
Further, according to the CDC, the prevalence of smoking of people with a GED is at 40 percent, the highest amongst any SES group. The fact that tobacco companies attempt to advertise in low-income areas and to women is also well-studied. These factors combined to then cause higher rates of smoking in lower-income populations, and blacks are some of the most affected. There are also a slew of interesting physiological differences between blacks and whites regarding smoking.
Ho and Elo (2013) show that smoking differences between blacks and whites at age 50 accounted for 20 and 40 percent of the gap between 1980 and 2005, but not for women. Without adjusting for SES, smoking explains 20 percent of the excessive risk blacks have regarding all-cause mortality.
A study of 720 black smokers from Los Angeles, California showed that 57 percent only smoked menthols, 15 smoked regulars while 28 percent smoked both menthols and regulars (Unger et al, 2010). One of their main findings was that blacks who smoked menthol cigarettes thought that it was a ‘healthier alternative’ to regular cigarettes. Unger et al (2010: 405) also write:
This cross-sectional study identified correlates of menthol smoking, but it does not prove causality. It is possible that smoking menthol cigarettes causes changes in some of the psychological, attitudinal, social, and cultural variables. For example, people who smoke menthols may form beliefs about the positive medicinal benefits of menthols as a way of reducing their cognitive dissonance about smoking.
Figuring out the causation will be interesting, and I’m sure that advertisements outside of storefronts are causally related. Okuyemi et al (2004) also show that blacks who smoke menthol cigarettes are less likely to quit smoking than blacks who smoke regulars. Younger children were more likely to smoke cigarettes with a “longer rod length” (for instance, Newport 100s over Newport regulars). People smoke menthol cigarettes because they taste better, while menthol also “is a prominent design feature used by cigarette manufacturers to attract and retain new, younger smokers.” (Klausner, 2011). Klausner, though, advocates to ban menthol cigarettes, writing:
This evidence suggests that a ban on menthol in cigarettes would result in fewer people smoking cigarettes. Menthol is a prominent design feature used by cigarette manufacturers to attract and retain new, younger smokers. In addition, not only would some current smokers decide to quit rather than smoke non-mentholated cigarettes, but some young people would not make the transition from experimenting with cigarettes to becoming a confirmed smoker. The FDA should ban menthol in cigarettes which will help lower smoking rates particularly among African Americans and women.
Sterling et al (2016) also agree, but argue to ban little cigars and cigarillos (LCCs) writing “Our data add to the body of scientific evidence that supports the FDA’s ban of all characterising flavours in LCCs.” Numerous studies attest to the availability of menthol cigarettes and LCCs which then contributes to influence different demographics to begin smoking. Hersey et al (2006) also shows menthol cigarettes to be a ‘starter product for youth’, stating one reason that children begin smoking mentholated cigarettes is that they are more addictive than non-menthols. Menthol cigarettes are a ‘starter product’ because they taste better than regular cigarettes and, as shown above, seem like they are more ‘theraputic’ due to their taste and coolness compared to regular cigarettes.
Smokers are more likely to be extroverted, tense, anxious and impulsive, while showing more traits of neuroticism and psychoticism than ex- or non-smokers (Rondina, Gorayeb, and Botelho III, 2007). In a ten-year longitudinal study, Zvolensky et al (2015) showed that people who were more likely to be open to experience and be more neurotic would be more likely to smoke, whereas conscientiousness ‘protected’ against picking up the habit. Neuroticism is one of the most important factors of personality to study regarding the habit of smoking. Munafo, Zetteler, and Clark (2006) show in their meta-analysis on personality factors and smoking that neuroticism and increased extraversion were risk factors for being a smoker. I am aware of one study on the effects of different personality and smoking. Choi et al (2017) write:
The results emerging from this study indicate that neuroticism and conscientiousness are associated with the likelihood of being a current smoker, as well as level of ND. Furthermore, personality traits have a greater influence on smoking status and severity of ND in AAs relative to EAs. These relationships were particularly pronounced among smokers with reporting TTFC of ≤5 min.
…
… we found that higher neuroticism and lower conscientiousness were associated with higher likelihood of being a current smoker in the AA sample.
So black smokers were more likely to be conscientious, neurotic and open to experience whereas white smokers were more likely to be neurotic and conscientious.
Finally, racial differences in serum cotnine levels are seen, too. Black smokers have higher levels of cotnine than white smokers (Caraballo et al, 1998; Signorello et al, 2010). Perez-Stable et al (2006) show that higher levels of cotnine can be explained by slower clearance of cotnine along with a higher intake of nicotine per cigarette, because blacks take deeper pulls than whites (though they smoke fewer cigarettes than whites, taking deeper pulls off-sets this; Ho and Elo, 2013).
Smoking can be lessened in all populations—no matter the race/ethincity—with the right universal and intervention efforts (Kandel et al, 2004; Kahende et al, 2011). This can be achieved—especially in low-income areas—by lessening and eventually ridding storefronts of these advertisements for menthol cigarettes, which would then decrease the population of smokers in that area because most only smoke menthols. This would then close some of the black-white mortality gap since smoking causes a good amount of it.
Dauphinee et al (2013) even noted how 52 percent of students recognized Camel cigarettes, whereas 36 percent recognized Marlboro and 32 percent recognized Newports. Black students were three times more likely to recognize Newports than Marlboros (because, in my experience, blacks are way more likely to smoke Newports than Marlboros, which whites are more likely to smoke), while this effect held even after controlling for exposure to smoking by parents and peers. This is yet more proof of the ‘menthol effect’ in lower-income communities that partly drives the higher rates of smoking.
In conclusion, it seems that most of the disparity can be pinned down on Big Tobacco advertising mostly in low-income areas where they spend more than 10 percent of their income on cigarettes. Young children are more likely to know what menthol cigarettes are, what they look like and are more likely to know those type of brains of cigarettes, due mainly to how often and how much they are advertised in low-income areas in comparison to high-income areas. Blacks are also more likely than whites to have the personality traits found in smokers, so this, too, contributes to the how and why of black smoking in comparison to whites; they are more susceptible to it due to their personality along with being exposed to more advertisements since they are more likely to live in lower-income areas than whites.
I don’t believe in banning things, but the literature on this suggests that many people only smoke menthols and that if they were ever banned, most would just quit smoking. I don’t think that we need to go as far as banning menthol cigarettes—or cigarettes in general—we just need to educate people better and, of course, reel in Big Tobaccos reach in lower-income communities. Smoking also began to decline the same year that Joe Camel was ‘voluntarily’ discontinued by its parent company (Pampel and Aguilar, 2008), and so, that is good evidence that at least banning or reforming laws in low-income areas would change the number of smokers in a low-income area, and, along with it, close at least a small part of the black-white mortality gap.
Race/Ethnicity and the Microbiome
1800 words
The microbiome is the number and types of different microorganisms and viruses in the human body. Racial differences are seen everywhere, most notably in the phenotype and morphology. Though, of course, there are unseen racial differences that then effect bodily processes of different races and ethnic groups. The microbiome is one such difference, which is highly heritable (Goodrich et al, 2014; Beaumont et al, 2016; Hall, Tolonen, and Xavier, 2017) (though they use the highly flawed twin method, so heritabilities are most likely substantially lower). They also show that certain genetic variants predispose individuals to microbial dysbiosis. However, diet, antibiotics and birth mode can also influence the diversity of microbiota in your biome (Conlon and Bird, 2015; Bokulich et al, 2017; Singh et al, 2017) and so while the heritability of the microbiome is important (which is probably inflated due to the twin method), diet can and does change the diversity of the biome.
It used to be thought that our bodies contained 90 percent bacteria and only 10 percent human cells (Collen, 2014), however that has been recently debunked and the ratio is 1.3 to 1, human to microbe (Sender, Fuchs, and Milo, 2016). (Collen’s book is still an outstanding introduction to this subject despite the title of her book being incorrect.) Though the 10:1 microbe/human cell dogma is debunked, in no way does that lessen the importance of the microbiome regarding health, disease and longevity.
Lloyd-Price, Abu-Ali, and Huttenhower (2016) review definitions for the ‘healthy human microbiome’ writing “several population-scale studies have documented the ranges and diversity of both taxonomic compositions and functional potentials normally observed in the microbiomes of healthy populations, along with possible driving factors such as geography, diet, and lifestyle.” Studies comparing the biomes of North and South America, Europe and Africa, Korea and Japan, and urban and rural communities in Russia and China have identified numerous different associations that are related to differences in the microbiome between continents that include (but are not limited to) diet, genetics, lifestyle, geography, and early life exposures though none of these factors have been shown to be directly causal regarding geographic microbiome diversity.
Gupta, Paul, and Dutta (2017) question the case of a universal definition of a ‘healthy microbiome’ since it varies by geographic ancestry. Of course, ancestry and geographic location influence culture which influences diet which influences microbiome diversity between populations. This, of course, makes sense. why have a universal healthy microbiome with a reference man that doesn’t reflect the diversity of both the individual and group differences in the microbiome? This will better help different populations with different microbiomes lose weight and better manage diseases in certain populations.
The microbiome of athletes also differs, too. Athletes had enhanced microbiome diversity when compared to non-athletes (Clarke et al, 2016). In a further follow-up study, it was found that microbial diversity correlated with both protein consumption and creatine kinase levels in the body (Clarke et al, 2017) are proxies for exercise, and since they’re all associations, causality remains to be untangled. Nevertheless, these papers are good evidence that both lifestyle and diet leads to changes in the microbiome.
Fortenberry (2013: 165) notes that American racial and ethnic classifications are “social and political in origin and represent little meaningful biologic basis of between-group racial/ ethnic diversity“. It is also known that eating habits, differing lifestyles and metabolic levels also influence the diversity of the microbiome in the three ‘races’* studied (Chen et al, 2016), while deep sequencing of oral microbiota has the ability to classify “African Americans with a 100% sensitivity and 74% specificity and Caucasians with a 50% sensitivity and 91% specificity” (Mason et al, 2014). The infant microbiome, furthermore, is influenced by maternal diet and breastfeeding as well as the infant’s diet (Stearns et al, 2017). This is why differences in race/ethnicity call into question the term of ‘healthy human microbiota’ (Gupta, Paul, and Dutta, 2017). These differences in the microbiome also lead to increased risk for colorectal cancer in black Americans (Goyal et al, 2016; Kinross, 2017).
Further, the healthy vagina “contains one of the most remarkably structured microbial ecosystems, with at least five reproducible community types, or “community state types” (Lloyd-Price, Abu-Ali, and Huttenhower 2016). The diversity of the microbiome in the vagina also varies by race. It was found that 80 percent of Asian women and 90 percent of white women harbored a microbiota species named Lactobacillus, whereas only about 60 percent of ‘Hispanics’ and blacks harbored this species. The pH level, too, varied by race with blacks and ‘Hispanics’ averaging 4.7 and 5.0 and Asians and whites averaging 4.4 and 4.2. So, clearly, since Asians and whites have similar vaginal pH levels, then it is no surprise that they have similar levels of vaginal Lactobacillus, whereas blacks and ‘Hispanics’, with similar pH levels have similar vaginal levels of Lactobacillus.
White subjects also have more diverse species of microbiota than non-white subjects while also having a different microbiota structure (Chen et al, 2015). Caucasian ethnicity/race was also shown to have a lower overall microbiome diversity, but higher Bacteroidetes scores, while white babes also had lower scores of Proteobacteria than black Americans (Sordillo et al, 2017). This comes down to both diet and genetic factors (though causation remains to be untangled).
Differences in the skin microbiome also exist between the US population and South Americans (Blaser et al, 2013). They showed that Venezuelan Indians had a significantly different skin biome when compared to US populations from Colorado and New York, having more Propionibacterium than US residents. Regarding the skin microbiota in the Chinese, Leung, Wilkins, and Lee (2015) write “skin microbiomes within an individual is more similar than that of different co-habiting individuals, which is in turn more similar than individuals living in different households.” Skin microbiota also becomes similar in cohabitating couples (Ross, Doxey, and Neufeld, 2017) and even cohabitating family members and their dogs (Song et al, 2013; Cusco et al, 2017; Torres et al, 2017).
Differences between the East and West exist regarding chronic liver disease, which may come down to diet which may influence the microbiota and along with it, chronic liver disease. (Nakamoto and Schabl, 2016). The interplay between diet, the microbiome and disease is critical if we want to understand racial/ethnic differentials in disease acquisition/mortality, because the microbiome influences so many diseases (Cho and Blaser, 2012; Guinane and Cotter, 2013; Bull and Plummer, 2014; Shoemark and Allen, 2015; Zhang et al, 2015; Shreiner, Kao, and Young, 2016; Young, 2017).
The human microbiome has been called our ‘second genome’ (Zhu, Wang, and Li, 2010; Grice and Seger, 2012) with others calling it an ‘organ’ (Baquero and Nombela, 2012; Clarke et al, 2014; Brown and Hazen, 2015). This ‘organ’, our ‘second genome’ can also influence gene expression (Masotti, 2012; Maurice, Haiser, and Turnbaugh, 2013; Byrd and Seger, 2015) which could also have implications for racial differences in disease acquisition and mortality. This is why the study of the microbiome is so important; since the microbiome can up- and down-regulate gene expression—effectively, turning genes ‘on’ and ‘off’—then understanding the intricacies that influence the microbiome diversity along with the diet that one consumes will help us better understand racial differences in disease acquisition. Diet is a huge factor not only regarding obesity and diabetes differences within and between populations, but a ‘healthy microbiome’ also staves off obesity. This is important. The fact that the diversity of microbiota in our gut can effectively up- and down-regulate genes shows that we can, in effect, influence some of this ourselves by changing our diets, which would then, theoretically, lower disease acquisition and mortality once certain microbiome/diet/disease associations are untangled and shown to be causative.
Finally, the Hadza have some of the best-studied microbiota, and since they still largely live a hunter-gatherer lifestyle, this is an important look at what the diversity of microbiota may have looked like in our hunter-gatherer ancestors (Samuel et al, 2017). The fact that they noticed such diverse changes in the microbiome—some species effectively disappearing during the dry season and reappearing during the wet season—is good proof that what drives these changes in the diversity of the microbiota in the Hadza are seasonal changes in diet which are driven by the wet and dry seasons.
Gut microbiota may also influence our mood and behavior, and it would be interesting to see which types of microbiota differ between populations and how they would be associated with certain behaviors. The microbes are a part of the unconscious system which regulates behavior, which may have causal effects regarding cognition, behavioral patterns, and social interaction and stress management; this too makes up our ‘collective unconscious’ (Dinan et al, 2015). It is clear that the microbes in our gut influence our behavior, and it even may be possible to ‘shape our second genome’ (Foster, 2013). Endocrine and neurocrine pathways may also be involved in gut-microbiota-to-brain-signaling, which can then alter the composition of the microbiome and along with it behavior (Mayer, Tillisch, and Gupta, 2015). Gut microbiota also plays a role in the acquisition of eating disorders, and identifying the specific microbiotal profiles linked to eating disorders, why it occurs and what happens while the microbiome is out of whack is important in understanding our behavior, because the gut microbiome also influences our behavior to a great degree.
The debate on whether or not racial/ethnic differences in microbiome diversity differs due to ‘nature’ or ‘nurture’ (a false dichotomy in the view of developmental systems theory) remains to be settled (Gupta, Paul, and Dutta, 2017). However, like with all traits/variations in traits, it is due to a complex interaction of the developmental system in question along with how it interacts with its environment. Understanding these complex disease/gene/environment/microbiotal pathways will be a challenge, as will untangling direct causation and what role diet plays regarding the disease/microbiota/dysbiosis factor. As we better understand our ‘second genome’, our ‘other organ’, and individual differences in the genome and how those genomic differences interact with different environments, we will then be able to give better care to both races/ethnies along with individuals. Just like with race and medicine—although there is good correlative data—we should not jump to quick conclusions based on these studies on disease, diet, and microbiotal diversity.
The study of ethnic/racial/geographic/cultural/SES differences in the diversity of the microbiome and how it influences disease, behaviors and gene expression will be interesting to follow in the next couple of years. I think that there will be considerable ‘genetic’ (i.e., differences out of the womb; I am aware that untangling ‘genetic’ and ‘environmental’ in utero factors is hard, next to impossible) differences between populations regarding newborn children, and I am sure that even the microbiota will be found to influence our food choices in the seas of our obesogenic environments. The fact that our microbiota is changeable with diet means that, in effect, we can have small control over certain parts of our gene expression which may then have consequences for future generations of our offspring. Nevertheless, things such as that remain to be uncovered but I bet more interesting things never dreamed of will be found as we look into the hows and whys of both individual and populational differences in the microbiome.
