
Home » 2019
Yearly Archives: 2019
Correlation and Causation Regarding the Etiology of Lung Cancer in Regard to Smoking
1550 words
The etiology of the increase in lung cancer over the course of the 20th century has been a large area of debate. Was it smoking that caused cancer? Or was some other, unknown, factor the cause? Causation is multifactorial and multi-level—that is, causes of anything are numerous and these causes all interact with each other. But when it comes to smoking, it was erroneously argued that genotypic differences between individuals were the cause of both smoking and cancer. We know now that smoking is directly related to the incidence of lung cancer, but in the 20th century, there were researchers who were influenced and bribed to bring about favorable conclusions for the tobacco companies.
Psychologist Hans Eysenck (1916-1997) was a controversial psychologist researching many things, perhaps most controversially, racial differences in intelligence. It came out recently, though, that he published fraudulent papers with bad data (Smith, 2019). He, among other weird things, believed that smoking was not causal in regard to cancer. Now, why might Eysenck think that? Well, he was funded by many tobacco companies (Rose, 2010; Smith, 2019). He accepted money from tobacco companies to attempt to disprove the strong correlation between smoking and cancer. Between the 1977-1989, Eysenck accepted about 800,000 pounds from tobacco companies. He is not alone in holding erroneous beliefs such as this, however.
Biostatistician Ronald Fisher (1890-1962) (a pipe smoker himself), the inventor of many statistical techniques still used today, also held the erroneous belief that smoking was not causal in regard to cancer (Parascandola, 2004). Fisher (1957) argued in a letter to the British Medical Journal that while there was a correlation between smoking and the acquisition of lung cancer, “both [are] influenced by a common cause, in this case the individual genotype.” He went on to add that “Differentiation of genotype is not in itself an unreasonable possibility“, since it has been shown that genotypic differences in mice precede differences “in the frequency, age-incidence and type of the various kinds of cancer.”
So, if we look at the chain it goes like this: people smoke; people smoking is related to incidences in cancer; but it does not follow that since people smoke that the smoking is the cause of cancer, since an unknown third factor could cause both the smoking and cancer. So now we have four hypotheses: (1) Smoking causes lung cancer; (2) Lung cancer causes smoking; (3) Both smoking and lung cancer are caused by an unknown third factor. In the case of (3), this “unknown third factor” would be the individual genotype; and (4) the relationship is spurious . Fisher was of the belief that “although lung cancer occurred in cigarette smokers it did not necessarily follow that the cancer was caused by cigarettes because there might have been something in the genetic make up of people destined to have lung cancer that made them addicted to cigarettes” (Cowen, 1999). Arguments of this type were popular in the 19th and 20th century—what I would term ‘genetic determinists’ arguments, in that genes dispose people to certain behaviors. In this case, genes disposed people to lung cancer which made them addicted to cigarettes.
Now, the argument is as follows: Smoking, while correlated to cancer is not causal in regard to cancer. Those who choose to smoke would have acquired cancer anyway, as they were predisposed to both smoke and acquire cancer at X age. We now know, of course, that such claims are ridiculous—no matter which “scientific authorities” they come from. Fisher’s idea was that differences in genotype caused differences in cancer acquisition and so along with it, caused people to either acquire the behavior of smoking or not. While at the time such an argument could have been seen as plausible, the mounting evidence against the argument did nothing to sway Fisher’s belief that smoking did not outright cause lung cancer.
The fact that smoking caused lung cancer was initially resisted by the mainstream press in America (Cowen, 1999). Cowen (1999) notes that Eysenck stated that, just because smoking and lung cancer were statistically associated, it did not follow that smoking caused lung cancer. Of course, when thinking about what causes, for example, an observed disease, we must look at similar habits they have. And if they have similar habits and it is likely that those with similar habits have the hypothesized outcome (smokers having a higher incidence of lung cancer, in this case), then it would not be erroneous to conclude that the habit in question was a driving factor behind the hypothesized disease.
It just so happens that we now have good sociological research on the foundations of smoking. Cockerham (2013: 13) cites Hughes’ (2003) Learning to Smoke: Tobacco Use in the West where he describes the five stages that smokers go through: “(1) becoming a smoker, (2) continued smoking, (3) regular smoking, (4) addicted smoking, and, for some, (5) stopping smoking.” Most people report their first few times smoking cigarettes as unpleasant, but power through it to become a part of the group. Smoking becomes somewhat of a social ritual for kids in high-school—with kids being taught how to light a cigarette and how to inhale properly. For many, starting smoking is a social thing that they do with their friends—it can be said to be similar to being social drinkers, they were social smokers. There is good evidence that, for many, their journey as smokers starts and is fully dependent on their social environment than actual physical addiction (Johnson et al, 2003; Haines, et al, 2009).
One individual interviewed in Johnson et al (2003: 1484) stated that “the social setting
of it all [smoking] is something that is somewhat addictive itself.” So, not only is the nicotine the addictive substance on the mind of the youth, so too is the social situation for the youth in which the smoking occurs. The need to fit in with their peers is one important driver for the beginning—and continuance—of the behavior of smoking. So we now have a causal chain in regard to smoking, the social, and disease: youths are influenced/pressured to smoke by their social group which then leads to addiction and then, eventually, health problems such as lung cancer.
The fact that the etiology of smoking is social leads us to a necessary conclusion: change the social network, change the behavior. Just as people begin smoking in social groups, so too, do people quit smoking in social groups (Christakis and Fowler, 2008). We can then state that, on the basis of the cited research, that the social is ultimately causal in the etiology of lung cancer—the vehicle of cancer-causation being the cigarettes pushed bu the social group.
Eysenck and Fisher, two pioneers of statistics and different methods in psychology, were blinded by self-interest. It is very clear with both Eysenck and Fisher, that their beliefs were driven by Big Tobacco and the money they acquired from them. Philosopher Donald Davidson famously stated that reasons are causes for actions (Davidson, 1963). Eysenck’s and Fisher’s “pro-belief” (in this case, the non-causation of smoking to lung cancer) would be their “pro-attitude” and their beliefs lead to their actions (taking money from Big Tobacco in an attempt to show that cigarettes do not cause cancer).
The etiology of lung cancer as brought on by smoking is multifactorial, multilevel, and complex. We do have ample research showing that the beginnings of smoking for a large majority of smokers are social in nature. They begin smoking in social groups, and their identity as a smoker is then refined by others in their social group who see them as “a smoker.” Since individuals both begin smoking in groups and quitting in groups, it then follows that the acquisition of lung cancer can be looked at as a social phenomenon as well, since most people start smoking in a peer group.
The lung cancer-smoking debate is one of the best examples of the dictum post hoc, ergo propter hoc—or, correlation does not equal causation (indeed, this is where the dictum first originated). While Fisher and Eysenck did hold to that view in regard to the etiology of lung cancer (they did not believe that since smokers were more likely to acquire lung cancer that smoking caused lung cancer), it does speak to the biases the two men had in their personal and professional lives. These beliefs were disproven by showing a dose-dependent relationship in regard to smoking and lung cancer: heavier smokers had more serious cancer incidences, which tapered down the less an individual smoked. Fisher’s belief, though, that differences in genotype caused both behavior that led to smoking and the lung cancer itself, while plausible at the time, was nothing more than a usual genetic determinist argument. We now know that genes are not causes on their own; they do not cause traits irrespective of their uses for the physiological system (Noble, 2012).
Everyone is biased—everyone. Now, this does not mean that objective science cannot be done. But what it does show is that “… scientific ideas did not develop in a vacuum but rather reflected underlying political or economic trends” (Hilliard, 2012: 85). This, and many more examples, speak to the biases of scientists. For reasons like this, though, is why science is about the reproduction of evidence. And, for that, the ideas of Eysenck and Fisher will be left in the dustbin of history.
African Neolithic Part 2: Misunderstandings Continue
Last time I’ve posted on this subject, it was dissecting the association between magical thinking and technological progress among Africans proposed by Rinderman. In general, I found it wanting of an up-to-date understanding of African anthropology, either in material culture or belief systems. This time, however, the central subject can’t be dismissed on the matter of ignorance. In fact, in a rather awkward way, his dismissal in on the grounds of how much he knows in bot his field and his own writings.
Henry Harpending, deceased, has been listed by the SPLC as a “white nationalist”, though it is the specific content of his quotes in regards to Africans, in light of his admittedly impressive contributions to SW African anthropology, is the major focus than classifying the nature of his bias. The claims in question are
- He has never meet an African who has a hobby, that is, one with the inclination to work.
- Hunter Gatherers are impulsive, lazy, and violent.
- Africans are more interested in breeding than raising children.
- Africans, Baltimore Aframs, and PNG natives all share the same behavior in regard to points 2 and 3.
- Superstitions are pan-african and the only Herero he’s met that was an atheist had a ethnic German Father.
So Harpending seemingly has the edge given his background in Anthropology with specific experiences with Africans…this only makes the only more painful to articulate.
- This will set the theme for the nature of my responses…his own work contradicts these assertions. The Herero refugee descent from Botswana, the main strain of Bantu-Speaking Africans he had studied, were described and calculated as prosperous in regards to cattle per capita and ownership of rural homesteads that stand apart from typical Botswana farming infrastructure.
Today, they are perceived as one of the wealthiest ethnic groups inBotswana and Namibia. They are known for their large herds, for theirs kill at managing cattle, and for their endogamy and staunch ethnicity even while participating fully in the developing economy and educational system of Botswana.
His research even noted how age five is when Herero begin herding. A similar phenomenon is noted among the Dinka which prompted Dutton to review the literature of their intelligence scores.
- Violence among the Khoi-San groups I’ll admit has been undermined. However, the Hadza, known for their discourage mean of conflict, express this through much lower rates of violent deaths compared to most others. The general consensus is that there is a mix, with the general trend towards higher rates but with cautious interpretation into the causes. On the charge of Laziness, however, is once again unfounded by his work on the lesser resources faced by mobile bands of foragers compared to sedentary ones on labor camps. The same link on the Hadza also pinpoints the hours spent in HG life working and accounts for the difficulty of those hours.
- Harpending actually made a model of cads versus dads that he actually attributed to non-genetic factors. Otherwise, we are left with his work on the oddity of “Herero Households”.
If women cannot provision themselves and their offspring without
assistance, then the “cad/breeder” corner of Fig. 2 is not feasible, and we are left with “dad/feeder.” Draper and Harpending argue that this is true of the Ju/’hoansi, and other mobile foragers in marginal habitats. Among swidden agriculturalists, on the other hand, female labor is more productive, and men can afford to do less work. The theory thus predicts that such populations will be more likely to fall into the “cad/breeder” equilibrium, as in fact they seem to do. Although this theory is couched in Darwinian terms, Harpending and Draper do not see genetic evolution as the engine that accounts for variation within and among societies. Instead, they suggest a facultative adaptation: humans have “evolved the ability to sense household structure in infancy” and to alter their developmental trajectories in response to what is learned during this early critical period (1980, p. 63).There does not seem to be any durable group of associated individuals that we could usefully characterize as a household among the Herero. If forced we would say that the Herero have two parallel types of households. The “male household” is the homestead, consisting of an adult male, his wives, sisters, and other relatives, and it is defined by the herd and the kraals that he maintains for the herd. The “female household” is a woman and the children for whom she has responsibility, localized in a hut or hut cluster within a larger homestead. These aregynofocal households, rather than matrifocal households, since matrifocal implies mother and offspring while the Herero unit is a woman and children under the care of that woman. These children may be her own, her grandchildren, children of relatives, or even children leased from other tribes to work on the cattle. Men do not appear prominently in daily domestic life. They are gone at first light pursuing their own interests and careers with cattle, with hunting parties, or with other stereotyped male activities. Similarly, women are not prominently present at male areas like the wells where the cattle are watered. There is, then, not a Herero household, but rather there is a Herero male household that includes cattle and female households, and these females may be wives, or sisters, or other female relatives. The female households are the loci of domestic production and consumption.
However, it does not follow that the lack of interpersonal interaction means the lack of acknowledgement in parenthood within households. One is by association.
We interviewed 161 adult Herero (112 females, 49 males) intensively about the residence of themselves, their siblings with whom they share a mother or a father and about their legal children (children born in marriage or children in whom they had purchased parental rights). None of the men we interviewed whose fathers were still alive (n = 10) considered his residence to be in a homestead different from his father’s. Only two of the men had sons with residences elsewhere –one was a child who had been purchased but was living with the mother and the other was a child borne by a wife from whom he was now divorced. We also heard of very few men ascertained in several hundred shorter demographic interviews that were residing in a homestead other than their fathers’. Most of the men(24/39) with deceased fathers had their own homesteads. Brothers who had both the same mother and father were more likely to stay together, however, than brothers who had different mothers.
The other comes from Harpending’s own blog post regarding his Herero friend who claims the children of his new wife as being of his household despite not actually conceiving them. Note, he also describes the man as “prosperous”.
- I sadly lack data on Bantu rates of violence, swearing I once found data showing it to be low compared to that of the Khoi-san. If anybody has quantified data like in the link regarding the Hadza then that would be appreciated. In regards to parenting however it doesn’t reflect that by comparing non-resident fathers. Regarding Africans, here’s a perspective from a female perspective.
- This point once again warrants the mention of superstitions still being quite common in non Western societies like China in regards to evil spirits and luck. Likewise, traditions are known to be modified or dropped among Herero in major urban centers. The Herero Harpending encountered that he labeled “employees” nonetheless grew up near the study areas.
Before I end this, I want to cover some further discrepancies by another author who refers to his work, Steve Sailer.
The small, yellow-brown Bushmen, hunters who mated more or less for life and put much effort into feeding their nuclear families, reminded Henry of his upstate New York neighbors. If fathers didn”t work, their children would go hungry.
In contrast, the Bantu Herero (distant relatives of American blacks) were full of surprises. In general, black African men seemed less concerned with bringing home the bacon to provision their children than did Bushmen dads.
This doesn’t deviate too far from what Harpending explains. That comes later.
In black African farming cultures, women do most of the work because agriculture involves light weeding with hoes rather than heavy plowing. Men are less expected to contribute functionally to their children’s upkeep, but are expected to be sexy.
So technically this is correct but only to a certain degree in regards to division of labor. It’s particular to farming schemes where root/tuber agriculture is done, and in those areas forest clearing is done by males.
One parallel is that Baumann views climatic and environmental factors as closely
associated with differences in the participation of the sexes in agriculture. He observes that the northern boundary of women’s predominance in agriculture is constrained by the limits of the tropical forest region, and that the boundary of female agriculture also tends to coincide with that between root crops and cereal grains. Baumann’s view of the economies of labor is also similar to our own. He emphasizes that land clearing is more difficult in the forest than in the savannah, and that males often perform clearing in the forest zones in spite of the predominance of female labor, whereas soil preparation is more difficult in the savannah than in the forest. He notes the higher male participation in agriculture in the savannah region of the Sudan than in the West African and Congo forest regions, and more generally, that women are much more likely to participate in root cultivation than in cereal cultivation.
Not mention other activities such as crafts and trading. Baumann’s old scheme as it is is still simplistic. More research shows that labor between sexes shift depending on circumstances. See this on Igbo yam farming or West African Cocoa farming. This trend of shifting continues into the modern day.
In many places in Africa, traditionally there has been a
strict division of labor by gender in agriculture. This
division of labor may be based on crop or task, and both
types of division of labor by gender may occur
simultaneously. Women may mobilize male labor for some
tasks involved in their crops and men frequently mobilize
women’s labor for crops that they control. These divisions
are not static and may change in response to new
economic opportunities.
Likewise, male development in connection to their father is represented in this early anthropological text through inheritance of property and apprenticeship. Collective Fatherhood through the extended family is also recognized, with actual absence being highly due to migrant labor in Southern African countries.
The “Sexy” part is rather presumptuous and absent from the text, where it is in fact the woman that is scrutinized uphold standards in the chapter of Ibo courtship, which seems to be widespread. The simple and lazy role reversal is obvious, as it assumes that female labor undermined the general trend of patriarchy since they weren’t always dependent on the male.
So with all this said, what is there to make of it?: As far as direct connections to the Herero go, Harpending didn’t show any particular malice. Any such was more towards western phenomenon that he draws parallels with. As far as his conference comments, obvious bias is just that. His blog posts don’t even read as such, clearly contradicting it comments of industry among Africans according to his experience for one matter.
It may sadly suggest the type of filter scene through experience in this “field”.
“Definitions” of ‘Intelligence’ and its ‘Measurement’
1750 words
What ‘intelligence’ is and how, and if, we can measure it has puzzled us for the better part of 100 years. A few surveys have been done on what ‘intelligence’ is, and there has been little agreement on what it is and even if IQ tests measure ‘intelligence.’ Richardson (2002: 284) noted that:
Of the 25 attributes of intelligence mentioned, only 3 were mentioned by 25 per cent or more of respondents (half of the respondents mentioned ‘higher level components’; 25 per cent mentioned ‘executive processes’; and 29 per cent mentioned ‘that which is valued by culture’). Over a third of the attributes were mentioned by less than 10 per cent of respondents (only 8 per cent of the 1986 respondents mentioned ‘ability to learn’).
As can be seen, even IQ-ists today cannot agree upon a definition—indeed, even Ian Deary admits that “There is no such thing as a theory of human intelligence differences—not in the way that grown-up sciences like physics or chemistry have theories” (quoted in Richardson, 2012). (Also note that attempts of validity are circular, relying on correlations with other, similar tests; Richardson and Norgate, 2015; Richardson, 2017b.)
Linda Gottfredson, University of Delaware sociologist and well-known hereditarian, is a staunch defender of JP Rushton (Gottfredson, 2013) and the hereditarian hypothesis (Gottfredson, 2005, 2009). Her ‘definition’ of intelligence is one of the most-oft cited ones, eg, Gottfredson et al (1993: 13) notes that (my emphasis):
Intelligence is a very general mental capability that, among other things, involves the ability to reason, plan, solve problems, think abstractly, comprehend complex ideas, learn quickly and learn from experience. It is not merely book learning, a narrow academic skill, or test-taking smarts. Rather, it reflects a broader and deeper capability for comprehending our surroundings-“catching on,” “ making sense” of things, or “figuring out” what to do.
So ‘intelligence’ is “a very general mental capability”, its main ‘measure’ IQ tests (knowledge tests), but ‘intelligence’ “is not merely book learning, a narrow academic skill, or test-taking smarts.” Here’s some more hereditarian “reasoning” (which you can contrast with the hereditarian “reasoning” on race—just assume it exists). Gottfredson also argues that ‘intelligence’ or ‘g’ is learning ability. But, as Richardson (2017a: 100) notes, “it will always be quite impossible to measure ability with an instrument that depends on learning in one particular culture“—which he terms “the g paradox, or a general measurement paradox.”
Gottfredson (1997) also argues that the “active ingredient” in IQ testing is the “complexity” of the items—what makes one item more difficult than another, such as a 3×3 matrix item being more complex than a 2×2 matrix item and giving some examples of analogies which she believes to show a type of higher, more complex cognition in order to figure out the answer to the problem. (Also see Richardson and Norgate, 2014 for further critiques of Gottfredson.)
The trouble with this argument is that IQ test items are remarkably simple in their cognitive demands compared with, say, the cognitive demands of ordinary social life and other activities that the vast majority of children and adults can meet adequately every day.
For example, many test items demand little more than rote reproduction of factual knowledge most likely acquired from experience at home or by being taught in school. Opportunities and pressures for acquiring such valued pieces of information, from books in the home to parents’ interests and educational level, are more likely to be found in middle-class than in working-class homes. So the causes of differences could be causes in opportunities for such learning.
The same could be said about other frequently used items, such as “vocabulary” (or word definitions); “similarities” (describing how two things are the same); “comprehension” (explaining common phenomena, such as why doctors need more training). This helps explain why differences in home background correlate so highly with school performance—a common finding. In effect, such items could simply reflect the specific learning demanded by the items, rather than a more general cognitive strength. (Richardson, 2017a: 91)
IQ-ists, of course, would then state that there is utility in such “simple-looking” test items, but we have to remember that items on IQ tests are not selected based on a theoretical cognitive model, but are selected to give the desired distributions that the test constructors want (Mensh and Mensh, 1991). “… those items in IQ tests have been selected because they help produce the expected pattern of scores. A mere assertion of complexity about IQ test items is not good enough” (Richardson, 2017a: 93). “The items selected for inclusion [on Binet’s test] were those that in the judgment of the teachers distinguished bright from dull students” (Castles, 2012: 88). It seems that all hereditarians do is “assert” or “assume” things—like the equal environments assumption (EEA), the existence of race, and now, the existence of “intelligence”. Just presuppose what you want and, unsurprisingly, you get what you wanted. The IQ-ist then triumphs that the test did its job—sorting high- and low-quality thinkers on the basis of their IQ scores. But that’s exactly the problem: prior assumptions on the nature of ‘intelligence’ and its distribution dictate the construction of the tests in question.
Mensh and Mensh (1991: 30) state that “The [IQ] tests do what their construction dictates; they correlate a group’s mental worth with its place in the social hierarchy.” That is, who is or is not “intelligent” is already presupposed. There has been ample admission of such presumptions affecting the distribution of scores, as some critics have documented (e.g., Hilliard, 2012’s documentation of test norming for two different white cultural groups in South Africa and that Terman equalized scores on his 1937 revision of the Stanford-Binet).
Herrnstein and Murray (1994: 1) write that:
That the word intelligence describes something real and that it varies from person to person is as universal and ancient as any understanding about the state of being human. Literate cultures everywhere and throughout history have had words for saying that some people are smarter than others. Given the survival value of intelligence, the concept must be still older than that. Gossip about who in the tribe is cleverest has probably been a topic of conversation around the fire since fires, and conversation, were invented.
Castles (2012: 83) responds to these assertions stating that “the concept of intelligence is indeed a “brashing modern notion.” 1” Herrnstein and Murray, of course, are in the “Of COURSE intelligence exists!” camp, for, to them, it conferred survival advantages and so, it must exist and we can, therefore, measure it in humans.
Howe (1997), in his book IQ in Question, asks us to imagine someone asking to construct a vanity test. Vanity, like ‘intelligence’, has no agreed-upon definition which states how it should be measured nor anything that makes it possible to check that we are measuring the supposed construct correctly. So the one who wants to assess vanity needs to construct a test with questions he presumes tests vanity. So if the questions he asks relates to how others perceive vanity, then the ‘vanity test’ has been successfully constructed and the test constructor can then believe that he’s measuring “differences in” vanity. But, of course, selecting items on a test is a subjective matter; there is no objective way for this to occur. We can say, with length for instance, that line A is twice as long as line B. But we could not, then, state that person A is twice as vain as person B—nor could we say that person A is twice as intelligent as person B (on the basis of IQ scores)—for what would it mean for someone to be twice as vain as someone else, just like what would it mean for someone to be twice as intelligent as someone else?
Howe (1997: 6) writes:
The measurement of intelligence is bedeviled by the same problems that make it virtually impossible to measure vanity. It is of course possible to construct intelligence tests, and the tests can be useful in a number of ways for assessing human mental abilities, but it is wrong to assume that such tests have the capability of measuring an underlying quality of intelligence, if by ‘measuring’ we have in mind the same operations that are involved in the measurement of a physical quality such as length. A psychological test score is no more than an indication of how well someone has performed at a number of questions that have been chosen for largely practical reasons. Nothing is genuinely being measured.
But if “A psychological test score is no more an indication of how well someone has performed at a number of questions that have been chosen largely for practical reasons”, then it follows that knowledge exposure explains outcomes in psychological test scores. Richardson (1998: 127) writes:
The most reasonable answer to the question “What is being measured?”, then, is ‘degree of cultural affiliation’: to the culture of test constructors, school teachers and school curricula. It is (unconsciously) to conceal this that all the manipulations of item selection, evasions about test validities, and searches for post hoc theoretical underpinning seem to be about. What is being measured is certainly not genetically constrained complexity of general reasoning ability as such,
Mensh and Mensh (1991: 73) note that “In reality — which is precisely the opposite of what Jensen claims it to be — test discrimination among individuals within any group is the incidental by-product of tests constructed to discriminate between groups. Because the tests’ class and racial bias ensures that some groups will be higher and others lower in the scoring hierarchy, the status of an individual member of a group is as a rule predetermined by the status of that group.”
In sum, what these tests test is what the test constructors presume—mainly, class and racial bias—so they get what they want to see. If the test does not match their presuppositions, the test gets discarded or reconstructed to fit with their biases. Thus, definitions of ‘intelligence’ will always be, as Castles (2012: 29), “intelligence is a cultural construct, specific to a certain time and place.” The definition from Gottfredson doesn’t make sense, as the “test-taking smarts” is the main “measure” of ‘intelligence’, and so intelligence’s “main measure” is the IQ test—which presupposes the distribution of scores as developed by the test constructors (Mensh and Mensh, 1991). Herrnstein and Murray’s definition does not make sense either, as the concept of “intelligence” is a modern notion.
At best, IQ test scores measure the degree of cultural acquisition of knowledge; they do not, nor can they, measure ‘intelligence’—which is a cultural concept which changes with the times. The tests are inherently biased against certain groups; looking at the history and construction of IQ testing will make that clear. The tests are middle-class knowledge tests; not tests of ‘intelligence.’
The “World’s Smartest Man” Christopher Langan on Koko the Gorilla’s IQ
1500 words
Christopher Langan is purported to have the highest IQ in the world, at 195—though comparisons to Wittgenstein (“estimated IQ” of 190), da Vinci, and Descartes on their “IQs” are unfounded. He and others are responsible for starting the high IQ society the Mega foundation for people with IQs of 164 or above. For a man with one of the highest IQs in the world, he lived on a poverty wage at less than $10,000 per year in 2001. He has also been a bouncer for the past twenty years.
Koko is one of the world’s most famous gorillas, most-known for crying when she was told her cat got hit by a car and being friends with Robin Williams, also apparently expressing sadness upon learning of his death. Koko’s IQ, as measured by an infant IQ test, was said to be on-par or higher than some of the (shoddy) national IQ scores from Richard Lynn (Richardson, 2004; Morse, 2008). This then prompted white nationalist/alt-right groups to compare Koko’s IQ scores with that of certain nationalities and proclaim that Koko was more ‘intelligent’ than those nationalities on the basis of her IQ score. But, unfortunately for them, the claims do not hold up.
The “World’s Smartest Man” Christopher Langan is one who falls prey to this kind of thinking. He was “banned from” Facebook for writing a post comparing Koko’s IQ scores to that of Somalians, asking why we don’t admit gorillas into our civilization if we are letting Somalian refugees into the West:
“According to the “30 point rule” of psychometrics (as proposed by pioneering psychometrician Leta S. Holingsworth), Koko’s elevated level of thought would have been all but incomprehensible to nearly half the population of Somalia (average IQ 68). Yet the nation’s of Europe and North America are being flooded with millions of unvetted Somalian refugees who are not (initially) kept in cages despite what appears to be the world’s highest rate of violent crime.
Obviously, this raises the question: Why is Western Civilization not admitting gorillas? They too are from Africa, and probably have a group mean IQ at least equal to that of Somalia. In addition, they have peaceful and environmentally friendly cultures, commit far less violent crime than Somalians…”
I presume that Langan is working off the assumption that Koko’s IQ is 95. I also presume that he has seen memes such as this one floating around:

There are a few problems with Langan’s claims, however. (1) The notion of a “30-point IQ point communication” rule—that one’s own IQ, plus or minus 30 points, denotes where two people can understand each other; and (2) bringing up Koko’s IQ and the comparing it to “Somalians.”
It seems intuitive to the IQ-ist that a large, 2 SD gap in IQ between people will mean that more often than not there will be little understanding between them if they talk, as well as the kinds of interests they have. Neuroskeptic looked into the origins of the claim of the communication gap in IQ, found it to be attributed to Leta Hollingworth and elucidated by Grady Towers. Towers noted that “a leadership pattern will not form—or it will break up—when a discrepancy of more than about 30 points comes to exist between leader and lead.” Neuroskeptic comments:
This seems to me a significant logical leap. Hollingworth was writing specifically about leadership, and in childen [sic], but Towers extrapolates the point to claim that any kind of ‘genuine’ communication is impossible across a 30 IQ point gap.
It is worth noting that although Hollingworth was an academic psychologist, her remark about leadership does not seem to have been stated as a scientific conclusion from research, but simply as an ‘observation’.
[…]
So as far as I can see the ‘communication range’ is just an idea someone came up with. It’s not based on data. The reference to specific numbers (“+/- 2 standard deviations, 30 points”) gives the illusion of scientific precision, but these numbers were plucked from the air.
The notion that Koko had an “elevated level of thought [that] would have been all but incomprehensible to nearly half the population of Somalia (average IQ 68)” (Langan) is therefore laughable, not only for the reason that a so-called communication gap is false, but for the simple fact that Koko’s IQ was tested using the Cattell Infant Intelligence Scales (CIIS) (Patterson and Linden,1981: 100). It seems to me that Langan has not read the book that Koko’s handlers wrote about her—The Education of Koko (Patterson and Linden, 1981)—since they describe why Koko’s score should not be compared with human infants, so it follows that her score cannot be compared with human adults.
The CIIS was developed “to a downward extension of the Stanford-Binet” (Hooper, Conner, and Umansky, 1986), and so, it must correlate highly with the Stanford-Binet in order to be “valid” (the psychometric benchmark for validity—correlating a new test with the most up-to-date test which had assumed validity; Richardson, 1991, 2000, 2017; Howe, 1997). Hooper, Conner, and Umansky (1986: 160) note in their review of the CIIS, “Given these few strengths and numerous shortcomings, salvaging the Cattell would be a major undertaking with questionable yield. . . . Nonetheless, without more research investigating this instrument, and with the advent of psychometrically superior measures of infant development, the Cattell may be relegated to the role of an historical antecedent.” Items selected for the CIIS—like all IQ tests—“followed a quasi-statistical approach with many items being accepted and rejected subjectively.” They state that many of the items on the CIIS need to be updated with “objective” item analysis—but, as Jensen notes, items emerge arbitrarily from the heads of the test’s constructors.
Patterson—the woman who raised Koko—notes that she “tried to gauge [Koko’s] performance by every available yardstick, and this meant administering infant IQ tests” (Patterson and Linden, 1981: 96). Patterson and Linden (1981: 100) note that Koko did better than human counterparts of her age in certain tasks over others, for example “her ability to complete logical progressions like the Ravens Progressive Matrices test” since she pointed to the answer with no hesitation.
Koko generally performed worse than children when a verbal rather than a pointing response was required. When tasks involved detailed drawings, such as penciling a path through a maze, or precise coordination, such as fitting puzzle pieces together. Koko’s performance was distinctly inferior to that of children.
[…]
It is hard to draw any firm conclusions about the gorilla’s intelligence as compared to that of the human child. Because infant intelligence tests have so much to do with motor control, results tend to get skewed. Gorillas and chimps seem to gain general control over their bodies earlier than humans, although ultimately children far outpace both in the fine coordination required in drawing or writing. In problems involving more abstract reasoning, Koko, when she is willing to play the game, is capable of solving relatively complex problems. If nothing else, the increase in Koko’s mental age shows that she is capable of understanding a number of the principles that are the foundation of what we call abstract thought. (Patterson and Linden, 1981: 100-101)
They conclude that “it is specious to compare her IQ directly with that of a human infant” since gorillas develop motor skills earlier than human infants. So if it is “specious” to compare Koko’s IQ with an infant, then it is “specious” to compare Koko’s IQ with the average Somalian—as Langan does.
There have been many critics of Koko, and similar apes, of course. One criticism was that Koko was coaxed into signing the word she signed by asking Koko certain questions, to Robert Sapolsky stating that Patterson corrected Koko’s signs. She, therefore, would not actually know what she was signing, she was just doing what she was told. Of course, caregivers of primates with the supposed extraordinary ability for complex (humanlike) cognition will defend their interpretations of their observations since they are emotionally invested in the interpretations. Patterson’s Ph.D. research was on Koko and her supposed capabilities for language, too.
Perhaps the strongest criticism of these kinds of interpretations of Koko comes from Terrace et al (1979). Terrace et al (1979: 899) write:
The Nova film, which also shows Ally (Nim’s full brother) and Koko, reveals a similar tendency for the teacher to sign before the ape signs. Ninety-two percent of Ally’s, and all of Koko’s, signs were signed by the teacher immediately before Ally and Koko signed.
It seems that Langan has never done any kind of reading on Koko, the tests she was administered, nor the problems in comparing them to humans (infants). The fact that Koko seemed to be influenced by her handlers to “sign” what they wanted her to sign, too, makes interpretations of her IQ scores problematic. For if Koko were influenced what to sign, then we, therefore, cannot trust her scores on the CIIS. The false claims of Langan are laughable knowing the truth about Koko’s IQ, what her handlers said about her IQ, and knowing what critics have said about Koko and her sign language. In any case, Langan did not show his “high IQ” with such idiotic statements.
China’s Project Coast?
1250 words
Project Coast was a secret biological/chemical weapons program developed by the apartheid government in South Africa started by a cardiologist named Wouter Basson. One of the many things they attempted was to develop a bio-chemical weapon that targets blacks and only blacks.
I used to listen to the Alex Jones show in the beginning of the decade and in one of his rants, he brought up Project Coast and how they attempted to develop a weapon to only target blacks. So I looked into it, and there is some truth to it.
For instance, The Washington Times writes in their article Biotoxins Fall Into Private Hands:
More sinister were the attempts — ordered by Basson — to use science against the country’s black majority population. Daan Goosen, former director of Project Coast’s biological research division, said he was ordered by Basson to develop ways to suppress population growth among blacks, perhaps by secretly applying contraceptives to drinking water. Basson also urged scientists to search for a “black bomb,” a biological weapon that would select targets based on skin color, he said.
“Basson was very interested. He said ‘If you can do this, it would be very good,'” Goosen recalled. “But nothing came of it.”
They created novel ways to disperse the toxins: using letters and cigarettes to transmit anthrax to black communities (something those old enough to be alive during 911 know of), lacing sugar cubes with salmonella, lacing beer and peppermint candy with poison.
Project Coast was, at its heart, a eugenics program (Singh, 2008). Singh (2008: 9) writes, for example that “Project Coast also speaks for the need for those involved in scientific research and practice to be sensitized to appreciate the social circumstances and particular factors that precipitate a loss of moral perspective on one’s actions.”
Jackson (2015) states that another objective of the Project was to develop anti-fertility drugs and attempt to distribute them into the black population in South Africa to decrease birth rates. They also attempted to create vaccines to make black women sterile to decrease the black population in South Africa in a few generations—along with attempting to create weapons to only target blacks.
The head of the weapons program, Wouter Basson, is even thought to have developed HIV with help from the CIA to cull the black population (Nattrass, 2012). There are many conspiracy theories that involve HIV and its creation to cull black populations, though they are pretty farfetched. In any case, though, since they were attempting to develop new kinds of bioweapons to target certain populations, it’s not out of the realm of possibility that there is a kernel of truth to the story.
So now we come to today. So Kyle Bass said that the Chinese already have access to all of our genomes, through companies like Steve Hsu’s BGI, stating that “there’s a Chinese company called BGI that does the overwhelming majority of all the sequencing of U.S. genes. … China had the genomic sequence of every single person that’s been gene types in the U.S., and they’re developing bio weapons that only affect Caucasians.”
I have no way to verify these claims (they’re probably bullshit), but with what went on in the 80s and 90s in South Africa with Project Coast, I don’t believe it’s outside of the realm of plausibility. Though Caucasians are a broad grouping.
It’d be like if someone attempted to develop a bioweapon that only targets Ashkenazi Jews. They could let’s say, attempt to make a bioweapon to target those with Tay Sach’s disease. It’s, majorly, a Jewish disease, though it’s also prevalent in other populations, like French Canadians. It’d be like if someone attempted to develop a bioweapon that only targets those with the sickle cell trait (SCT). Certain African ethnies are more like to carry the trait, but it’s also prevalent in southern Europe and Northern Africa since the trait is prevalent in areas with many mosquitoes.
With Chinese scientists like He Jiankui CRISPR-ing two Chinese twins back in 2018 to attempt to edit their genome to make them less susceptible to HIV, I can see a scientist in China attempt to do something like this. In our increasingly technological world with all of these new tools we develop, I would be surprised if there was nothing strange like this going on.
Some claim that “China will always be bad at bioethics“:
Even when ethics boards exist, conflicts of interest are rife. While the Ministry of Health’s ethics guidelines state that ethical reviews are “based upon the principles of ethics accepted by the international community,” they lack enforcement mechanisms and provide few instructions for investigators. As a result, the ethics review process is often reduced to a formality, “a rubber stamp” in Hu’s words. The lax ethical environment has led many to consider China the “Wild East” in biomedical research. Widely criticized and rejected by Western institutions, the Italian surgeon Sergio Canavero found a home for his radical quest to perform the first human head transplant in the northern Chinese city of Harbin. Canavero’s Chinese partner, Ren Xiaoping, although specifying that human trials were a long way off, justified the controversial experiment on technological grounds, “I am a scientist, not an ethical expert.” As the Chinese government props up the pseudoscience of traditional Chinese medicine as a valid “Eastern” alternative to anatomy-based “Western” medicine, the utterly unscientific approach makes the establishment of biomedical regulations and their enforcement even more difficult.
Chinese ethicists, though, did respond to the charge of a ‘Wild East’, writing:
Some commentators consider Dr. He’s wrongdoings as evidence of a “Wild East” in scientific ethics or bioethics. This conclusion is not based on facts but on stereotypes and is not the whole story. In the era of globalization, rule-breaking is not limited to the East. Several cases of rule-breaking in research involved both the East and the West.
Henning (2006) notes that “bioethical issues in China are well covered by various national guidelines and regulations, which are clearly defined and adhere to internationally recognized standards. However, the implementation of these rules remains difficult, because they provide only limited detailed instructions for investigators.” With a large country like China, of course, it will be hard to implement guidelines on a wide-scale.
Gene-edited humans were going to come sooner or later, but the way that Jiankui went about it was all wrong. Jiankjui raised funds, dodged supervision and organized researchers in order to carry out the gene-editing on the Chinese twins. “Mad scientists” are, no doubt, in many places in many countries. “… the Chinese state is not fundamentally interested in fostering a culture of respect for human dignity. Thus, observing bioethical norms run second.”
Countries attempting to develop bioweapons to target specific groups of people have already been attempted recently, so I wouldn’t doubt that someone, somewhere, is attempting something along these lines. Maybe it is happening in China, a ‘Wild East’ of low regulations and oversight. There is a bioethical divide when it comes to East and West, which I would chalk up to differences in collectivism vs individualism (which some have claimed to be ‘genetic’ in nature; Kiaris, 2012). Since the West is more individualistic, they would care about individual embryos which eventually become a person; since the East is more collectivist, whatever is better for the group (that is, whatever can eventually make the group ‘better’) will override the individual and so, tinkering with individual genomes would be seen as less of an ethical charge to them.
A Systems View of Kenyan Success in Distance Running
1550 words
The causes of sporting success are multi-factorial, with no cause being more important than the other since the whole system needs to work in concert to produce the athletic phenotype–call this “causal parity” of athletic success determinants. For a refresher, take what Shenk (2010: 107):
As the search for athletic genes continues, therefore, the overwhelming evidence suggests that researchers will instead locate genes prone to certain types of interactions: gene variant A in combination with gene variant B, provoked into expression by X amount of training + Y altitude + Z will to win + a hundred other life variables (coaching, injuries, etc.), will produce some specific result R. What this means, of course, What this means, of course, is that we need to dispense rhetorically with thick firewall between biology (nature) and training (nurture). The reality of GxE assures that each person’s genes interacts with his climate, altitude, culture, meals, language, customs and spirituality—everything—to produce unique lifestyle trajectories. Genes play a critical role, but as dynamic instruments, not a fixed blueprint. A seven- or fourteen- or twenty-eight-year-old is not that way merely because of genetic instruction. (Shenk, 2010: 107) [Also read my article Explaining African Running Success Through a Systems View.]
This is how athletic success needs to be looked at; not reducing it to genes or a group of genes that ’cause’ athletic success. Since to be successful in the sport of the athlete’s choice takes more than being born with “the right” genes.
Recently, a Kenyan woman—Joyciline Jepkosgei—won the NYC marathon in here debut (November 3rd, 2019), while Eliud Kipchoge—another Kenyan—became the first human ever to complete a marathon (26.2 miles) in under 2 hours. I recall in the spring reading that he said he would break the 2-hour mark in October. He also attempted to break it in 2017 in Italy but, of course, he failed. His official time in Italy was 2:00:25! While he set the world record in Berlin at 2:01:39. Kipchoge’s official time was 1:59:40—twenty seconds shy of 2 hours—that means his average mile pace was about 4 minutes and 34 seconds. That is insane. (But the IAAF does not accept the time as a new world record since it was not in an open competition—Kipchoge had a slew of Olympic pacesetters following him; an electric car drove just ahead of him and pointed lasers at the ground showing him where to run; so he shaved 2 minutes off his time—2 crucial minutes—according to sport scientist Ross Tucker; and . So he did not set a world record. His feat, though, is still impressive.)
Now, Kipchoge is Kenyan—but what’s his ethnicity? Surprise surprise! He is of the Nandi tribe, more specifically, of the Talai subgroup, born in Kapsisiywa in the Nandi county. Jepkosgei, too, is Nandi, from Cheptil in Nandi county. (Jepkosgei also set the record for the half marathon in 2017. Also, see her regular training regimen and what she does throughout the day. This, of course, is how she is able to be so elite—without hard training, even without “the right genetic makeup”, one will not become an elite athlete.) What a strange coincidence that these two individuals who won recent marathons—and one who set the best time ever in the 26.2 mile race—are both Kenyan, specifically Nandi?
Both of these runners are from the same county in Kenya. Nandi county is elevated about 6,716 ft above sea level. Being born and living at a high elevation means that they have different kinds of physiological adaptations due to being born at such a higher elevation. Living and training at such high elevations means that they have greater lung capacities since they are breathing in thinner air. Those born in highlands like Kipchoge and Jepkosgei have larger lungs and thorax volumes, while oxygen intake is enhanced by increases in lung compliance, pulmonary diffusion, and ventilation (Meer, Heymans, and Zijlstra, 1995).
Those exposed to such elevation develop what is known as “high-altitude hypoxia.” Humans born at high altitudes are able to cope with such a lack of oxygen, since our physiological systems are dynamic—not static—and can respond to environmental changes within seconds of them occurring. Babes born at higher elevations have increased ventilation, and a rise in the alveolar and the pressure of arterial oxygen (Meer, Heymans, and Zjilstra, 1995).
Kenyans have 5 percent longer legs and 12 percent lighter muscles than Scandinavians (Suchy and Waic, 2017). Mooses et al (2014) notes that “upper leg length, total leg length and total leg length to body height ratio were correlated with running performance.” Kong and de Heer (2008) note that:
The slim limbs of Kenyan distance runners may positively contribute to performance by having a low moment of inertia and thus requiring less muscular effort in leg swing. The short ground contact time observed may be related to good running economy since there is less time for the braking force to decelerate forward motion of the body.
An abundance of type I muscle fibers is conducive to success in distance running (Zierath and Hawley, 2004), though Kenyans and Caucasians have no difference in type I muscle fibers (Saltin et al, 1995; Larsen and Sheel, 2015). That, then, throws a wrench in the claim that a whole slew of anatomic and physiologic variables conducive to running success is the cause for Kenyan running success—specifically the type I fibers—right? Wrong. Recall that the appearance of the athletic phenotype is due to nature and nurture—genes and environment—working together in concert. Kenyans are more likely to have slim, long limbs with lower body fat while they lived and trained over 6000 ft high. Their will to win to better themselves and their families’ socioeconomic status, too, plays a part. As I have argued in-depth for years—we cannot understand athletic success and elite athleticism without understanding individual histories, how they grew up, and what they did as a child.
For example, Wilbur and Pitsiladis (2012) espouse a systems view of Kenyan marathon success, writing:
In general, it appears that Kenyan and Ethiopian distance-running success is not based on a unique genetic or physiological characteristic. Rather, it appears to be the result of favorable somatotypical characteristics lending to exceptional biomechanical and metabolic economy/efficiency; chronic exposure to altitude in combination with moderate-volume, high-intensity training (live high + train high), and a strong psychological motivation to succeed athletically for the purpose of economic and social advancement.
Becoming a successful runner in Kenya can lead to economic opportunities not afforded to those who do not do well in running. This, too, is a factor in Kenyan running success. So, for the ignorant people who would—pushing a false dichotomy of genes and environment—state that Kenyan running success is due to “socioeconomic status”—they are right, to a point (even if they are mocking it and making their genetic determinism seem more palatable). See figure 6 for their hypothetical model:

This is one of the best models I have come across explaining the success of these people. One can see that it is not reductonist; note that there is no appeal to genes (just variables that genes are implicated IN! Which is not the same as reductionism). It’s not as if one can have an endomorphic somatotype with Kenyan training and their psychological reasons for becoming runners. The ecto-dominant somatotype is a necessary factor for success; but all four of these—biomechanical & physiological, training, and psychological—factors explain the success of the running Kenyans and, in turn, the success of Kipchoge and Jepkosgei. African dominance in distance running is, also, dominated by the Nandi subtribe (Tucker, Onywera, and Santos-Concejero, 2015). Knechtle et al (2016) also note that male and female Kenyan and Ethiopian runners are the youngest and fast at the half and full marathons.
The actual environment—climate—on the day of the race, too plays a factor. El Helou et al (2012) note that “Air temperature is the most important factor influencing marathon running performance for runners of all levels.” Nikolaidis et al (2019) note that “race times in the Boston Marathon are influenced by temperature, pressure, precipitations, WBGT, wind coming from the West and wind speed.”
The success of Kenyans—and other groups—shows how the dictum “Athleticism is irreducible to biology” (St. Louis, 2004) is true. How does it make any sense to attempt to reduce athletic success down to one variable and say that that explains the overrepresentation of, say, Kenyans in distance running? A whole slew of factors needs to occur to an individual, along with actually wanting to do something, in order for them to succeed at distance running.
So, what makes Kenyans like Kipchoge and Jepkosgei so good at distance running? It’s due to an interaction with genes and environment, since we take a systems and not a reductionist view of sport success. Even though Kipchoge’s time does not count as an official world record, what he did was still impressive (though not as impressive if he would have done so without all of the help he had). Looking at the system, and not trying to reduce the system to its parts, is how we will explain why some groups are better than others. Genes, of course, play a role in the ontogeny of the athletic phenotype, but they are not the be-all-end-all that genetic reductionists seem to make it out to be. The systems view for Kenyan running success shown here is how and why Kenyans—Kipchoge and Jepkosgei—dominate distance running.
The History and Construction of IQ Tests
4100 words
The [IQ] tests do what their construction dictates; they correlate a group’s mental worth with its place in the social hierarchy. (Mensh and Mensh, 1991, The IQ Mythology, pg 30)
We have been attempting to measure “intelligence” in humans for over 100 years. Mental testing began with Galton and then shifted over to Binet, which then became the most-well-known IQ tests today—Stanford-Binet and the WAIS/WISC. But the history of IQ testing is rife with unethical conclusions derived from their use, along with such conclusions they drew actually being carried out (i.e., the sterilization of “morons”; see Wilson, 2017’s The Eugenic Mind Project).
History of IQ testing
Any history of ‘intelligence’ testing will, of course, include Francis Galton’s contributions to the creation of psychological tests (in terms of statistical analyses, the construction of some tests, among other things) to the field. Galton was, in effect, one of the first behavioral geneticists.
Galton (1869: 37) asked “Is reputation a fair test of natural ability?“, to which he answered, “it is the only one I can employ.” Galton, for example, stated that, theoretically or intuitively, there is a relationship between reaction time and intelligence (Khodadi et al, 2014). Galton then devised tests of “reaction time, discrimination in sight and hearing, judgment of length, and so on, and applied them to groups of volunteers, with the aim of obtaining a more reliable and ‘pure’ measure of his socially judged intelligence” (Richardson, 1991: 19). But there was little to no relationship between Galton’s proposed proxies for intelligence and social class.
In 1890, Galton, publishing in the journal Mind coined the term “mental test (Castles, 2012: 85), while Cattell then got Galton to move to Columbia and got him permission to use his “mental tests” to all of the entering students. This was about two decades before Goddard brought the test to America—Galton and Cattell were just getting America warmed up for the testing process.
Yet others still attempted to create tests that were purported to measure intelligence, using similar kinds of parameters as Galton. For instance, Miller, 1962 provides a list (quoted in Richardson, 1991: 19):
1 Dynamotor pressure How tightly can the hand squeeze?
2 Rate of movement How quickly can the hand move through a distance of 30 cms?
3 Sensation areas How far apart must two points be on the skin to be recognised as two rather than one?
4 Pressure causing pain How much pressure on the forehead is necessary to cause pain?
5 Least noticeable difference in weight How large must the difference be between two weights before it is reliably detected?
6 Reaction-time for sound How quickly can the hand be moved at the onset of an auditory signal?
7 Time for naming colours How long does it take to name a strop of ten colored papers?
8 Bisection on a 10 cm line How accurately can onr point to the centre of an ebony rule?
9 Judgment of 10 sec time How accurately can an interval of 10 secs be judged?
10 Number of letters remembered on once hearing How many letters, ordered at random, can be repeated exactly after one presentation?
Individuals differed on these measures, but when they were used to compare social classes, Cattell stated that they were “disappointingly low” (quoted in Richardson, 1991: 20). So-called mental tests, Richardson (1991: 20) states, were “not [a] measurement for a straightforward, objective scientific investigation. The theory was there, but it was hardly a scientific one, but one derived largely from common intuition; what we described earlier as a popular or informal theory. And the theory had strong social implications. Measurement was devised mainly as a way of applying the theory in accordance with the prejudices it entailed.”
It wasn’t until 1903 when Alfred Binet was tasked to construct a test that identified slow learners in grade-school. In 1904, Binet was appointed a member of a commission on special classes in schools (Murphy, 1949: 354). In fact, Binet constructed his test in order to limit the role of psychiatrists in making decisions on whether or not healthy children—but ‘abnormal’—children should be excluded from the standard material used in regular schools (Nicolas et al, 2013). (See Nicolas et al, 2013 for a full overview of the history of intelligence in Psychology and a fuller overview of Binet and Simon’s test and why they constructed it. Also see Fancher, 1985 and )
The way Binet constructed his tests were in a way to identify children who were not learning what the average child their age knew. But the tests must distinguish between the lazy from the mentally deficient. So in 1905, Binet teamed up with Simon, and they published their first IQ test, with items arranged from the simplest to the most difficult (but with no standardization). A few of these items include: naming objects, completing sentences, comparing lines, comprehending questions, and repeating digits. Their test consisted of 30 items, which increased in difficulty from easiest to hardest and the items were chosen on the basis of teacher assessment and checking the items and seeing which discriminated which child and that also agreed with the constructors’ presuppositions.
Richardson (2000: 32) discusses how IQ tests are constructed:
In this regard, the construction of IQ tests is perhaps best thought of as a reformatting exercise: ranks in one format (teachers’ estimates) are converted into ranks in another format (test scores, see figure 2.1).
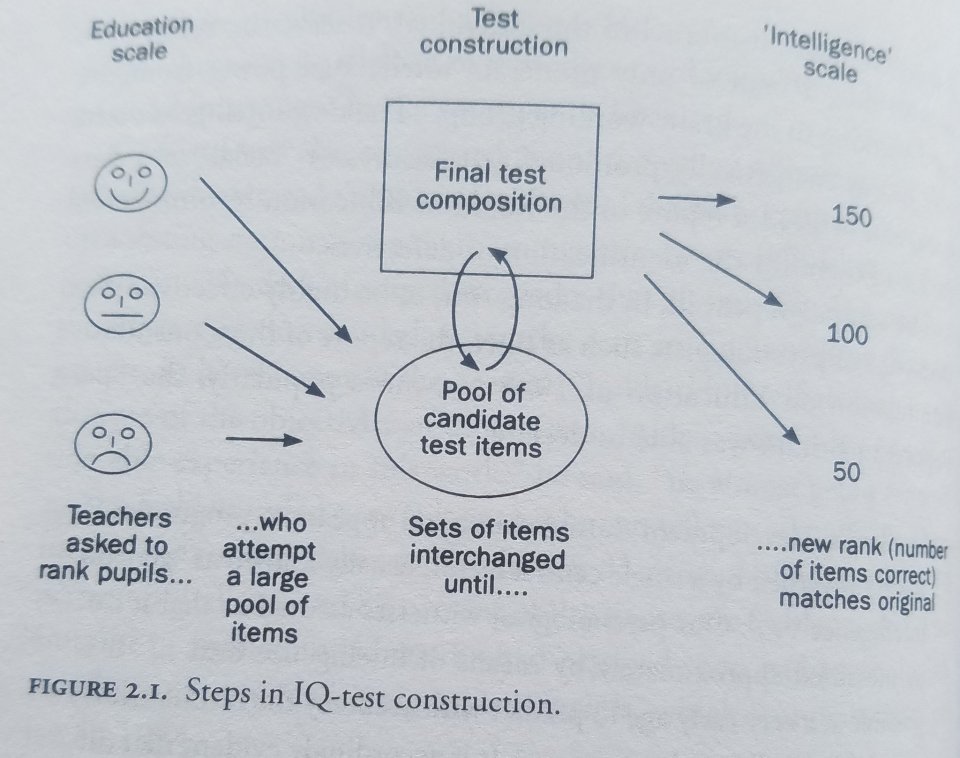
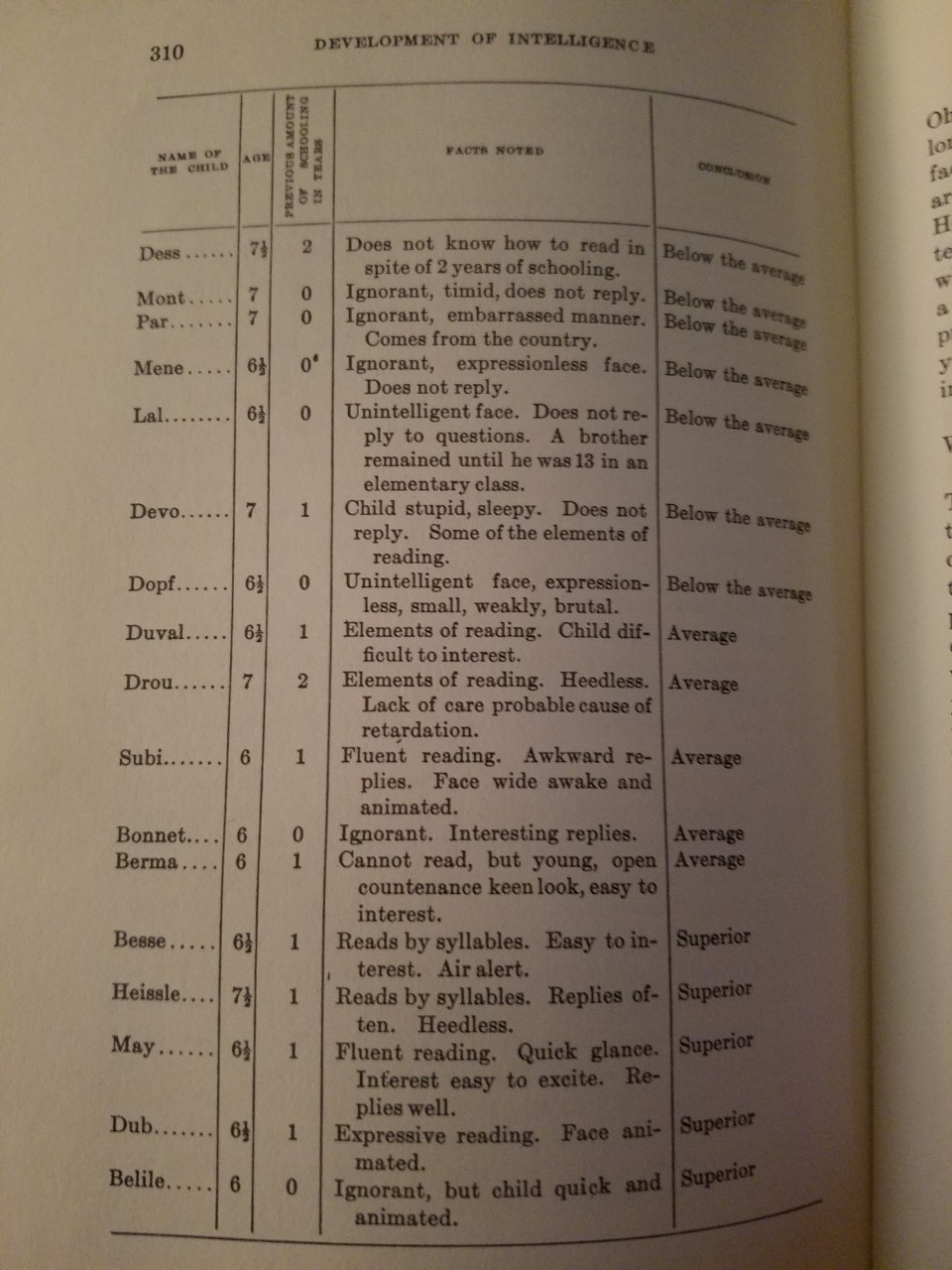
In The Development of Intelligence in Children, Binet and Simon (1916: 309) discuss how teachers assessed students:
A teacher , whom I know, who is methodical and considerate, has given an account of the habits he has formed for studying his pupils; he has analysed his methods, and sent them to me. They have nothing original, which makes them all the more important. He instructs children from five and a half to seven and a half years old; they are 35 in number; they have come to his class after having passed a prepatory course, where they have commenced to learn to read. For judging each child, the teacher takes account of his age, his previous schooling (the child may have been one year, two years in the prepatory class, or else was never passed through the division at all), of his expression of countenance, his state of health, his knowledge, his attitude in class, and his replies. From thes diverse elements he forms his opinion. I have transcribed some of these notes on the following page.
In reading his judgments one can see how his opinion was formed, and of how many elements it took account; it seems to us that this detail is interesting; perhaps if one attempted to make it precise by giving coefficients to all of these remarks, one would realize still greater exactitude. But is it possible to define precisely an attitude, a physiognomy, interesting replies, animated eyes? It seems that in all this the best element of diagnosis is furnished by the degree of reading which the child has attained after a given number of months, and the rest remains constantly vague.
Binet chose the items used on his tests for practical, not theoretical reasons. They then learned that some of their tests were harder, and others were easier, so they then arranged their tests by age levels: how well the average child for that age could complete the test in question. For example, if the average child could complete 10/20 for their age group, then they were average for that age. Then, if they scored below that, they were below average and above that they were higher than average. So the “mental age” for the child in question was calculated with the following formula: IQ=MA/CA*100. So if one’s MA (mental age) was 13 and their chronological age was 9, then their IQ would be 144.
Before Binet’s death in 1911, he revised his and Simon’s previous test. Intelligence, to Binet, is “the ability to understand directions, to maintain a mental set, and to apply “autocriticism” (the correction of one’s own errors)” (Murphy, 1949: 355). Binet measured subnormality by subtracting mental age from chronological age. (If mental and chronological age are equal, then IQ is 100.) To Binet, relative retardation was important. But William Stern, in 1912, thought that relative retardation was not important, but relative retardation was, and so he proposed to divide the mental age by the chronological age and multiply by 100. This, he showed, was stable in most children.
Binet termed his new scale a test of intelligence. It is interesting to note that the primary connotation of the French term l’intelligence in Binet’s time was what we might call “school brightness,” and Binet himself claimed no function for his scales beyond that of measuring academic aptitude.
In 1908, Henry Goddard went on a trip to Europe, heard of Binet’s test, and brought home an original version to try out on his students at the Vineland Training School. He translated Binet’s 1908 edition of his test from French to English in 1909. Castles (2012: 90) notes that “American psychology would never be the same.” Goddard was also the one who coined the term “moron” (Dolmage, 2018) for any adult with a mental age between 8 and 13. In 1912, Goddard administered tests to immigrants who landed at Ellis Island and found that 87 percent of Russians, 83 percent of Jews, 80 percent of Hungarians, and 79 percent of Italians were “feebleminded.” Deportations soon picked up, with Goddard reporting a 350 percent increase in 1913 and a 570 percent increase in 1914 (Mensh and Mensh, 1991: 26).
Then, in 1916, Terman published his revision of the Binet-Simon scale, which he termed the Stanford-Binet intelligence scale, based on a sample of 1,000 subjects and standardized for ages ranging from 3-18—the tests for 16-year-olds being were for adults, whereas the tests for 18-year-olds were for ‘superior’ adults (Murphy, 1949: 355). (Terman’s test was revised in 1937, when the question of sex differences came up, see below, and in 1960.) Murphy (1949: 355) goes on to write:
Many of Binet’s tests were placed at higher or lower age levels than those at which Binet had placed them, and new tests were added. Each age level was represented by a battery of tests, each test being assigned a certain number of month credits. It was possible, therefore, to reckon the subject’s intelligence quotient, as Stern had suggested, in terms of the ratio of mental age to chronological age. A child attaining a score of 120 months, but only 100 months old, would have an IQ of 120 (the decimal point omitted).
It wasn’t until 1917 that psychologists devised the Army Alpha test for literate test-takers and the Army Beta test for illiterate test-takers and non-English speakers. Examples for items on the Alpha and the Beta can be found below:
1. The Percheron is a kind of
(a) goat, (b) horse, (c) cow, (d) sheep.
2. The most prominent industry of Gloucester is
(a) fishing, (b) packing, (c) brewing, (d) automobiles.
3. “There’s a reason” is an advertisement for
(a) drink, (b) revolver, (c) flour, (d) cleanser.
4. The Knight engine is used in the
(a) drink, (b) Stearns, (c) Lozier, (d) Pierce Arrow.
5. The Stanchion is used in
(a) fishing, (b) hunting, (c) farming, (d) motoring. (Heine, 2017: 187)

Mensh and Mensh (1991: 31) tell us that
… the tests’ very lack of effect on the placement of [army] personnel provides the clue to their use. The tests were used to justify, not alter, the army’s traditional personnel policy, which called for the selection of officers from among relatively affluent whites and the assignment of white of lower socioeconomic status go lower-status roles and African-Americans at the bottom rung.
Meanwhile, while Binet was devising his Binet scales at the beginning of the 20th century, Spearman was devising his theory of g over in Europe. Spearman noted in 1904 that children who did well or poorly on certain types of tests did well or poorly on all of them—they were correlated. Spearman’s discovery was that correlated scores reflect a common ability, and this ability is called ‘general intelligence’ or ‘g’ (which has been widely criticized).
In sum, the conception of ‘intelligence tests’ began as a way to attempt to justify the class/race hierarchy by constructing the tests in a way to agree with the constructors’ presuppositions of who is or is not intelligent—which will be covered below.
Test construction
When tests are standardized, a whole slew of candidate items are pooled together and used in the construction of the test. For an item to be used for the final test, it must agree with the a priori assumptions of the test’s constructors on who is or is not “intelligent.”
Andrew Strenio, author of The Testing Trap states exactly how IQ tests are constructed, writing:
We look at individual questions and see how many people get them right and who gets them right. … We consciously and deliberately select questions so that the kind of people who scored low on the pretest will score low on subsequent tests. We do the same for middle or high scorers. We are imposing our will on the outcome. (pg 95, quoted in Mensh and Mensh, 1991)
Richardson (2017a: 82) writes that IQ tests—and the items on them—are:
still based on the basic assumption of knowing in advance who is or is not intelligent and making up and selecting items accordingly. Items are invented by test designers themselves or sent out to other psychologists, educators, or other “experts” to come up with ideas. As described above, initial batches are then refined using some intuitive guidelines.
This is strange… I thought that IQ tests were “objective”? Well, this shows that they are anything but objective—they are, very clearly, subjective in their construction which leads to what the constructors of the test assumed—their score hierarchy. The test’s constructors assume that their preconceptions on who is or is not intelligent is true and that differences in intelligence are the cause for differences in social class, so the IQ test was created to justify the existing social hierarchy. (Nevermind the fact that IQ scores are an index of social class, Richardson, 2017b.)
Mensh and Mensh (1991: 5) write that:
Nor are the [IQ] tests objective in any scientific sense. In the special vocabulary of psychometrics, this term refers to the way standardized tests are graded, i.e., according to the answers designated “right” or “wrong” when the questions are written. This definition not only overlooks that the tests contain items of opinion, which cannot be answered according to universal standards of true/false, but also overlooks that the selection of items is an arbitrary or subjective matter.
Nor do the tests “allocate benefits.” Rather, because of their class and racial biases, they sort the test takers in a way that conforms to the existing allocation, thus justifying it. This is why the tests are so vehemently defended by some and so strongly opposed by others.
When it comes to Terman and his reconstruction of the Binet-Simon—which he called the Stanford-Binet—something must be noted.
There are negligible differences in IQ between men and women. In 1916, Terman thought that the sexes should be equal in IQ. So he constructed his test to mirror his assumption. Others (e.g., Yerkes) thought that whatever differences materialized between the sexes on the test should be kept and boys and girls should have different norms. Terman, though, to reflect his assumption, specifically constructed his test by including subtests in which sex differences were eliminated. This assumption is still used today. (See Richardson, 1998; Hilliard, 2012.) Richardson (2017a: 82) puts this into context:
It is in this context that we need to assess claims about social class and racial differences in IQ. These could be exaggerated, reduced, or eliminated in exactly the same way. That they are allowed to persist is a matter of social prejudice, not scientific fact. In all these ways, then, we find that the IQ testing movement is not merely describing properties of people—it has largely created them.
This is outright admission from the test’s constructors themselves that IQ differences can be built into and out of the test. It further shows that these tests are not “objective”, as they claim. In reality, they are subjective, based on prior assumptions. Take what Hilliard (2012: 115-116) noted about two white South African groups and differences in IQ between them:
A consistent 15- to 20-point IQ differential existed between the more economically privileged, better educated, urban-based, English-speaking whites and the lower-scoring, rural-based, poor, white Afrikaners. To avoid comparisons that would have led to political tensions between the two white groups, South African IQ testers squelched discussion about genetic differences between the two European ethnicities. They solved the problem by composing a modified version of the IQ test in Afrikaans. In this way they were able to normalize scores between the two white cultural groups.
The SAT suffers from the same problems. Mensh and Mensh (1991: 69) note that “the SAT has been weighted to widen a gender scoring differential that from the start favored males.” They note that, since the SAT’s inception, men have score higher than women, but the gap was due primarily to men’s scores on the math subtest “which was partially offset until 1972 by women’s higher scores on the verbal subtest.” But by 1986 men outscored women on the verbal portion, with the ETS stating that they created a “better balance for the scores between sexes” (quoted in Mensh and Mensh, 1991: 69). What they did, though, was exactly what Terman did: they added items where the context favored men and eliminated those that favored women. This prompts Hilliard (2012: 118) to ask “How then could they insist with such force that no cultural biases existed in the IQ tests given blacks, who scored 15 points below whites?”
When it comes to test bias, Mensh and Mensh (1991: 51) write that:
From a functional standpoint, there is no distinction between crassly biased IQ-test items and those that appear to be non-biased. Because all types of test items are biased (if not explicitly, then implicitly, or in some combination thereof), and because the tests’ racial and class biased correspond to the society’s, each element of a test plays its part in ranking children in the way their respective groups are ranked in the social order.
This, then, returns to the normal distribution—the Gaussian distribution or bell curve.
The normal distribution is assumed. Items are selected to conform with the normal curve after the fact by trying out a whole slew of items for which Jensen (1980: 147-148) states that “items must simply emerge arbitrarily from the heads of test constructors.” Items that show little correlation with the testers’ expectations are then removed from the final test. Fischer et al (1996), Simon (1997), Richardson (1991; 1998; 2017) also discuss the myth of the normal distribution and how it is constructed by IQ test-makers. Further, Jensen brings up an important point about items emerging “arbitrarily from the heads of test constructors.” That is, test constructors have their idea in their head on who is or is not ‘intelligent’, they then try out a whole slew of items, and, unsurprisingly, they get the type of score distribution they want! Howe (1997: 20) writes that:
However, it is wrongly assumed that the fact that IQ scores have a bell-shaped distribution implies that differing intelligence levels of individuals are ‘naturally’ distributed in that way. This is incorrect: the bell-shaped distribution of IQ scores is an artifical product that results from test-makers initially assuming that intelligence is normally distributed, and then matchinig IQ scores to differing levels of test performance in a manner that results in a bell-shaped curve.
Richardson (1991) notes that the normal distribution “is achieved in the IQ test by the simple decision of including more items on which an average number of the trial group performed well, and relatively fewer on which either a substantial majority or a minority of subjects did well. Richardson (1991) also states that “if the bell-shaped curve is the myth it seems to be—for IQ as for much else—then it is devastating for nearly all discussion surrounding it.” Even Jensen (1980: 71) states that “It is claimed that the psychometrist can make up a test that will yield any kind of score distribution he pleases. This is roughly true, but some types of distributions are much easier to obtain than others.”
The [IQ test] items are, after all, devised by test designers from a very narrow social class and culture, based on intuitions about intelligence and variation in it, and on a technology of item selection which builds in the required degree of convergence of performance. (Richardson, 1991)
Micceri (1988) examined score distributions from 400 tests administered all over the US in workplaces, universities, and schools. He found significant non-normal distributions of test scores. The same can be said about physiological processes, as well.
Candidate items are administered to a sample population, and to be selected for the final test, the question must establish the scoring norm for the whole group, along with subtest norms which is supposed to replicate when the test is then released for general use. So an item must play the role in creating a distribution of scores that places each subgroup (of people) in its predetermined place on the (artifact of test construction’s) normal curve. It is then how Hilliard (2012: 118) notes:
Validating a newly drawn-up IQ exam involved giving it to a prescribed sample population to determine whether it measured what it was designed to assess. The scores were then correlated, that is, compared with the test designers’ presumptions. If the individuals who were supposed to come out on top didn’t score highly or, conversely, if the individuals who were assumed would be at the bottom of the scores didn’t end up there, then the designers would scrap the test.
Howe (1997: 6) states that “A psychological test score is no more than an indication of how well someone has performed at a number of questions that have been chosen for largely practical reasons. Nothing is genuinely being measured.” Howe (1997: 17) also noted that:
Because their construction has never been guided by any formal definition of what intelligence is, intelligence tests are strikingly different from genuine measuring instruments. Binet and Simon’s choice of items to include as the problems that made up their test was based purely on practical considerations.
IQ tests are ‘validated’ against older tests such as the Stanford-Binet, but the older tests were never validated themselves (see Richardson, 2002: 301.) Howe (1997: 18) continues:
In the case of the Binet and Simon test, since their main purpose was to help establish whether or not a child was capable of coping with the conventional school cirriculum, they sensibly chose items that seemed to assess a child’s capacity to succeed at the kinds of mental problems that are encountered in the classroom. Importantly, the content of the first intelligence test was decided by largely pragmatic considerations rather than being constrained by a formal definition of intelligence. That remains largely true of the tests that are used even now. As the early tests were revised and new assessment batteries constructed, the main benchmark for believing a new test to be adequate was its degree of agreement with the older ones. Each new test was assummed to be a proper measure of intelligence if the distributions of people’s scores at it matched the pattern of scores at a previous test, a line of reasoning that conveniently ignored the fact that the earlier ‘measures’ of intelligence that provided the basis for confirming the quality of the subsequent ones were never actually measures of anything. In reality … intelligence tests are very different from true measures (Nash, 1990). For instance, with a measure such as height it is clear that a particular quantity is the same irrespective of where it occurs. The 5 cm difference between 40 cm and 45 cm is the same as the 5 cm difference between 115 cm and 120 cm, but the same cannot be said about differing scores gained in a psychological test.
Conclusion
This discussion of the construction of IQ tests and the history of IQ testing can lead us to one conclusion: that differences in scores can be built into and out of the tests based on the prior assumptions of the test’s constructors; the history of IQ testing is rife with these same assumptions; and all newer tests are ‘validated’ on their agreement with older—still non-valid!—tests. The genesis of IQ testing beginning with social prejudices, constructing the tests to agree with the current hierarchy, however, does indeed damn the conclusions of the tests—that group A outscores group B does not mean that A is more ‘intelligent’ than B; it only means that A was exposed to more of the knowledge on the test.
The normal distribution, too, is a result of the same item addition/elimination to get the expected scores—the scores that then agree with the constructors’ racial and class biases. Bias in mental testing does exist, contra Jensen (1980). It exists due to carefully selected items to distinguish between different racial groups and social classes.
This critique in IQ testing I have mounted is not an ‘environmentalist’ critique, either. It is a methodological one.
Genetic and Epigenetic Determinism
1550 words
Genetic determinism is the belief that behavior/mental abilities are ‘controlled by’ genes. Gerick et al (2017) note that “Genetic determinism can be described as the attribution of the formation of traits to genes, where genes are ascribed more causal power than what scientific consensus suggests“, which is similar to Oyama (1985) who writes “Just as traditional though placed biological forms in the mind of God, so modern thought finds ways of endowing genes with ultimate formative power.” Moore (2014: 15) notes that genetic determinism is “the idea that genes can determine the nature of our characteristics” or “the old idea that biology controls the development of characteristics like intelligence, height, and personality” (pg 39). (See my article DNA is not a Blueprint for more information.)
On the other hand, epigenetic determinism is “the belief that epigenetic mechanisms determine the expression of human traits and behaviors” (Wagoner and Uller, 2016). Both views are, of course, espoused in the scientific literature as well as usual social discourse. Both views, as well, are false. Moore (2014: 245) notes that epigenetic determinism is “the idea that an organism’s epigenetic state invariably leads to a particular phenotype.”
Genetic Determinism
The concept of genetic determinism was first proposed by Weismann in 1893 with a theory of germplasm. This, in contemporary times, is contrasted with “blank slatism” (Pinker, 2002), or the Standard Social Science Model (SSSM; Tooby and Cosmides, 1992; see Richardson, 2008 for a response). Genes, genetic determinists hold, determine the ontogeny of traits, being a sort of “director.” But this betrays modern thinking on genes, what they are, and what they “do.” Genes do nothing on their own without input from the physiological system—that is, from the environment (Noble, 2011). Thus, gene-environment interaction is the rule.
This lead to either-or thinking in regard to the origin of traits and their development—what we now call “the nature-nurture debate.” Nature (genes/biology) or nurture (experience, how one is raised), gene determinists hold, are the cause of certain traits, like, for example, IQ.
Plomin (2018) asserts that nature has won the battle over nurture—while also stating that they interact. So, which one is it? It’s obvious that they interact—if there were no genes there would still be an environment but if there were no environment there would be no genes. (See here and here for critiques of his book Blueprint.)
This belief that genes determine traits goes back to Galton—one of the first hereditarians. Indeed, Galton was the one to coin the phrase “nature vs nurture”, while being a proponent of ‘nature over nurture.’ Do genes or environment influence/cause human behavior? The obvious answer to the question is both do—and they are intertwined: they interact.
Griffiths (2002) notes that:
Genetic determinism is the idea that many significant human characteristics are rendered inevitable by the presence of certain genes; that it is futile to attempt to modify criminal behavior or obesity or alcoholism by any means other than genetic manipulation.
Griffiths then argues that genes are very unlikely to be deterministic causes of behavior. Genes are thought to have a kind of “information” in them which then determines how the organism will develop. This is what the “blueprint metaphor” for genes attempts to show. Genes contain this information for trait development. The implicit assumption here is that genes are context-independent—that the (environmental) context the organism is in does not matter. But genes are context-dependent—“the very concept of a gene requires the environment” (Schneider, 2007). This speaks to the context-dependency of genes. There is no “information”—genes are not like blueprints or recipes. So genetic determinism is false.
But even though genetic determinism is false, it still stays in the minds of our society/culture and scientists (Moore, 2008), while still being taught in schools (Jamieson and Radick, 2017).
The claim that genes determine phenotypes can be shown in the following figure from Kampourakis (2017: 187):
Figure 9.6 (a) The common representation of gene function: a single gene determines a single phenotype. It should be clear by what has been present in the book so far that is not accurate. (b) A more accurate representation of gene function that takes development and environment into account. In this case, a phenotype is produced in a particular environment by developmental processes in which genes are implicated. In a different environment the same genes might contribute to the development of a different phenotype. Note the “black box” of development.
Richardson (2017: 133) notes that “There is no direct command line between environments and genes or between genes and phenotypes.” The fact of the matter is, genes do not determine an organism’s characters, they are merely implicated in the development of the character—being passive, not active templates (Noble, 2011).
Moore (2014: 199) tells us how genetic determinism fails since genes do not work in a vaccuum:
There is just one problem with the neo-Darwinian assumption that “hard” inheritance is the only good explanation for the transgenerational transmission of phenotypes: It is hopelessly simplistic. Genetic determinism is a faulty idea, because genes do not operate in a vacuum; phenotypes develop when genes interact with nongenetic factors in their local environments, factors that are affected by the broader environment.
Epigenetic Determinism
On the other hand, epigenetic determinism, the belief that epigenetic mechanisms determine the behavior of the organism, is false but in the other direction. Epigenetic determinists decry genetic determinism, but I don’t think they realize that they are just as deterministic as they are.
Dupras et al (2018) note how “overly deterministic readings of epigenetic marks could promote discriminatory attitudes, discourses and practices based on the predictive nature of epigenetic information.” While epigenetics—specifically behavioral epigenetics—refutes notions of genetic determinism, we can then fall into a similar trap, but determinism all the same. This means, though, that since genes don’t determine, epigenetics does not either, so we cannot epigenetically manipulate pre- or perinatally since what we would attempt to manipulate—‘intelligence’, contentment, happiness—all develop over the lifespan. Moore (2014: 248) continues:
Even in situations where we know that certain perinatal experiences can have very long-term effects, determinism is still an inappropriate framework for thinking about human development. For example, no one doubts that drinking alcohol during pregnancy is bad for the fetus, but in the hundreds of years before scientists established this relationship, innumerable fetuses exposed to some alcohol nonetheless grew up to be healthy, normal adults. This does not mean that pregnant women should drink alcohol freely, of course, but it does mean that developmental outcomes are not as easy to predict as we sometimes think. Therefore, it is probably always a bad idea to apply a deterministic worldview to a human being. Like DNA segments, epigenetic marks should not be considered destiny. How a given child will develop after trauma, for example, depends on a lot more than simply the experience of the trauma itself.
In an interview with The Psych Report Moore tells us that people not know enough about epigenetics for there to be epigenetic determinists (though many journalists and some scientists talk like they are :
I don’t think people know enough about epigenetics yet to be epigenetic determinists, but I foresee that as a problem. As soon as people start hearing about these kinds of data that suggest that your early experiences can have long-term effects, there’s a natural assumption we all make that those experiences are determinative. That is, we tend to assume that if you have this experience in poverty, you are going to be permanently scarred by it.
The data seem to suggest that it may work that way, but it also seems to be the case that the experiences we have later in life also have epigenetic effects. And there’s every reason to think that those later experiences can ameliorate some of the effects that happened early on. So, I don’t think we need to be overly concerned that the things that happen to us early in life necessarily fate us to certain kinds of outcomes.
While epigenetics refutes genetic determinism, we can run into the problem of epigenetic determinism, which Moore predicts. But journalists note how genes can be turned on or off by the environment, thereby dictating disease states, for example. Though, biological determinism—of any kind, epigenetic or genetic—is nonsensical as “the development of phenotypes depends on the contexts in which epigenetic marks (and other developmentally relevant factors, of course, are embedded” (Moore, 2014: 246).
What really happens?
What really happens regarding development if genetic and epigenetic determinism are false? It’s simple: causal parity (Oyama, 1985; Noble, 2012): the thesis that genes/DNA play an important role in development, but so do other variables, so there is no reason to privilege genes/DNA above other developmental variables. Genes are not special developmental resources and so, nor are they more important than other developmental resources. So the thesis is that genes and other developmental resources are developmentally ‘on par’. ALL traits develop through an interaction between genes and environment—nature and nurture. Contra ignorant pontifications (e.g., Plomin), neither has “won out”—they need each other to produce phenotypes.
So, genetic and epigenetic determinism are incoherent concepts: nature and nurture interact to produce the phenotypes we see around us today. Developmental systems theory, which integrates all factors of development, including epigenetics, is the superior framework to work with, but we should not, of course, be deterministic about organismal development.
A not uncommon reaction to DST is, ‘‘That’s completely crazy, and besides, I already knew it.” — Oyama, 2000, 195, Evolution’s Eye
Hereditarian “Reasoning” on Race
1100 words
The existence of race is important for the hereditarian paradigm. Since it is so important, there must be some theories of race that hereditarians use to ground their theories of race and IQ, right? Well, looking at the main hereditarians’ writings, they just assume the existence of race, and, along with the assumption, the existence of three races—Caucasoid, Negroid, and Mongoloid, to use Rushton’s (1997) terminology.
But just assuming race exists without a definition of what race is is troubling for the hereditarian position. Why just assume that race exists?
Fish (2002: 6) in Race and Intelligence: Separating Science from Myth critiques the usual hereditarians on what race is and their assumptions that it exists. He cites Jensen (1998: 425) who writes:
A race is one of a number of statistically distinguishable groups in which individual membership is not mutually exclusive by any single criterion, and individuals in a given group differ only statistically from one another and from the group’s central tendency on each of the many imperfectly correlated genetic characteristics that distinguish between groups as such.
Fish (2002: 6) continues:
This is an example of the kind of ethnocentric operational definition described earlier. A fair translation is, “As an American, I know that blacks and whites are races, so even though I can’t find any way of making sense of the biological facts, I’ll assign people to my cultural categories, do my statistical tests, and explain the differences in biological terms.” In essence, the process involves a kind of reasoning by converse. Instead of arguing, “If races exist there are genetic differences between them,” the argument is “Genetic differences between groups exist, therefore the groups are races.”
Fish goes on to write that if we take a group of bowlers and a group of golfers then, by chance, there may be genetic differences between them but we wouldn’t call them “golfer races” or “bowler races.” If there were differences in IQ, income and other variables, he continues, we wouldn’t argue that the differences are due to biology, we would attempt argue that the differences are social. (Though I can see behavioral geneticists try to argue that the differences are due to differences in genes between the groups.)
So the reasoning that Jensen uses is clearly fallacious. Though, it is better than Levin’s (1997) and Rushton’s (1997) assumptions that race exists, it still fails since Jensen (1998) is attempting argue that genetic differences between groups make them races. Lynn (2006: 11) uses a similar argument to the one Jensen provides above. (Nevermind Lynn conflating social and biological races in chapter 2 of Race Differences in Intelligence.)
Arguments exist for the existence of race that doesn’t, obviously, assume their existence. The two best ones I’m aware of are by Hardimon (2017) and Spencer (2014, 2019).
Hardimon has four concepts: the racialist race concept (what I take to be the hereditarian position), the minimalist/populationist race concept (they are two separate concepts, but the populationist race concept is the “scientization” of the minimalist race concept) and the socialrace concept. Specifically, Hardimon (2017: 99) defines ‘race’ as:
… a subdivision of Homo sapiens—a group of populations that exhibits a distinctive pattern of genetically transmitted phenotypic characters that corresponds to the group’s geographic ancestry and belongs to a biological line of descent initiated by a geographically separated and reproductively isolated founding population.
Spencer (2014, 2019), on the other hand, grounds his racial ontology in the Census and the OMB—what Spencer calls “the OMB race theory”—or “Blumenbachian partitions.” Take Spencer’s most recent (2019) formulation of his concept:
In this chapter, I have defended a nuanced biological racial realism as an account of how ‘race’ is used in one US race talk. I will call the theory OMB race theory, and the theory makes the following three claims:
(3.7) The set of races in OMB race talk is one meaning of ‘race’ in US race talk.
(3.8) The set of races in OMB race talk is the set of human continental populations.
(3.9) The set of human continental populations is biologically real.
I argued for (3.7) in sections 3.2 and 3.3. Here, I argued that OMB race talk is not only an ordinary race talk in the current United States, but a race talk where the meaning of ‘race’ in the race talk is just the set of races used in the race talk. I argued for (3.8) (a.k.a. ‘the identity thesis’) in sections 3.3 and 3.4. Here, I argued that the thing being referred to in OMB race talk (a.k.a. the meaning of ‘race’ in OMB race talk) is a set of biological populations in humans (Africans, East Asians, Eurasians, Native Americans, and Oceanians), which I’ve dubbed the human continental populations. Finally, I argued for (3.9) in section 3.4. Here, I argued that the set of human continental populations is biologically real because it currently occupies the K = 5 level of human population structure according to contemporary population genetics.
Whether or not one accepts Hardimon’s and Spencer’s arguments for the existence of race is not the point here, however. The point here is that these two philosophers have grounded their belief in the existence of race in a sound philosophical grounding—we cannot, though, say the same things for the hereditarians.
It should also be noted that both Spencer and Hardimon discount hereditarian theory—indeed, Spencer (2014: 1036) writes:
Nothing in Blumenbachian race theory entails that socially important differences exist among US races. This means that the theory does not entail that there are aesthetic, intellectual, or moral differences among US races. Nor does it entail that US races differ in drug metabolizing enzymes or genetic disorders. This is not political correctness either. Rather, the genetic evidence that supports the theory comes from noncoding DNA sequences. Thus, if individuals wish to make claims about one race being superior to another in some respect, they will have to look elsewhere for that evidence.
So, as can be seen, hereditarian ‘reasoning’ on race is not grounded in anything—they just assume that races exist. This stands in stark contrast to theories of race put forth by philosophers of race. Nonhereditarian theories of race exist—and, as I’ve shown, hereditarians don’t define race, nor do they have an argument for the existence of races, they just assume their existence. But, for the hereditarian paradigm to be valid, they must be biologically real. Hardimon and Spencer argue that they are, but hereditarian theories do not have any bearing on their theories of race.
There is the hereditarian ‘reasoning’ on race: either assume its existence sans argument or argue that genetic differences between groups exist so the groups are races. Hereditarians need to posit something like Hardimon or Spencer.
Jews, IQ, Genes, and Culture
1500 words
Jewish IQ is one of the most-talked-about things in the hereditarian sphere. Jews have higher IQs, Cochran, Hardy, and Harpending (2006: 2) argue due to “the unique demography and sociology of Ashkenazim in medieval Europe selected for intelligence.” To IQ-ists, IQ is influenced/caused by genetic factors—while environment accounts for only a small portion.
In The Chosen People: A Study of Jewish Intelligence, Lynn (2011) discusses one explanation for higher Jewish IQ—that of “pushy Jewish mothers” (Marjoribanks, 1972).
“Fourth, other environmentalists such as Majoribanks (1972) have argued that the high intelligence of the Ashkenazi Jews is attributable to the typical “pushy Jewish mother”. In a study carried out in Canada he compared 100 Jewish boys aged 11 years with 100 Protestant white gentile boys and 100 white French Canadians and assessed their mothers for “Press for Achievement”, i.e. the extent to which mothers put pressure on their sons to achieve. He found that the Jewish mothers scored higher on “Press for Achievement” than Protestant mothers by 5 SD units and higher than French Canadian mothers by 8 SD units and argued that this explains the high IQ of the children. But this inference does not follow. There is no general acceptance of the thesis that pushy mothers can raise the IQs of their children. Indeed, the contemporary consensus is that family environmental factors have no long term effect on the intelligence of children (Rowe, 1994).
The inference is a modus ponens:
P1 If p, then q.
P2 p.
C Therefore q.
Let p be “Jewish mothers scored higher on “Press for Achievement” by X SDs” and let q be “then this explains the high IQ of the children.”
So now we have:
Premise 1: If “Jewish mothers scored higher on “Press for Achievement” by X SDs”, then “this explains the high IQ of the children.”
Premise 2: “Jewish mothers scores higher on “Press for Achievement” by X SDs.”
Conclusion: Therefore, “Jewish mothers scoring higher on “Press for Achievement” by X SDs” so “this explains the high IQ of the children.”
Vaughn (2008: 12) notes that an inference is “reasoning from a premise or premises to … conclusions based on those premises.” The conclusion follows from the two premises, so how does the inference not follow?
IQ tests are tests of specific knowledge and skills. It, therefore, follows that, for example, if a “mother is pushy” and being pushy leads to studying more then the IQ of the child can be raised.
Looking at Lynn’s claim that “family environmental factors have no long term effect on the intelligence of children” is puzzling. Rowe relies heavily on twin and adoption studies which have false assumptions underlying them, as noted by Richardson and Norgate (2005), Moore (2006), Joseph (2014), Fosse, Joseph, and Richardson (2015), Joseph et al (2015). The EEA is false so we, therefore, cannot accept the genetic conclusions from twin studies.
Lynn and Kanazawa (2008: 807) argue that their “results clearly support the high intelligence theory of Jewish achievement while at the same time provide no support for the cultural values theory as an explanation for Jewish success.” They are positing “intelligence” as an explanatory concept, though Howe (1988) notes that “intelligence” is “a descriptive measure, not an explanatory concept.” “Intelligence, says Howe (1997: ix) “is … an outcome … not a cause.” More specifically, it is an outcome of development from infancy all the way up to adulthood and being exposed to the items on the test. Lynn has claimed for decades that high intelligence explains Jewish achievement. But whence came intelligence? Intelligence develops throughout the life cycle—from infancy to adolescence to adulthood (Moore, 2014).
Ogbu and Simon (1998: 164) notes that Jews are “autonomous minorities”—groups with a small number. They note that “Although [Jews, the Amish, and Mormons] may suffer discrimination, they are not totally dominated and oppressed, and their school achievement is no different from the dominant group (Ogbu 1978)” (Ogbu and Simon, 1998: 164). Jews are voluntary minorities, and voluntary minorities, according to Ogbu (2002: 250-251; in Race and Intelligence: Separating Science from Myth) suggests five reasons for good test performance from these types of minorities:
- Their preimmigration experience: Some do well since they were exposed to the items and structure of the tests in their native countries.
- They are cognitively acculturated: They acquired the cognitive skills of the white middle-class when they began to participate in their culture, schools, and economy.
- The history and incentive of motivation: They are motivated to score well on the tests as they have this “preimmigration expectation” in which high test scores are necessary to achieve their goals for why they emigrated along with a “positive frame of reference” in which becoming successful in America is better than becoming successful at home, and the “folk theory of getting ahead in the United States”, that their chance of success is better in the US and the key to success is a good education—which they then equate with high test scores.
So if ‘intelligence’ is a test of specific culturally-specific knowledge and skills, and if certain groups are exposed more to this knowledge, it then follows that certain groups of people are better-prepared for test-taking—specifically IQ tests.
The IQ-ists attempt to argue that differences in IQ are due, largely, to differences in ‘genes for’ IQ, and this explanation is supposed to explain Jewish IQ, and, along with it, Jewish achievement. (See also Gilman, 2008 and Ferguson, 2008 for responses to the just-so storytelling from Cochran, Hardy, and Harpending, 2006.) Lynn, purportedly, is invoking ‘genetic confounding’—he is presupposing that Jews have ‘high IQ genes’ and this is what explains the “pushiness” of Jewish mothers. The Jewish mothers then pass on their “genes for” high IQ—according to Lynn. But the evolutionary accounts (just-so stories) explaining Jewish IQ fail. Ferguson (2008) shows how “there is no good reason to believe that the argument of [Cochran, Hardy, and Harpending, 2006] is likely, or even reasonably possible.” The tall-tale explanations for Jewish IQ, too, fail.
Prinz (2014: 68) notes that Cochran et al have “a seductive story” (aren’t all just-so stories seductive since they are selected to comport with the observation? Smith, 2016), while continuing (pg 71):
The very fact that the Utah researchers use to argue for a genetic difference actually points to a cultural difference between Ashkenazim and other groups. Ashkenazi Jews may have encouraged their children to study maths because it was the only way to get ahead. The emphasis remains widespread today, and it may be the major source of performance on IQ tests. In arguing that Ashkenazim are genetically different, the Utah researchers identify a major cultural difference, and that cultural difference is sufficient to explain the pattern of academic achievement. There is no solid evidence for thinking that the Ashkenazim advantage in IQ tests is genetically, as opposed to culturally, caused.
Nisbett (2008: 146) notes other problems with the theory—most notably Sephardic over-achievement under Islam:
It is also important to the Cochran theory that Sephardic Jews not be terribly accomplished, since they did not pass through the genetic filter of occupations that demanded high intelligence. Contemporary Sephardic Jews in fact do not seem to haave unusally high IQs. But Sephardic Jews under Islam achieved at very high levels. Fifteen percent of all scientists in the period AD 1150-1300 were Jewish—far out of proportion to their presence in the world population, or even the population of the Islamic world—and these scientists were overwhelmingly Sephardic. Cochran and company are left with only a cultural explanation of this Sephardic efflorescence, and it is not congenial to their genetic theory of Jewish intelligence.
Finally, Berg and Belmont (1990: 106) note that “The purpose of the present study was to clarify a possible misinterpretation of the results of Lesser et al’s (1965) influential study that suggested that existence of a “Jewish” pattern of mental abilities. In establishing that Jewish children of different socio-cultural backgrounds display different patterns of mental abilities, which tend to cluster by socio-cultural group, this study confirms Lesser et al’s position that intellectual patterns are, in large part, culturally derived.” Cultural differences exist; cultural differences have an effect on psychological traits; if cultural differences exist and cultural differences have an effect on psychological traits (with culture influencing a population’s beliefs and values) and IQ tests are culturally-/class-specific knowledge tests, then it necessarily follows that IQ differences are cultural/social in nature, not ‘genetic.’
In sum, Lynn’s claim that the inference does not follow is ridiculous. The argument provided is a modus ponens, so the inference does follow. Similarly, Lynn’s claim that “pushy Jewish mothers” don’t explain the high IQs of Jews doesn’t follow. If IQ tests are tests of middle-class knowledge and skills and they are exposed to the structure and items on them, then it follows that being “pushy” with children—that is, getting them to study and whatnot—would explain higher IQs. Lynn’s and Kanazawa’s assertion that “high intelligence is the most promising explanation of Jewish achievement” also fails since intelligence is not an explanatory concept—a cause—it is a descriptive measure that develops across the lifespan.
