
4100 words
The [IQ] tests do what their construction dictates; they correlate a group’s mental worth with its place in the social hierarchy. (Mensh and Mensh, 1991, The IQ Mythology, pg 30)
We have been attempting to measure “intelligence” in humans for over 100 years. Mental testing began with Galton and then shifted over to Binet, which then became the most-well-known IQ tests today—Stanford-Binet and the WAIS/WISC. But the history of IQ testing is rife with unethical conclusions derived from their use, along with such conclusions they drew actually being carried out (i.e., the sterilization of “morons”; see Wilson, 2017’s The Eugenic Mind Project).
History of IQ testing
Any history of ‘intelligence’ testing will, of course, include Francis Galton’s contributions to the creation of psychological tests (in terms of statistical analyses, the construction of some tests, among other things) to the field. Galton was, in effect, one of the first behavioral geneticists.
Galton (1869: 37) asked “Is reputation a fair test of natural ability?“, to which he answered, “it is the only one I can employ.” Galton, for example, stated that, theoretically or intuitively, there is a relationship between reaction time and intelligence (Khodadi et al, 2014). Galton then devised tests of “reaction time, discrimination in sight and hearing, judgment of length, and so on, and applied them to groups of volunteers, with the aim of obtaining a more reliable and ‘pure’ measure of his socially judged intelligence” (Richardson, 1991: 19). But there was little to no relationship between Galton’s proposed proxies for intelligence and social class.
In 1890, Galton, publishing in the journal Mind coined the term “mental test (Castles, 2012: 85), while Cattell then got Galton to move to Columbia and got him permission to use his “mental tests” to all of the entering students. This was about two decades before Goddard brought the test to America—Galton and Cattell were just getting America warmed up for the testing process.
Yet others still attempted to create tests that were purported to measure intelligence, using similar kinds of parameters as Galton. For instance, Miller, 1962 provides a list (quoted in Richardson, 1991: 19):
1 Dynamotor pressure How tightly can the hand squeeze?
2 Rate of movement How quickly can the hand move through a distance of 30 cms?
3 Sensation areas How far apart must two points be on the skin to be recognised as two rather than one?
4 Pressure causing pain How much pressure on the forehead is necessary to cause pain?
5 Least noticeable difference in weight How large must the difference be between two weights before it is reliably detected?
6 Reaction-time for sound How quickly can the hand be moved at the onset of an auditory signal?
7 Time for naming colours How long does it take to name a strop of ten colored papers?
8 Bisection on a 10 cm line How accurately can onr point to the centre of an ebony rule?
9 Judgment of 10 sec time How accurately can an interval of 10 secs be judged?
10 Number of letters remembered on once hearing How many letters, ordered at random, can be repeated exactly after one presentation?
Individuals differed on these measures, but when they were used to compare social classes, Cattell stated that they were “disappointingly low” (quoted in Richardson, 1991: 20). So-called mental tests, Richardson (1991: 20) states, were “not [a] measurement for a straightforward, objective scientific investigation. The theory was there, but it was hardly a scientific one, but one derived largely from common intuition; what we described earlier as a popular or informal theory. And the theory had strong social implications. Measurement was devised mainly as a way of applying the theory in accordance with the prejudices it entailed.”
It wasn’t until 1903 when Alfred Binet was tasked to construct a test that identified slow learners in grade-school. In 1904, Binet was appointed a member of a commission on special classes in schools (Murphy, 1949: 354). In fact, Binet constructed his test in order to limit the role of psychiatrists in making decisions on whether or not healthy children—but ‘abnormal’—children should be excluded from the standard material used in regular schools (Nicolas et al, 2013). (See Nicolas et al, 2013 for a full overview of the history of intelligence in Psychology and a fuller overview of Binet and Simon’s test and why they constructed it. Also see Fancher, 1985 and )
The way Binet constructed his tests were in a way to identify children who were not learning what the average child their age knew. But the tests must distinguish between the lazy from the mentally deficient. So in 1905, Binet teamed up with Simon, and they published their first IQ test, with items arranged from the simplest to the most difficult (but with no standardization). A few of these items include: naming objects, completing sentences, comparing lines, comprehending questions, and repeating digits. Their test consisted of 30 items, which increased in difficulty from easiest to hardest and the items were chosen on the basis of teacher assessment and checking the items and seeing which discriminated which child and that also agreed with the constructors’ presuppositions.
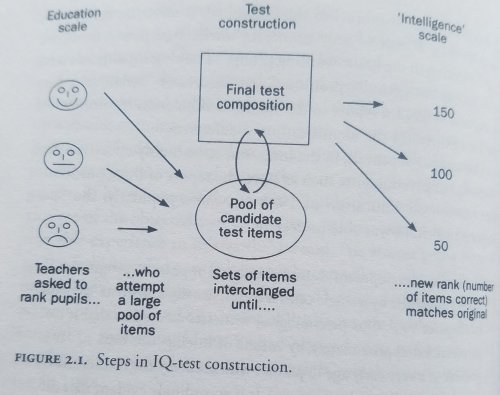
Richardson (2000: 32) discusses how IQ tests are constructed:
In this regard, the construction of IQ tests is perhaps best thought of as a reformatting exercise: ranks in one format (teachers’ estimates) are converted into ranks in another format (test scores, see figure 2.1).
In The Development of Intelligence in Children, Binet and Simon (1916: 309) discuss how teachers assessed students:
A teacher , whom I know, who is methodical and considerate, has given an account of the habits he has formed for studying his pupils; he has analysed his methods, and sent them to me. They have nothing original, which makes them all the more important. He instructs children from five and a half to seven and a half years old; they are 35 in number; they have come to his class after having passed a prepatory course, where they have commenced to learn to read. For judging each child, the teacher takes account of his age, his previous schooling (the child may have been one year, two years in the prepatory class, or else was never passed through the division at all), of his expression of countenance, his state of health, his knowledge, his attitude in class, and his replies. From thes diverse elements he forms his opinion. I have transcribed some of these notes on the following page.
In reading his judgments one can see how his opinion was formed, and of how many elements it took account; it seems to us that this detail is interesting; perhaps if one attempted to make it precise by giving coefficients to all of these remarks, one would realize still greater exactitude. But is it possible to define precisely an attitude, a physiognomy, interesting replies, animated eyes? It seems that in all this the best element of diagnosis is furnished by the degree of reading which the child has attained after a given number of months, and the rest remains constantly vague.

Binet chose the items used on his tests for practical, not theoretical reasons. They then learned that some of their tests were harder, and others were easier, so they then arranged their tests by age levels: how well the average child for that age could complete the test in question. For example, if the average child could complete 10/20 for their age group, then they were average for that age. Then, if they scored below that, they were below average and above that they were higher than average. So the “mental age” for the child in question was calculated with the following formula: IQ=MA/CA*100. So if one’s MA (mental age) was 13 and their chronological age was 9, then their IQ would be 144.
Before Binet’s death in 1911, he revised his and Simon’s previous test. Intelligence, to Binet, is “the ability to understand directions, to maintain a mental set, and to apply “autocriticism” (the correction of one’s own errors)” (Murphy, 1949: 355). Binet measured subnormality by subtracting mental age from chronological age. (If mental and chronological age are equal, then IQ is 100.) To Binet, relative retardation was important. But William Stern, in 1912, thought that relative retardation was not important, but relative retardation was, and so he proposed to divide the mental age by the chronological age and multiply by 100. This, he showed, was stable in most children.
Binet termed his new scale a test of intelligence. It is interesting to note that the primary connotation of the French term l’intelligence in Binet’s time was what we might call “school brightness,” and Binet himself claimed no function for his scales beyond that of measuring academic aptitude.
In 1908, Henry Goddard went on a trip to Europe, heard of Binet’s test, and brought home an original version to try out on his students at the Vineland Training School. He translated Binet’s 1908 edition of his test from French to English in 1909. Castles (2012: 90) notes that “American psychology would never be the same.” Goddard was also the one who coined the term “moron” (Dolmage, 2018) for any adult with a mental age between 8 and 13. In 1912, Goddard administered tests to immigrants who landed at Ellis Island and found that 87 percent of Russians, 83 percent of Jews, 80 percent of Hungarians, and 79 percent of Italians were “feebleminded.” Deportations soon picked up, with Goddard reporting a 350 percent increase in 1913 and a 570 percent increase in 1914 (Mensh and Mensh, 1991: 26).
Then, in 1916, Terman published his revision of the Binet-Simon scale, which he termed the Stanford-Binet intelligence scale, based on a sample of 1,000 subjects and standardized for ages ranging from 3-18—the tests for 16-year-olds being were for adults, whereas the tests for 18-year-olds were for ‘superior’ adults (Murphy, 1949: 355). (Terman’s test was revised in 1937, when the question of sex differences came up, see below, and in 1960.) Murphy (1949: 355) goes on to write:
Many of Binet’s tests were placed at higher or lower age levels than those at which Binet had placed them, and new tests were added. Each age level was represented by a battery of tests, each test being assigned a certain number of month credits. It was possible, therefore, to reckon the subject’s intelligence quotient, as Stern had suggested, in terms of the ratio of mental age to chronological age. A child attaining a score of 120 months, but only 100 months old, would have an IQ of 120 (the decimal point omitted).
It wasn’t until 1917 that psychologists devised the Army Alpha test for literate test-takers and the Army Beta test for illiterate test-takers and non-English speakers. Examples for items on the Alpha and the Beta can be found below:
1. The Percheron is a kind of
(a) goat, (b) horse, (c) cow, (d) sheep.
2. The most prominent industry of Gloucester is
(a) fishing, (b) packing, (c) brewing, (d) automobiles.
3. “There’s a reason” is an advertisement for
(a) drink, (b) revolver, (c) flour, (d) cleanser.
4. The Knight engine is used in the
(a) drink, (b) Stearns, (c) Lozier, (d) Pierce Arrow.
5. The Stanchion is used in
(a) fishing, (b) hunting, (c) farming, (d) motoring. (Heine, 2017: 187)

Mensh and Mensh (1991: 31) tell us that
… the tests’ very lack of effect on the placement of [army] personnel provides the clue to their use. The tests were used to justify, not alter, the army’s traditional personnel policy, which called for the selection of officers from among relatively affluent whites and the assignment of white of lower socioeconomic status go lower-status roles and African-Americans at the bottom rung.
Meanwhile, while Binet was devising his Binet scales at the beginning of the 20th century, Spearman was devising his theory of g over in Europe. Spearman noted in 1904 that children who did well or poorly on certain types of tests did well or poorly on all of them—they were correlated. Spearman’s discovery was that correlated scores reflect a common ability, and this ability is called ‘general intelligence’ or ‘g’ (which has been widely criticized).
In sum, the conception of ‘intelligence tests’ began as a way to attempt to justify the class/race hierarchy by constructing the tests in a way to agree with the constructors’ presuppositions of who is or is not intelligent—which will be covered below.
Test construction
When tests are standardized, a whole slew of candidate items are pooled together and used in the construction of the test. For an item to be used for the final test, it must agree with the a priori assumptions of the test’s constructors on who is or is not “intelligent.”
Andrew Strenio, author of The Testing Trap states exactly how IQ tests are constructed, writing:
We look at individual questions and see how many people get them right and who gets them right. … We consciously and deliberately select questions so that the kind of people who scored low on the pretest will score low on subsequent tests. We do the same for middle or high scorers. We are imposing our will on the outcome. (pg 95, quoted in Mensh and Mensh, 1991)
Richardson (2017a: 82) writes that IQ tests—and the items on them—are:
still based on the basic assumption of knowing in advance who is or is not intelligent and making up and selecting items accordingly. Items are invented by test designers themselves or sent out to other psychologists, educators, or other “experts” to come up with ideas. As described above, initial batches are then refined using some intuitive guidelines.
This is strange… I thought that IQ tests were “objective”? Well, this shows that they are anything but objective—they are, very clearly, subjective in their construction which leads to what the constructors of the test assumed—their score hierarchy. The test’s constructors assume that their preconceptions on who is or is not intelligent is true and that differences in intelligence are the cause for differences in social class, so the IQ test was created to justify the existing social hierarchy. (Nevermind the fact that IQ scores are an index of social class, Richardson, 2017b.)
Mensh and Mensh (1991: 5) write that:
Nor are the [IQ] tests objective in any scientific sense. In the special vocabulary of psychometrics, this term refers to the way standardized tests are graded, i.e., according to the answers designated “right” or “wrong” when the questions are written. This definition not only overlooks that the tests contain items of opinion, which cannot be answered according to universal standards of true/false, but also overlooks that the selection of items is an arbitrary or subjective matter.
Nor do the tests “allocate benefits.” Rather, because of their class and racial biases, they sort the test takers in a way that conforms to the existing allocation, thus justifying it. This is why the tests are so vehemently defended by some and so strongly opposed by others.
When it comes to Terman and his reconstruction of the Binet-Simon—which he called the Stanford-Binet—something must be noted.
There are negligible differences in IQ between men and women. In 1916, Terman thought that the sexes should be equal in IQ. So he constructed his test to mirror his assumption. Others (e.g., Yerkes) thought that whatever differences materialized between the sexes on the test should be kept and boys and girls should have different norms. Terman, though, to reflect his assumption, specifically constructed his test by including subtests in which sex differences were eliminated. This assumption is still used today. (See Richardson, 1998; Hilliard, 2012.) Richardson (2017a: 82) puts this into context:
It is in this context that we need to assess claims about social class and racial differences in IQ. These could be exaggerated, reduced, or eliminated in exactly the same way. That they are allowed to persist is a matter of social prejudice, not scientific fact. In all these ways, then, we find that the IQ testing movement is not merely describing properties of people—it has largely created them.
This is outright admission from the test’s constructors themselves that IQ differences can be built into and out of the test. It further shows that these tests are not “objective”, as they claim. In reality, they are subjective, based on prior assumptions. Take what Hilliard (2012: 115-116) noted about two white South African groups and differences in IQ between them:
A consistent 15- to 20-point IQ differential existed between the more economically privileged, better educated, urban-based, English-speaking whites and the lower-scoring, rural-based, poor, white Afrikaners. To avoid comparisons that would have led to political tensions between the two white groups, South African IQ testers squelched discussion about genetic differences between the two European ethnicities. They solved the problem by composing a modified version of the IQ test in Afrikaans. In this way they were able to normalize scores between the two white cultural groups.
The SAT suffers from the same problems. Mensh and Mensh (1991: 69) note that “the SAT has been weighted to widen a gender scoring differential that from the start favored males.” They note that, since the SAT’s inception, men have score higher than women, but the gap was due primarily to men’s scores on the math subtest “which was partially offset until 1972 by women’s higher scores on the verbal subtest.” But by 1986 men outscored women on the verbal portion, with the ETS stating that they created a “better balance for the scores between sexes” (quoted in Mensh and Mensh, 1991: 69). What they did, though, was exactly what Terman did: they added items where the context favored men and eliminated those that favored women. This prompts Hilliard (2012: 118) to ask “How then could they insist with such force that no cultural biases existed in the IQ tests given blacks, who scored 15 points below whites?”
When it comes to test bias, Mensh and Mensh (1991: 51) write that:
From a functional standpoint, there is no distinction between crassly biased IQ-test items and those that appear to be non-biased. Because all types of test items are biased (if not explicitly, then implicitly, or in some combination thereof), and because the tests’ racial and class biased correspond to the society’s, each element of a test plays its part in ranking children in the way their respective groups are ranked in the social order.
This, then, returns to the normal distribution—the Gaussian distribution or bell curve.
The normal distribution is assumed. Items are selected to conform with the normal curve after the fact by trying out a whole slew of items for which Jensen (1980: 147-148) states that “items must simply emerge arbitrarily from the heads of test constructors.” Items that show little correlation with the testers’ expectations are then removed from the final test. Fischer et al (1996), Simon (1997), Richardson (1991; 1998; 2017) also discuss the myth of the normal distribution and how it is constructed by IQ test-makers. Further, Jensen brings up an important point about items emerging “arbitrarily from the heads of test constructors.” That is, test constructors have their idea in their head on who is or is not ‘intelligent’, they then try out a whole slew of items, and, unsurprisingly, they get the type of score distribution they want! Howe (1997: 20) writes that:
However, it is wrongly assumed that the fact that IQ scores have a bell-shaped distribution implies that differing intelligence levels of individuals are ‘naturally’ distributed in that way. This is incorrect: the bell-shaped distribution of IQ scores is an artifical product that results from test-makers initially assuming that intelligence is normally distributed, and then matchinig IQ scores to differing levels of test performance in a manner that results in a bell-shaped curve.
Richardson (1991) notes that the normal distribution “is achieved in the IQ test by the simple decision of including more items on which an average number of the trial group performed well, and relatively fewer on which either a substantial majority or a minority of subjects did well. Richardson (1991) also states that “if the bell-shaped curve is the myth it seems to be—for IQ as for much else—then it is devastating for nearly all discussion surrounding it.” Even Jensen (1980: 71) states that “It is claimed that the psychometrist can make up a test that will yield any kind of score distribution he pleases. This is roughly true, but some types of distributions are much easier to obtain than others.”
The [IQ test] items are, after all, devised by test designers from a very narrow social class and culture, based on intuitions about intelligence and variation in it, and on a technology of item selection which builds in the required degree of convergence of performance. (Richardson, 1991)
Micceri (1988) examined score distributions from 400 tests administered all over the US in workplaces, universities, and schools. He found significant non-normal distributions of test scores. The same can be said about physiological processes, as well.
Candidate items are administered to a sample population, and to be selected for the final test, the question must establish the scoring norm for the whole group, along with subtest norms which is supposed to replicate when the test is then released for general use. So an item must play the role in creating a distribution of scores that places each subgroup (of people) in its predetermined place on the (artifact of test construction’s) normal curve. It is then how Hilliard (2012: 118) notes:
Validating a newly drawn-up IQ exam involved giving it to a prescribed sample population to determine whether it measured what it was designed to assess. The scores were then correlated, that is, compared with the test designers’ presumptions. If the individuals who were supposed to come out on top didn’t score highly or, conversely, if the individuals who were assumed would be at the bottom of the scores didn’t end up there, then the designers would scrap the test.
Howe (1997: 6) states that “A psychological test score is no more than an indication of how well someone has performed at a number of questions that have been chosen for largely practical reasons. Nothing is genuinely being measured.” Howe (1997: 17) also noted that:
Because their construction has never been guided by any formal definition of what intelligence is, intelligence tests are strikingly different from genuine measuring instruments. Binet and Simon’s choice of items to include as the problems that made up their test was based purely on practical considerations.
IQ tests are ‘validated’ against older tests such as the Stanford-Binet, but the older tests were never validated themselves (see Richardson, 2002: 301.) Howe (1997: 18) continues:
In the case of the Binet and Simon test, since their main purpose was to help establish whether or not a child was capable of coping with the conventional school cirriculum, they sensibly chose items that seemed to assess a child’s capacity to succeed at the kinds of mental problems that are encountered in the classroom. Importantly, the content of the first intelligence test was decided by largely pragmatic considerations rather than being constrained by a formal definition of intelligence. That remains largely true of the tests that are used even now. As the early tests were revised and new assessment batteries constructed, the main benchmark for believing a new test to be adequate was its degree of agreement with the older ones. Each new test was assummed to be a proper measure of intelligence if the distributions of people’s scores at it matched the pattern of scores at a previous test, a line of reasoning that conveniently ignored the fact that the earlier ‘measures’ of intelligence that provided the basis for confirming the quality of the subsequent ones were never actually measures of anything. In reality … intelligence tests are very different from true measures (Nash, 1990). For instance, with a measure such as height it is clear that a particular quantity is the same irrespective of where it occurs. The 5 cm difference between 40 cm and 45 cm is the same as the 5 cm difference between 115 cm and 120 cm, but the same cannot be said about differing scores gained in a psychological test.
Conclusion
This discussion of the construction of IQ tests and the history of IQ testing can lead us to one conclusion: that differences in scores can be built into and out of the tests based on the prior assumptions of the test’s constructors; the history of IQ testing is rife with these same assumptions; and all newer tests are ‘validated’ on their agreement with older—still non-valid!—tests. The genesis of IQ testing beginning with social prejudices, constructing the tests to agree with the current hierarchy, however, does indeed damn the conclusions of the tests—that group A outscores group B does not mean that A is more ‘intelligent’ than B; it only means that A was exposed to more of the knowledge on the test.
The normal distribution, too, is a result of the same item addition/elimination to get the expected scores—the scores that then agree with the constructors’ racial and class biases. Bias in mental testing does exist, contra Jensen (1980). It exists due to carefully selected items to distinguish between different racial groups and social classes.
This critique in IQ testing I have mounted is not an ‘environmentalist’ critique, either. It is a methodological one.

One of the thing I’ve noted is that most of the articles to cite are older. Nothing wrong with that, but since time is short I like to focus on the new articles.
We now have three admixture studies (Lasker 2019, Kierkegard 2019 and Warne 2019) that all support racial hereditarianism. Shouldn’t that be the jumping off point for future discussions of race differences in intelligence?
LikeLike
It’s been explained to you time and time again how those admixture studies are not evidence and that the small correlations found can be explained without appealing to genes.
Admixture studies, in any case, are irrelevant to this article. This article describes the history of IQ tests and how test constructors presuppose their score distributions and construct the test to reflect that.
LikeLike
No it hasn’t been explained to me.
We have three studies (one which included Hispanics) and the higher the rate of European admixture the higher the IQ. And the results are linear. If the environmentalist thesis were correct you’d expect the IQ to increase significantly when, say, a black person hits 30 or 40 percent white when he has lighter skin or perhaps a parent from a different background.
Even Flynn and Nisbett have cited older admixture studies (Witty & Jenkins and Eyferth for example).
I’m curious, what would count as evidence for the racial hereditarian thesis?
LikeLike
Yes it has.
What would count as evidence? Construct a test that isn’t biased—but this is impossible (see Cole) as all tests are culture-bound. “What would count as evidence” for hereditarianism is the wrong question to ask as you’re pushing a false dichotomy between genes and environment. What else is new for “hereditarians.”
LikeLike
The results are statistically significant and just as importantly they are linear. What’s your explanation for the fact that they don’t jump around as the rate of admixture changes?
LikeLike
Again. This has been explained to you time and time again.
LikeLike
And we also have GWAs studies and brain size differnces. How many lines of evidence do you need?
LikeLike
Imagine thinking GWA studies show causation.
LikeLike
imagine thinking ONLY 79% of italians are feeble minded.
LikeLike
Andrew Strenio…
this is true of tests like the wechsler which are normed on ca 2,500 people.
this is NOT true of entrance exams. there are whole sections which don’t count toward one’s score which are used to test the test. but the test taker doesn’t know which section counts.
what are the criteria for inclusion or exclusion given statistics on 100s of thousands or millions? idk. but one would be “is this question answered correctly any more often than chance would predict?” if “no” i expect it would be excluded.
LikeLike
In the special vocabulary of psychometrics…
this is why objective tests must always be the sole criterion of admissions as they are in every country on earth except les etats unis merdeux and canada.
the tests may be shit, but all alternatives are even shittier and the tests can be changed.
if you can’t measure it, you can’t change it. — william deming
if rr thinks objective tests need to be scratched and 100% subjective methods like high school grades and essay and whatever bullshit used instead, then he needs to suck a black felon’s asshole in prison.
LikeLike
The 5 cm difference between 40 cm and 45 cm is the same as the 5 cm difference between 115 cm and 120 cm…
that’s racist.
it’s well known that the way westerners measure length is biased against korean men’s penises and in favor of black men’s penises.
LikeLike
In the Lasker 2019 study the correlation between g and European ancestry is .41, which is moderate
LikeLike
” . . . that group A outscores group B does not mean that A is more ‘intelligent’ than B; it only means that A was exposed to more of the knowledge on the test.”
If whites are not on average more intelligent than blacks, then why is it that no black has (to the best of my knowledge) has one a nobel prize in science?
Look at it this way: the white IQ is 100 and the average black IQ is 85. What’s more likely – that relatively few blacks can master calculus because they haven’t been exposed to it or that they don’t have the intelligence to master it?
And consider the following. IQ scores correlate to biological facts: brain size, glucose metabolism, electrical potential and reaction. IQ correlates to various social results such as crime, job success, drug abuse, etc. That this is all a coincidence seems very unlikely.
I can imagine that the low IQ of blacks is due to cultural factors such as parenting and education. But the claim that IQ differences in races aren’t real differences in intelligence obviously is false.
LikeLiked by 1 person