
2300 words
One debate in the philosophy of science is whether or not a scientific hypothesis should make testable predictions or merely explain only what it purports to explain. Should a scientific hypothesis H predict previously unknown facts of the matter or only explain an observation? Take, for example, evolutionary psychology (EP). Any EP hypothesis H can speculate on the so-called causes that led a trait to fixate in a biological population of organisms, but the claim that they can do more than that—that is, that they can generate successful predictions of previously unknown facts not used in the construction of the hypothesis—but that’s all they can do. The claim, therefore, that EP hypotheses are anything but just-so stories, is false.
Prediction and novel facts
For example, Einstein’s theory of general relativity predicted the bending of light, which was a novel prediction for the hypothesis (see pg 177-180 for predictions generated from Einstein’s theory). Fresnel’s wave theory of light predicted different infraction fringes to the prediction of the white spot—a spot which appears in a circular object’s shadow due to Fresnel diffraction (see Worrall, 1989). So Fresnel’s theory explained the diffraction and the diffraction then generated testable—and successful—novel predictions (see Magnus and Douglas, 2013). There is an example of succeful novel prediction. Ad hoc hypotheses are produced “for this” explanation—so the only evidence for the hypothesis is, for example, the existence of trait T. EP hypotheses attempt to explain the fixation of any trait T in humans, but all EP hypotheses do is explain—they generate no testable, novel predictions of previously unknown facts.
A defining feature of science and what it purports to do is to predict facts-of-the-matter which are yet to be known. John Beerbower (2016) explains this well in his book Limits of Science? (emphasis mine):
At this point, it seems appropriate to address explicitly one debate in the philosophy of science—that is, whether science can, or should try to, do more than predict consequences. One view that held considerable influence during the first half of the twentieth venture is called the predictivist thesis: that the purpose of science is to enable accurate predictions and that, in fact, science cannot actually achieve more than that. The test of an explanatory theory, therefore, is its success at prediction, at forecasting. This view need not be limited to actual predictions of future, yet to happen events; it can accommodate theories that are able to generate results that have already been observed or, if not observed, have already occurred. Of course, in such cases, care must be taken that the theory has not simply been retrofitted to the observations that have already been made—it must have some reach beyond the data used to construct the theory.
That a theory or hypothesis explains observations isn’t enough—it must generate successful predictions of novel facts. If it does not generate any novel facts-of-the-matter, then of what use is the hypothesis if it only weakly justifies the phenomenon in question? So now, what is a novel fact?
A novel fact is a fact that’s generated by hypothesis H that’s not used in the construction of the hypothesis. For example, Musgrave (1988) writes:
All of this depends, of course, on our being able to make good the intuitive distinction between prediction and novel prediction. Several competing accounts of when a prediction is a novel prediction for a theory have been produced. The one I favour, due to Elie Zahar and John Worral says that a predicted fact is a novel fact for a theory if it was not used to construct that theory — where a fact is used to construct a theory if it figures in the premises from which that theory was deduced.
Mayo (1991: 524; her emphasis) writes that a “novel fact [is] a newly discovered fact—one not known before used in testing.” So a fact is novel when it predicts a fact of the matter not used in the construction of the hypothesis—i.e., a future event. About novel predictions, Musgrave also writes that “It is only novel predictive success that is surprising, where an observed fact is novel for a theory when it was not used to construct it.” So hypothesis H entails evidence E; evidence E is not used in the construction of hypothesis H, therefore E is novel evidence for hypothesis H.
To philosopher of science Imre Lakatos, a progressive research program is one that generates novel facts, whereas a degenerating research program either fails to generate novel facts or the predictions made that were novel continue to be falsified, according to Musgrave in his article on Lakatos. We can put EP in the “degenerating research program, as no EP hypothesis generates any type of novel prediction—the only evidence for the trait is the existence of the trait.
Evolutionary Psychology
The term “just-so stories” comes from Rudyard Kipling Just-so Stories for Little Children. Then Gould and Lewontin used the term for evolutionary hypotheses that can only explain and not predict future as-of-yet-known events. Law (2016) notes that just-so stories offer “little in the way of independent evidence to suggest that it is actually true.” Sterelny and Griffiths (1999: 61) state that just-so stories are “… an adaptive scenario, a hypothesis about what a trait’s selective history might have been and hence what its function may be.” Examples of just-so stories covered on this blog include: beards, FOXP2, cartels and Mesoamerican ritual sacrifice, Christian storytelling, just-so storytellers and their pet just-so stories, the slavery hypertension hypothesis, fear of snakes and spiders, and cold winter theory. Smith (2016: 278) has a helpful table showing ten different definitions and descriptions of just-so stories:
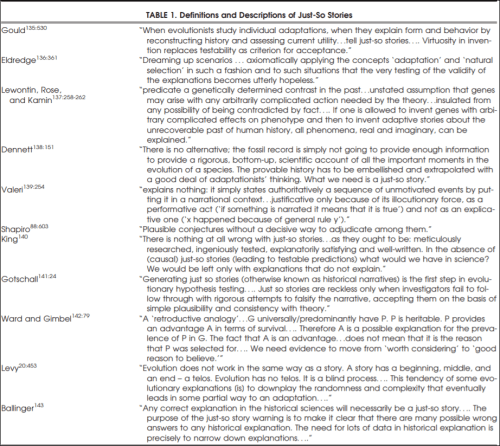
So the defining criterion for just-so stories is that there must be independent evidence to believe the proposed explanation for the existence of the trait. There must be independent reasons to believe a certain hypothesis, as the defining feature of a scientific hypothesis or theory is whether or not it can predict yet-to-happen events. Though, as Beerbower notes, we have to be careful that we do not retrofit the observations.
One can make an observation. Then they can work backward (what Richardson (2007) elicits is “reverse engineering”) and posit (speculate about) a good-sounding story (just-so storytelling) to explain this observation. Reverse engineering is “a process of figuring out the design of a mechanism on the basis of an analysis of the tasks it performs” (Buller, 2005: 92). Of course, the just-so storyteller can then create a story to explain the fixation of the trait in question. But that’s only (purportedly) the explanation of why the trait came to fixation for us to observe it today. There are no testable predictions of previously unknown facts. So it’s all storytelling—speculation.
The theory of natural selection is then deployed to attempt the explain the fixation of trait T in any population. It is true that a hypothesis is weakly corroborated by the existence of trait T, but what makes it a just-so story is the fact that there are no successful predictions of previously unknown facts,
When it comes to EP, one can say that the hypothesis “makes sense” and it “explains” why trait T still exists and went to fixation. However, the story only “makes sense” because there is no other way for it to be—if the story didn’t “make sense”, then the just-so storyteller wouldn’t be telling the story because it wouldn’t satisfy their aims of “proving” that a trait is an adaptation.
Smith (2016:277-278) notes 7 just-so story triggers:
1) proposing a theory-driven rather than a problem-driven explanation, 2) presenting an explanation for a change without providing a contrast for that change, 3) overlooking the limitations of evidence for distinguishing between alternative explanations (underdetermination), 4) assuming that current utility is the same as historical role, 5) misusing reverse engineering, 6) repurposing just-so stories as hypotheses rather than explanations, and 7) attempting to explain unique events that lack comparative data.
EP is most guilty of (3), (4), (5), (6), and (7). It is guilty of (3) in that it hardly ever posits other explanations for trait T, it’s always “adaptation”, as EP is an adaptationist paradigm. It is guilty of (4) perhaps the most. That trait T still exists and is useful for this today is not evidence that trait T was selected-for its use as we see it today. This then leads to (5) which is the misuse of reverse engineering. Just-so stories are ad hoc (“for this”) explanations and these types of explanations are ad hoc if there is no independent data for the hypothesis. Of course, it is guilty of (7) in that it attempts to explain, of course, unique events in human evolution. Many problems exist for evolutionary psychology (see for example Samuels, 1998; Lloyd, 1999; Prinz, 2006;), but the biggest problem is the ability of any hypothesis to generate testable, novel predictions. Smith (2016: 279) further writes that:
An important weakness in the use of narratives for scientific purposes is that the ending is known before the narrative is constructed. Merton pointed out that a “disarming characteristic” of ex post facto explanations is that they are always consistent with the observations because they are selected to be so.
Bo Winegard, in his defense of just-so storytelling, writes “that inference to the best explanation most accurately describes how science is (and ought to be) practiced. According to this description, scientists forward theories and hypotheses that are coherent, parsimonious, and fruitful.” However, as Smith (2016: 280-281) notes, that a hypothesis is “coherent”, “parsimonious” and “fruitful” (along with 11 more explanatory virtues of IBE, including depth, precision, consilience, and simplicity) is not sufficient to accept IBE—IBE is not a solution to the problems proposed by the just-so story critics as the slew of explanatory virtues do not lend evidence that T was an adaptation and thusly do not lend evidence that hypothesis H is true.
Simon (2018: 5) concludes that “(1) there is much rampant speculation in evolutionary psychology as to the reasons and the origin for certain traits being present in human beings, (2) there is circular reasoning as to a particular trait’s supposed advantage in adaptability in that a trait is chosen and reasoning works backward to subjectively “prove” its adaptive advantage, (3) the original classical theory is untestable, and most importantly, (4) there are serious doubts as to Natural Selection, i.e., selection through adaptive advantage, being the principal engine for evolution.” (1) is true since that’s all EP is—speculation. (2) is true in evolutionary psychologists notice trait T and that, since it survived today, there must be a function it performs for why natural selection “selected” the trait to propagate in species (though selection cannot select-for certain traits). (3) it is untestable in that we have no time machine to go back and watch how trait T evolved (this is where the storytelling narrative comes in: if only we had a good story to tell about the evolution of trait T). And finally, (4) is also true since natural selection is not a mechanism (see Fodor, 2008; Fodor and Piattelli-Palmarini, 2010).
EP exists in an attempt to explain so-called psychological adaptations humans have to the EEA (environment of evolutionary adaptiveness). So one looks at the current phenotype and then looks to the past in an attempt to construct a “story” which shows how a trait came to fixation. There are, furthermore, no hallmarks of adaptation. When one attempts to use selection theory to explain the fixation of trait T, they must wrestle with spandrels. Spandrels are heritable, can increase fitness, and they are selected as well—as the whole organism is selected. This also, of course, falls right back to Fodor’s (2008) argument against natural selection. Fodor (2008: 1) writes that the central claim of EP “is that heritable properties of psychological phenotypes are typically adaptations; which is to say that they are typically explained by their histories of selection.” But if “psychological phenotypes” cannot be selected, then the whole EP paradigm crumbles.
Conclusion
This is why EP is not scientific. It cannot make successful predictions of previously unknown facts not used in the construction of the hypothesis, it can only explain what it purports to explain. The claim, therefore, that EP hypotheses are anything but just-so stories is false. One can create good-sounding narratives for any type of trait. But that they “sound good” to the ear, and are “plausible” are not reasons to believe that the story told is true.
Are all hypotheses just-so stories? No. Since a just-so story is an ad hoc hypothesis and a hypothesis is ad hoc if it cannot be independently verified, then a hypothesis that makes predictions which can be independently verified are not just-so stories. There are hypotheses that generate no predictions, ad hoc hypotheses (where the only evidence to believe H is the existence of trait T), and hypotheses that generate novel predictions. EP is the second of these—the only evidence we have to believe H is true is that trait T exists. Independent evidence is a necessary condition of science—that is, the ability of a hypothesis to predict novel evidence is a necessary condition for science. That no EP hypothesis can generate a successful novel prediction is evidence that all EP hypotheses are just-so stories. So for the criticism to be refuted, one would have to name an EP hypothesis that is not a just-so story—that is, (1) name an EP hypothesis, (2) state the prediction, and then (3) state how the prediction follows from the hypothesis.
To be justified in believing hypothesis H in explaining how trait T became fixated in a population there must be independent evidence for this belief. The hypothesis must generate a novel fact which was previously unknown before the hypothesis was constructed. If the hypothesis cannot generate any predictions, or the predictions it makes are continuously falsified, then the hypothesis is to be rejected. No EP hypothesis can generate successful predictions of novel facts and so, the whole EP enterprise is a degenerative research program. The EP paradigm explains and accommodates, but no EP hypothesis generates independently confirmable evidence for any of its hypotheses. Therefore EP is not a scientific program and just-so stories are not scientific.

Here is a case which I believe qualifies as making an EP hypothesis not just a “just-so” story. In gender differentiation, it is hypothesized that the traditional roles are determined by the amount of parental investment from each gender. There was an inherent bias in the beginning because of the difference in metabolic contribution between males and females. Female, most broadly defined, being the parent which donates the gamete with mitochondria, and the bulk of cell constituents, and the male donating the gamete absent mitochondria. Given the higher metabolic cost, the female became the pickier one. As social behavior evolved this fundamental bias was accentuated into the behavior. Males thus became more competitive, which might mean being larger and better able to fight or having more colorful displays. Or the ability to provide resources such as building a nest.
If this role pattern is a direct result of parental investment, the exceptions which prove the rule should only show reversed roles in species which had inverted the pattern of parental investment. This, obviously, hasn’t happened very often, but there are a few examples. IIRC the north atlantic wren (bird) is such an example. In this species the male builds the nest and performs most of the care of the offspring, and as expected in this species the females are larger and compete for males.
LikeLike
The main claim of Trivers’ parental investment theory—that anisogamy lies at the heart of male-female sex differences because gametes are a form of pre-zygotic parental investment—is false. Trivers is also guilty of the Concorde fallacy. See:
https://onlinelibrary.wiley.com/doi/full/10.1111/j.1420-9101.2008.01540.x
So yes, it’s still a just-so story. I’d also recommend Robert Richardson’s discussion of the theory in his book Evolutionary Psychology as Maladapted Psychology (chapter 4) and David Buller’s discussion of it in Adapting Minds (chapter 6).
LikeLike
who is pilon?
LikeLike
So “the ground is in my driveway is wet, I this this is because it rained last night” is a just-so story because the only evidence in favour of the hypothesis (it rained last night) is the wet driveway, which is the thing we are trying to explain.
While “the ground in my driveway is wet. I think this is because it rained last night, so if the rest of the city is also wet, that is evidence it rained last night. I have walked around the city and it would appear my prediction is confirmed, the rest of the city is wet, so it rained last night” is not a just-so story because we observed the wet ground, made a hypothesis, make a prediction from that and found our prediction was confirmed (it’s a novel fact since we didn’t know the city was wet when we made the prediction), making this scientific.
That’s how it works, right?
LikeLike