For more than 100 years—from Galton and Spearman to Burt, Jensen, Rushton, Lynn and today’s polygenic score enthusiasts—hereditarian thinkers have argued that general intelligence is a unitary, highly heritable biological trait and that observed individual and group level differences in IQ and it’s underlying “g” factor primarily reflect genetic causation. The Bell Curve brought such thinking into the mainstream from obscure psychology journals, and today hereditarian behavioral geneticists claim that 10 to 20 percent of the variance in education and cognitive performance has been explained by GWA studies (see Richardson, 2017). The consensus is that intelligence within and between populations is largely genetic in nature.
While hereditarianism is empirically contested and morally wrong, the biggest kill-shot is that it is conceptually impossible, and one can use many a priori arguments from philosophy of mind to show this. Donald Davidson’s argument against the possibility of psychophysical laws, Kripke’s reading of Wittgenstein, and Nagel’s argument from indexicality can be used to show that hereditarianism is a category error. Ken Richardson’s systems theory can then be used to show that g is an artifact of dynamic systems (along with test construction), and Vygotsky’s cultural-historical psychology shows that higher mental functions (which hereditarians try to explain biologically) originate as socially scaffolded, inter-mental processes mediated by cultural tools and interactions with more knowledgeable others, not individual genetic endowment.
Thus, these metaphysical, normative, systemic, developmental and phenomenological refutations show that hereditarianism is based on a category mistake. Ultimately, what hereditarianism lacks is a coherent object to measure—since psychological traits aren’t measurable at all. I will show here how hereditarianism can be refuted with nothing but a priori logic, and then show what really causes differences in test scores within and between groups. Kripke’s Wittgenstein and the argument against the possibility of psychophysical laws, along with a Kim-Kripke normativity argument against hereditarianism show that hereditarianism just isn’t a logically tenable position. So if it’s not logically tenable, then the only way to explain gaps in IQ is an environmental one.
I will begin with showing that no strict psychophysical laws can link genes/brain states to mental kinds, then demonstrating that even the weaker functional-reduction route collapses at the very first step because no causal-role definition of intentionality (intelligence) is possible. After that I will add the general rule following considerations from Kripke’s Wittgenstein and then add it to my definition of intelligence, showing that rule-following is irreducibly normative and cannot be fixed by any internal state and that no causal-functional definition is possible. Then I will show that the empirical target of hereditarianism—the g factor—is nothing more than a statistical artifact of historically contingent, culturally-situated rule systems and not a biological substrate. These rule systems do not originate internally, but they develop as inter-mental relations mediated by cultural tools. Each of these arguments dispenses with attempted hereditarian escapes—the very notion of a genetically constituted, rank-orderable general intelligence is logically impossible.
We don’t need “better data”—I will demonstrate that the target of hereditarian research does not and cannot exist as a natural, measurable, genetically-distributed trait. IQ scores are not measurements of a psychological magnitude (Berka, 1983; Nash, 1990); no psychophysical laws exist that can bridge genes to normative mental kinds (Davidson, 1979), and the so-called positive manifold is nothing more than a cultural artifact due to test construction (Richardson, 2017). Thus, what explains IQ variance is exposure to the culture in which the right rules are used regarding the IQ test.
Psychophysical laws don’t exist
Hereditarianism implicitly assumes a psychophysical law like “G -> P.” Psychophysical laws are universal, necessary mappings between physical states and mental states. To reduce the mental to the physical, you need lawlike correlations—whenever physical state P occurs, mental state M occurs. These laws must be necessary, not contingent. They must bridge the explanatory gap from the third-personal to the first-personal. We have correlations, but correlations don’t entail identity. If correlations don’t entail identity, then the correlations aren’t evidence of any kind is psychophysical law. So if there are no psychophysical laws, there is no reduction and there is no explanation of the mental.
Hereditarianism assumes type-type psychophysical reduction. Type-type identity posits that all instances of a mental type correspond to all instances of a physical type. But hereditarians need bridge laws—they imply universal mappings allowing reduction of the mental to the measurable physical. But since mental kinds are anomalous, type-type reduction is impossible.
Hereditarians claim that genes cause g which then cause intelligence. This requires type-type reduction. Intelligence kind = g kind = physical kind. But g isn’t physical—it’s a mathematical construct, the first PC. Only physical kinds can be influenced by genes;nonphysical kinds cannot. Even if g correlates with brain states, correlation isn’t identity. Basically, no psychophysical laws means no reduction and therefore no mental explanation.
If hereditarianism is true, then intelligence is type-reducible to g/genes. If type-reduction holds, then strict psychophysical laws exist. So if hereditarianism is true, then strict psychophysical laws exist. But no psychophysical laws exist, due to multiple realizablilty and Davidson’s considerations. So hereditarianism is false.
We know that the same mental kind can be realized in different physical kinds, meaning that no physical kind correlates one-to-one necessarily with a mental kind. Even if we generously weaken the demand from strict identity to functional laws, hereditarian reduction still fails (see below).
The Kim-Kripke normativity argument
Even the only plausible route to mind-body reduction that most physicalists still defend collapses a priori for intentional/cognitive states because no causal-functional definition can ever capture the normativity of meaning and rule following (Heikenhimo, 2008). Identity claims like water = h2O only work because the functional profile is already reducible. Since the functional profile of intentional intelligence is not reducible, there is no explanatory bridge from neural states to the normativity of thought. So identity claims fail—this just strengthens Davidson’s conclusions. Therefore, every reductionist strategy that could possibly license the move from “genetic variance -> variation in intelligence” is blocked a priori.
(1) If hereditarianism is true, then general intelligence as a real cognitive capacity must be reducible to the physical domain (genes, neural states, etc).
(2) The only remaining respectable route to mind-body reduction of cognitive/intentional processes is Kim’s three-step functional-reduction model.
(C1) So if hereditarianism is true, then general intelligence must he reducible to Kim’s three-step functional-reduction model.
(3) Kim-style reduction requires—as its indispensable first step—an adequate causal-functional definition of the target property (intelligence, rule-following, grasping meaning, etc) that preserves the established normative meaning of the concept without circularly using mental/intentional vocabulary in the definiens.
(4) Any causal-functional definition of intentional/cognitive states necessarily obliterates the normative distinction between correct and incorrect application (Kripke’s normativity argument applied to mental content).
(C2) Therefore, no adequate causal-functional definition of general intelligence is possible, even in principle.
(5) If no adequate causal-functional definition is possible, then Kim-style functional reduction of general intelligence is impossible.
(C3) So Kim-style functional reduction of general intelligence is impossible.
(C4) So hereditarianism is false.
A hereditarian can resist Kim-Kripke in 4 ways but each fails. (1) They can claim intelligence need not be reducible, but then genes cannot causally affect it, dissolving hereditarianism into mere correlation. (2) They can reject Kim-style reduction in factor of non-reductive or mechanistic physicalism, but these views still require functional roles and collapse under Kim’s causal exclusion argument. (3) They can insist that intelligence has a purely causal-functional definition (processing efficiency or pattern recognition), but such definitions omit the normativity of reasoning and therefore do no capture intelligence at all. (4) They can deny that normativity matters, but removing correctness conditions eliminates psychological content and makes “intelligence” unintelligible, destroying the very trait hereditarianism requires. Thus, all possible routes collapse into contradiction or eliminativism.
The rule-following argument against hereditarianism
Imagine a child who is just learning to add. She adds 68+57=125. We then say that she is correct. Why is 125 correct and 15 incorrect? It isn’t correct because she feels sure, because someone who writes 15 could be just as sure. It isn’t correct because her brain lit up in a certain way, because the neural pattern could also belong to someone following a different rule. It isn’t correct because all of her past answers, because all past uses were finite and are compatible with infinitely many bizzare rules that only diverge now. It isn’t correct because of her genes or any internal biological state, because DNA is just another finite physical fact inside of her body.
There is nothing inside of her head, body or genome that reaches out and touches the difference between correct and incorrect. But the difference is real. So where does it lie? It lives outside of her in the shared community practices. Correctness is a public status, not a private possession. Every single thing that IQ tests reward—series completion, analogies, classification, vocabulary, matrix reasoning—is exactly this kind of going on correctly. So every single point on an IQ test is an act whose rightness is fixed in the space of communal practice. What we call “intelligence” exists only between us—between the community, society and culture in which an individual is raised.
Intelligence is a normative ability. To be intelligent is to go on in the same way, to apply concepts correctly, to get it right when solving new problems, reasoning, understanding analogies, etc. So intelligence = rule-following (grasping and correctly applying abstract patterns).
Rule following is essentially normative—there is a difference between seeming right and being right. Any finite set of past performances is compatible with an infinite set of many rules. No fact about an individual—neither physical nor mental content—uniquely determines the rule they are following. So no internal state fixes the norm. Thus, rule following cannot be constituted by internal/genetic states. No psychophysical law can connect G to correct rule following (intelligence).
Therefore rule-following is set by participation in a social practice. Therefore, normative abilities (intelligence, reasoning, understanding) are socially, not genetically, constituted. So hereditarianism is logically impossible.
At its core, intelligence is the ability to get it right. Getting it right is a social status conferred by participation in communal practices. No amount of genetic or neural causation can confer that status—because no internal state can fix the normative fact. So the very concept of “genetically constituted general intelligence” is incoherent. Therefore, hereditarianism is logically impossible.
(1) H -> G -> P Hereditarianism -> genes/g -> normative intelligence (2) P -> R Normative intelligence -> correct rule-following. (3) R -> ~G Rule following cannot be fixed by internal physical/mental states. So ~(G -> P) So ~H.
The Berka-Nash measurement objection
This is a little-known critique of psychology and IQ. First put forth in Karel Berka’s 1983 book Measurement: It’s Concepts, Theories, and Problems, and then elaborated on in Roy Nash’s (1990) Intelligence and Realism: A Materialist Critique of IQ.
If hereditarianism is true, then intelligence must be a measurable trait (with additive structure, object, and units) that genes can causally influence via g. If intelligence is measurable, then psychophysical laws must exist to map physical causes to mental kinds. But no such measurability or laws exist. Thus, hereditarianism is false.
None of the main, big-name hereditarians have ever addressed this type of argument. (Although Brand et al, 2003 did attempt to, their critique didn’t work and they didn’t even touch the heart of the matter.) Clearly, the argument shows that hereditarian psychology is weak to such critique. The above argument shows that IQ is quasi-quantification, without an empirical object, no structure, or lawful properties
The argument for g is circular
“Subtests within a battery of intelligence tests are included n the basis of them showing a substantial correlation with the test as a whole, and tests which do not show such correlations are excluded.” (Tyson, Jones, and Elcock, 2011: 67)
g is defined as the common variance of pre-selected subtests that must correlate. Subtests are included only if they correlate. A pattern guaranteed by construction cannot be evidence of a pre-existing biological unity. So g is a tautological artifact, not a natural kind that genes can cause.
Hereditarians need g to be a natural kind trait that genes can act upon. But g is an epiphenomenal artifact due to test construction produced by current covariation of culturally specific cognitive tasks in modern school societies. Artifacts of historically contingent cultural ecologies are not natural kind traits. So g is not a natural kind. So hereditarianism is false.
The category error argument
Intelligence is a first-person indexical act. g is a third-person statistical abstraction. There can be no identity between a phenomenonal act and a statistical abstraction. So g cannot be intelligence—no reduction is possible.
There is no such thing as genetically constituted general intelligence since intelligence is a rational normative competence, the g factor is an epiphenomenal artifact of a historically contingent self-organizing cultural-cognitive ecology, and higher psychological functions originate as social relations mediated by cultural tools which only later appear individual. Hereditarianism tries to explain a normative status with causal mechanisms, a dynamic cultural artifact with a fixed trait, and an inter-mental function with intra-cranial genetics.
g is a third-person statistical construct. Intelligence, as a psychological trait, consists of first-person indexical cognitive acts. Category A – third-person, impersonal (g, PGS, allele frequencies, brain scans). Category B – first-person, subjective, experiential).
Genetic claims assert that differences in g (category A) are caused by differences in genes and that this then explains differences in intelligence (category B). For such claims to be valid, g (category A) must be identical to intelligence (category B). But g has no first-person phenomenology meaning no one experiences using g, while intelligence does. So g (category A) cannot be identical to intelligence (category B).
Thus, claiming genes cause differences in g which then explain group differences in intelligence commits a category error, since a statistical artifact is equated with a lived, psychological reality.
A natural-kind trait must be individuated independent of the measurement procedure. g is individuated only by the procedure (PC1 extracted from tests chosen for their intercorrelations). Therefore, g is not a natural-kind trait. Only natural kinds can plausibly be treated as biological traits. Thus, g is not a biological trait.
Combining this argument with the Kim-Kripke normativity argument shows that hereditarians don’t just reify a statistical abstraction, they try to reduce a normative category into a descriptive one.
Vygotsky’s social genesis of higher functions
Higher psychological functions originate as social relations mediated by cultural tools which only later appear individual. If hereditarianism is true, then higher psychological functions originate as intra-individual genetic endowments. A function cannot originate both as inter-mental social relations and as intra-individual genetic endowments. So hereditarianism is false.
Intelligence is not something a sole individual possesses—it is something a person achieves within a cultural-historical scaffold. Intelligence is not an individual possession that cab be ranked by genes, it is a first-person indexical act that is performed within, and made possible by, that social scaffold.
Ultimately, Vygotsky’s claim is ontological, not merely developmental. Higher mental functions are constituted by social interaction and cultural tools. Thus, their ontological origin cannot be genetic because the property isn’t intrinsic, it’s relational. No amount of intra-individual genetic variation can produce a relational property.
Possible counters
“We don’t need reduction, we only need prediction/causal inference. We’re only showing genes -> brains -> test scores.” If genes or polygenic scores causally explain the intentional-level fact that someone got question 27 right, there must be a strict law covering the relation. There is none. All they have is physical-physical causation—DNA -> neural firing -> finger movement. The normative fact that the movement was the correct one is never touched by any physical law.
“Intelligence is just “whatever enables success on complex cognitive tasks—we can functionalize it that way and avoid normativity.” This is the move that Heikenhimo (2008) takes out. Any causal-role description of “getting it right on complex tasks” obliterates the distinction between getting it right and merely producing behavior that happens to match. The normativity argument shows you can’t define “correct application” in purely causal terms without eliminativism or circularity.
“g is biologically real because it correlates with brain volume, reaction time, PGSs, etc.” Even if every physical variable perfectly correlated with getting every Raven item right, it still wouldn’t explain why one pattern is normatively correct and another isn’t. The normative status is anomalous and socially constituted. Correlation isn’t identity and identity is impossible.
“Heritability is just a population statistic.” Heritability presupposes that the trait is well-defined and additive in the relevant population. The Berka-Nash measurement objection shows that IQ (and any psychological trait) is not quantitatively-structured trait with a conjoint measurement structure. Without that, h2 is either undefined or meaningless.
Even then, the hereditarian can agree with the overall argument I’ve mounted here and say something like: “Psychometrics and behavioral genetics have replaced the folk notion of intelligence with a precise, operational successor concept: general cognitive ability as indexed by the first principle component of cognitive test variance. This successor concept is quantitative, additive, biologically real and has non-zero heritability. We aren’t measuring the irreducibly normative thing you’re talking about; we’re measuring something else that is useful and genetically influenced.” Unfortunately, this concept fails once you ask what justifies treating the first PC as a causal trait. As soon as you claim it causes anything at the intentional-level (higher g causes better reasoning, generic variance causes higher g which causes higher life success), they are back to needing psychophysical laws or a functional definition that bridges the normative gap. If they then retreat to pure physical prediction, they have then abandoned the claim that genes cause intelligence differences. Therefore, this concept is either covertly normative (and therefore irreducible), or purely descriptive/physical (therefore being irrelevant to intelligence.)
A successor concept can replace a folk concept if and only if it preserves the explanatorily relevant structure. But replacing “intelligence” with “PC1 of test performance” destroys the essential normative structure of the concept. Therefore, g cannot serve as a scientific successor to the concept of intelligence.
“We don’t need laws, identity, or functional definitions. Intelligence is a real pattern in the data. PGSs, brain volume, reaction time, educational attainment and job performance all compress onto a single and robust predictive dimension. That dimension is ontologically real in exactly the same way as temperature is real in statistical mechanics even before we had microphysical reduction. The heritability of the pattern is high. Therefore genes causally contribute to the pattern. g, the single latent variable, compresses performance across dozens of cognitive tests, predicts school grades, job performance, reaction time, brain size, PGSs with great accuracy. This compression is identical across countries, decades, and test batteries. So g is as real as temperature.” This “robust, predictive pattern” is real only as conformity to culturally dominant rule systems inside modern test-taking societies. The circularity of g still rears its head.
Conclusion
Hereditarianism rests on the unspoken assumption that general intelligence is a natural-kind, individual-level, biologically-caused property that can be lawfully tied to, or functionality defined in terms of, genes and brain states. Davidson shows there are no psychophysical laws; Kim-Kripke show even functional definitions are impossible; Kripke-Wittgenstein show that intelligence is irreducibly normative and holistic; Richardson/Vygotsky show that g is a cultural artifact and that higher mental faculties are born inter-mental;
Because IQ doesn’t measure any quantitatively-structured psychological trait (Berka-Nash), and no psychophysical laws exist (Davidson), the very notion of additive genetic variance contributing to variance in IQ is logically incoherent – h2 is therefore 0.
Hereditarianism requires general intelligence to be (1) a natural-kind trait located inside the skull (eg Jensen’s g), (2) quantitatively-structured so that genetic variance components are meaningful, (3) reducible—whether by strict laws or functional definition—to physical states that genes can modulate, and (4) the causal origin of correct rule-following on IQ tests. Every one of these requirements is logically impossible: no psychophysical laws exist (Davidson), no functional definitions of intentional states is possible (Heikenhimo), rule-following is irreducibly normative and socially constituted (Kripke-Wittgenstein), IQ lacks additive quantitative structure (Berka, Nash, Michell, Richardson) higher mental functions originate as social relations (Vygotsky).
Now I can say that: Intelligence is the dynamic capacity of individuals to engage effectively with their sociocultural environment, utilizing a diverse range of cognitive abilities (psychological tools), cultural tools, and social interactions, and realized through rule-governed practices that determine the correctness of reasoning, problem solving and concept application.
Differences in IQ, therefore, aren’t due to differences in genes/biology (no matter what the latest PGS/neuroimaging study tells you). They show an individual’s proximity to the culturally and socially defined practices on the test. So from a rule-following perspective, each test item has a normatively correct solution, determined by communal standards. So IQ scores show the extent to which someone has internalized the relevant, culturally-mediated rules, not a fixed, heritable mental trait.
So the object that hereditarians have been trying to measure and rank by race doesn’t and cannot exist. There is no remaining, respectable position for the hereditarian to turn to. They would all collapse into the same category error: trying to explain a normative, inter-mental historically contingent status with intra-cranial causation.
No future discovery—no better PGSs, no perfect brain scan, no new and improved test battery—can ever rescue the core hereditarian claim. Because the arguments here are conceptual. Hereditarianism is clearly a physicalist theory, but because physicalism cannot accommodate the normativity and rule following that constitute intelligence, the hereditarian position inherits physicalism’failure, making it untenable. Hereditarianism needs physicalism to be true. But since physicalism is false, so is hereditarianism.
(1) If hereditarianism is true then general intelligence must be a quantitatively-structured, individual-level, natural-kind trait that is either (a) linked by strict psychophysical laws or (b) functionally reducible to physical states genes can modulate.
(2) No such trait is possible since no psychophysical laws exist (Davidson), no functional reduction of intentional/normative states is possible (Kim-Kripke normativity argument), and rule-following correctness is irreducibly social and non-quantitative (Wittgenstein/Kripke, Berka, Nash, Michell, Richardson, Vygotsky).
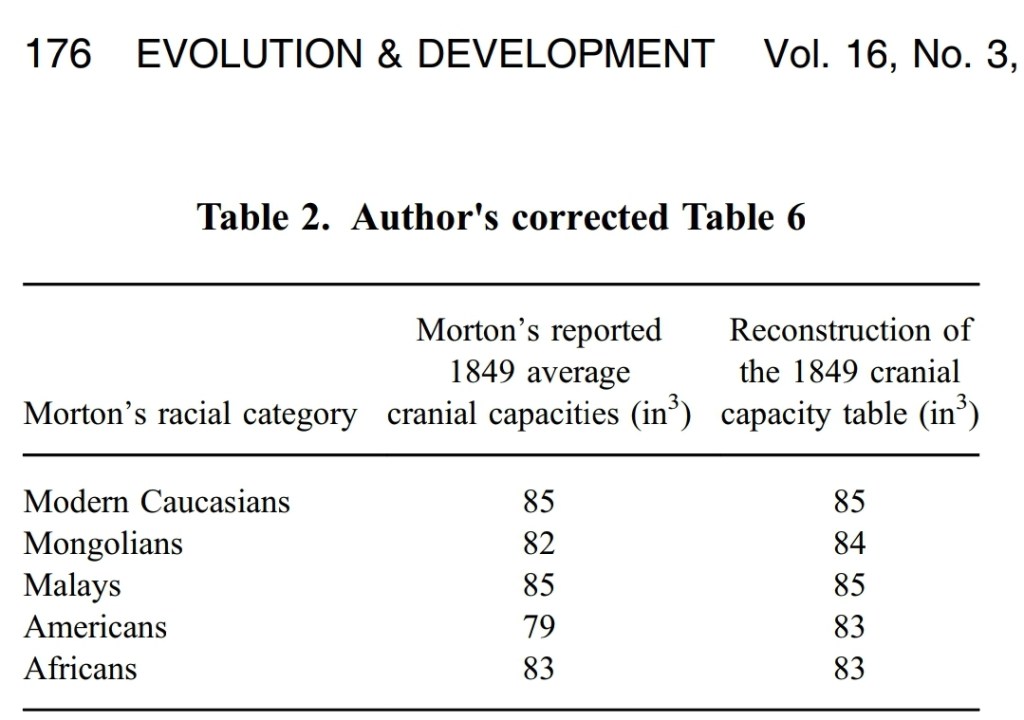
In his 1981 book The Mismeasure of Man, Stephen Jay Gould mounted a long, historical argument, against scientific racism and eugenics. A key point to the book was arguing against the so-called “general factor of intelligence” (GFI). Gould argued that the GFI was a mere reification—an abstraction treated as a concrete entity. In this article, I will formalize Gould’s argument from the book (that g is a mere statistical abstraction), and that we, therefore, should reject the GFI. Gould’s argument is one of ontology—basically what g is or isn’t. I have already touched on Gould’s argument before, but this will be a more systematic approach in actually formalizing the argument and defending the premises.
Spearman’s g was falsified soon after he proposed it. Jensen’s g is an unfalsifiable tautology, a circular construct where test performance defines intelligence and intelligence explains performance. Geary’s g rests on an identity claim: that g is identical to mitochondrial functioning and can be localized to ATP, but it lacks causal clarity and direct measurability to elevate it beyond a mere correlation to a real, biologically-grounded entity.
Gould’s argument against the GFI
In Mismeasure, Gould attacked historical hereditarian figures as reifying intelligence as a unitary, measurable entity. Mainly attacking Spearman’s Burt, Gould argued that since Spearman saw positive correlations between tests that, therefore, there must be a GFI to explain test intercorrelations. Spearman’s GFI is the first principle component (PC1), which Jensen redefined to be g. (We also know that Spearman saw what he wanted to see in his data; Schlinger, 2003.) Here is Gould’s (1981: 252) argument against the GFI:
Causal reasons lie behind the positive correlations of most mental tests. But what reasons? We cannot infer the reasons from a strong first principal component any more than we can induce the cause of a single correlation coefficient from its magnitude. We cannot reify g as a “thing” unless we have convincing, independent information beyond the fact of correlation itself.
Using modus tollens, the argument is:
(P1) If g is a real, biologically-grounded entity, then it should be directly observable or measurable independently of statistical correlations in test performance. (P2) But g is not directly observable or measurable as a distinct entity in the brain or elsewhere; it is only inferred from factor analysis of test scores. (C) So g is not a real biologically-grounded entity—it is a reification, an abstraction mistaken for a concrete reality.
(P1) A real entity needs a clear, standalone existence—not just a shadow in data. (P2) g lacks this standalone evidence, it’s tied to correlations. (C) So g isn’t real; it’s reified.
Hereditarians treat g as quantifiable brainstuff. That is, they assume that it can already be measured. For g to be more than a statistical artifact, it would need to have an independent, standalone existence—like an actual physical trait—and not merely just be a statistical pattern in data. But Gould shows that no one has located where in the brain this occurs—despite even Jensen’s (1999) insistence about g being quantifiable brainstuff:
g…[is] a biological [property], a property of the brain
The ultimate arbiter among various “theories of intelligence” must be the physical properties of the brain itself. The current frontier of g research is the investigation of the anatomical and physiological features of the brain that cause g.
…psychometric g has many physical correlates…[and it] is a biological phenomenon.
Just like in Jensen’s infamous 1969 paper, he wrote that “We should not reify g as an entity…since it is only a hypothetical construct“, but then he contradicted himself 10 pages later writing that g (“intelligence”) “is a biological reality and not just a figment of social conventions.” However, here are the steps that Jensen uses to infer that g exists:
(1) If there is a general intelligence factor “g,” then it explains why people perform well on various cognitive tests.
(2) If “g” exists and explains test performance, the absence of “g” would mean that people do not perform well on these tests.
(3) We observe that people do perform well on various cognitive tests (i.e., test performance is generally positive).
(4) Therefore, since “g” would explain this positive test performance, we conclude that “g” exists.
Put another way, the argument is: If g exists then it explains test performance; we see test performance; therefore g exists. Quite obviously, it seems like logic wasn’t Jensen’s strong point.
But if g is reified as a unitary, measurable entity, then it must be a simple, indivisible capacity which uniformly underlies all cognitive abilities. So if g is a simple, indivisible capacity that uniform underlies all cognitive abilities, then it must be able to be expressed as a single, consistent property unaffected by the diversity of cognitive tasks. So if g is reified as a unitary, real entity, then it must be expressed as a single cognitive property unaffected by the diversity of cognitive tasks. But g cannot be expressed as a single, consistent property unaffected by the diversity of cognitive tasks, so g cannot be reified as a unitary, real entity. We know, a priori, that a real entity must have a nature that can be defined. Thus, if g is real then it needs to be everything (all abilities) and one thing (a conceptual impossibility). (Note that step 4 in my steps is the rectification that Gould warned about.) The fact of the matter is, the existence of g is circularly tied to the test—which is where P1 comes into play.
“Subtests within a battery of intelligence tests are included n the basis of them showing a substantial correlation with the test as a whole, and tests which do not show such correlations are excluded.” (Tyson, Jones, and Elcock, 2011: 67)
This quote shows the inherent circularity in defining intelligence from a hereditarian viewpoint. Since only subtests that correlate are chosen, there is a self-reinforcing loop, meaning that the intercorrelations merely reflect test design. Thus, the statistical analysis merely “sees” what is already built into the test which then creates a false impression of a unified general factor. So using factor analysis to show that a general factor arises is irrelevant—since it’s obviously engineered into the test. The claim that “intelligence is what IQ tests measure” (eg Van der Maas, Kan, and Borsboom, 2014) but the tests are constructed to CONFIRM a GFI. Thus, g isn’t a discovered truth, it’s a mere construct that was created due to how tests themselves are created. g emerges from IQ tests designed to produce correlated subtest scores, since we know that subtests are included on the basis of correlation. The engineering of this positive manifold creates g, not as a natural phenomenon, but as a human creation. Unlike real entities which exist independently of how we measure them, g’s existence hinges on test construction which then stripes it of its ontological autonomy.
One, certainly novel, view on the biology supposedly underlying g is Geary’s (2018, 2019, 2020, 2021) argument that mitochondrial functioning—specifically the role of mitochondrial functioning in producing ATP through oxidative phosphorylation—is the biological basis for g. Thus, since mitochondria fuel cellular processes including neuronal activity, Geary links that efficiency to cognitive performance across diverse tasks which then explains the positive manifold. But Geary relies on correlations between mitochondrial health and cognitive outcomes without causal evidence tying it to g. Furthermore, environmental factors like pollutants affect mitochondrial functioning which means that external influences—and not an intrinsic g—could drive the observed patterns. Moreover, Schubert and Hagemann (2020) showed that Geary’s hypothesis doesn’t hold under scrutiny. Again, g is inferred from correlational outcomes, and not observed independently. Since Geary identifies g with mitochondrial functioning, he assumes that the positive manifold reflects a single entity, namely ATP efficiency. Thus, without proving the identity, Geary reifies a correlation into a thing, which is what Gould warned about not doing. Geary also assumes that the positive manifold demands a biological cause, making it circular (much like Jensen’s g). My rejection of Geary’s hypothesis hinges on causality and identity—mitochondrial functioning just isn’t identical with the mythical g.
The ultimate claim I’m making here is that if psychometricians are actually measuring something, then it must be physical (going back to what Jensen argued about g having a biological basis and being a brain property). So if g is what psychometricians are measuring, then g must be a physical entity. But if g lacks a physical basis or the mental defies physical reduction, then psychometrics isn’t measuring anything real. This is indeed why psychometrics isn’t measurement and, therefore, why a science of the mind is impossible.
For something to exist as a real, biological entity, it must exhibit real verifiable properties, like hemoglobin and dopamine, and it must exhibit specific, verifiable properties: a well-defined structure or mechanism; a clear function; and causal powers that can be directly observed and measured independently of the tools used to detect it. Clearly, these hallmarks distinguish real entities from mere abstractions/statistical artifacts. As we have seen, g doesn’t meet the above criteria, so the claim that g is a biologically-grounded entity is philosophically untenable. Real biological entities have specific, delimited roles, like the role of hemoglobin in the transportation of oxygen. But g is proposed as a single, unified factor that explains ALL cognitive abilities. So the g concept is vague and lacks the specificity expected of real biological entities.
Hemoglobin can be measured in a blood sample but g can’t be directly observed or quantified outside of the statistical framework of IQ test correlations. Factor analysis derives g from patters of test performance, not from an independent biological substrate. Further, intelligence encompasses distinct abilities, as I have argued. g cannot coherently unify the multiplicity of what makes up intelligence, without sacrificing ontological precision. As I argued above, real entities maintain stable, specific identities—g’s elasticity, which is stretched to explain all cognition—undermines it’s claims to be a singular, real thing.
Now I can unpack the argument like this:
(P1) A concept is valid if, and only if, it corresponds to an independently verifiable reality. (P2) If g corresponds to an independently verifiable reality, then it must be directly measurable or observable beyond the correlations of IQ test scores. (P3) But g is not directly observable beyond the correlations of IQ test scores; it is constructed through the deliberate selection of subtests that correlate with the overall test. (C1) Thus g does not correspond to an independently verifiable reality. (C2) Thus, g is not a valid concept.
Conclusion
The so-called evidence that hereditarians have brought to the table to infer the existence of g for almost 100 years since Spearman clearly fails. Even after Spearman formulated it, it was quickly falsified (Heene, 2008). Even then, for the neuroreductionist who would try to argue that MRI or fMRI would show a biological basis to the GFI, they would run right into the empirical/logical arguments from Uttal’s anti-neuroreduction arguments.
g is not a real, measurable entity in the brain or biology but a reified abstraction shaped by methodological biases and statistical convenience. g lacks the ontological coherence and empirical support of real biological entities. Now, if g doesn’t exist—especially as an explanation for IQ test performance—then we need an explanation, and it can be found in social class.
(P1) If g doesn’t exist then psychometricians are showing other sources of variation. (P2) The items on the test are class-dependent. (P3) If psychometricians are showing other sources of variation and the items on the tests are class-dependent, then IQ score differences are mere surrogates for social class. (C) Thus, if g doesn’t exist then IQ score differences are mere surrogates for social class.
We don’t need a mysterious factor to explain the intercorrelations. What does explain it is class—exposure to the item content of the test. We need to dispense with a GFI, since it’s conceptual incoherence and biological implausibility undermine it’s validity as a scientific construct. Thus, g will remain a myth. This is another thing that Gould got right in his book, along with his attack on Morton.
Gould was obviously right about the reification of g.
Hereditarians have been trying to prove the existence of a genetic basis of intelligence for over 100 years. In this time frame, they have used everything from twin, family and adoption studies to tools from the molecular genetics era like GCTA and GWAS. Using heritability estimates, behavior geneticists claim that since intelligence is highly heritable, that there must thusly be a genetic basis to intelligence controlled by many genes of small effect, meaning it’s highly polygenic.
In his outstanding book Misbehaving Science, Panofsky (2014) discusses an attempt funded by the Rockefeller Foundation (RF) at showing a genetic basis to dog intelligence to prove that intelligence had a genetic basis. But it didn’t end up working out for them—in fact, it showed the opposite. The investigation which was funded by the RF showed quite the opposite result that they were looking for—while they did find evidence of some genetic differences between the dog breeds studied, they didn’t find evidence for the existence of a “general factor of intelligence” in the dogs. This issue was explored in Scott and Fuller’s 1965 book Genetics and the Social Behavior of the Dog. These researchers, though, outright failed in their task to discover a “general intelligence” in dogs. Modern-day research also corroborates this notion.
The genetic basis of dog intelligence?
This push to breed a dog that was highly intelligent was funded by the Rockefeller Foundation for ten years at the Jackson Laboratory. Panofsky (2014: 55) explains:
Over the next twenty years many scientists did stints at Jackson Laboratory working on its projects or attending its short courses and training programs. These projects and researchers produced dozens of papers, mostly concerning dogs and mice, that would form much of the empirical base of the emerging field. In 1965 Scott and John Fuller, his research partner, published Genetics and the Social Behavior of the Dog. It was the most important publication to come out of the Jackson Lab program. Scott and Fuller found many genetic differences between dog breeds; they did not find evidence for general intelligence or temperament. Dogs would exhibit different degrees of intelligence or temperamental characteristics depending on the situation. This evidence of interaction led them to question the high heritability of human intelligence—thus undermining a goal of the Rockefeller Foundation sponsors who had hoped to discredit the idea that intelligence was the product of education. Although the behavioral program at Jackson Laboratory declined after this point, it had been the first important base for the new field.
Quite obviously this was the opposite result of what they wanted—dog intelligence was based on the situation and therefore context-dependent.
Scott and Fuller (1965) discuss how they used to call their tests “intelligence tests” but then switched to calling them “performance tests”, “since the animals seemed to solve their problems in many ways other than through pure thought or intellect” (Scott and Fuller 1965: 37), while also writing that “no evidence was found for a general factor of intelligence which would produce good performance on all tests” (1965, 328). They also stated that they found nothing like the general intelligence factor in dogs like that is found in humans (1965: 472) while also stating that it’s a “mistaken notion” to believe in the general intelligence factor (1965: 512). They then conclude, basically, that situationism is valid for dogs, writing that their “general impression is that an individual from any dog breed will perform well in a situation in which he can be highly motivated and for which he has the necessary physical capacities” (1965: 512). Indeed, Scott noted that due to the heritability estimates of dog intelligence Scott came to the conclusion that human heritability estimates “are far too high” (quoted in Paul, 1998: 279). This is something that even Schonemann (1997) noted—and it’s “too high” due to the inflation of heritability due to the false assumptions of twin studies, which lead to the missing heritability crisis. One principle finding was that genetic differences didn’t appear early in development, which were then molded by further experience in the world. Behavior was highly variable between individuals and similar within breeds.
The results were quite unexpected but scientifically exciting. During the very early stages of development there was so little behavior observed that there was little opportunity for genetic differences to be expressed. When the complex patterns of behavior did appear, they did not show pure and uncontaminated effects of heredity. Instead, they were extraordinarily variable within an individual and surprisingly similar between individuals. In short, the evidence supported the conclusion that genetic differences in behavior do not appear all at once early in development, to be modified by later experience, but are themselves developed under the influence of environmental factors and may appear in full flower only relatively late in life. (Scott and Fuller, 1965)
The whole goal of this study by the Jackson Lab was to show that there was a genetic basis to intelligence in dogs and that they therefore could breed a dog that was intelligent and friendly (Paul, 1998). They also noted that there was no breed which was far and above the best at the task in question. Scott and Fuller found that performance on their tests was strongly affected by motivational and emotional factors. They also found that breed differences were strongly influenced by the environment, where two dogs from different breeds became similar when raised together. We know that dogs raised with cats showed more favorable disposition towards them (Fox, 1958; cf Feuerstein and Terkel, 2008, Menchetti et al, 2020). Scott and Fuller (1965: 333) then concluded that:
On the basis of the information we now have, we can conclude that all breeds show about the same average level of performance in problem solving, provided they can be adequately motivated, provided physical differences and handicaps do not affect the tests, and provided interfering emotional reactions such as fear can be eliminated. In short, all the breeds appear quite similar in pure intelligence.
The issue is that by believing that heritability shows anything about how “genetic” a trait is, one then inters that there has to be a genetic basis to the trait in question, and that the higher the estimate, the more strongly controlled by genes the trait in question is. However, we now know this claim to be false (Moore and Shenk, 2016). More to the point, the simple fact that IQ shows higher heritability than traits in the animal kingdom should have given behavioral geneticists pause. Nonetheless, it is interesting that this study that was carried out in the 1940s showed a negative result in the quest to show a genetic basis to intelligence using dogs, since dogs and humans quite obviously are different. Panofsky (2014: 65) also framed these results with that of rats that were selectively bred to be “smart” and “dumb”:
Further, many animal studies showed that strain differences in behavior were not independent of environment. R. M. Cooper and J. P. Zubek’s study of rats selectively bred to be “dull” and “bright” in maze-running ability showed dramatic differences between the strains in the “normal” environment. But in the “enriched” and especially the “restricted” developmental environments, both strains’ performance were quite similar. Scott and Fuller made a similar finding in their comparative study of dog breeds: “The behavior traits do not appear to be preorganized by heredity. Rather a dog inherits a number of abilities which can be organized in different ways to meet different situations.” Thus even creatures that had been explicitly engineered to embody racial superiority and inferiority could not demonstrate the idea in any simple way
Psychologist Robert Tryon (1940) devised a series of mazes, ran rats through them and then selected rats that learned quicker and slower (Innis, 1992). These differences then seemed to persists across these rat generations. Then Searle (1949) discovered that the so-called “dumb” rats were merely afraid of the mechanical noise of the maze, showing that Tryon selected for—unknowingly—emotional capacity. Marlowitz (1969) then concluded “that the labels “maze-bright” and “maze-dull” are inexplicit and inappropriate for use with these strains.”
Dogs and human races are sometimes said to be similar, in which a dog breed can be likened to a human race (see Norton et al, 2019). However, dog breeds are the result of conscious human selection for certain traits which then creates the breed. So while Scott and Fuller did find evidence for a good amount of genetic differences between the breeds they studied, they did not find any evidence of a genetic basis of intelligence or temperament. This is also good evidence for the claim that a trait can be heritable (have high heritability) but have no genetic basis. Moreover, we know that high levels of training improve dog’s problem solving ability (Marshall-Pescini et al, 2008, 2016). Further, perceived differences in trainability are due to physical capabilities and not cognitive ones (Helton, 2008). And in Labrador Retrievers, post-play training also improved training performance (Affenzeller, Palme, and Zulch, 2017; Affenzeller, 2020). Dogs’ body language during operant conditioning was also related to their success rate in learning (Hasegawa, Ohtani, and Ohta, 2014). We also know that dogs performed tasks better and faster the more experience they had with them, not being able to solve the task before seeing it demonstrated by the human administering the task (Albuquerque et al, 2021). Gnanadesikan et al (2020) state that cognitive phenotypes seem to vary by breed, and that these phenotypes have strong potential to be artificially selected, but we have seen that this is an error. Morrill et al (2022) found no evidence that the behavioral tendencies of certain breeds reflected intentional selection by humans but could not discount the possibility.
Conclusion
Dog breeds have been used by hereditarians for decades as a model for that of intelligence differences between human races. The analogy that dog breeds and human races are also similar has been used to show that there is a genetic basis for human race, and that human races are thusly a biological reality. (Note that I am a pluralist about race.) But we have seen that in the 40s the study which was undertaken to prove a hereditary basis to dog intelligence and then liken it to human intelligence quite obviously failed. This then led one of the authors to conclude—correctly—that human heritability estimates are inflated (which has led to the missing heritability problem of the 2000s).
Upon studying the dogs in their study, they found that there was no general factor of intelligence in these dogs, and that the situation was paramount in how the dog would perform on the task in question. This then led Scott to conclude that human heritability estimates are too high, a conclusion echoed by modern day researchers like Schonemann. The issue is, if dogs with their numerous breeds and genetic variation defy a single general factor, what would that mean for humans? This is just more evidence that “general intelligence” is a mere myth, a statistical abstraction. There was also no evidence for a general temperament, since breeds that were scared in one situation were confident in another (showing yet again that situationism held here). The failure of the study carried out by the RF then led to the questioning of the high heritability of human intelligence (IQ), which wasn’t forgotten as the decades progressed. Nonetheless, this study casted doubt on the claim that intelligence had a genetic basis.
Why, though, would a study of dogs be informative here? Well, the goal was to show that intelligence in dogs had a hereditary component and that thusly a kind of designer dog could be created that was friendly and intelligent, and this could then be likened to humans. But when the results were the opposite of what they desired, the project was quickly abandoned. If only modern-day behavioral geneticists would get the memo that heritability isn’t useful for what they want it to be useful for (Moore and Shenk, 2016)
What I term “the Berka-Nash measurement objection” is—I think—one of the most powerful arguments against not only the concept of IQ “measurement” but against psychological “measurement” as a whole—this also compliments my irreducibility of the mental arguments. (Although there are of course contemporary authors who argue that IQ—and other psychological traits—are immeasurable, the Berka-Nash measurement objection I think touches the heart of the matter extremely well). The argument that Karel Berka (1983) mounted in Measurement: Its Concepts, Theories, and Problems is a masterclass in defining what “measurement” means and the rules needed for what designates X is a true measure and Y as a true measurement device. Then Roy Nash (1990) in Intelligence and Realism: A Materialist Critique of IQ brought Berka’s critique of extraphysical (mental) measurement to a broader audience, simplifying some of the concepts that Berka discussed and likened it to the IQ debate, arguing that there is no true property that IQ tests measure, therefore IQ tests aren’t a measurement device and IQ isn’t a measure.
I have found only one response to this critique of mental measurement by hereditarians—that of Brand et al (2003). Brand et al think they have shown that Berka’s and Nash’s critique of mental measurement is consistent with IQ, and that IQ can be seen as a form of “quasi-quantification.” But their response misses the mark. In this article I will argue how it misses the mark and it’s for these reasons: (1) they didn’t articulate the specified measured object, object of measurement and measurement unit for IQ and they overlooked the challenges that Berka discussed about mental measurement; (2) they ignored the lack of objectively reproducible measurement units; (3) they misinterpreted what Berka meant by “quasi-quantification” and then likening it to IQ; and (4) they failed to engage with Berka’s call for precision and reliability.
IQ, therefore, isn’t a measurable construct since there is no property being measured by IQ tests.
Brand et al’s arguments against Berka
The response from Brand et al to Berka’s critiques of mental measurement in the context of IQ raises critical concerns of Berka’s overarching analysis on measurement. So examining their arguments against Berka reveals a few shortcomings which undermine the central tenets of Berka’s thesis of measurement. From failing to articulate the fundamental components of IQ measurement, to overlooking the broader philosophical issues that Berka addressed, Brand et al’s response falls short in providing a comprehensive rebuttal to Berka’s thesis, and in actuality—despite the claims from Brand et al—Berka’s argument against mental measurement doesn’t lend credence to IQ measurement—it effectively destroys it, upon a close, careful reading of Berka (and then Nash).
(1) The lack of articulation of a specified measured object, object of measurement and measurement unit for IQ
“If the necessary preconditions under which the object of measurement can be analyzed on a higher level of qualitative aspects are not satisfied, empirical variables must be related to more concrete equivalence classes of the measured objects. As a rule, we encounter this situation at the very onset of measurement, when it is not yet fully apparent to what sort of objects the property we are searching for refers, when its scope is not precisely delineated, or if we measure it under new conditions which are not entirely clarified operationally and theoretically. This situation is therefore mainly characteristic of the various cases of extra-physical measurement, when it is often not apparent what magnitude is, in fact, measured, or whether that which is measured really corresponds to our projected goals.” (Berka, 1983: 51)
“Both specific postulates of the theory of extraphysical measurement, scaling and testing – the postulates of validity and reliability – are then linked to the thematic area of the meaningfulness of measurement and, to a considerable extent, to the problem area of precision and repeatability. Both these postulates are set forth particularly because the methodologists of extra-physical measurement are very well aware that, unlike in physical measurement, it is here often not at all clear which properties are the actual object of measurement, more precisely, the object of scaling or counting, and what conclusions can be meaningfully derived from the numerical data concerning the assumed subject matter of investigation. Since the formulation, interpretation, and application of these requirements is a subject of very vivid discussion, which so far has not reached any satisfactory and more or less congruent conclusions, in our exposition we shall limit ourselves merely to the most fundamental characteristics of these postulates.” (Berka, 1983: 202-203)
“At any rate, the fact that, in the case of extraphysical measurement, we do not have at our disposal an objectively reproducible and significantly interpretable measurement unit, is the most convincing argument against the conventionalist view of a measurement, as well as against the anti-ontological position of operationalism, instrumentalism, and neopositivism.” (Berka, 1983: 211)
One glaring flaw—and I think it is the biggest—in Brand et al’s response is their failure to articulate the specified measured object, object of measurement and measurement unit for IQ. Berka’s insistence on precision in measurement requires a detailed conception of what IQ tests aim to measure—we know this is “IQ” or “intelligence” or “g“, but they then of course would have run into how to articulate and define it in a physical way. Berka emphasized that the concept of measurement demands precision in defining what is being measured (the specified measured object), the entity being measured (the object of measurement), and the unit applied for measurement (the measurement unit). Thus, for IQ to be a valid measure and for IQ tests to be a valid measurement device, it is crucial to elucidate exactly what the tests measure the nature of the mental attribute which is supposedly under scrutiny, and the standardized unit of measurement.
Berka’s insistence on precision aligns with a fundamental aspect of scientific measurement—the need for a well defined and standardized procedure to quantify a particular property. This is evidence for physical measurement, like the length of an object being measured using meters. But when transitioning to the mental, the challenge lies in actually measuring something that lacks a unit of measurement. (And as Richard Haier (2014) even admits, there is no measurement unit for IQ like inches, liters or grams.) So without a clear and standardized unit for mental properties, claims of measurement are therefore suspect—and impossible. Moreover, by sidestepping this crucial aspect of what Berka was getting at, their argument remains vulnerable to Berka’s foundational challenge regarding the essence of what is being measured along with how it is quantified.
Furthermore, Brand et al failed to grapple with what Berka wrote on mental measurement. Brand et al’s response would have been more robust if it had engaged with Berka’s exploration of the inherent intracacies and nuances involved in establishing a clear object of measurement for IQ, and any mental attributes.
Measurement units have to be a standardized and universally applicable quantity or physical property while allowing for standardized comparisons across different measures. And none exists for IQ, nor any other psychological trait. So we can safely argue that psychometrics isn’t measurement, even without touching contemporary arguments against mental measurement.
(2) Ignoring the lack of objectively reproducible measurement units
A crucial aspect of Berka’s critique involves the absence of objectively reproducible measurement units in the realm of measurement. Berka therefore contended that in the absence of such a standardized unit of measurement, the foundations for a robust enterprise of measurement are compromised. This is yet another thing that Brand et al overlooked in their response.
Brand et al’s response lacks a comprehensive examination of how the absence of objectively reproducible measurement units in mental measurement undermines the claim that IQ is a measure. They do not engage with Berka’s concern that the lack of such units in mental measurement actually hinders the claim that IQ is a measure. So the lack of attention to the absence of objectively reproducible measurement units in mental measurement actually weakens, and I think destroys, Brand et al’s response. They should have explored the ramifications of a so-called measure without a measurement unit. So this then brings me to their claims that IQ is a form of “quasi-quantification.”
(3) Misinterpretation of “quasi-quantification” and its application to IQ
Brand et al hinge their defense of IQ on Berka’s concept of “quasi-quantification”, which they misinterpret. Berka uses “quasi-quantification” to describe situations where the properties being measured lack the clear objectivity and standardization found in actual physical measurements. But Brand et al seem to interpret “quasi-quantification” as a justification for considering IQ as a valid form of measurement.
Brand et al’s misunderstanding of Berka’s conception of “quasi-quantification” is evidence in their attempt to equate it with a validation of IQ as a form of measurement. Berka was not endorsing it as a fully-fledged form of measurement, but he highlighted the limitations and distinctiveness compared to traditional quantification and measurement. Berka distinguishes between quantification, pseudo-quantification, and quasi-quantification. Berka explicitly states that numbering and scaling—in contrast to counting and measurement—cannot be regarded as kinds of quantification. (Note that “counting” in this framework isn’t a variety of measurement, since measurement is much more than enumeration, and counted elements in a set aren’t magnitudes.) Brand et al fail to grasp this nuanced difference, while mischaracterizing quasi-quantification as a blanket acceptance of IQ as a form of measurement.
Berka’s reservations of quasi-quantification are rooted in the challenges and complexities associated with mental properties, acknowledging that they fall short of the clear objectivity found in actual physical measurements. So Brand et al’s interpretation overlooks this critical aspect, which leads them to erroneously argue that accepting IQ as quasi-quantification is sufficient to justify its status as measurement.
Brand et al’s arguments against Nash
Nash’s book, on the other hand, is a much more accessible and pointed attack on the concept of IQ and it’s so-called “measurement.” He spends the book talking about the beginnings of IQ testing to the Flynn Effect, Berka’s argument and then ends with talking about test bias. IQ doesn’t have a true “0” point (like temperature, which IQ-ists have tried to liken to IQ, and the thermometer to IQ tests—there is no lawful property like the relation between mercury and temperature in a thermometer and IQ and intelligence, so again the hereditarian claim fails). But most importantly, Nash made the claim that there is actually no property to be measured by IQ tests—what did he mean by this?
Nash of course doesn’t deny that IQ tests rank individuals on their performance. So the claim that IQ is a metric property is already assumed in IQ theory. But the very fact that people are ranked doesn’t justify the claim that people are then ranked according to a property revealed by their performance (Nash, 1990: 134). Moreover, if intelligence/”IQ” were truly quantifiable, then the difference between 80 and 90 IQ and 110 and 120 IQ would represent the same cognitive difference between both groups of scores. But this isn’t the case.
Nash is a skeptic of the claim that IQ tests measure some property. (As I am.) So he challenges the idea that there is a distinct and quantifiable property that can be objectively measured by IQ tests (the construct “intelligence”). Nash also questions whether intelligence possesses the characteristics necessary for measurement—like a well-defined object of measurement and measurement unit. Nash successfully argued that intelligence cannot be legitimately expressed in a metric concept, since there is no true measurement property. But Brand et al do nothing to attack the arguments of Berka and Nash and they do not at all articulate the specified measured object, object of measurement and measurement unit for IQ, which was the heart of the critique. Furthermore, a precise articulation of the specified measured object when it comes to the metrication of X (any psychological trait) is necessary for the claim that X is a measure (along with articulating the object of measurement and measurement unit). But Brand et al did not address this in their response to Nash, which I think is very telling.
Brand et al do rightly note Nash’s key points, but they fall far, far from the mark in effectively mounting a sound argument against his view. Nash argues that IQ test results can only, at best, be used for ordinal comparisons of “less than, equal to, greater than” (which is also what Michell, 2022 argues, and the concludes the same as Nash). This is of course true, since people take a test and their performance is based on the type of culture they are exposed to (their cultural and psychological tools). Brand et al failed to acknowledge this and grapple with its full implications. But the issue is, Brand et al did not grapple at all with this:
The psychometric literature is full of plaintive appeals that despite all the theoretical difficulties IQ tests must measure something, but we have seen that this is an error. No precise specification of the measured object, no object of measurement, and no measurement unit, means that the necessary conditions for metrication do not exist. (Nash, 1990: 145)
All in all, a fair reading of both Berka and Nash will show that Brand et al slithered away from doing any actual philosophizing on the phenomena that Berka and Nash discussed. And, therefore, that their “response” is anything but.
Conclusion
Berka’s and Nash’s arguments against mental measurement/IQ show the insurmountable challenges that the peddlers of mental measurement have to contend with. Berka emphasized the necessity of clearly defining the measured object, object of measurement and measurement unit for a genuine quantitative measurement—these are the necessary conditions for metrication, and they are nonexistent for IQ. Nash then extended this critique to IQ testing, then concluding that the lack of a measurable property undermines the claim that IQ is a true measurement.
Brand et al’s response, on the other hand, was pitiful. They attempted to reconcile Berka’s concept of “quasi-quantification” with IQ measurement. Despite seemingly having some familiarity with both Berka’s and Nash’s arguments, they did not articulate the specified measured object, object of measurement and measurement unit for IQ. If Berka really did agree that IQ is “quasi-quantification”, then why did Brand et al not articulate what needs to be articulated?
When discussing Nash, Brand et al failed to address Nash’s claim that IQ can only IQ can only allow for ordinal comparisons. Nash emphasized numerous times in his book that an absence of a true measurement property challenges the claim that IQ can be measured. Thus, again, Brand et al’s response did not successfully and effectively engage with Nash’s key points and his overall argument against the possibility of intelligence/IQ (and mental measurement as a whole).
Berka’s and Nash’s critiques highlight the difficulties of treating intelligence (and psychological traits as a whole) as quantifiable properties. Brand et al did not adequately address and consider the issues I brought up above, and they outright tried to weasle their way into having Berka “agree” with them (on quasi-quantification). So they didn’t provide any effective counterargument against them, nor did they do the simplest thing they could have done—which was articulate the specified measured object, object of measurement and measurement unit for IQ. The very fact that there is no true “0” point is devestating for claims that IQ is a measure. I’ve been told on more than one occasion that “IQ is a unit-less measure”—but they doesn’t make sense. That’s just trying to cover for the fact that there is no measurement unit at all, and consequently, no specified measured object and object of measurement.
For these reasons, the Berka-Nash measurement objection remains untouched and the questions raised by them remain unanswered. (It’s simple: IQ-ists just need to admit that they can’t answer the challenge and that psychological traits aren’t measurable like physical traits. But then their whole worldview would crumble.) Maybe we’ll wait another 40 and 30 years for a response to the Berka-Nash measurement objection, and hopefully it will at least try harder than Brand et al did in their failure to address these conceptual issues raised by Berka and Nash.
Jensen’s default hypothesis proposes that individual and group differences in IQ are primarily explained genetic factors. But Fagan and Holland (2002) question this hypothesis. For if differences in experience lead to differences in knowledge, and differences in knowledge lead to differences in IQ scores, then Jensen’s assumption that blacks and whites have the same opportunity to learn the content is questionable, and I’d think it false. It is obvious that there are differences in opportunity to acquire knowledge which would then lead to differences in IQ scores. I will argue that Jensen’s default hypothesis is false due to this very fact.
In fact, there is no good reason to accept Jensen’s default hypothesis and the assumptions that come with it. Of course different cultural groups are exposed to different kinds of knowledge, so this—and not genes—would explain why different groups score differently on IQ tests (tests of knowledge, even so-called culture-fair tests are biased; Richardson, 2002). I will argue that we need to reject Jensen’s default hypothesis on these grounds, because it is clear that groups aren’t exposed to the same kinds of knowledge, and so, Jensen’s assumption is false.
Jensen’s default hypothesis is false due to the nature of knowledge acquisition
Jensen (1998: 444) (cf Rushton and Jensen, 2005: 335) claimed that what he called the “default hypothesis” should be the null that needs to be disproved. He also claimed that individual and group differences are “composed of the same stuff“, in that they are “controlled by differences in allele frequencies” and that these differences in allele frequencies also exist for all “heritable” characters, and that we would find such differences within populations too. So if the default hypothesis is true, then it would suggest that differences in IQ between blacks and whites are primarily attributed to the same genetic and environmental influences that account for individual differences within each group. So this implies that genetic and environmental variances that contribute to IQ are therefore the same for blacks and whites, which supposedly supports the idea that group differences are a reflection of individual differences within each group.
But if the default hypothesis were false, then it would challenge the assumption that genetic and environmental influences in IQ between blacks and whites are proportionally the same as seen in each group. Thus, this allows us to talk about other causes of variance in IQ between blacks and whites—factors other than what is accounted for by the default hypothesis—like socioeconomic, cultural, and historical influences that play a more substantial role in explaining IQ differences between blacks and whites.
In the present study, we ensured that Blacks and Whites were given equal opportunity to learn the meanings of relatively novel words and we conducted tests to determine how much knowledge had been acquired. If, as Jensen suggests, the differences in IQ between Blacks and Whites are due to differences in intellectual ability per se, then knowledge for word meanings learned under exactly the same conditions should differ between Blacks and Whites. In contrast to Jensen, we assume that an IQ score depends on information provided to the learner as well as on intellectual ability. Thus, if differences in IQ between Blacks and Whites are due to unequal opportunity for exposure to information, rather than to differences in intellectual ability, no differences in knowledge should obtain between Blacks and Whites given equal opportunity to learn new information. Moreover, if equal training produces equal knowledge across racial groups, than the search for racial differences in IQ should not be aimed at the genetic bases of IQ but at differences in the information to which people from different racial groups have been exposed.
There are reasons to think that Jensen’s default hypothesis is false. For instance, since IQ tests are culture-bound—that is, culturally biased—then they are biased against a group so they therefore are biased for a group. Thus, this introduces a confounding factor which challenges the assumption of equal genetic and environmental influences between blacks and whites. And since we know that cultural differences in the acquisition of information and knowledge vary by race, then what explains the black-white IQ gap is exposure to information (Fagan and Holland, 2002, 2007).
The Default Hypothesis of Jensen (1998) assumes that differences in IQ between races are the result of the same environmental and genetic factors, in the same ratio, that underlie individual differences in intelligence test performance among the members of each racial group. If Jensen is correct, higher and lower IQ individuals within each racial group in the present series of experiments should differ in the same manner as had the African-Americans and the Whites. That is, in our initial experiment, individuals within a racial group who differed in word knowledge should not differ in recognition memory. In the second, third, and fourth experiments individuals within a racial group who differed in knowledge based on specific information should not differ in knowledge based on general information. The present results are not consistent with the default hypothesis.(Fagan and Holland, 2007: 326)
Historical and systematic inequalities could also lead to differences in knowledge acquisition. The existence of cultural biases in educational systems and materials can create disparities in knowledge acquisition. Thus, if IQ tests—which reflect this bias—are culture-bound, it also questions the assumption that the same genetic and environmental factors account for IQ differences between blacks and whites. The default hypothesis assumes that genetic and environmental influences are essentially the same for all groups. But SES/class differences significantly affect knowledge acquisition, so if challenges the default hypothesis.
For years I have been saying, what if all humans have the same potential but it just crystallizes differently due to differences in knowledge acquisition/exposure and motivation? There is a new study that shows that although some children appeared to learn faster than others, they merely had a head start in learning. So it seems that students have the same ability to learn and that so-called “high achievers” had a head start in learning (Koedinger et al, 2023). They found that students vary significantly in their initial knowledge. So although the students had different starting points (which showed the illusion of “natural” talents), they had more of a knowledge base but all of the students had a similar rate of learning. They also state that “Recent research providing human tutoring to increase student motivation to engage in difficult deliberate practice opportunities suggests promise in reducing achievement gaps by reducing opportunity gaps (63, 64).”
So we know that different experiences lead to differences in knowledge (it’s type and content), and we also know that racial groups for example have different experiences, of course, in virtue of their being different social groups. So these different experiences lead to differences in knowledge which are then reflected in the group IQ score. This, then, leads to one raising questions about the truth of Jensen’s default hypothesis described above. Thus, if individuals from different racial groups have unequal opportunities to be exposed to information, then Jensen’s default hypothesis is questionable (and I’d say it’s false).
Intelligence/knowledge crystalization is a dynamic process shaped by extensive practice and consistent learning opportunities. So the journey towards expertise involves iterative refinement with each practice opportunity contribute to the crystallization of knowledge. So if intelligence/knowledge crystallizes through extensive practice, and if students don’t show substantial differences in their rates of learning, then it follows that the crystalization of intelligence/knowledge is more reliant on the frequency and quality of learning opportunities than on inherent differences in individual learning rates. It’s clear that my position enjoys some substantial support. “It’s completely possible that we all have the same potential but it crystallizes differently based on motivation and experience.” The Fagan and Holland papers show exactly that in the context of the black-white IQ gap, showing that Jensen’s default hypothesis is false.
I recently proposed a non-IQ-ist definition of intelligence where I said:
So a comprehensive definition of intelligence in my view—informed by Richardson and Vygotsky—is that of a socially embedded cognitive capacity—characterized by intentionality—that encompasses diverse abilities and is continually shaped by an individual’s cultural and social interactions.
So I think that IQ is the same way. It is obvious that IQ tests are culture-bound and tests of a certain kind of knowledge (middle-class knowledge). So we need to understand how social and cultural factors shape opportunities for exposure to information. And per my definition, the idea that intelligence is socially embedded aligns with the notion that varying sociocultural contexts do influence the development of knowledge and cognitive abilities. We also know that summer vacation increases educational inequality, and that IQ decreases during the summer months. This is due to the nature of IQ and achievement tests—they’re different versions of the same test. So higher class children will return to school with an advantage over lower class children. This is yet more evidence in how knowledge exposure and acquisition can affect test scores and motivation, and how such differences crystallize, even though we all have the same potential (for learning ability).
Conclusion
So intelligence is a dynamic cognitive capacity characterized by intentionality, cultural context and social interactions. It isn’t a fixed trait as IQ-ists would like you to believe but it evolves over time due to the types of knowledge one is exposed to. Knowledge acquisition occurs through repeated exposure to information and intentional learning. This, then, challenges Jensen’s default hypothesis which attributes the black-white IQ gap primarily to genetics.Since diverse experiences lead to varied knowledge, and there is a certain type of knowledge in IQ tests, individuals with a broad range of life experiences varying performance on these tests which then reflect the types of knowledge one is exposed to during the course of their lives. So knowing what we know about blacks and whites being different cultural groups, and what we know about different cultures having different knowledge bases, then we can rightly state that disparities in IQ scores between blacks and whites are suggested to be due to environmental factors.
Unequal exposure to information creates divergent knowledge bases which then influence the score on the test of knowledge (IQ test). And since we now know that despite initial differences in initial performance that students have a surprising regularity in learning rates, this suggests that once exposed to information, the rate of knowledge acquisition remains consistent across individuals which then challenges the assumption of innate disparities in learning abilities. So the sociocultural context becomes pivotal in shaping the kinds of knowledge that people are exposed to. Cultural tools environmental factors and social interactions contribute to diverse cognitive abilities and knowledge domains which then emphasize the contextual nature of not only intelligence but performance in IQ tests. So what this shows is that test scores are reflective of the kinds of experience the testee was exposed to. So disparities in test scores therefore indicate differences in learning opportunities and cultural contexts
So a conclusive rejection of Jensen’s default hypothesis asserts that the black-white IQ gap is due to exposure to different types of knowledge. Thus, what explains disparities in not only blacks and whites but between groups is unequal opportunities to exposure of information—most importantly the type of information found on IQ tests. My sociocultural theory of knowledge acquisition and crystalization offers a compelling counter to hereditarian perspectives, and asserts that diverse experiences and intentionality learning efforts contribute to cognitive development. The claim that all groups or individuals are exposed to similar types of knowledge as Jensen assumes is false. By virtue of being different groups, they are exposed to different knowledge bases. Since this is true, and IQ tests are culture-bound and tests of a certain kind of knowledge, then it follows that what explains group differences in IQ and knowledge would therefore be differences in exposure to information.
In the realm of educational assessment and psychometrics, a distinction between IQ and achievement tests needs to be upheld. It is claimed that IQ is a measure of one’s potential learning ability, while achievement tests show what one has actually learned. However, this distinction is not strongly supported in my reading of this literature. IQ and achievement tests are merely different versions of the same evaluative tool. This is what I will argue in this article: That IQ and achievement tests are different versions of the same test, and so any attempt to “validate” IQ tests based not only on other IQ tests, achievement tests and job performance is circular, I will argue that, of course, the goal of psychometrics in measuring the mind is impossible. The hereditarian argument, when it comes to defending their concept and the claim that they are measuring some unitary and hypothetical variable, then, fails. At best, these tests show one’s distance from the middle class, since that’s the where most of the items on the test derive from. Thus, IQ and achievement tests are different versions of the same test and so, they merely show one’s “distance” from a certain kind of class-specific knowledge (Richardson, 2012), due to the cultural and psychologicaltools one must possess to score well on these tests (Richardson, 2002).
Circular IQ-ist arguments
IQ-ists have been using IQ tests since they were brought to America by Henry Goddard in 1913. But one major issue (one they still haven’t solved—and quite honestly never will) was that they didn’t have any way to ensure that the test was construct valid. So this is why, in 1923, Boring stated that “intelligence is what intelligence tests test“, while Jensen (1972: 76) said “intelligence, by definition, is what intelligence tests measure.” However, such statements are circular and they are circular because they don’t provide real evidence or explanation.
Boring’s claim that “intelligence is what intelligence tests test” is circular since it defines intelligence based on the outcome of “intelligence tests.” So if you ask “What is intelligence“, and I say “It’s what intelligence tests measure“, I haven’t actually provided a meaningful definition of intelligence. The claim merely rests on the assumption that “intelligence tests” measure intelligence, not telling us what it actually is.
Jensen’s (1976) claim that “intelligence, by definition, is what intelligence tests measure” is circular for similar reasons to Boring’s since it also defines intelligence by referring to “intelligence tests” and at the same time assumes that intelligence tests are accurately measuring intelligence. Neither claim actually provides an independent understanding of what intelligence is, it merely ties the concept of “intelligence” back to its “measurement” (by IQ tests). Jensen’s Spearman’s hypothesis on the nature of black-white differences has also been criticized as circular (Wilson, 1985). Not only was Jensen (and by extension Spearman) guilty of circular reasoning, so too was Sternberg (Schlinger, 2003). Such a circular claim was also made by Van der Mass, Kan, and Borsboom (2014).
But Jensen seemed to have changed his view, since in his 1998 book The g Factor, he argues that we should dispense with the term “intelligence”, but curiously that we should still study the g factor and assume identity between IQ and g… (Jensen made many more logical errors in his defense of “general intelligence”, like saying not to reify intelligence on one page and then a few pages later reifying it.) Circular arguments have been identified in not only Jensen’s writings Spearman’s hypothesis, but also in using construct validity to validate a measure (Gordon, Schonemann; Guttman, 1992: 192).
The same circularity can be seen when discussions of the correlation between IQ and achievement tests is brought up. “These two tests correlate so they’re measuring the same thing”, is an example one may come across. But the error here is assuming that mental measurement is possible and that IQ and achievement tests are independent of each other. However, IQ and achievement tests are different versions of the same test. This is an example of circular validation, which occurs when a test’s “validity” is established by the test itself, leading to a self-reinforcing loop.
IQ tests are often validated with other older editions of the test. For example, the newer version of the S-B would be “validated” against the older version of the test that the newer version was created to replace (Howe, 1997: 18; Richardson, 2002: 301), which not only leads to circular “validation”, but would also lead to the same assumptions from the older test constructors (like Terman) which would still then be alive in the test itself (since Terman assumed men and women should be equal in IQ and so this assumption is still there today). IQ tests are also often “validated” by comparing IQ test results to outcomes like job performance and academic performance. Richardson and Norgate (2015) have a critical review of the correlation between IQ and job performance, arguing that it’s inflated by “corrections”, while Sackett et al, 2023 show “a mean observed validity of .16, and a mean corrected for unreliability in the criterion and for range restriction of .23. Using this value drops cognitive ability’s rank among the set of predictors examined from 5th to 12th” for the correlation between “general cognitive ability” and job performance.
But this could lead to circular validation, in that if a high IQ is used as a predictor of success in school or work, then success in school or work would be used as evidence in validating the IQ test, which would then lead to a circular argument. The test’s validity is being supported by the outcome that it’s supposed to predict.
Achievement tests are destined to see what one had learned or achieved regarding a certain kind of subject matter. Achievement tests are often validated by correlating test scores with grades or other kinds of academic achievement (which would also be circular). But if high achievement test scores are used to validate the test and those scores are also used as evidence of academic achievement, then that would be circular. Achievement tests are “validated” on their relationship between IQ tests and grades. Heckman and Kautz (2013) note that “achievement tests are often validated using other standardized achievement tests or other measures of cognitive ability—surely a circular practice” and “Validating one measure of cognitive ability using other measures of cognitive ability is circular.” But it should also be noted that the correlation between college grades and job performance 6 or more years after college is only .05 (Armstrong, 2011).
Now what about the claim that IQ tests and achievement tests correlate so they measure the same thing? Richardson (2017) addressed this issue:
For example, IQ tests are so constructed as to predict school performance by testing for specific knowledge or text‐like rules—like those learned in school. But then, a circularity of logic makes the case that a correlation between IQ and school performance proves test validity. From the very way in which the tests are assembled, however, this is inevitable. Such circularity is also reflected in correlations between IQ and adult occupational levels, income, wealth, and so on. As education largely determines the entry level to the job market, correlations between IQ and occupation are, again, at least partly, self‐fulfilling
The circularity inherent in likening IQ and achievement tests has also been noted by Nash (1990). There is no distinction between IQ and achievement tests since there is no theory or definition of intelligence and how, then, this theory and definition would be likened to answering questions correctly on an IQ test.
But how, to put first things first, is the term ‘cognitive ability’ defined? If it is a hypothetical ability required to do well at school then an ability so theorised could be measured by an ordinary scholastic attainment test. IQ measures are the best measures of IQ we have because IQ is defined as ‘general cognitive ability’. Actually, as we have seen, IQ theory is compelled to maintain that IQ tests measure ‘cognitive ability’ by fiat, and it therefore follows that it is tautologous to claim that IQ tests are the best measures of IQ that we have. Unless IQ theory can protect the distinction it makes between IQ/ability tests and attainment/ achievement tests its argument is revealed as circular. IQ measures are the best measures of IQ we have because IQ is defined as ‘general cognitive ability’: IQ tests are the only measures of IQ.
The fact of the matter is, IQ “predicts” (is correlated with) school achievement since they are different versions of the same test (Schwartz, 1975; Beaujean et al, 2018). Since the main purpose of IQ tests in the modern day is to “predict” achievement (Kaufman et al, 2012), then if we correctly identify IQ and achievement tests as different versions of the same test, then we can rightly state that the “prediction” is itself a form of circular reasoning. What is the distinction between “intelligence” tests and achievement tests? They both have similar items on them, which is why they correlate so highly with each other. This, therefore, makes the comparison of the two in an attempt to “validate” one or the other circular.
I can now argue that the distinction between IQ and achievement tests is nonexistent. If IQ and achievement tests are different versions of the same test, then they share the same domain of assessing knowledge and skills. IQ and achievement tests contain similar informational content on them, and so they can both be considered knowledge tests—class-specific knowledge. IQ and achievement tests share the same domain of assessing knowledge and skills. Therefore, IQ and achievement tests are different versions of the same test. Put simply, if IQ and achievement tests are different versions of the same test, then they will have similar item content, and they do so we can correctly argue that they are different versions of the same test.
Moreover, even constructing tests has been criticized as circular:
Given the consistent use of teachers’ opinions as a primary criterion for validity of the Binet and Wechsler tests, it seems odd to claim then that such tests provide “objective alternatives to the subjective judgments of teachers and employers.” If the tests’ primary claim to predictive validity is that their results have strong correlations with academic success, one wonders how an objective test can predict performance in an acknowledged subjective environment? No one seems willing to acknowledge the circular and tortuous reasoning behind the development of tests that rely on the subjective judgments of secondary teachers in order to develop an assessment device that claims independence of those judgments so as to then be able to claim that it can objectively assess a student’s ability to gain the approval of subjective judgments of college professors. (And remember, these tests were used to validate the next generation of tests and those tests validated the following generation and so forth on down to the tests that are being given today.) Anastasi (1985) comes close to admitting that bias is inherent in the tests when he confesses the tests only measure what many anthropologists would called a culturally bound definition of intelligence. (Thorndike and Lohman, 1990)
Conclusion
It seems clear to me that almost the whole field of psychometrics is plagued with the problem of inferring causes from correlation and using circular arguments in an attempt to justify and validate the claim that IQ tests measure intelligence by using flawed arguments that relate IQ to job and academic performance. However this idea is very confused. Moreover, circular arguments aren’t only restricted to IQ and achievement tests, but also in twin studies (Joseph, 2014; Joseph et al, 2015). IQ and achievement tests merely show what one knows, not their learning potential, since they are general knowledge tests—tests of class-specific knowledge. So even Gottfredson’s “definition” of intelligence fails, since Gottfredson presumes IQ to be a measure of learning ability (nevermind the fact that the “definition” is so narrow and I struggle to think of a valid way to operationalize it to culture-bound tests).
The fact that newer versions of tests already in circulation are “validated” against other older versions of the same test means that the tests are circularly validated. The original test (say the S-B) was never itself validated, and so, they’re just “validating” the newer test on the assumption that the older one was valid. The newer test, in being compared to its predecessor, means that the “validation” is occuring on the other older test which has similar principles, assumptions, and content to the newer test. The issue of content overlap, too, is a problem, since some questions or tasks on the newer test could be identical to questions or tasks on the older test. The point is, both IQ and achievement tests are merely knowledge tests, not tests of a mythical general cognitive ability.
“the study of the brains of human races would lose most of its interest and utility” if variation in size counted for nothing ([Broca] 1861 , p. 141). Quoted in Gould, 1996: 115)
The law is: small brain, little achievement; great brain, great achievement (Ridpath, 1891: 571)
I can’t hope to give as good a review as Gould’s review in Mismeasure of Man on the history of skull measuring, but I will try to show that hereditarians are mistaken in their brain size-IQ correlations and racial differences in brain size as a whole.
The claim that brain size is causal for differences in intelligence is not new. Although over the last few hundred years there has been back and forth arguments on this issue, it is generally believed that there are racial differences in brain size and that this racial difference in brain size accounted for civilizational accomplishments, among other things. Notions from Samuel Morton which seem to have been revived by Rushton in the 80s while formulating his r/K selection theory show that the racism that was incipient in the time period never left us, even after 1964. Rushton and others merely revived the racist thought of those from the 1800s.
Using MRI scans (Rushton and Ankney, 2009) and measuring the physical skull, Rushton asserted that the differences in brain size and quality between races accounted for differences in IQ. Although Rushton was not alone in this belief, this belief on the relationship between brain weight/structure and intelligence goes back centuries. In this article, I will review studies on racial differences in brain size and see if Rushton et al’s conclusions hold on not only brain size being causally efficacious for IQ but there being racial and differences in brain size and the brain size and IQ correlation.
The Morton debate
Morton’s skull collection has received much attention over the years. Gould (1978) first questioned Morton’s results on the ranking of skulls. He argued that when the data was properly reinterpreted, “all races have approximately equal capacities.” The skulls in Morton’s collection were collected from all over. Morton’s men even robbed graves to procure skulls for Morton, even going as far to take “bodies in front of grieving relatives and boiled flesh off fresh corpses” (Fabian, 2010: 178). One man even told Morton that grave robbing gave him a “rascally pleasure” (Fabian, 2010: 15). Indeed, grave robbing seems to have been a way to procure many skulls which were used in these kinds of analyses (Monarrez et al, 2022). Nevertheless, since skulls house brains, the thought is that by measuring skulls then we can ascertain the brain of the individual that the skull belonged to. A larger skull would imply a larger brain. And larger brains, it was said, belong to more “intelligent” people. This assumption was one that was held by the neurologist Broca, and this then justified using brain weight as a measure of intelligence. Though in 1836, an anti-racist Tiedemann (1836) argued that there were no differences in brain size between whites and blacks. (Also see Gould, 1999 for a reanalysis of Tiedemann where he shows C > M > N in brain size, but concludes that the “differencesare tiny and probably of no significancein the judgment of intelligence” (p 10).) It is interesting to note that Tiedemann and Morton worked with pretty much the same data, but they came to different conclusions (Gould, 1999; Mitchell, 2018).
In 1981 Gould published his landmark book The Mismeasure of Man (Gould, 1981/1996). In the book, he argued that bias—sometimes unconscious—pervaded science and that Morton’s work on his skull collection was a great example of this type of bias. Gould (1996: 140) listed many reasons why group (race) differences in brain size have never been demonstrated, citing Tobias (1970):
After all, what can be simpler than weighing a brain?—take it out, and put it on the scale. One set of difficulties refers to problems of measurement itself: at what level is the brain severed from the spinal cord; are the meninges removed or not (meninges are the brain’s covering membranes, and the dura mater, or thick outer covering, weighs 50 to 60 grams); how much time elapsed after death; was the brain preserved in any fluid before weighing and, if so, for how long; at what temperature was the brain preserved after death. Most literature does not specify these factors adequately, and studies made by different scientists usually cannot be compared. Even when we can be sure that the same object has been measured in the same way under the same conditions, a second set of biases intervenes—influences upon brain size with no direct tie to the desired properties of intelligence or racial affiliation: sex, body size, age, nutrition, nonnutritional environment, occupation, and cause of death.
Nevertheless, in Mismeasure, Gould argued that Morton had unconscious bias where he packed the skulls of smaller African skulls more loosely while he would pack the skulls of a smaller Caucasian skull tighter (Gould made this inference due to the disconnect between Morton’s lead shot and seed measurements).
Plausible scenarios are easy to construct. Morton, measuring by seed, picks up a threateningly large black skull, fills it lightly and gives it a few desultory shakes. Next, he takes a distressingly small Caucasian skull, shakes hard, and pushes mightily at the foramen magnum with his thumb. It is easily done, without conscious motivation; expectation is a powerful guide to action. (1996: 97)
…
Yet through all this juggling, I detect no sign of fraud or conscious manipulation. Morton mad e no attempt to cove r his tracks and I must presume that he was unaware he had left them. He explained all his procedure s and published all his raw data. All I can discern is an a priori conviction about racial ranking so powerful that it directed his tabulations along preestablished lines. Yet Morton was widely hailed as the objectivist of his age, the man who would rescue American science from the mire of unsupported speculation. (1996: 101)
But in 2011, a team of researchers tried to argue that Morton did not manipulate data to fit his a priori biases (Lewis et al, 2011). They claimed that “most of Gould’s criticisms are poorly supported or falsified.” They argued that Morton’s measurements were reliable and that Morton really was the scientific objectivist many claimed him to be. Of course, since Gould died in 2002 shortly after publishing his magnum opus The Stuecure of Evolutionary Theory, Gould could not defend his arguments against Morton.
Weisberg (2014) was the first to argue against Lewis et al’s conclusions on Gould. Weisberg argued that while Gould sometimes overstated his case, most of his arguments were sound. Weisberg argued that, contra what Lewis et al claimed, they did not falsify Gould’s claim, which was that the difference between shot and seed measurements showed Morton’s unconscious racial bias. While Weisberg rightly states that Lewis et al uncovered some errors that Gould made, they did not successfully refute two of Gould’s main claims: “that there is evidence that Morton’s seed‐based measurements exhibit racial bias and that there are no significant differences in mean cranial capacities across races in Morton’s collection.”
There is prima facie evidence of racial bias in Morton’s (or his assistant’s) seed‐basedmeasurements. This argument is based on Gould’s accurate analysis of the difference between the seed‐ and shot‐based measurements of the same crania.
Gould is also correct about two other major issues. First, sexual dimorphism is a very suspicious source of bias in Morton’s reported averages. Since Morton identified most of his sample by sex, this is something that he could have investigated and corrected for. Second, when one takes appropriately weighted grand means of Morton’s data, and excludes obvious sources of bias including sexual dimorphism, then the average cranial capacity of the five racial groups in Morton’s collection is very similar. This was probably the point that Gould cared most about. It has been reinforced by my analysis.
[This is Weisberg’s reanalysis]
So Weisberg successfully defended Gould’s claim that there are no general differences in the races as ascribed by Morton and his contemporaries.
In 2015, another defense of Gould was mounted (Kaplan, Pigliucci and Banta, 2015). Like Weisberg before them, they also state that Gould got some things right and some things wrong, but his main arguments weren’t touched by Lewis et al. Kaplan et al stated that while Gould was right to reject Morton’s data, he was wrong to believe that “a more appropriate analysis was available.” They also argue due to the “poor datasetno legitimateinferences to“natural” populations can be drawn.” (See Luchetti, 2022 for a great discussion of Kaplan, Pigliucci and Banta.)
In 2016, Weisberg and Paul (2016) argued that Gould assumed that Morton’s lead shot method was an objective way to ascertain the cranial capacities of skulls. Gould’s argument rested on the differences between lead shot and seed. Then in 2018, Mitchell (2018) published a paper where he discovered lost notes of Morton’s and he argued that Gould was wrong. He, however, admitted that Gould’s strongest argument was untouched—the “measurement issue” (Weisberg and Paul, 2016) was Gould’s strongest argument, deemed “perceptive” by Mitchell. In any case, Mitchell showed that the case of Morton isn’t one of an objective scientist looking to explain the world sans subjective bias—Morton’s a priori biases were strong and strongly influenced his thinking.
Lastly, ironically Rushton used Morton’s data from Gould’s (1978) critique, but didn’t seem to understand why Gould wrote the paper, nor why Morton’s methodology was highly suspect. Rushton basically took the unweighted average for “Ancient Caucasian” skulls, and the sex/age of the skulls weren’t known. He also—coincidentally I’m sure—increased the “Mongoloid skull” size from 85 to 85.5cc (Gould’s table had it as 85cc). Amazingly—and totally coincidentally, I’m sure—Rushton miscited Gould’s table and basically combined Morton’s and Gould’s data, increased the skull size slightly of “Mongoloids” and used the unweighted average of “Ancient Caucasian” skulls (Cain and Vanderwolf, 1990). How honest of Rushton. It’s ironic how people say that Gould lied about Morton’s data and that Gould was a fraud, when in all actuality, Rushton was the real fraud, never recanting on his r/K theory, and now we can see that Rushton actually miscited and combined Gould’s and Morton’s results and made assumptions without valid justification.
The discussion of bias in science is an interesting one. Since science is a social endeavor, there necessarily will be bias inherent in it, especially when studying humans and discussing the causes of certain peculiarities. I would say that Gould was right about Morton and while Gould did make a few mistakes, his main argument against Morton was untouched.
Skull measuring after Morton
The inferiority of blacks and other non-white races has been asserted ever since the European age of discovery. While there were of course 2 camps at the time—one which argued that blacks were not inferior in intelligence and another that argued they were—the claim that blacks are inferior in intelligence was, and still is, ubiquitous. They argued that smaller heads meant that one was less intelligent, and if groups had smaller heads then they too were less intelligent than groups that had smaller heads. This then was used to argue that blacks hadn’t achieved any kind of civilizational accomplishments since they were intellectually inferior due to their smaller brains (Davis, 1869; Campbell, 1891; Hoffman, 1896; Ridpath, 1897; Christison, 1899).
Robert Bean (1906) stated, using cadavers, that his white cadavers had larger frontal lobes than his black cadavers. He concluded that blacks were more objective than whites who were more subjective, and that white cadavers has larger frontal and anterior lobes than black cadavers. However, it seems that Bean did not state one conclusion—that the brain’s of his cadavers seemed to show no difference. Gould (1996: 112) discusses this issue (see Mall, 1909: 8-10, 13; Reuter, 1927). Mall (1909: 32) concluded, “In this study of several anatomical characters said to vary according to race and sex, the evidence advanced has been tested and found wanting.”
Franz Boas also didn’t agree with Bean’s analysis:
Furthermore, in “The Anthropological Position of the Negro,” which appeared in Van Norden)- Magazine a few months later, Boas attempted to refute Bean by arguing that “the anatomical differences” between blacks and whites “are minute,” and “no scientific proof that will stand honest proof … would prove the inferiority of the negro race.”39 (Williams, 1996: 20)
In 1912, Boas argued that the skull was plastic, so plastic that changes in skull shape between immigrants and their progeny were seen. His results were disputed (Sparks and Jantz, 2002), though Gravlee, Bernard, and Leonard (2002) argued that Boas was right—the shape of the skull indeed was influenced by environmental factors.
When it comes to sex, brain size, and intelligence, this was discredited by Alice Lee in her thesis in 1900. Lee created a way to measure the brain of living subjects and she used her method on the Anthropological Society and showed a wife variation, with of course overlapping sizes between men and women.
Lee, though, was a staunch eugenicist and did not apply the same thinking to race:
After dismantling the connection between gender and intellect, a logical route would have been to apply the same analysis to race. And race was indeed the next realm that Lee turned to—but her conclusions were not the same. Instead, she affirmed that through systematic measurement of skull size, scientists could indeed define distinct and separate racial groups, as craniometry contended. (The Statistician Who Debunked Sexist Myths About Skull Size and Intelligence)
Contemporary research on race, brain size, and intelligence
Starting from the mid-1980s when Rushton first tried to apply r/K to human races, there was a lively debate in the literature, with people responding to Rushton and Rushton responding back (Cain and Vanderwolf, 1990; Lynn, 1990; Rushton, 1990; Mouat, 1992). Why did Rushton seemingly revive this area of “research” into racial differences in brain size between human races?
Centring Rushton’s views on racial differences needs to start in his teenage years. Rushton stated that being surrounded by anti-white and anti-western views led to him seeking out right-wing ideas:
JPR recalls how the works of Hans Eysenck were significantly influential to the teenage Rushton, particularly his personality questionnaires mapping political affiliation to personality. During those turbulent years JPR describes bundled as growing his hair long becoming outgoing but utterly selfish. Finding himself surrounded by what he described as anti-white and anti-western views, JPR became interested in right-wing groups. He went about sourcing old, forbidden copies of eugenics articles that argued that evolutionary differences existed between blacks and whites. (Forsythe, 2019) (See alsoDutton, 2018.)
Knowing this, it makes sense how Rushton was so well-versed in old 18 and 1900s literature on racial differences.
For decades, J. P. Rushton argued that skulls and brains of blacks were smaller than whites. Since intelligence was related to brain size in Rushtonian r/K selection theory, this meant that what would account for some of the intelligence differences based on IQ scores between blacks and whites could be accounted for by differences in brain size between them. Since the brain size differences between races accounted for millions of brain cells, this could then explain race differences in IQ (Rushton and Rushton, 2003). Rushton (2010) went as far to argue that brain size was an explanation for national IQ differences and longevity.
Rushton’s thing in the 90s was to use MRI to measure endocranial volumes (eg Rushton and Ankney, 1996). Of course they attempt to show how smaller brain sizes are found in lower classes, women, and non-white races. Quite obviously, this is scientific racism, sexism, and classism (which Murray 2020 also wrote a book on). In any case, Rushton and Ankney (2009) tried arguing for “general mental ability” and whole brain size, trying to argue that the older studies “got it right” in regard to not only intelligence and brain size but also race and brain size. (Rushton and Ankney, just like Rushton and Jensen 2005, cited Mall, 1909 in the same sentence as Bean, 1906 trying to argue that the differences in brain size between whites and blacks were noted then, when Mall was a response specifically to Bean! See Gould 1996 for a solid review of Bean and Mall.) Kamin and Omari (1998) show that whites had greater head height than blacks while blacks had greater head length and circumference. They described many errors that Lynn, Rushton and Jensen made in their analyses of race and head size. Not only did Rushton ignore Tobias’ conclusions when it comes to measuring brains, he also ignored the fact that American Blacks, in comparison to American, French and English whites, had larger brains in Tobias’ (1970) study (Weizmann et al, 1990).
Rushton and Ankney (2009) review much of the same material they did in their 1996 review. They state:
The sex differences in brain size present a paradox. Women have proportionately smaller average brains than men but apparently have the same intelligence test scores.
This isn’t a paradox at all, it’s very simple to explain. Terman assumed that men and women should be equal in IQ and so constructed his test to fit that assumption. Since Terman’s Stanford-Binet test is still in use today, and since newer versions are “validated” on older versions that held the same assumption, then it follows that the assumption is still alive today. This isn’t some “paradox” that needs to be explained away by brain size, we just need to look back into history and see why this is a thing. The SAT has been changed many times to strengthen or weaken sex differences (Rosser, 1989). It’s funny how this completely astounds hereditarians. “There are large differences in brain size between men and women but hardly if any differences in IQ, but a 1 SD difference in IQ between whites and blacks which is accounted for in part by brain size.” I wonder why that never struck them as absurd? If Rushton accepted brain weight as an indicator that IQ test scores reflected differences in brain size between the races, then he would also need to accept that this should be true for men and women (Cernovsky, 1990), but Rushton never proposed anything like that. Indeed he couldn’t, since sex differences in IQ are small or nonexistent.
In their review papers, Rushton and Ankney, as did Rushton and Jensen (I should assume that this was Rushton’s contribution to the paper since he also has the same citations and arguments in his book and other papers) consistently return to a few references: Mall, Bean, Vint and Gordon, Ho et al and Beals et al. Cernovsky (1995) has a masterful response to Rushton where he dismantles his inferences and conclusions based on other studies. Cernovsky showed that Rushton’s claim that his claim that there are consistent differences between races in brain size is false; Rushton misrepresented other studies which showed blacks having heavier brains and larger cranial capacities than whites. He misrepresented Beals et al by claiming that the differences in the skulls they studied are due to race when race was spurious, climate explained the differences regardless of race. And Rushton even misrepresented Herskovits’ data which showed no difference in regarding statute or crania. So Rushton even misrepresented the brain-body size literature.
Now I need to discuss one citation line that Rushton went back to again and again throughout his career writing about racial differences. In articles like Rushton (2002)Rushton and Jensen (2005), Rushton and Ankney (2007, 2009) Rushton went back to a similar citation line: Citing 1900s studies which show racial differences. Knowing what we know about Rushton looking for old eugenics articles that showed that evolutionary differences existed between blacks and whites, this can now be placed into context.
Weighing brains at autopsy, Broca (1873) found that Whites averaged heavier brains than Blacks and had more complex convolutions and larger frontal lobes. Subsequent studies have found an average Black–White difference of about 100 g (Bean, 1906; Mall, 1909; Pearl, 1934; Vint, 1934). Some studies have found that the more White admixture (judged independently from skin color), the greater the average brain weight in Blacks (Bean, 1906; Pearl, 1934). In a study of 1,261 American adults, Ho et al. (1980) found that 811 White Americans averaged 1,323 g and 450 Black Americans averaged 1,223 g (Figure 1).
There are however, some problems with this citation line. For instance, Mall (1909) was actually a response to Bean (1906). Mall was race-blind to where the brains came from after reanalysis and found no differences in the brain between blacks and whites. Regarding the Ho et al citation, Rushton completely misrepresented their conclusions. Further, brains that are autopsied aren’t representative of the population at large (Cain and Vanderwolf, 1990; see also Lynn, 1989; Fairchild, 1991). Rushton also misrepresented the conclusions in Beals et al (1984) over the years (eg, Rushton and Ankney, 2009). Rushton reported that they found his same racial hierarchy in brain size. Cernovsky and Littman (2019) stated that Beals et al’s conclusion was that cranial size varied with climatic zone and not race, and that the correlation between race and brain size was spurious, with smaller heads found in warmer climates, regardless of race. This is yet more evidence that Rushton ignored data that fid not fit his a priori conclusions (see Cernovsky, 1997; Lerner, 2019: 694-700). Nevertheless, it seems that Rushton’s categorization of races by brain size cannot be valid (Peters, 1995).
It would seem to me that Rushton was well-aware of these older papers due to what he read in his teenage years. Although at the beginning of his career, Rushton was a social learning theorist (Rushton, 1980), quite obviously Rushton shifted to differential psychology and became a follower—and collaborator—of Jensenism.
But what is interesting here in the renewed ideas of race and brain size are the different conclusions that different investigators came to after they measured skulls. Lieberman (2001) produced a table which shies different rankings of different races over the past few hundred years.
Table 1 from Lieberman, 2001 showing different racial hierarchies in the 19th and 20th century
As can be seen, there is a stark contrast in who was on top of the hierarchy based on the time period the measurements were taken. Why may this be? Obviously, this is due to what the investigator wanted to find—if you’re looking for something, you’re going to find it.
Rushton (2004) sought to revive the scala naturae, proposing that g—the general factor of intelligence—sits a top a matrix of correlated traits and he tried to argue that the concept of progress should return to evolutionary biology. Rushton’s r/K theory has been addressed in depth, and his claim that evolution is progressive is false. Nevertheless, even Rushton’s claim that brain size was selected for over evolutionary history also seems to be incorrect—it was body size that was, and since larger bodies have larger brains this explains the relationship. (See Deacon, 1990a, 1990b.)
Salami et al (2017) used brains from fresh cadavers, severing them from the spinal cord at the forum magnum and they completely removed the dura mater. This then allowed them to measure the whole brain without any confounds due to parts of the spinal cord which aren’t actually parts of the brain. They found that the mean brain weight for blacks was 1280g with a ranging between 1015g to 1590g while the mean weight of male brains was 1334g. Govender et al (2018) showed a 1404g mean brain weight for the brains of black males.
Rushton aggregated data from myriad different sources and time periods, claiming that by aggregating even data which may have been questionable in quality, the true differences in brain size would appear when averaged out. Rushton, Brainerd, and Pressley, 1983 defended the use of aggregation stating “By combining numerous exemplars, such errors of measurement are averaged out, leaving a clearer view of underlying relationships.” However, this method that Rushton used throughout his career has been widely criticized (eg, Cernovsky, 1993; Lieberman, 2001).
Rushton was quoted as saying “Even if you take something like athletic ability or sexuality—not to reinforce stereotypes or some such thing—but, you know, it’s a trade-off: more brain or more penis. You can’t have both.” How strange—because for 30 years Rushton pushed stereotypes as truth and built a whole (invalid) research program around them. The fact of the matter is, for Rushton’s hierarchy when it comes to Asians, they are a selected population in America. Thus, even there, Rushton’s claim rests on values taken from a selected population into the country.
While Asians had larger brains and higher IQ scores, they had lower sexual drive and smaller genitals; blacks had smaller brains and lower IQ scores with higher sexual drive and larger genitals; whites were just right, having brains slightly smaller than Asians with slightly lower IQs and lower sexual drive than blacks but higher than Asians along with smaller genitals than blacks but larger than Asians. This is Rushton’s legacy—keeping up racial stereotypes (even then, his claims on racial differences in penis size do not hold.)
The misleading arguments on brain size lend further evidence against Rushton’s overarching program. Thus, this discussion is yet more evidence that Rushton was anything but a “serious scholar” who trolled shopping malls asking people their sexual exploits. He was clearly an ideologue with a point to prove about race differences which probably manifested in his younger, teenage years. Rushton got a ton wrong, and we can now add brain size to that list, too, due to his fudging of data, misrepresenting data, and not including data that didn’t fit his a priori biases.
Quite clearly, whites and Asians have all the “good” while blacks and other non-white races have all the “bad.” And thus, what explains social positions not only in America but throughout the world (based on Lynn’s fraudulent national IQs; Sear, 2020) is IQ which is mediated by brain size. Brain size was but a part of Rushton’s racial rank ordering, known as r-K selection theory or differential K theory. However, his theory didn’t replicate and it was found that any differences noticed by Rushton could be environmentally-driven (Gorey and Cryns, 1995; Peregrine, Ember and Ember, 2003).
The fact of the matter is, Rushton has been summarily refuted on many of his incendiary claims about racial differences, so much so that a couple of years ago quite a few of his papers were retracted (three in one swipe). While a theoretical article arguing about the possibility that melanocortin and skin color may mediate aggression and sexuality in humans (Rushton and Templer, 2012). (This appears to be the last paper that Rushton published before his death in October, 2012. How poetic that it was retracted.) This was due mainly to the outstanding and in depth look into the arguments and citations made by Rushton and Templer. (See my critique here.)
Conclusion
Quite clearly, Gould got it right about Morton—Gould’s reanalysis showed the unconscious bias that was inherent in Morton’s thoughts on his skull collection. Gould’s—and Weisberg’s—reanalysis show that there are small differences in skulls of Morton’s collection. Even then, Gould’s landmark book showed that the study of racial differences—in this case, in brain and skull size—came from a place of racist thought. Writings from Rushton and others carry on this flame, although Rushton’s work was shown to have considerable flaws, along with the fact that he outright ignored data that didn’t fit his a priori convictions.
Although comparative studies of brain size have been widely criticized (Healy and Rowe, 2007), they quite obviously survive today due to the assumptions that hereditarians have between “IQ” and brain size along with the assumption that there are racial differences in brain size and that these differences are causal for socially-important things. However, as can be seen, the comparative study of racial brain sizes and the assumption that IQ is causally mediated by it are hugely mistaken. Morton’s studies were clouded by his racial bias, as Gould and Weisberg and Kaplan et al showed. When Rushton, Jensen, and Lynn arose, they they tried to carry on that flame, correlating head size and IQ while claiming that smaller head sizes and—by identity—smaller brains are related to a suite of negative traits.
The brain is of course an experience-dependent organ and people are exposed to different types of knowledge based on their race and social class. This difference in knowledge exposure based on group membership, then, explains IQ scores. Not any so-called differences in brain size, brain physiology or genes. And while Cairo (2011) concludes that “Everything indicates that experience makes the great difference, and therefore, we contend that the gene-environment interplay is what defines the IQ of an individual“, genes are merely necessary for that, not sufficient. Of course, since IQ is an outcome of experience, this is what explains IQ differences between groups.
Table 1 from Lieberman (2001) is very telling about Gould’s overarching claim about bias in science. As the table shows, the hierarchy in brain size was constantly shifting throughout the years based on a priori biases. Even different authors coming to different conclusions in the same time period on whether or not there are differences in brain size between races pop up. Quite obviously, the race scientists would show that race is the significant variable in whatever they were studying and so the average differences in brain size then reflect differences in genes and then intelligence which would then be reflected in civilizational accomplishments. That’s the line of reasoning that hereditarians like Rushton use when operating under these assumptions.
Science itself isn’t racist, but racist individuals can attempt to use science to import their biases and thoughts on certain groups to the masses and use a scientific veneer to achieve that aim. Rushton, Jensen and others have particular reasons to believe what they do about the structure of society and how and why certain racial groups are in the societal spot they are in. However, these a priori conceptions they had then guided their research programs for the rest of their lives. Thus, Gould’s main claim in Mismeasure about the bias that was inherent in science is well-represented: one only needs to look at contemporary hereditarian writings to see how their biases shape their research and interpretations of data.
In the end, we don’t need just-so stories to explain how and why races differ in IQ scores. We most definitely don’t need any kinds of false claims about how brain size is causal for intelligence. Nor do we need to revive racist thought on the causes and consequences of racial differences in brain size. Quite obviously, Rushton was a dodgy character in his attempt to prove his tri-archic racial theory using r/K selection theory. But it seems that when one surveys the history of accounts of racial differences in brain size and how these values were ascertained, upon critical examination, such differences claimed by the hereditarian all but dissappear.
I’ve had a few discussions with Grey Enlightenment on this blog, regarding construct validity. He has now published a response piece on his blog to the arguments put forth in my article, though unfortunately it’s kind of sophomoric.
2) That I strongly question the usefulness and utility of IQ due to its construction doesn’t mean that I’m not a race realist.
3) I’ve even put forth an analogous argument on an ‘athletic abilities test’ where I gave a hypothetical argument where a test was constructed that wasn’t a true test of athletic ability and that it was constructed on the basis of who is or is not athletic, per the constructors’ presuppositions. In this hypothetical scenario, am I really denying that athletic differences exist between races and individuals? No. I’d just be pointing out flaws in a shitty test.
Just because I question the usefulness and (nonexistent) validity of IQ doesn’t mean that I’m not a race realist, nor that I believe groups or individuals are ‘the same’ in ‘intelligence’ (whatever that may be; which seems to be a common strawman for those who don’t bow to the alter of IQ).
Blood alcohol concentration is very specific and simple; human intelligence by comparison is not . Intelligence is polygenic (as opposed to just a single compound) and is not as easy to delineate, as, say, the concentration of ethanol in the blood.
It’s irrelevant how ‘simple’ blood alcohol concentration is. The point of bringing it up is that it’s a construct valid measure which is then calibrated against an accepted and theoretical biological model. The additive gene assumption is false, that is, genes being independent of the environment giving ‘positive charges’ as Robert Plomin believes.
He says IQ tests are biased because they require some implicit understanding if social constructs, like what 1+1 equals or how to read a word problem, but how is a test that is as simple as digit recall or pattern recognition possibly a social construct.
What is it that allows individuals to be better than others on digit recall or pattern recognition (what kind of pattern recognition?)? The point of my 1+1 statement is that it is construct valid regarding one’s knowledge of that math problem whereas for the word problem, it was a quoted example showing how if the answer isn’t worded correctly it could be indirectly testing something else.
He’s invoking a postmodernist argument that IQ tests do not measure an innate, intrinsic intelligence, but rather a subjective one that is construct of the test creators and society.
I could do without the buzzword (postmodernist) though he is correct. IQ tests test what their constructors assume is ‘intelligence’ and through item analysis they get the results they want, as I’ve shown previously.
If IQ tests are biased, how is then [sic] that Asians and Jews are able to score better than Whiles [sic] on such tests; surely, they should be at a disadvantage due to implicit biases of a test that is created by Whites.
If I had a dollar for every time I’ve heard this ‘argument’… We can just go back to the test construction argument and we can construct a test that, say, blacks and women score higher than whites and men respectively. How well would that ‘predict’ anything then, if the test constructors had a different set of assumptions?
IQ tests aren’t ‘biased’, as much as lower class people aren’t as prepared to take these tests as people in higher classes (which East Asians and Jews are in). IQ tests score enculturation to the middle class, even the Flynn effect can be explained by the rise in the middle class, lending credence to the aforementioned hypothesis (Richardson, 2002).
Regarding the common objection by the left that IQ tests don’t measures [sic] anything useful or that IQ isn’t correlated with success at life, on a practical level, how else can one explain obvious differences in learning speed, income or educational attainment among otherwise homogeneous groups? Why is it in class some kids learn so much faster than others, and many of these fast-learners go to university and get good-paying jobs, while those who learn slowly tend to not go to college, or if they do, drop out and are either permanently unemployed or stuck in low-paying, low-status jobs? In a family with many siblings, is it not evident that some children are smarter than others (and because it’s a shared environment, environmental differences cannot be blamed).
1) I’m not a leftist.
2) I never stated that IQ tests don’t correlate with success in life. They correlate with success in life since achievement tests and IQ tests are different versions of the same test. This, of course, goes back to our good friend test construction. IQ is correlated with income at .4, meaning 16 percent of the variance is explained by IQ and since you shouldn’t attribute causation to correlations (lest you commit the cum hoc, ergo propter hoc fallacy), we cannot even truthfully say that 16 percent of the variation between individuals is due to IQ.
3) Pupils who do well in school tend to not be high-achieving adults whereas children who were not good pupils ended up having good success in life (see the paper Natural Learning in Higher Education by Armstrong, 2011). Furthermore, the role of test motivation could account for low-paying, low-status jobs (Duckworth et al, 2011; though I disagree with their consulting that IQ tests test ‘intelligence’ [whatever that is] they show good evidence that in low scorers, incentives can raise scores, implying that they weren’t as motivated as the high scorers). Lastly, do individuals within the same family experience the same environment the same or differently?
As teachers can attest, some students are just ‘slow’ and cannot grasp the material despite many repetitions; others learn much more quickly.
This is evidence of the uselessness of IQ tests, for if teachers can accurately predict student success then why should we waste time and money to give a kid some test that supposedly ‘predicts’ his success in life (which as I’ve argued is self-fulfilling)? Richardson (1998: 117) quotes Layzer (1973: 238) who writes:
Admirers of IQ tests usually lay great stress on their predictive power. They marvel that a one-hour test administered to a child at the age of eight can predict with considerable accuracy whether he will finish college. But as Burt and his associates have clearly demonstrated, teachers’ subjective assessments afford even more reliable predictors. This is almost a truism.
Because IQ tests test for the skills that are required for learning, such as short term memory, someone who has a low IQ would find learning difficult and be unable to make correct inferences from existing knowledge.
Right, IQ tests test for skills that are required for learning. Though a lot of IQ test questions are general knowledge questions, so how is that testing anything innate if you’ve first got to learn the material, and if you have not you’ll score lower? Richardson (2002) discusses how people in lower classes are differentially prepared for IQ tests which then affects scores, along with psycho-social factors that do so as well. It’s more complicated than ‘low IQ > X’.
All of these sub-tests are positively correlated due to an underlying factor –called g–that accounts for 40-50% of the variation between IQ scores. This suggests that IQ tests measure a certain factor that every individual is endowed with, rather than just being a haphazard collection of questions that have nothing to do with each other. Race realists’ objection is that g is meaningless, but the literature disagrees “… The practical validity of g as a predictor of educational, economic, and social outcomes is more far-ranging and universal than that of any other known psychological variable. The validity of g is greater the complexity of the task.[57][58]”
I’ve covered this before. It correlates with the aforementioned variables due to test construction. It’s really that easy. If the test constructors have a different set of presuppositions before the test is constructed then completely different outcomes can be had just by constricting a different test.
Then what about ‘g’? What would one say then? Nevertheless, I’ve heavily criticized ‘g’ and its supposed physiology, and if physiologists did study this ‘variable’ and if it truly did exist, 1) it would not be rank ordered because physiologists don’t rank order traits, 2) they don’t assume normal variations, they don’t estimate heritability and attempt to untangle genes from environment, 3) they don’t assume that normal variation is related to genetic variation (except in rare cases, like down syndrome, for instance), and 4) nor do they assume within the normal range of physiological differences that a higher level is ‘better’ than a lower. My go-to example here is BMR (basal metabolic rate). It has a similar heritability range as IQ (.4 to .8; which is most likely overestimated due to the use of the flawed twin method, just like the heritability of IQ), so is one with a higher BMR somehow ‘better’ than one with a lower BMR? This is what logically follows from assuming that ‘g’ is physiological and all of the assumptions that come along with it. It doesn’t make logical, physiological sense! (Jensen, 1998: 92 further notes that “g tells us little if anything about its contents“.)
All in all, I thank Grey Enlightenment for his response to my article, though it leaves a lot to be desired and if he responds to this article then I hope that it’s much more nuanced. IQ has no construct validity, and as I’ve shown, the attempts at giving it validity are circular, and done by correlating it with other IQ tests and achievement tests. That’s not construct validity.
“The human mind is not a blank slate; intelligence is biological”
The mind is not a ‘blank slate’, though there is no ‘biological’ basis for intelligence (at least in the way that hereditarians believe). They’re just correlations. (Whatever ‘intelligence’ is.)
“there is no known environmental intervention—including breast feeding”
There is a causal effect of breast feeding on IQ:
While reported associations of breastfeeding with child BP and BMI are likely to reflect residual confounding, breastfeeding may have causal effects on IQ. Comparing associations between populations with differing confounding structures can be used to improve causal inference in observational studies.
Breastfeeding is related to improved performance in intelligence tests. A positive effect of breastfeeding on cognition was also observed in a randomised trial. This suggests that the association is causal.
“Normal people can have extraordinary abilities. Prof. Haier writes about a non-savant who used memory techniques to memorize 67,890 digits of π! He also notes that chess grandmasters have an average IQ of 100; they seem to have a highly specialized ability that is different from normal intelligence. Prof. Haier asks whether we will eventually understand the brain well enough to endow anyone with special abilities of that kind.”
Evidence that intelligence is not related to expertise.
“It is only after a weight of evidence has been established that we should have any degree of confidence in a finding, and Prof. Haier issues another warning: “If the weight of evidence changes for any of the topics covered, I will change my mind, and so should you.” It is refreshing when scientists do science rather than sociology.”
Even with the “weight of evidence”, most people will not change their views on this matter.
“Once it became possible to take static and then real-time pictures of what is going on in the brain, a number of findings emerged. One is that intelligence appears to be related to both brain efficiency and structure”
Patterns of activation in response to various fluid reasoning tasks are diverse, and brain regions activated in response to ostensibly similar types of reasoning (inductive, deductive) appear to be closely associated with task content and context. The evidence is not consistent with the view that there is a unitary reasoning neural substrate. (p. 145)
“Early findings suggested that smart people’s brains require less glucose—the main fuel for brain activity—than those of dullards.”
Cause and correlation aren’t untangled; they could be answering questions in a familiar format, for instance, and this could be why their brains show less glucose consumption.
“It now appears that grey matter is where “thinking” takes place, and white matter provides connections between different areas of grey matter. Some brains seem to be organized with shorter white-matter connections, which appear to allow more efficient communication, and there seem to be sex differences in the ways the part of the brain are connected. One of the effects of aging is deterioration of the white-matter connections, which reduces intelligence.”
Read this commentary (pg. 162): Norgate, S., & Richardson, K. (2007). On images from correlations. Behavioral and Brain Sciences, 30(02), 162. doi:10.1017/s0140525x07001379
“Brain damage never makes people smarter”
This is wrong:
You would think that cutting out one-half of people’s brains would kill them, or at least leave them vegetables needing care for the rest of their lives. But it does not. Consider this striking story. A boy starts having seizures at 10 years of age when his right cerebral hemisphere atrophies. By the time he is 12, the left side of his body is paralyzed. When he is 19, surgeons decide to operate and remove the right side of his brain, as it is causing gits in his intact left one. You might think this would lower his IQ or leave him severely retarded, but no. His IQ shoots up 14 points, to 142! The mystery is not so great when you realize that the operation has gotten rid of the source of his fits, which had previously hampered his intelligence. When doctors saw him 15 years later, they described him as “having obtained a university diploma . . . [and now holding] a responsible administrative position with a local authority.”
“Prof. Haier wants a concerted effort: “What if a country ignored space exploration and announced its major scientific goal was to achieve the capability to increase every citizen’s g-factor [general intelligence] by a standard deviation?””
Don’t make me laugh. You need to prove that ‘g’ exists first. Glad to see some commentary on epigenetics that isn’t bashing it (it is a real phenomenon, though the scope of it in regards to health, disease and evolution remains to be discovered).
As most readers may know, I’m skeptical here and a huge contrarian. I do not believe that g is physiological and if it were then they better start defining it/talking about it differently because I’ve shown that if it were physiological then it would not mimick any known physiological process in the body. I eagerly await some good neuroscience studies on IQ that are robust, with large ns, their conclusions show the arrow of causality, and they’re not just making large sweeping claims that they found X “just because they want to” and are emotionally invested in their work. That’s my opinion about a lot of intelligence research; like everyone, they are invested in their own theories and will do whatever it takes to save face no matter the results. The recent Amy Cuddy fiasco is the perfect example of someone not giving up when it’s clear they’re incorrect.
I wish that Mr. Taylor would actually read some of the literature out there on TBI and IQ along with how people with chunks of their brains missing can have IQs in the normal range, showing evidence that most a lot of our brain mass is redundant. How can someone survive with a brain that weighs 1.5 pounds (680 gms) and not need care for the rest of his life? That, in my opinion, shows how incredible of an organ the human brain is and how plastic it is—especially in young age. People with IQs in the normal range need to be studied by neuroscientists because anomalies need explaining.
If large brains are needed for high IQs, then how do these people function in day-to-day life? Shouldn’t they be ‘as dumb as an erectus’, since they have erectus-sized brains living in the modern world? Well, the human body and brain are two amazing aspects of evolution, so even sudden brain damage and brain removal (up to half the brain) does not show deleterious effects in a lot of people. This is a clue, a clue that most of our brain mass after erectus is useless for our ‘intelligence’ and that our brains must have expanded for another reason—family structure, sociality, expertise, etc. I will cover this at length in the future.
RaceRealist and I have been ruminating on a lot of stuff lately. Here’s a fun one: what economic system works best relative to what we know about human health? In my mind there are two approaches: the libertarian approach, and quasi-fascism.
In the libertarian approach, there’s no regulation of sugar placed in our food. That’s already the case. But here’s an improvement: you don’t have to pay for anyone’s gastric bypass after they overeat that sugar.
In the fascist approach, there is regulation of sugar, because a fascist state does not allow people to poison each other for profit. You still have to pay for others’ medical expenses, but those expenses will be lower.
Here’s an advantage to the libertarian approach. In that society, the people who stuff their faces and refuse to get off the couch- who are dumber and lazier on average, probably- will have a higher mortality rate on average. Eugenics need not cost a dime.
But you run into a snag, sand in the gears of your hands-off system, when Big Food kicks out a whole bunch of crappy dietary advice, at which point a minority of reasonably intelligent people will be led astray, perhaps to the grave. How could a libertarian society stop that from taking place? Would it even bother? Could the system broadly work in spite of this snag?
A libertarian society doesn’t pay for idiots to have children. That’s good, but half of your population (women) are unlikely to ever support it. Women don’t do libertarianism; observe Rand Paul’s demographic Achilles Heel on page 25. When women asked men what to do about so-and-so’s eighth unpaid for child, we’d have to look them in the eyes and give a deadpan “let’s hope private charity can handle it.” There was a time, before FDR, when women would’ve accepted that answer. They were still in the kitchen back then, and I don’t know how to put them back there.
A fascist society has more hands-on eugenics, possibly genome editing or embryo selection. Also good. Expensive, but obviously worth it.
We welcome your input on these issues.
*****
As an aside, White men are well-known as the most conservative, small government, nationalist group out there in our current political atmosphere. I always hear people spewing the schmaltziest nonsense about the values of the Founding Fathers. They were, relative to our political compass, nationalist libertarians. Accordingly, modern nationalists and libertarians do best with the exact same demographics that used to vote on candidates back then: property-owning White men. The sole reason that Ron and Rand Paul couldn’t get elected is that they are too similar to the Founding Fathers. Any other candidate who blathers on about the Founding values is simply a liar, and their obvious lies show a disrespect of your intelligence.
If you’re a libertarian, but not an ethno-nationalistic and patriarchal thinker, then you simply haven’t gotten the memo: women and minorities do not want to create the same world that you do, nor will they ever. Evolution gave us women who want social safety nets and other races which are better off if they parasitize off of your tax dollars. All of the most libertarian societies that ever existed (early US, ancient Athens, Roman Republic) were entirely run by White men, and adding women to the electorate gave us the welfare state. Aristophanes was right.
*****
We’re also ruminating on the difference between IQ and expertise. I know of no mentally complicated task of which one can be a master without being intelligent. Take the IQs of chess grandmasters and you will find no morons.
Contrast that with purely physical activities. I bet you there are some really stupid people out there who are great at dancing for example. A prodigiously capable cerebellum may not predict an equally capable frontal lobe.
Discounting tasks which exclusively require things like simple physical coordination, muscle memory, etc, I ought to think that IQ is the biggest component of expertise.