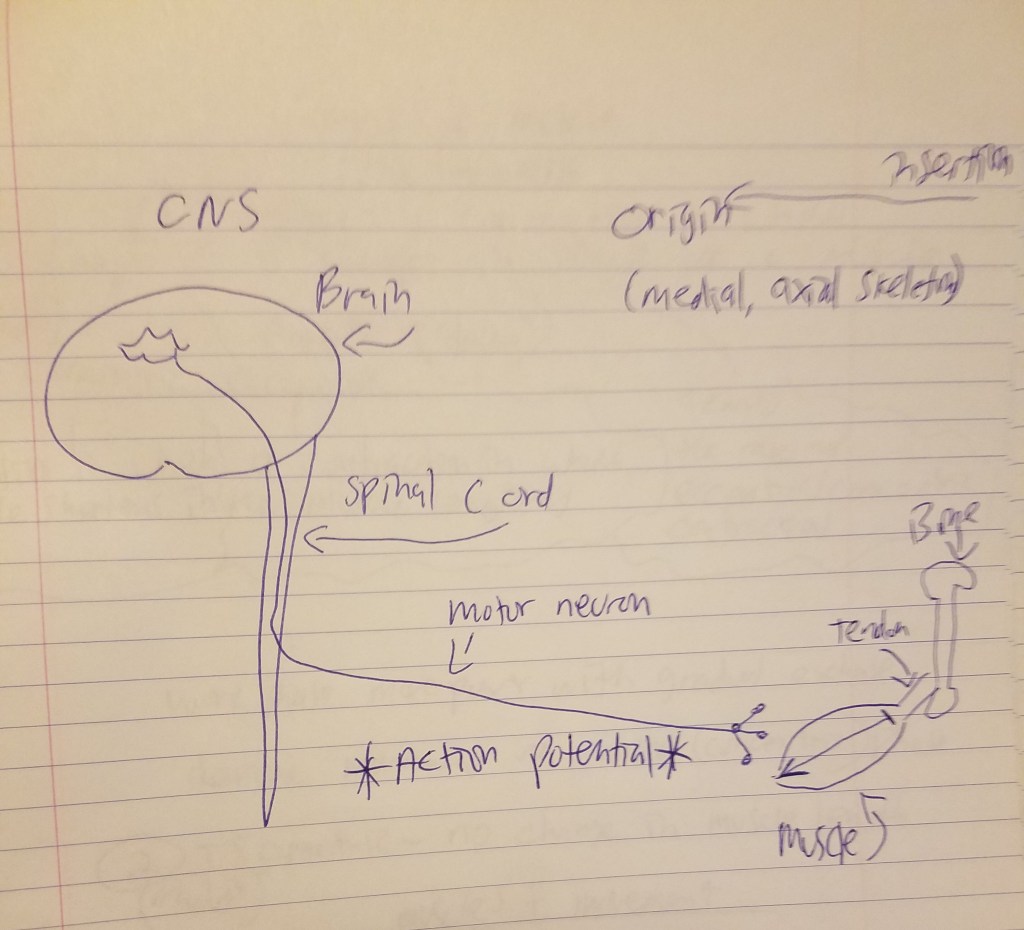
Spring training is ramping up to prepare MLB players for the beginning of the season at the end of the month. (Go Yankees, Yankee fan for 30+ years.) To celebrate, I’m going to discuss sabermetrics and psychometrics and why sabermetrics > psychometrics. The gist is this: Sabermetrics and sabermetricians are actually measuring aspects of baseball performance (since there are observable physical events that occur, and then the sabermetricians think of what they want to measure and then use tangible values) while psychometricians aren’t measuring anything since there is no specified measured object, object of measurement and measurement unit for IQ or any psychological trait. I will mount the argument that sabermetricians are actually measuring aspects of baseball performance while psychometricians aren’t actually measuring aspects of human psychology.
Sabermetrics > psychometrics
Psychometrics is the so-called science of the mind. The psychometrician claims that they can measure the mind and specific attributes of individuals. But without a specified measured object, object of measurement and measurement unit for any psychological trait, then a science of the mind just isn’t possible. Psychometrics fails as true measurement since it doesn’t meet the basic requirements for measurement. When something physical is measured—like the length of a stick or a person’s weight—three things are needed: a clear object (a person or stick); a specific property (length or weight); and a standard unit (inches or kilograms). But unlike physical traits, mental traits aren’t directly observable and therefore, psychometricians just assume that they are measuring what they set out to. People think they because numbers are assigned to things, that psychometrics is measurement.
Sabermetrics was developed in the 1980s, pioneered by Bill James. The point of sabermetrics is to used advanced stats to analyze baseball performance to understand player performance and how a manager should build their team. We now have tools like Statcast where the exit velocity is measured once a player hits a ball, and we can also see the launch angle of the ball after it leaves the bat. It clearly focuses on measurable, tangible events which can then be evaluated more in depth when we want to understand more about a certain player.
For instance, take OBP, SLG, and OPS.
OBP (on-base percentage) is the frequency by which a player reaches base. This could be due to getting a hit, drawing a walk or being hit by a pitch. The OBP formula is: OBP = hits + walks + hit by pitch / at bats + walks + hit by pitch + sac flies. While batting average (BA) tells us how often we would expect a hitter to get a hit during a plate appearance, OBP incorporates walks which are of course important for scoring opportunities.
SLG (slugging) measures the total bases a player earns per at bat, while giving extra weight to a double, triple and homerun. SLG shows how well a batter can hit for extra bases, which is basically an aspect of their batting power. (That’s is also isolated power or ISO which is SLG – BA.) The formula for SLG is total bases / at bats.
OPS (on-base plus slugging) is a sum of OBP and SLG. It combines a player’s ability to get on base with their power through their SLG. There is also OPS+ which takes into account the ballpark’s dimensions and the altitude of the stadium to compare players without variables that would influence their performance in either direction.
When it comes to balls and strikes there is a subjective element there since different umpires have different strike zones and therefore, one umpire’s strike zone will be different from another’s. However, the MLB is actually testing an automated ball-strike system which would then take out subjectivity.
There is also wOBA (weighted on base average) which accounts for how a player got on base. Homeruns are weighted more than triples, doubles, or singles since they contribute fully to a run. Thus, wOBA is calculated from observable physical events. wOBA predicts run production and is testable against actual scoring.
We also have DRS (defensive runs saved) which attempts to quantify how many runs a particular defenders defense saved which takes into account the defender’s range of his throw, errors and double play ability. It basically is a measure of how many runs a defender cost or saved his team. So a SS who prevents 10 runs in a season has a DRS of +10. (This is similar to the ultimate zone rating—UZR—stat.) Both stats are derived from measurable physical events.
Each of the stats I discussed measure specific and countable actions which are verifiable through replay/Statcast which then tie directly to the game’s result (runs scored/prevented). Advanced baseball stats now have tools like Statcast which analyzes player and ball data during the game. Statcast takes out a lot of subjectivity in certain measurements, and it makes these measurements more reliable. Statcast captures things like exit velocity, launch angle, sprint speed and pitch spin rate. It can also track how far a ball is hit.
The argument that sabermetrics > psychometrics
(P1) If a field relies on quantifiable, observable data (physical events), then its analyses are more accurate. (P2) If a field’s analyses are more accurate, then it is better for measurement. (C) So if a field relies on quantifiable, observable data (physical events), then it is better for measurement.
Premise 1
Sabermetrics uses concrete numbers like hits, RBIs and homeruns. BA = hits / at bats, so a player who has 90 hits out of 300 at bats has a .300 average. When it comes to psychometrics mental traits cannot be observed/seen or counted like the physical events in baseball. So sabermetrics satisfies P1 since it relies on quantifiable, observable data while psychometrics fails since it’s data isn’t directly observable nor is it consistently quantifiable in a verifiable way. It should be noted that counting right or wrong answers on a test isn’t the same. A correct answer on a so-called intelligence test doesn’t directly measure intelligence, it’s supposedly a proxy which is influenced by test design and exposure to the items in question.
Premise 2
A player’s OBP can reliably indicate their runs scored contribution which can then be validated by the outcomes in the game. Psychometrics on the other hand has an issue here—one’s performance on a so-called psychometric test can be influenced by time or test type. So sabermetrics satisfies P2, since it’s accurate analyses enhance its measurement strength while psychometrics does not less accurate analyses along with not having the basic requirements for measurement then mean that it’s not measurement proper, at all.
Conclusion
Sabermetrics relies on quantifiable, observable data (P1 is true), and this leads to accurate analyses making it better for measurement (P2 is true), so sabermetrics > psychometrics since there are actual, quantifiable, observable physical events to be measured and analyzed by sabermetricians while the same is not true for psychometrics.
Since only counting and measurement qualify for quantification because they provide meaningful representations of quantities, then sabermetrics excels as a true quantitative field by directly rallying observable physical events. The numbers used in sabermetrics reflect real physical events and not interpretations. Batting average and on-base percentage are calculated directly from counts without introducing arbitrary scaling, meaning that a clear link to the original quantifiable events are maintained.
Conclusion
Rooted in data and observable, physical events, sabermetrics comes out the clear winner in this comparison. Fields that use quantifiable, observable evidence yield better, clearer insights and these insights then allow a field to gauge its subject accurately. This clearly encompasses sabermetrics. The data used in sabermetrics are based on quantifiable, observable data (physical events).
On the other hand, psychometrics fails where sabermetrics flourishes. Psychometrics lacks observable, quantifiable substance that true measurement demands. There is no specified measured object, object of measurement and measurement unit for IQ or any psychological trait. Therefore, psychometrics can’t satisfy the premises in the argument that I have constructed.
Basically, psychometricians render “mere application of number systems to objects” (Garrison, 2004: 63). Therefore, there is an illusion of measurement for psychometrics. The psychometrician claims they can assess abstract constructs that cannot be directly observed while also using indirect proxies like answers to test questions—which are not the trait themselves. There is no standardized unit in psychometrics and, for example for IQ, not true “0” point. Psychometricians order people from high to low, without using true countable units.
If there is physical event analysis then there is quantifiable data. If there is quantifiable data, then there is better measurement. So if there is physical event analysis, then there is better measurement. Thus, if there is no physical event analysis, then there is no measurement. It’s clear which field holds for each premise. The mere fact that baseball is a physical event and we can then count and average out certain aspects of player performance means that sabermetrics is true measurement (since there is a specified measured object, object of measurement and measurement unit) while psychometrics isn’t (no specified measured object, object of measurement and measurement unit).
(1) Crime is bad. (2) Racism causes crime. (C) Thus, racism is morally wrong. (1) is self-evident based on people not wanting to be harmed. (2) is known upon empirical examination, like the TAAO and it’s successful novel predictions. (C) then logically follows. In this article, I will give the argument in formal notation and show its validity while defending the premises and then show how the conclusion follows from the premises. I will then discuss two possible counter arguments and then show how they would fail. I will show that you can derive normative conclusions from ethical and factual statements (which then bypasses the naturalistic fallacy), and then I will give the general argument I am giving here. I will discuss other reasons why racism is bad (since it leads to negative physiological and mental health outcomes), and then conclude that the argument is valid and sound and I will discuss how stereotypes and self-fulfilling prophecies also contribute to black crime.
Defending the argument
This argument is obviously valid and I will show how.
B stands for “crime is bad”, C stands for “racism causes crime”, D stands for racism is objectively incorrect, so from B and C we derive D (if C causes B and B is bad, then D is morally wrong). So the argument is “(B ^ C) -> D”. B and C lead to D, proving validity.
Saying “crime is bad” is an ethical judgement. The term “bad” is used as a moral or ethical judgment. “Bad” implies a negative ethical assessment which suggests that engaging in criminal actions is morally undesirable or ethically wrong. The premise asserts a moral viewpoint, claiming that actions that cause harm—including crime—are inherently bad. It implies a normative stance which implies that criminal behavior is wrong or morally undesirable. So it aligns with the idea that causing harm, violating laws or infringing upon others is morally undesirable.
When it comes to the premise “racism causes crime”, this needs to be centered on the theory of African American offending (TAAO). It’s been established that blacks experiencing racism is causal for crime. So the premise implies that racism is a factor in or contributes to criminal behavior amongst blacks who experience racism. Discriminatory practices based on race (racism) could lead to social inequalities, marginalization and frustration which would then contribute to criminal behavior among the affected person. This could also highlight systemic issues where racist policies or structures create an environment conducive to crime. And on the individual level, experiences of racism could influence certain individuals to engage in criminal activity as a response or coping mechanism (Unnever, 2014; Unnever, Cullen, and Barnes, 2016). Perceived racial discrimination “indirectly predicted arrest, and directly predicted both illegal behavior and jail” (Gibbons et al, 2021). Racists propose that what causes the gap is a slew of psychological traits, genetic factors, and physiological variables, but even in the 1960s, criminologists and geneticists rejected the genetic hypothesis of crime (Wolfgang,1964). However we do know there is a protective effect when parents prepare their children for bias (Burt, Simons, and Gibbons, 2013). Even the role of institutions exacerbates the issue (Hetey and Eberhardt, 2014). And in my article on the Unnever-Gabbidon theory of African American offending, I wrote about one of the predictions that follows from the theory which was borne out when it was tested.
So it’s quite obvious that the premise “racism causes crime” has empirical support.
So if B and C are true then D follows. The logical connection between B and C leads to the conclusion that “racism is morally wrong”, expressed by (B ^ C) -> D. Now I can express this argument using modus ponens.
(1) If (B ^ C) then D. (Expressed as (B ^ C) -> D).
(2) (B ^ C) is true.
(3) Thus, D is true.
When it comes to the argument as a whole it can be generalized to harm is bad and racism causes harm so racism is bad.
Furthermore, I can generalize the argument further and state that not only that crime is bad, but that racism leads to psychological harm and harm is bad, so racism is morally wrong. We know that racism can lead to “weathering” (Geronimus et al, 2006, 2011; Simons, 2021) and increased allostatic load (Barr 2014: 71-72). So racism leads to a slew of unwanted physiological issues (of which microaggressions are a species of; Williams, 2021).
Racism leads to negative physiological and mental health outcomes (P), and negative physiological and mental health outcomes are undesirable (Q), so racism is morally objectionable (R). So the factual statement (P) establishes a link between negative health outcomes, providing evidence that racism leads to these negative health outcomes. The ethical statement (Q) asserts that negative health outcomes are morally undesirable which aligns with a common ethical principle that causing harm is morally objectionable. Then the logical connection (Q ^ P) combines the factual observation of harm caused by racism with the ethical judgment that harm is morally undesirable. Then the normative conclusion (R) follows, which asserts that racial is morally objectionable since it leads to negative health outcomes. So this argument is (Q ^ P) -> R.
Racism can lead to stereotyping of certain groups as more prone to criminal behavior, and this stereotype can be internalized and perpetuated which would then contribute to biased law enforcement and along with it unjust profiling. It can also lead to systemic inequalities like in education, employment and housing which are then linked to higher crime rates (in this instance, racism and stereotyping causes the black-white crime gap, as predicted by Unnever and Gabbidon, 2011 and then verified by numerous authors). Further, as I’ve shown, racism can negatively affect mental health leading to stress, anxiety and trauma and people facing these challenges would be more vulnerable to engage in criminal acts.
Stereotypes and self-fulfilling prophecies
In his book Concepts and Theories of Human Development, Lerner (2018: 298) discusses how stereotyping and self-fulfilling prophecies would arise from said stereotyping. He says that people, based on their skin color, are placed into an unfavorable category. Then negative behaviors were attributed to the group. Then these behaviors were associated with different experience in comparison to other skin color groups. These different behaviors then delimit the range of possible behaviors that could develop. So the group was forced into a limited number of possible behaviors, the same behaviors they were stereotyped to have. So the group finally develops the behavior due to being “channeled” (to use Lerner’s word) which is then “the end result of the physically cued social stereotype was a self-fulfilling prophecy” (Lerner, 2018: 298).
From the analysis of the example I provided and, as well, from empirical literature in support of it (e.g., Spencer, 2006; Spencer et al., 2015), a strong argument can be made that the people of color in the United States have perhaps experienced the most unfortunate effects of this most indirect type of hereditary contribution to behavior–social stereotypes. Thus, it may be that African Americans for many years have been involved in an educational and intellectual self-fulfilling prophecy in the United States. (Lerner, 2018: 299)
Whether it is with images of the super-athlete, criminal, gangster, or hypersexed male, it seems that most of society’s views of African Americans are defined by these stereotypes. The Black male has, in one way or another, captured the imagination of the media to such a wide extent that media representations create his image far more than reality does. Most of the images of the Black male denote physical prowess or aggression and downplay other characteristics. For example, stereotypes of Black athletic prowess can be used to promote the notion that Blacks are unintelligent (Harpalani, 2005). These societal stereotypes, in conjunction with numerous social, political, and economic forces, interact to place African American males at extreme risk for adverse outcomes and behaviors.
A -> B—So stereotypes can lead to self-fulfilling prophecies (if there are stereotypes, then they can result in self-fulfilling prophecies). B -> C—Self-fulfilling prophecies can increase the chance of crime for blacks (if there are self-fulfilling prophecies, then they can increase the chance of crime for blacks. So A -> C—Stereotypes can increase the chance of crime for blacks (if there are stereotypes, then they can increase the chance of crime for blacks). Going back to the empirical studies on the TAAO, we know that racism and stereotypes cause the black-white crime gap (Unnever, 2014; Unnever, Cullen, and Barnes, 2016; Herda, 2016, 2018; Scott and Seal, 2019), and so the argument by Spencer et al and Lerner is yet more evidence that racism and stereotypes lead to self-fulfilling prophecies which then cause black crime. Behavior can quite clearly be shaped by stereotypes and self-fulfilling prophecies.
Responses to possible counters
I think there are 3 ways that one could try to refute the argument—(1) Argue that B is false, (2) argue that C is false, or (3) argue that the argument commits the is-ought fallacy.
(1) Counter premise: B’: “Not all crimes are morally bad, some may be morally justifiable or necessary in certain contexts. So if not all crimes are morally bad, then the conclusion that racism is morally wrong based on the premises (B ^ C) isn’t universally valid.”
Premise B reflects a broad ethical judgment which is based on social norms that generally view actions that cause harm morally undesirable. My argument is based on consequences—that racism causes crime. The legal systems of numerous societies categorize certain actions as crimes since they are deemed morally reprehensible and harmful to individuals and communities. Thus, there is a broad moral stance against actions that cause harm which is reflected in the societal normative stance against actions which cause harm.
(2) Counter premise: C’: “Racism does not necessarily cause crime. Since racism does not necessarily cause crime, then the conclusion that racism is objectively wrong isn’t valid.”
Premise C states that racism causes crime. When I say that, it doesn’t mean that every instance of racism leads to an instance of crime. Numerous social factors contribute to criminal actions, but there is a relationship between racial discrimination (racism) and crime:
Experiencing racial discrimination increases the likelihood of black Americans engaging in criminal actions. How does this follow from the theory? TAAO posits that racial discrimination can lead to feelings of frustration and marginalization, and to cope with these stressors, some individuals may resort to commuting criminal acts as a way to exert power or control in response to their experiences of racial discrimination. (Unnever, 2014; Unnever, Cullen, and Barnes, 2016; Herda, 2016, 2018; Scott and Seal, 2019)
(3) “The argument commits the naturalistic fallacy by inferring an “ought” from an “is.” It appears to derive a normative conclusion from factual and ethical statements. So the transition from descriptive premises to moral judgments lacks a clear ethical justification which violates the naturalistic fallacy.” So this possible counter contends that normative statement B and the ethical statement C isn’t enough to justify the normative conclusion D. Therefore it questions whether the argument has good justification for an ethical transition to the conclusion D.”
I can simply show this. Observe X causing Y (C). Y is morally undesirable (B). Y is morally undesirable and X causes Y (B ^ C). So X is morally objectionable (D). So C begins with an empirical finding. B then is the ethical premise. The logical connection is then established with B ^ C (which can be reduced to “Harm is morally objectionable and racism causes harm”). This then allows me to infer the normative conclusion—D—allowing me to bypass the charge of committing the naturalistic fallacy. Thus, the ethical principle that harm is morally undesirable and that racism causes harm allows me to derive the conclusion that racism is objectively wrong. So factual statements can be combined with ethical statements to derive ethical conclusions, bypassing the naturalistic fallacy.
Conclusion
This discussion centered on my argument (B ^ C) -> D. The argument was:
(P1) Crime is bad (whatever causes harm is bad). (B)
(P2) Racism causes crime. (C)
(C) Racism is morally wrong. (D)
I defended the truth of both premises, and then I answered two possible objections, both rejecting B and C. I then defended my argument against the charge of it committing the naturalistic fallacy by stating that ethical statements can be combined with factual statements to derive normative conclusions. Addressing possible counters (C’ and B’), I argued that there is evidence that racism leads to crime (and other negative health outcomes, generalized as “harm”) in black Americans, and that harm is generally seen as bad, so it then follows that C’ and B’ fail. Spencer’s and Lerner’s arguments, furthermore, show how stereotypes can spur behavioral development, meaning that social stereotypes increase the chance of adverse behavior—meaning crime. It is quite obvious that the TAAO has strong empirical support, and so since crime is bad and racism causes crime then racism is morally wrong. So to decrease the rate of black crime we—as a society—need to change our negative attitudes toward certain groups of people.
Thus, my argument builds a logical connection between harm being bad, racism causing harm and moral undesirability. In addressing potential objections and clarifying the ethical framework I ren, So the general argument is: Harm is bad, racism causes harm, so racism is morally wrong.
Hereditarians have been trying to prove the existence of a genetic basis of intelligence for over 100 years. In this time frame, they have used everything from twin, family and adoption studies to tools from the molecular genetics era like GCTA and GWAS. Using heritability estimates, behavior geneticists claim that since intelligence is highly heritable, that there must thusly be a genetic basis to intelligence controlled by many genes of small effect, meaning it’s highly polygenic.
In his outstanding book Misbehaving Science, Panofsky (2014) discusses an attempt funded by the Rockefeller Foundation (RF) at showing a genetic basis to dog intelligence to prove that intelligence had a genetic basis. But it didn’t end up working out for them—in fact, it showed the opposite. The investigation which was funded by the RF showed quite the opposite result that they were looking for—while they did find evidence of some genetic differences between the dog breeds studied, they didn’t find evidence for the existence of a “general factor of intelligence” in the dogs. This issue was explored in Scott and Fuller’s 1965 book Genetics and the Social Behavior of the Dog. These researchers, though, outright failed in their task to discover a “general intelligence” in dogs. Modern-day research also corroborates this notion.
The genetic basis of dog intelligence?
This push to breed a dog that was highly intelligent was funded by the Rockefeller Foundation for ten years at the Jackson Laboratory. Panofsky (2014: 55) explains:
Over the next twenty years many scientists did stints at Jackson Laboratory working on its projects or attending its short courses and training programs. These projects and researchers produced dozens of papers, mostly concerning dogs and mice, that would form much of the empirical base of the emerging field. In 1965 Scott and John Fuller, his research partner, published Genetics and the Social Behavior of the Dog. It was the most important publication to come out of the Jackson Lab program. Scott and Fuller found many genetic differences between dog breeds; they did not find evidence for general intelligence or temperament. Dogs would exhibit different degrees of intelligence or temperamental characteristics depending on the situation. This evidence of interaction led them to question the high heritability of human intelligence—thus undermining a goal of the Rockefeller Foundation sponsors who had hoped to discredit the idea that intelligence was the product of education. Although the behavioral program at Jackson Laboratory declined after this point, it had been the first important base for the new field.
Quite obviously this was the opposite result of what they wanted—dog intelligence was based on the situation and therefore context-dependent.
Scott and Fuller (1965) discuss how they used to call their tests “intelligence tests” but then switched to calling them “performance tests”, “since the animals seemed to solve their problems in many ways other than through pure thought or intellect” (Scott and Fuller 1965: 37), while also writing that “no evidence was found for a general factor of intelligence which would produce good performance on all tests” (1965, 328). They also stated that they found nothing like the general intelligence factor in dogs like that is found in humans (1965: 472) while also stating that it’s a “mistaken notion” to believe in the general intelligence factor (1965: 512). They then conclude, basically, that situationism is valid for dogs, writing that their “general impression is that an individual from any dog breed will perform well in a situation in which he can be highly motivated and for which he has the necessary physical capacities” (1965: 512). Indeed, Scott noted that due to the heritability estimates of dog intelligence Scott came to the conclusion that human heritability estimates “are far too high” (quoted in Paul, 1998: 279). This is something that even Schonemann (1997) noted—and it’s “too high” due to the inflation of heritability due to the false assumptions of twin studies, which lead to the missing heritability crisis. One principle finding was that genetic differences didn’t appear early in development, which were then molded by further experience in the world. Behavior was highly variable between individuals and similar within breeds.
The results were quite unexpected but scientifically exciting. During the very early stages of development there was so little behavior observed that there was little opportunity for genetic differences to be expressed. When the complex patterns of behavior did appear, they did not show pure and uncontaminated effects of heredity. Instead, they were extraordinarily variable within an individual and surprisingly similar between individuals. In short, the evidence supported the conclusion that genetic differences in behavior do not appear all at once early in development, to be modified by later experience, but are themselves developed under the influence of environmental factors and may appear in full flower only relatively late in life. (Scott and Fuller, 1965)
The whole goal of this study by the Jackson Lab was to show that there was a genetic basis to intelligence in dogs and that they therefore could breed a dog that was intelligent and friendly (Paul, 1998). They also noted that there was no breed which was far and above the best at the task in question. Scott and Fuller found that performance on their tests was strongly affected by motivational and emotional factors. They also found that breed differences were strongly influenced by the environment, where two dogs from different breeds became similar when raised together. We know that dogs raised with cats showed more favorable disposition towards them (Fox, 1958; cf Feuerstein and Terkel, 2008, Menchetti et al, 2020). Scott and Fuller (1965: 333) then concluded that:
On the basis of the information we now have, we can conclude that all breeds show about the same average level of performance in problem solving, provided they can be adequately motivated, provided physical differences and handicaps do not affect the tests, and provided interfering emotional reactions such as fear can be eliminated. In short, all the breeds appear quite similar in pure intelligence.
The issue is that by believing that heritability shows anything about how “genetic” a trait is, one then inters that there has to be a genetic basis to the trait in question, and that the higher the estimate, the more strongly controlled by genes the trait in question is. However, we now know this claim to be false (Moore and Shenk, 2016). More to the point, the simple fact that IQ shows higher heritability than traits in the animal kingdom should have given behavioral geneticists pause. Nonetheless, it is interesting that this study that was carried out in the 1940s showed a negative result in the quest to show a genetic basis to intelligence using dogs, since dogs and humans quite obviously are different. Panofsky (2014: 65) also framed these results with that of rats that were selectively bred to be “smart” and “dumb”:
Further, many animal studies showed that strain differences in behavior were not independent of environment. R. M. Cooper and J. P. Zubek’s study of rats selectively bred to be “dull” and “bright” in maze-running ability showed dramatic differences between the strains in the “normal” environment. But in the “enriched” and especially the “restricted” developmental environments, both strains’ performance were quite similar. Scott and Fuller made a similar finding in their comparative study of dog breeds: “The behavior traits do not appear to be preorganized by heredity. Rather a dog inherits a number of abilities which can be organized in different ways to meet different situations.” Thus even creatures that had been explicitly engineered to embody racial superiority and inferiority could not demonstrate the idea in any simple way
Psychologist Robert Tryon (1940) devised a series of mazes, ran rats through them and then selected rats that learned quicker and slower (Innis, 1992). These differences then seemed to persists across these rat generations. Then Searle (1949) discovered that the so-called “dumb” rats were merely afraid of the mechanical noise of the maze, showing that Tryon selected for—unknowingly—emotional capacity. Marlowitz (1969) then concluded “that the labels “maze-bright” and “maze-dull” are inexplicit and inappropriate for use with these strains.”
Dogs and human races are sometimes said to be similar, in which a dog breed can be likened to a human race (see Norton et al, 2019). However, dog breeds are the result of conscious human selection for certain traits which then creates the breed. So while Scott and Fuller did find evidence for a good amount of genetic differences between the breeds they studied, they did not find any evidence of a genetic basis of intelligence or temperament. This is also good evidence for the claim that a trait can be heritable (have high heritability) but have no genetic basis. Moreover, we know that high levels of training improve dog’s problem solving ability (Marshall-Pescini et al, 2008, 2016). Further, perceived differences in trainability are due to physical capabilities and not cognitive ones (Helton, 2008). And in Labrador Retrievers, post-play training also improved training performance (Affenzeller, Palme, and Zulch, 2017; Affenzeller, 2020). Dogs’ body language during operant conditioning was also related to their success rate in learning (Hasegawa, Ohtani, and Ohta, 2014). We also know that dogs performed tasks better and faster the more experience they had with them, not being able to solve the task before seeing it demonstrated by the human administering the task (Albuquerque et al, 2021). Gnanadesikan et al (2020) state that cognitive phenotypes seem to vary by breed, and that these phenotypes have strong potential to be artificially selected, but we have seen that this is an error. Morrill et al (2022) found no evidence that the behavioral tendencies of certain breeds reflected intentional selection by humans but could not discount the possibility.
Conclusion
Dog breeds have been used by hereditarians for decades as a model for that of intelligence differences between human races. The analogy that dog breeds and human races are also similar has been used to show that there is a genetic basis for human race, and that human races are thusly a biological reality. (Note that I am a pluralist about race.) But we have seen that in the 40s the study which was undertaken to prove a hereditary basis to dog intelligence and then liken it to human intelligence quite obviously failed. This then led one of the authors to conclude—correctly—that human heritability estimates are inflated (which has led to the missing heritability problem of the 2000s).
Upon studying the dogs in their study, they found that there was no general factor of intelligence in these dogs, and that the situation was paramount in how the dog would perform on the task in question. This then led Scott to conclude that human heritability estimates are too high, a conclusion echoed by modern day researchers like Schonemann. The issue is, if dogs with their numerous breeds and genetic variation defy a single general factor, what would that mean for humans? This is just more evidence that “general intelligence” is a mere myth, a statistical abstraction. There was also no evidence for a general temperament, since breeds that were scared in one situation were confident in another (showing yet again that situationism held here). The failure of the study carried out by the RF then led to the questioning of the high heritability of human intelligence (IQ), which wasn’t forgotten as the decades progressed. Nonetheless, this study casted doubt on the claim that intelligence had a genetic basis.
Why, though, would a study of dogs be informative here? Well, the goal was to show that intelligence in dogs had a hereditary component and that thusly a kind of designer dog could be created that was friendly and intelligent, and this could then be likened to humans. But when the results were the opposite of what they desired, the project was quickly abandoned. If only modern-day behavioral geneticists would get the memo that heritability isn’t useful for what they want it to be useful for (Moore and Shenk, 2016)
“Variance explained” (VE) is a statistical concept which is used to quantify the proportion of variance in a trait that can be accounted for or attributed to one or more independent variables in a statistical model. VE is represented by “R squared”, which ranges from 0 to 100 percent. An r2 of 0 percent means that none of the variance in the dependent variable is explained by the independent variable whereas an r2 of 100 percent means that all of the variance is explained. But VE doesn’t imply causation, it merely quantifies the degree of association or predictability between two variables.
So in the world of genetics, heritability and GWAS, the VE concept has been employed as a fundamental measure to quantify the extent to which a specific trait’s variability can be attributed to genetic factors. One may think that it’s intuitive to think that G and E factors can be separated and their relative influences can be seen and disentangled for human traits. But beneath its apparent simplicity lies a philosophically contentious issue, most importantly, due to the claim/assumption that G and E factors can be separated into percentages.
But I think the concept of VE in psychology/psychometrics and GWAS is mistaken, because (1) it implies a causal relationship that may not exist; (2) implies reductionism; (3) upholds the nature-nurture dichotomy; (4) doesn’t account for interaction and epigenetics; and (5) doesn’t account for context-dependency. In this article, I will argue that the concept of VE is confused, since it assumes too much while explaining too little. Overall, I will explain the issues using a conceptual analysis and then give a few arguments on why I think the phrase is confused.
Arguments against the phrase “variance explained”
While VE doesn’t necessarily imply causation, in psychology/psychometrics and GWAS literature, it seems to be used as somewhat of a causal phrase. The phrase also reduces the trait in question to a single percentage, which is of course not accurate—so basically it attempts at reducing T to a number, a percentage.
But more importantly, the notion of VE is subject to philosophical critique in virtue of the implications of what the phrase inherently means, particularly when it comes to the separation of genetic and environmental factors. The idea of VE most often perpetuates the nature-nurture dichotomy, assuming that G and E can be neatly separated into percentages of causes of a trait. Thus this simplistic division between G and E oversimplifies the intricate interplay between genes, environment and all levels of the developmental system and the irreducible interaction between all developmental resources that lead to the reliable ontogeny of traits (Noble, 2012).
Moreover, VE can be reductionist in nature, since it implies that a certain percentage of a trait’s variance can be attributable to genetics, disregarding the dynamic and complex interactions between genes and other resources in the developmental system. Therefore, this reductionism fails to capture the holistic and emergent nature of human development and behavior. So just like the concept of heritability, the reductionism inherent in the concept of VE focuses on isolating the contributions of G and E, rather than treating them as interacting factors that are not reducible.
Furthermore, we know that epigenetics demonstrates that environmental factors can influence gene expression which then blurs the line between G and E. Therefore, G and E are not separable entities but are intertwined and influence each other in unique ways.
It also may inadvertently carry implicit value judgements about which traits or outcomes are deemed desirable or significant. In a lot circles, a high heritability is seen as evidence for the belief that a trait is strongly influenced by genes—however wrong that may be (Moore and Shenk, 2016). Further, it could also stigmatize environmental influences if a trait is perceived as primarily genetic. This, then, could contribute to a bias that then downplays the importance of environmental factors which would then overlook their importance and potential impact in individual development and behavior.
This concept, moreover, doesn’t provide clarity on questions like identity and causality. Even if a high percentage of variance is attributed to genetics, it doesn’t necessarily reveal the causal mechanisms or genetic factors responsible, which then leads to philosophical indeterminancy regarding the nature of causation. Human traits are highly complex and the attempt to quantify them and break then apart into heat percentages or variances explained by G and E vastly oversimplifies the complexity of these traits. This oversimplification then further contributes to philosophical indeterminancy about the nature and true origins (which would be the irreducible interactions between all developmental resources) of these traits.
The act of quantifying variance also inherently involves power dynamics, where certain variables are deemed more significant or influential than others. This, then, introduces a potential bias that may reflect existing societal norms or power structures. “Variance explained” may inadvertently perpetuate and reinforce these power dynamics by quantifying and emphasizing certain factors over others. (Like eg the results of Hill et al, 2019 and Barth, Papageorge, and Thom, 2020 and see Joseph’s critique of these claims). Basically, these differences between people in income and other socially-important traits are due to genetic differences between them. (Even though there is no molecular genetic evidence for the claim made in The Bell Curve that we are becoming more genetically stratified; Conley and Domingue, 2016.)
The concept of VE also implies a kind of predictive precision that may not align with the uncertainty of human behavior. The illusion of certainty created by high r2 values can lead to misplaced confidence in predictions. In reality, the complexity of human traits often defies prediction and overreliance on VE may create a false sense of certainty.
We also have what I call the “veil of objectivity” argument. This argument challenges the notion that VE provides an entirely objective view. Behind the numerical representation lies a series of subjective decisions, like the selection of variables to the interpretation of results. From the initial selection of variables to be studied to the interpretation of their results, researchers exercise subjective judgments which then could introduce biases and assumptions. So if “variance explained” is presumed to offer an entirely objective view of human traits, then the numerical representation represents an objective measure of variance attribution. If, behind this numerical representation, subjective decisions are involved in variable selection and results interpretation, then the presumed objectivity implied by VE becomes a veil masking underlying subjectivity. So if subjective decisions are integral to the process of VE, then the presumed objectivity of the numerical representation serves as a veil concealing the subjective aspects of the research process. So if the veil of objectivity conceals subjective decisions, then there exists a potential for biases and assumptions which then would influence the quantitative analysis. Thus, if biases and assumptions are inherent in the quantitative analysis due to the veil of objectivity, then the objectivity attributed to VE is compromised, and a more critical examination of subjective elements becomes imperative. This argument of course is for “IQ” studies, heritability studies of socially-important human traits and the like, along with GWASs. In interpreting associations, GWASs and h2 studies also fall prey to the veil of objectivity argument, since as seen above, many people would like the hereditarian claim to be true. So when it comes to GWAS and heritability studies, VE refers to the propagation of phenotypic variance attributed to genetic variance.
So the VE concept assumes a clear separation between genetic and environmental factors which is often reductionist and unwarranted. It doesn’t account for the dynamic nature and influence of these influences, nor—of course—the influence of unmeasured factors. The concepts oversimplification can lead to misunderstandings and has ethical implications, especially when dealing with complex human traits and behaviors. Thus, the VE concept is conceptually flawed and should be used cautiously, if at all, in the fields in which it is applied. It does not adequately represent the complex reality of genetic and environmental influences on human traits. So the VE concept is conceptually limited.
If the concept of VE accurately separates genetic and environmental influences, then it should provide a comprehensive and nuanced representation of factors that contribute to a trait. But the concept does not adequately consider the dynamic interactions, correlations, contextual dependencies, and unmeasured variables. So if the concept does not and cannot address these complexities, then it cannot accurately separate genetic and environmental influences. So if a concept can’t accurately separate genetic and environmental influences, then it lacks coherence in the context of genetic and behavioral studies. Thus the concept of VE lacks coherence in the context of genetic and behavioral studies, as it does not and cannot adequately separate genetic and environmental influences.
Conclusion
In exploring the concept of VE and it’s application in genetic studies, heritability research and GWAS, a series of nuanced critiques have been uncovered that challenge its conceptual coherence. The phrase quantifies the proportion of variance in a trait that is attributed to certain variables, typically genetic and environmental ones. The reductionist nature of VE is apparent since it attempts to distill interplay between G and E into percentages (like h2 studies). But this oversimplification neglects the complexity and dynamic nature of these influences which then perpetuates the nature-nurture dichotomy which fails to capture the intricate interactions between all developmental resources in the system. The concepts inclination to overlook G-E interactions, epigenetic influences, and context-dependents variablity further speaks to its limitations. Lastly, normative assumptions intertwined with the concept thenninteouvde ethical considerations as implicit judgments may stigmatize certain traits or downplay the role and importance of environmental factors. Philosophical indeterminancy, therefore, arises from the inability of the concept of VE to offer clarity on identity, causality, and the complex nature of human traits.
So by considering the reductionist nature, the perpetuation of the false dichotomy between nature and nurture, the oversight of G-E interactions, and the introduction of normative assumptions, I have demonstrated through multiple cases that the phrase “variance explained” falls short in providing a nuanced and coherent understanding of the complexities involved in the study of human traits.
In all reality, the issue of this concept is refuted by the fact that the interaction between all developmental resources shows that the separation of the influences/factors is an impossible project, along with the fact that we know that there is no privileged level of causation. Claims of “variance explained”, heritability, and GWAS all push forth the false notion that the relative contributions of genes and environment can be be quantified into the causes of a trait in question. However, we know now that this is false since this is conceptually confused, since the organism and environment are interdependent. So the inseparability of nature and nurture, genes and environment, means that the The ability for GWAS and heritability studies to meet their intended goals will necessarily fall short, especially due to the missing heritability problem. The phrase “variance explained by” implies a direct causal link between independent and dependent variables. A priori reasoning suggests that the intracacies of human traits are probabilistic and context-dependent and it implicated a vast web of bidirectional influences with feedback loops and dynamic interactions. So if the a priori argument advocates for a contextual, nuanced and probabilistic view of human traits, then it challenges the conceptual foundations of VE.
At the molecular level, the nurture/nature debate currently revolves around reactive genomes and the environments, internal and external to the body, to which they ceaselessly respond. Body boundaries are permeable, and our genome and microbiome are constantly made and remade over our lifetimes. Certain of these changes can be transmitted from one generation to the next and may, at times, persist into succeeding generations. But these findings will not terminate the nurture/nature debate – ongoing research keeps arguments fueled and forces shifts in orientations to shift. Without doubt, molecular pathways will come to light that better account for the circumstances under which specific genes are expressed or inhibited, and data based on correlations will be replaced gradually by causal findings. Slowly, “links” between nurture and nature will collapse, leaving an indivisible entity. But such research, almost exclusively, will miniaturize the environment for the sake of accuracy – an unavoidable process if findings are to be scientifically replicable and reliable. Even so, increasing recognition of the frequency of stochastic, unpredictable events ensures that we can never achieve certainty. (Locke and Pallson, 2016)
“Biological systems are complex, non-linear, and non-additive. Heritability estimates are attempts to impose a simplistic and reified dichotomy (nature/nurture) on non-dichotomous processes.” (Rose, 2006)
“Heritability estimates do not help identify particular genes or ascertain their functions in development or physiology, and thus, by this way of thinking, they yield no causal information.” (Panofsky, 2016: 167)
“What is being reported as ‘genetic’, with high heritability, can be explained by difference-making interactions between real people. In other words, parents and children are sensitive, reactive, living beings, not hollow mechanical or statistical units.” (Richardson, 2022: 52)
Introduction
In the world of behavioral genetics, it is claimed that studies of twins, adoptees and families can point us to the interplay between genetic and environmental influences on complex behavioral traits. To study this, they use a concept called “heritability”—taken from animal breeding—which estimates the the degree of variation in a phenotypic trait that is due to genetic variation amongst individuals in the studied population. But upon the advent of molecular genetic analysis after the human genome project, something happened that troubled behavioral genetic researchers: The heritability estimates gleaned from twin, family and adoption studies did not match the estimates gleaned from the molecular genetic studies. This then creates a conundrum—why do the estimates from one way of gleaning heritability don’t match to other ways? I think it’s because biological models represent a simplistic (and false) model of biological causation (Burt and Simon, 2015; Lala, 2023). This is what is termed “missing heritability.” This raises questions that aren’t dissimilar to when a child dissappears.
Imagine a missing child. Imagine the fervor a family and authorities go through in order to find the child and bring them home. The initial fervor, the relentless pursuit, and the agonizing uncertainty constitute a parallel narrative in behavioral genetics, where behavioral geneticists—like the family of a missing child and the authorities—find themselves grappling with unforseen troubles. In this discussion, I will argue that the additivity assumption is false, that this kind of thinking is a holdover from the neo-Darwinian Modern Synthesis, that hereditarians have been told for decades that heritability just isn’t useful for what they want to do, and finally “missing heritability” and missing children are in some ways analogous, but that there is a key difference: The missing children actually existed, while the “missing heritability” never existed at all.
The additivity assumption
Behavioral geneticists pay lip service to “interactions”, but then conceptualize these interactions as due to additive heritability (Richardson, 2017a: 48-49). But the fact of the matter is, genetic interactions create phantom heritability (Zuk et al, 2012). When it comes to the additive claim of heritability, that claim is straight up false.
The additive claim is one of the most important things for the utility of the concept of heritability for the behavioral geneticist. The claim that heritability estimates for a trait are additive means that the contribution of each gene variant is independent and they all sum up to explain the overall heritability (Richardson 2017a: 44 states that “all genes associated with a trait (including intelligence) are like positive or negative charges“). But in reality, gene variants aren’t independent effects, they interact with other genes, the environment and other developmental resources. In fact, violations of the additivity assumption are large (Daw, Guo, and Harris, 2015).
Gene-gene, gene-environment, and environmental factors can lead to overestimates of heritability, and they are non-additive. So after the 2000s with the completion of the human genome project, these researchers realized that the genetic variants that heritability they identified using molecular genetics did not jive with the heritability they computed from twin studies from the 1920s until the late 1990s and then even into the 2020s. So the expected additive contribution of heritability fell short in actually explaining the heritability gleaned from twin studies using molecular genetic data.
Thinking of heritability as a complex jigsaw puzzle may better help to explain the issue. The traditional view of heritability assumes that each genetic piece fits neatly into the puzzle to then complete the overall genetic picture. But in reality, these pieces may not be additive. They can interact in unexpected ways which then creates gaps in our understanding, like a missing puzzle piece. So the non-additive effects of gene variants which includes interactions and their complexities, can be likened to missing pieces in the heritability puzzle. The unaccounted-for genetic interactions and nuances then contribute to what is called “missing heritability.” So just as one may search and search for missing puzzle pieces, so to do behavioral geneticists search and search for the “missing heritability”.
So heritability assumes no gene-gene and gene-environment interaction, no gene-environment correlation, among other false or questionable assumptions. But the main issue, I think, is that of the additivity assumption—it’s outright false and since it’s outright false, then it cannot accurately represent the intricate ways in which genes and other developmental resources interact to form the phenotype.
If heritability estimates assume that genetic influences on a trait are additive and independent, then heritability estimates oversimplify genetic complexity. If heritability estimates oversimplify genetic complexity, then heritability estimates do not adequately account for gene-environment interactions. If heritability does not account for gene-environment interactions, then heritability fails to capture the complexity of trait inheritance. Thus, if heritability assumes that genetic influences on a trait are additive and independent, then heritability fails to capture the complexity of trait inheritance due to its oversimplified treatment of genetic complexity and omission of gene-environment interactions.
One more issue, is that of the “heritability fallacy” (Moore and Shenk, 2016). One commits a heritability fallacy when they assume that heritability is an index of genetic influence on traits and that heritability can tell us anything about the relative contribution of trait inheritance and ontogeny. Moore and Shenk (2016) then make a valid conclusion based on the false belief that heritability us anything about the “genetic strength” on a trait:
In light of this, numerous theorists have concluded that ‘the term “heritability,” which carries a strong conviction or connotation of something “[in]heritable” in the everyday sense, is no longer suitable for use in human genetics, and its use should be discontinued.’31 Reviewing the evidence, we come to the same conclusion. Continued use of the term with respect to human traits spreads the demonstrably false notion that genes have some direct and isolated influence on traits. Instead, scientists need to help the public understand that all complex traits are a consequence of developmental processes.
This tells me one important thing—behavioral geneticists have so much faith in the heritability estimates gleaned from twin studies that they assume that the heritability is “missing” in the newer molecular genetic studies. But if something is “missing”, then that implies that it can be found. They have so much faith that eventually, as samples get higher and higher in GWAS and similar studies, that we will find the heritability that is missing and eventually, be able to identify genetic variants responsible for traits of interest such as IQ. However I think this is confused and a simple analogy will show why.
When a child goes missing, it is implied that they will be found by authorities, whether dead or alive. Now I can liken this to heritability. The term “missing heritability” comes from the disconnect between heritability estimates gleaned from twin studies and heritability estimates gleaned from molecular genetic studies like GWAS. So the implication here is, since twin studies show X percent heritability (high heritability), and molecular genetic studies show Y percent heritability (low heritability) – which is a huge difference between estimates between different tools – then the implication is that there is “missing heritability” that must be explained by rare variants or other factors.
So just like parents and authorities try so hard to find their missing children, so to do behavioral geneticists try so hard to find their “missing heritability.” As families endure anguish as they try to find their children, this is then mirrored in the efforts of behavioral geneticists to try and close the gap between two different kinds of tools that glean heritability.
But there is an important issue at play here—namely the fact that missing children actually exist, but “missing heritability” doesn’t, and that’s why we haven’t found it. Although some parents, sadly, may never find their missing children, the analogy here is that behavioral geneticists will never find their own “children” (their missing heritability) because it simply does not exist.
Spurious correlations
Even increasing the sample sizes won’t do anything, since the larger the sample size, the bigger chance for spurious correlations, and that’s all GWAS studies for IQ are (Richardson and Jones, 2019), while correlations with GWAS are inevitable and meaningless (Richardson, 2017b). Denis Noble (2018) puts this well:
As with the results of GWAS (genome-wide association studies) generally, the associations at the genome sequence level are remarkably weak and, with the exception of certain rare genetic diseases, may even be meaningless (13, 21). The reason is that if you gather a sufficiently large data set, it is a mathematical necessity that you will find correlations, even if the data set was generated randomly so that the correlations must be spurious. The bigger the data set, the more spurious correlations will be found (3). The current rush to gather sequence data from ever larger cohorts therefore runs the risk that it may simply prove a mathematical necessity rather than finding causal correlations. It cannot be emphasized enough that finding correlations does not prove causality. Investigating causation is the role of physiology.
Nor does finding higher overall correlations by summing correlations with larger numbers of genes showing individually tiny correlations solve the problem, even when the correlations are not spurious, since we have no way to find the drugs that can target so many gene products with the correct profile of action.
The Darwinian model
But the claim that there is a line that goes from G (genes) to P (phenotype) is just a mere holdover from the neo-Darwinian modern synthesis. The fact of the matter is, “HBD” and hereditarianism are based on reductionistic models of genes and how they work. But the reality is, genes don’t work how they think they do, reality is much more complex than they assume. Feldman and Ramachandran (2018) ask “Missing compared to what?”, effectively challenging the “missing heritability” claim. As Feldman and Ramachandran (2018) ask, would Herrnstein and Murray have written The Bell Curve if they believed that the heritability of IQ were 0.30? I don’t think they would have. In any case, such a belief in the heritability of IQ being between 0.4 and 0.8 shows the genetic determinist assumptions which are inherent in this type of “HBD” genetic determinist thinking.
Amusingly, as Ned Block (1995) noted, Murray said in an interview that “60 percent of the intelligence comes from heredity” and that that heritability is “not 60 percent of the variation. It is 60 percent of the IQ in any given person.” Such a major blunder from one of the “intellectual spearheads” of the “HBD race realist” movement…
Behavioral geneticists claim that the heritability is missing only because sample sizes are low, and as sample sizes increase, the missing heritability based on associated genes will be found. But this doesn’t follow at all since increasing sample sizes will just increase spurious hits of genes correlated with the trait in question but it says absolutely nothing about causation. Nevertheless, only a developmental perspective can provide us mechanistic knowledge and so-called heritability of a phenotype cannot give us such information because heritability isn’t a mechanistic variable and doesn’t show causation.
Importantly, a developmental perspective provides mechanistic knowledge that can yield practical treatments for pathologies. In contrast, information about the “heritability” of a phenotype—the kind of information generated by twin studies—can never be as useful as information about the development of a phenotype, because only developmental information produces the kind of thorough understanding of a trait’s emergence that can allow for successful interventions. (Moore 2015: 286)
The Darwinian model and it’s assumptions are inherent in thinking about heritability and genetic causation as a whole and are antithetical to developmental, EES-type thinking. Since hereditarianism and HBD-type thinking are neo-Darwinist, it then follows that such thinking is inherent in their beliefs, assumptions, and arguments.
Conclusion
Assumptions of heritability simply do not hold. Heritability, quite simply, isn’t a characteristic of traits but it is a characteristic of “relationships in a population observed in a particular setting” (Oyama, 1985/2000). Heritability estimates tell us absolutely nothing about development, nor the causes of development. Heritability is a mere breeding statistic and tells us nothing at all about the causes of development or whether or not genes are “causal” for a trait in question (Robette, Genin, and Clerget-Darpoux, 2022). It is key to understand that heritability along with the so-called “missing heritability” are based on reductive models of genetics that just do not hold, especially with newer knowledge that we have from systems biology (eg, Noble, 2012).
The assumption that heritability estimates tell us anything useful about genetics, traits, and causes along with a reductive belief in genetic causation for the ontogeny of traits has wasted millions of dollars. Now we need to grapple with the fact that heritability just doesn’t tell us anything about genetic causes of traits, but that genes are necessary, not sufficient, causes for traits because no genes (along with other developmental resources) means no organism. Also coming from twin, family and adoption studies are Turkheimer’s (2000) so-called “laws of behavioral genetics.” Further, the falsity of the EEA (equal environments assumption) is paramount here, and since the EEA is false, genetic conclusions from such studies are invalid (Joseph et al, 2015). There is also the fact that heritability is based on a false biological model. The issue is that heritability rests on a “conceptual model is unsound and the goal of heritability studies is biologically nonsensical given what we now know about the way genes work” (Burt and Simons, 2015: 107). What Richardson (2022) terms “the agricultural model of heritability” is known as false. In fact, the heritability of “IQ” is higher than any heritability found in the animal kingdom (Schonemann, 1997). Why this doesn’t give any researcher pause is beyond me.
Nonetheless, the Darwinian assumptions that are inherent in behavioral genetic, HBD “race realist” thinking are false. And the fact of the matter is, increasing the sample size of molecular genetic studies will only increase the chances of spurious correlations and picking up population stratification. So, it seems that using heritability to show genetic and environmental causes is a bust and has been a bust ever since Jensen revived the race and IQ debate in 1969, along with the subsequent responses that Jensen received against his argument which then led to the 1970s as being a decade in which numerous arguments were made against the concept of heritability (eg, Layzer, 1974).
However, the theory and research discussed across this chapter and previous ones afford the conclusion that no psychological attribute is pre-organized in the genes and unavailable to environmental influence. That is, any alleged genetic difference (or “inferiority”) of African Americans based on the high heritability of intelligence would seem to be an attribution built on a misunderstanding of concepts basic to an appropriate conceptualization of the nature–nurture controversy. An appreciation of the coaction of genes and context—of genes↔context relations—within the relational developmental system, and of the meaning, implications, and limitations of the heritability concept, should lead to the conclusion that the genetic-differences hypothesis of racial differences in IQ makes no scientific sense. (Lerner, 2018: 636)
That heritability doesn’t address mechanisms and ignores genetic factors, along with being inherently reductionist means that there is little to no utility of heritability for humans. And the complex, non-additive, non-linear aspects of biological systems are attempts at reducing biological systems to their component parts, (Rose, 2006), making heritability, again, inherently reductionist. We have to attempt to analyzed causes, not variances (Lewontin, 1974), which heritability cannot do. So it’s very obvious that the hereditarian programme which was revived by Jensen (1969)—and based on twin studies which were first undertaken in the 1920s—is based on a seriously flawed model of genes and how they work. But, of course, hereditarians have an ideological agenda to uphold, so that’s why they continue to pursue “heritability” in order to “prove” that “in part”, racial differences in many socio-behavioral traits—IQ included—are due to genes. But this type of argumentation quite clearly fails.
The fact of the matter is, “there are very good reasons to believe gene variations are at best irrelevant to common disorders and at worst a distraction from the social and political roots of major public health problems generally and of their unequal distribution in particular” (Chaufan and Joseph 2013: 284). (Also see Joseph’s, 2015The Trouble with Twin Studies for more argumentation against the use of heritability and it’s inflation due to false assumptions along with arguments against “missing heritability.”) In fact, claims of “missing heritability” rest on “genetic determinist beliefs, a reliance on twin research, the use of heritability estimates, and the failure to seriously consider the possibility that presumed genes do not exist” (Joseph, 2012). Although it has been claimed that so-called rare variants explain the “missing heritability” (Genin, 2020), this is nothing but cope. So the heritability was never missing, it never existed at all.
Language is the road map of a culture. It tells you where its people come from and where they are going. – Rita May Brown
Communication bridges gaps. The words we use and the languages we speak along with the knowledge that we share serve as a bridge to weave together human culture and intelligence. So imagine a multilingual encyclopedia that encompasses the whole of human knowledge, a book of human understanding from the sciences, the arts, history and philosophy. This encyclopedia is a testament to the universal nature of human knowledge, but it also shows the interplay between culture, language, knowledge and human intelligence.
In my most recent article, I argued that human intelligence is shaped by cultural and social context and that this is shaped by interactions in a cultural and social context. So here I will argue that: there are necessary aspects of knowledge; knowledge is context-dependent; language, culture and knowledge interact with the specific contexts to form intelligence, mind and rationality; and my multilingual encyclopedia analogy shows that while there are what is termed “universal core knowledge”, these would then become context-dependent based on the needs for different cultures and I will also use this example to again argue against IQ. Finally I will conclude that the arguments in this article and the previous one show how the mind is socially formed based on the necessary physical substrates but that the socio-cultural contexts are what is necessary for human intelligence, mindedness, and rationality.
Necessary aspects of knowledge
There are two necessary and fundamental aspects of knowledge and thought—that of cognition and the brain. The brain is a necessary pre-condition for human mindedness, and cognition is influenced by culture, although my framework posits that cognitive processes play a necessary role in human cognition, just as the brain plays a necessary physical substrate for these processes. While cognition and knowledge are intertwined, they’re not synonymous. To cognize is to actively think about something that you want to, meaning it is an action. There is a minimal structure and it’s accounted for by cognition, like pattern recognition, categorization, sequential processing, sensory integration, associative memory and selective attention. And these processes are necessary, they are inherent in “cognition” and they set the stage for more complex mental abilities, which is what Vygotsky was getting at with the social formation of mind with his theory.
Individuals do interpret their experiences through a cultural lense, since culture provides the framework for understanding, categorizing, and making sense of experiences. I recognize the role of individual experiences and personal interpretations. So while cultural lenses may shape initial perceptions, people can also think critically and reflect on their interpretations over time due to the differing experiences they have.
Fundamental necessary aspects of knowledge like sensory perception are also pivotal. By “fundamental”, I mean “necessary”—that is, we couldn’t think or cognize without the brain and it therefore follows we couldn’t think without cognition. These things are necessary for thinking, language, culture and eventually intelligence, but what is sufficient for mind, thinking, language and rationality are the specific socio-cultural interactions and knowledge formulations that we get by being engrossed in linguistically-mediated cultural environments.
The context-dependence of knowledge
“Context-dependent knowledge” refers to information or understanding that can take on different meaning or interpretations based on the specific context in which it is applied or used. But I also mean something else by this: I mean that an individual’s performance on IQ tests is influenced by their exposure to specific cultural, linguistic, and contextual factors. Thus, this means that IQ tests aren’t culture-neutral or universally applicable, but they are biased towards people who share similar class-cultural backgrounds and experiences.
There is something about humans that allow us to be receptive to cultural and social contexts to form mind, language, rationality and intelligence (and I would say that something is the immaterial self). But I wouldn’t call it “innate.” Thus, so-called “innate” traits need certain environmental contexts to be able to manifest themselves. So called “innate” traits are experience-dependent (Blumberg 2018).
So while humans actively adapt, shape, and create cultural knowledge through cultural processes, knowledge acquisition isn’t solely mediated by culture. Individual experiences matter, as do interactions with the environment along with the accumulation of knowledge from various cultural contexts. So human cognitive capacity isn’t entirely a product of culture, and human cognition allows for critical thinking, creative problem solving, along with the ability to adapt cultural knowledge.
Finally, knowledge acquisition is cumulative—and by this, I mean it is qualitatively cumulative. Because as individuals acquire knowledge from their cultural contexts, individual experiences etc, this knowledge then becomes internalized in their cognitive framework. They can then build on thus existing knowledge to further adapt and shape culture.
The statement “knowledge is context-dependent” is a description of the nature of knowledge itself. It means that knowledge can take on different meaning or interpretations in different contexts. So when I say “knowledge is context-dependent”, I am acknowledging that it applies in all contexts, I’m discussing the contextual nature of knowledge itself.
Examples of the context-dependence of universal knowledge for example, are how English-speakers use the “+” sign for addition, while the Chinese have “加” or “Jiā”. So while this fundamental principle is the same, these two cultures have different symbols and notations to signify the operation. Furthermore, there are differences in thinking between Eastern and Western cultures, where thinking is more analytic in Western cultures and more holistic in Eastern cultures (Yates and de Oliveira, 2016; also refer to their paper for more differences between cultures in decision-making processes). There are also differences between cultures in visual attention (Jurkat et al, 2016). While this isn’t “knowledge” per se, it does attest to how cultures are different in their perceptions and cognitive processes, which underscores the broader idea that cognition, including visual attention, is influenced by cultural contexts and social situations. Even the brain’s neural activity (the brain’s physiology) is context-dependent—thus culture is context-dependent (Northoff, 2013).
But when it comes to culture, how does language affect the meaning of culture and along with it intelligence and how it develops?
Language, culture, knowledge,and intelligence
Language plays a pivotal role in shaping the meaning of culture, and by extension, intelligence and its development. Language is not only a way to communicate, but it is also a psychological tool that molds how we think, perceive and relate to the world around us. Therefore, it serves as the bridge between individual cognition and shares cultural knowledge, while acting as the interface through which cultural values and norms are conveyed and internalized.
So language allows us to encode and decode cultural information, which is how, then, culture is generationally transmitted. Language provides the framework for expressing complex thoughts, concepts, and emotions, which enables us to discuss and negotiate the cultural norms that define our societies. Different languages offer unique structures for expressing ideas, which can then influence how people perceive and make sense of their cultural surroundings. And important for this understanding is the fact that a human can’t have a thought unless they have language (Davidson, 1982).
Language is also intimately linked with cognitive development. Under Vygotsky’s socio-historical theory of learning and development, language is a necessary cognitive tool for thought and the development of higher mental functions. So language not only reflects our cognitive abilities, it also plays an active role in their formation. Thus, through social interactions and linguistic exchanges, individuals engage in a dynamic process of cultural development, building on the foundation of their native language and culture.
Feral children and deaf linguistic isolates show this dictum: that there is a critical window in which language could be acquired and thusly the importance of human culture in human development (Vyshedakiy, Mahapatra, and Dunn, 2017). Cases of feral children, then, show us how children would develop without human culture and shows the importance of early language hearing and use for normal brain development. In fact, this shows how social isolation has negative effects on children, and since human culture is inherently social, it shows the importance of human culture and society in forming and nurturing the formation of mind, intelligence, rationality and knowledge.
So the relationship between language, culture and intelligence is intricate and reciprocal. Language allows us to express ourselves and our cultural knowledge while shaping our cognitive processes and influencing how we acquire and express our intelligence. On the other hand, intelligence—as shaped by cultural contexts—contributes to the diversification of language and culture. The interplay underscores how language impacts our understanding of intelligence within it’s cultural framework.
Furthermore, in my framework, intelligence isn’t a static, universally-measureable trait, but it is a dynamic and constantly-developing trait shaped by social and cultural interactions along with individualsm experiences, and so intentionality is inherent in it. Moreover, in the context of acquiring cultural knowledge, Vygotsky’s ZPD concept shows that individuals can learn and internalize things outside of their current toolkit as guided by more knowledgeable others (MKOs). It also shows that learning and development occur mostly in this zone between what someone can do alone and what someone can do with help which then allows them to expand their cognitive abilities and cultural understanding.
Cultural and social exposure
Cultural and social exposure are critical to my conception of intelligence. Because, as we can see in cases of feral children, there is a clear developmental window of opportunity to gain language and to think and act like a human due to the interaction of the individual in human culture. The base cognitive capacities that we are born with and develop throughout infancy to toddlerhood to childhood and then adulthood aren’t just inert, passive things that merely receive information through vision and then we gain minds, intelligence and then become human. Critically, they need to be nurtured through culture and socialization. The infant needs the requisite experiences doing certain things to be able to learn how to roll over, crawl, and finally walk. They need to be exposed to different things in order to be exposed to the culture they were borne into correctly. So while we are born into both cultural, and linguistically-mediated environments, it’s these three types of environment—along with what the individual does themselves when they finally learn to walk, talk, and gain their mind, intelligence and rationality—that shape individual humans, the knowledge they gain and ultimately their intelligence.
If humans possess foundational cognitive capacities that aren’t entirely culturally determined or influenced, and culture serves as a mediator in shaping how these capacities are expressed and applied, then it follows that culture influences cognitive development while cognitive abilities provide the foundation for being able to learn at all, as well as being able to speak and to internalize the culture and language they are exposed to. So if culture interacts dynamically with cognitive capacities, and crucial periods exist during which cultural learning is particularly influential (cases of feral children), then it follows that early cultural exposure and socialization are critical. So it follows that my framework acknowledges both cognitive capacities and cultural influences in shaping human cognition and intelligence.
In his book Vygotsky and the Social Formation of Mind, Wertsch (1985) noted that Vygotsky didn’t discount the role of biology (like in development in the womb), but that after a certain point, biology no longer can be viewed as the sole or even primary factor in force of change for the individual, and that the explanation necessarily shifts to a sociocultural explanation:
However, [Vygotsky] argued that beyond a certain point in development, biological forces can no longer be viewed as the sole, or even the primary, force of change. At this point there is a fundamental reorganization of the forces of development and a need for a corresponding reorganization in the system of explanatory principles. Specifically, in Vygotsky’s view the burden of explanation shifts from biological to social factors. The latter operate within a given biological framework and must be compatible with it, but they cannot be reduced to it. That is, biological factors are still given a role in this new system, but they lose their role as the primary force of change. Vygotsky contrasted embryological and psychological development on this basis:
The embryological development of the child … in no way can be considered on the same level as the postnatal development of the child as a social being. Embryological development is a completely unique type of development subordinated to other laws than is the development of the child’s personality, which begins at birth. Embryological development is studied by an independent science—embryology, which cannot be considered one of the chapters of psychology … Psychology does not study heredity or prenatal development as such, but only the role and influence of heredity and prenatal development of the child in the process of social development. ([Vygotsky] 1972, p. 123)
The multilingual encyclopedia
Imagine a multilingual encyclopedia that encompasses knowledge of multiple disciplines from the sciences to the humanities to religion. This encyclopedia has what I term universal core knowledge. This encyclopedia is maintained by experts from around the world and is available in many languages. So although the information in the encyclopedia is written in different languages and upheld by people from different cultures, fundamental scientific discoveries, historical events and mathematical theorems remain constant across all versions of the encyclopedia. So this knowledge is context-independent because it holds true no matter the language it’s written in or the cultural context it is presented in. But the encyclopedia’s entries are designed to be used in specific contexts. The same scientific principles can be applied in labs across the world, but the specific experiments, equipment and cultural practices could vary. Moreover, historical events could be studied differently in different parts of the world, but the events themselves are context-independent.
So this thought experiment challenges the claim that context-independent knowledge requires an assertion of absolute knowledge. Context-independent knowledge exists in the encyclopedia, but it isn’t absolute. It’s merely a collection of universally-accepted facts, principles and theories that are applied in different contexts taking into account linguistic and cultural differences. Thus the knowledge in the encyclopedia is context-independent in that it remains the same across the world, across languages and cultures, but it is used in specific contexts.
Now, likening this to IQ tests is simple. When I say that “all IQ tests culture-bound, and this means that they’re class-specific”, this is a specific claim. What this means, in my view, is that people grow up in different class-cultural environments, and so they are exposed to different knowledge bases and kinds of knowledge. Since they are exposed to different knowledge bases and kinds of knowledge, when it comes time for test time, if they aren’t exposed to the knowledge bases and kinds of knowledge on the test, they necessarily won’t score as high as someone who was immersed in the knowledge bases and kinds of knowledge. Cole’s (2002) argument that all tests are culture-bound is true. Thus IQ tests aren’t culture-neutral, they are all culture-bound, and culture-neutral tests are an impossibility. This further buttresses my argument that intelligence is shaped by the social and cultural environment, underscoring the idea that the specific knowledge bases and cognitive resources that individuals are exposed to within their unique socio-cultural contexts play a pivotal role in the expression and development of their cognitive abilities.
IQ tests are mere cultural artifacts. So IQ tests, like the entries in the multilingual encyclopedia, are not immune to cultural biases. So although the multilingual encyclopedia has universal core knowledge, the way that the information is presented in the encyclopedia, like explanations and illustrations, would be culturally influenced by the authors/editors of the encyclopedia. Remember—this encyclopedia is an encyclopedia of the whole of human knowledge written in different languages, seen through different cultural lenses. So different cultures could have ways of explaining the universal core knowledge or illustrating the concepts that are derived from them.
So IQ tests, just like the entries in the encyclopedia, are only usable for certain contexts. While the entries in the encyclopedia could be usable for more than one context of idea one has, there is a difference for IQ testing. The tests are created by people from a narrow social class and so the items on them are therefore class-specific. This then results in cultural biases, because people from different classes and cultures are exposed to varying different knowledge bases, so people will be differentially prepared for test-taking on this basis alone. So the knowledge that people are exposed to based on their class membership or even different cultures within America or even from an immigrant culture would influence test scores. So while there is universal core knowledge, and some of this knowledge may be on IQ tests, the fact is that different classes and cultures are exposed to different knowledge bases, and so that’s why they score differently—the specific language and numerical skills on IQ tests are class-specific (Brito, 2017). I have noted how culturally-dependent IQ tests are for years, and this interpretation is reinforced when we consider knowledge and its varying interpretations found in the multilingual encyclopedia, which then highlights the intricate relationship between culture, language, and IQ. This then serves to show that IQ tests are mere knowledge tests—class-specific knowledge tests (Richardson, 2002).
So my thought experiment shows that while there are fundamental scientific discoveries, historical events and mathematical theorems that remain constant throughout the world and across different languages and cultures, the encyclopedia’s entries are designed to be used in specific contexts. So the multilingual encyclopedia thought experiment supports my claim that even when knowledge is context-independent (like that of scientific discoveries, historical facts), it can become context-dependent when it is used and applied within specific cultural and linguistic contexts. This, then, aligns with the part of my argument that knowledge is not entirely divorced from social, cultural and contextual influences.
Conclusion
The limitations of IQ tests become evident when we consider how individuals produce and acquire knowledge and the cultural and linguistic diversity and contexts that define our social worlds. The analogy of the multilingual encyclopedia shows that while certain core principles remain constant, the way that we perceive and apply knowledge is deeply entwined within the cultural and social contexts in which we exist. This dynamic relationship between culture, language, knowledge and intelligence, then, underscores the need to recognize the social formation of mind and intelligence.
Ultimately, human socio-cultural interactions, language, and the knowledge we accumulate together mold our understanding of intelligence and how we acquire it. The understanding that intelligence arises through these multifaceted exchanges and interactions within a social and cultural framework points to a more comprehensive perspective. So by acknowledging the vital role of culture and language in the formation of human intelligence, we not only deconstruct the limitations of IQ tests, but we also lay the foundation for a more encompassing way of thinking about what it truly means to be intelligent, and how it is shaped and nurtured by our social lives in our unique cultural contexts and the experiences that we have.
Thus, to truly grasp the essence of human intelligence, we don’t need IQ tests, and we certainly don’t need claims like genes causing IQ or psychological traits and this then is what makes certain people or groups more intelligent than others; we have to embrace the fact that human intelligence thrives within the web of social and cultural influences and interactions which then collectively form what we understand as the social formation of mind.
In the disciplines of psychology and psychometrics, intelligence has long been the subject of study, attempting to reduce intelligence to a number based on what a class-biased test spits out when an individual takes an IQ test. But what if intelligence resisted quantification, and we can’t state that IQ tests can put a number to one’s intelligence? The view I will present here will conceptualize intelligence as a psychological trait, and since it’s a psychological trait, it’s then resistant to being reduced to anything physical and it’s also resistant to quantification. I will draw on Vygotsky’s socio-cultural theory of learning and development and his emphasis on the role of culture, social interactions and cultural tools in shaping intelligence and then I will explain that Vygotsky’s theory supports the notion that intelligence is socially and contextually situated. I will then draw on Ken Richardson’s view that intelligence is a socially dynamic trait that’s irreducible, created by sociocultural tools.
All in all, the definition that I will propose here will be irrelevant to IQ. Although I do conceptualize psychological traits as irreducible, it is obvious that IQ tests are class-specific knowledge tests—that is they are biased against certain classes and so it follows that they are biased for certain classes. But the view that I will articulate here will suggest that intelligence is a complex and multifaceted construct that is deeply influenced by cultural and social factors and that it resists quantification because intentionality is inherent in it. And I don’t need to posit a specified measured object, object of measurement and measurement unit for my conception because I’m not claiming measurability.
Vygotsky’s view
Vygotsky is most well-known for his concepts of private speech, more knowledgeable others, and the zone of proximal development (ZPD). Intelligence involves the internalization of private speech, where individuals engage in a self-directed dialogue to solve problems and guide their actions. This internalized private speech then represents an essential aspect of one’s cognitive development, and reflects an individual’s ability to think and reason independently.
Intelligence is then nurtured through interactions with more knowledgeable others (MKOs) in a few ways. MKOs are individuals who possess a deeper understanding or expertise in specific domains. MKOs provide guidance, support, and scaffolding, helping individuals to reach higher levels of cognitive functioning and problem solving.
Along with MKOs, the ZPD is a crucial aspect in understanding intelligence. It represents a range of tasks that individuals can’t perform independently, but can achieve with guidance and support—it is the “zone” where learning and cognitive development take place. e. So intelligence isn’t only about what one can do alone, but also what one can achieve with the assistance of a MKO. Thus, in this context, intelligence is seen as a dynamic process of development where individuals continuously expand their ZPD through sociocultural interactions. So MKOs play a pivotal role in facilitating learning and cognitive development by providing the necessary help to individuals within their ZPD. The ZPD concept underscores the fact and idea that learning is most effective when it is in this zone, where the learner is neither too challenged or too comfortable, but is then guided by a MKO to reach higher levels of competence in what they’re learning.
So the takeaway from this discussion is this: Intelligence isn’t merely a product of individual cognitive abilities, but it is deeply influenced by cultural and social interactions. It encompasses the capacity for private speech which demonstrates an individual’s capacity to think and reason independently. It also involves learning and development ad facilitated by MKOs who contribute to an individual cognitive growth. And the ZPD underscores the importance of sociocultural guidance in shaping and expanding an individual’s intelligence, while reflecting the dynamic and collaborative nature of cognitive development within the sociocultural context. So intelligence, as understood here, is inseparable from Vygotsky’s concepts of private speech, more knowledgeable others and the ZPD and it highlights the dynamic interplay between individual cognitive processes and sociocultural interactions in the development of intelligence.
Davidson (1982) stated that “Neither an infant one week old nor a snail is a rational creature. If the infant survives long enough, he will probably become rational, while this is not true of the snail.” And on Vygotsky’s theory, the infant becomes rational—that is, intelligent—by interacting with MKOs, and internalizing private speech when they learn to talk and think in cultural contexts in their ZPD. Infants quite clearly have the capacity to become rational, and they begin to become rational through interactions with MKOs and caregivers who guide their cognitive growth within their ZPD. This perspective, then, highlights the role of social and cultural influences in the development of infant’s intelligence and their becoming rational creatures. Children are born into both cultural and linguistically-mediated environments, which is put well by Vasileva and Balyasnikova (2019):
Based on the conceptualization of cultural tools by Vygotsky (contrary to more traditional socio-cultural schools), it follows that a child can be enculturated from birth. Children are not only born in a human-created environment, but in a linguistically mediated environment that becomes internalized through development.
Richardson’s view
Ken Richardson has been a critic of IQ testing since the 1970s being one editor of the edited volume Race and Intelligence: The Fallacies Behind the Race-IQ Controversy. He has published numerous books critiquing the concept of IQ, most recently Understanding Intelligence (Richardson, 2022). (In fact, Richardson’s book was what cured me of my IQ-ist delusions and set me on the path to DST.) Nonetheless,
Again, these dynamics would not be possible without the co- evolution of interdependencies across levels: between social, cognitive, and aff active interactions on the one hand and physiological and epigenetic processes on the other. As already mentioned, the burgeoning research areas of social neuroscience and social epigenetics are revealing ways in which social/cultural experiences ripple through, and recruit, those processes.
For example, different cognitive states can have different physiological, epigenetic, and immune-system consequences, depending on social context. Importantly, a distinction has been made between a eudaimonic sense of well-being, based on social meaning and involvement, and hedonic well-being, based on individual plea sure or pain. These different states are associated with different epigenetic processes, as seen in the recruitment of different transcription factors (and therefore genes) and even immune system responses.18 All this is part of the human intelligence system.
In that way human evolution became human history. Collaboration among brains and the emergent social cognition provided the conceptual breakout from individual limits. It resulted in the rapid progress seen in human history from original hunter-gatherers to the modern, global, technologiocal society—all on the basis of the same biological system with the same genes.
So intelligence emerges from the specific activities, experiences, and resources that individuals encounter throughout their development. Richardson’s view, too, is a Vygotskian one. And like Vygotsky, he emphasizes the significant cultural and social aspects in shaping human intelligence. He rejects the claim that human intelligence is reducible to a number (on IQ tests), genes, brain physiology etc.
Human intelligence cannot be divorced from the sociocultural context in which it is embedded and operates in. So in this view, intelligence is not “fixed” as the genetic reductionist IQ-ists would like you to believe, but instead it can evolve and adapt over time in response to learning, the environment, and experiences. Indeed, this is the basis for his argument on the intelligent developmental system. Indeed, Richardson (2012) even argues that “IQ scores might be more an index of individuals’ distance from the cultural tools making up the test than performance on a singular strength variable.” And due to what we know about the inherent bias in the items on IQ tests (how they’re basically middle-class cultural knowledge tests), it seems that Richardson is right here. Richardson (1991; cf 2001) even showed that when Raven’s progressive matrices items were couched in familiar contexts, the children were able to complete them, even when the same exact rules were there between Richardson’s re-built items and the abstract Raven’s items. This shows that couching items in cultural context even with the same rules as the Raven shows that cultural context matters for these kinds of items.
Returning the concept of cultural tools that Richardson brought up in the previous quote (which is derived from Vygotsky’s theory), cultural tools encompass language, knowledge, and problem solving abilities which are culturally-specific and influenced by that culture. These tools are embedded in IQ tests, influencing the problems presented and the types of questions. Thus, it follows that if one is exposed to different psychological and cultural tools (basically, if one is exposed to different knowledge bases of the test), then they will score lower on a test compared to another person whom is exposed to the item content and structure of the test. So individuals who are more familiar with the cultural references, language patterns, and knowledge will score better than those that don’t. Of course, there is still room here for differences in individual experiences, and these differences influence how individuals approach problem solving on the tests. Thus, Richardson’s view highlights that IQ scores can be influenced by how closely aligned an individual’s experiences are with the cultural tools that are embedded on the test. He has also argued that non-cognitive, cultural, and affective factors explain why individuals score differently on IQ tests, with IQ not measuring the ability for complex cognition (Richardson, 2002; Richardson and Norgate, 2014, 2015).
So contrary to how IQ-ists want to conceptualize intelligence (as something static, fixed, and genetic), Richardson’s view is more dynamic, and looks to the cultural and social context of the individual.
Culture, class, and intelligence
Since I have conceptualized intelligence as a socially embedded and culturally-influenced and dynamic trait, class and culture are deeply intertwined in my conception of intelligence. My definition recognizes that intelligence is culturally-influenced by cultural contexts. Culture provides different tools (cultural and psychological) which then develop and individual’s cognitive abilities. Language is a critical cultural (also psychological) tool which shapes how individuals think and communicate. So intelligence, in my conception and definition, encompasses the ability to effectively use these cultural tools. Furthermore, individuals from different cultures may developm unique problem solving strategies which are embedded in their cultural experiences.
Social class influences access to educational and cultural resources. Higher social classes often have greater access to quality education, books, and cultural experiences and this can then influence and impact an individual’s cognitive development and intelligence. My definition also highlights the limitations of reductionist approaches like IQ tests. It has been well-documented that IQ tests have class-specific knowledge and skills on them, and they also include knowledge and scenarios which are more familiar to individuals from certain social and cultural backgrounds. This bias, then, leads to disparities in IQ scores due to the nature of IQ tests and how the tests are constructed.
A definition of intelligence
Intelligence: Noun
Intelligence, as a noun, refers to the dynamic cognitive capacity—characterized by intentionality—possessed by individuals. It is characterized by a connection to one’s social and cultural context. This capacity includes a wide range of cognitive abilities and skills, reflecting the multifaceted nature of human cognition. This, then, shows that only humans are intelligent since intentionality is a human-specific ability which is due to the fact that we humans are minded beings and minds give rise and allow intentional action.
A fundamental aspect of intelligence is intentionality, which signifies that cognitive processes are directed towards single goals, problem solving, or understanding within the individual’s social and cultural context. So intelligence is deeply rooted in one’s cultural and social context, making it socially embedded. It’s influenced by cultural practices, social interactions, and the utilization of cultural tools for learning and problem solving. So this dynamic trait evolves over time as individuals engage with their environment and integrate new cultural and social experiences into their cognitive processes.
Intelligence is the dynamic capacity of individuals to engage effectively with their sociocultural environment, utilizing a diverse range of cognitive abilities (psychological tools), cultural tools, and social interactions. Richardson’s perspective emphasizes that intelligence is multifaceted and not reducible to a single numerical score, acknowledging the limits of IQ testing. Vygotsky’s socio-cultural theory underscores that intelligence is deeply shaped by cultural context, social interactions, and the use of cultural tools for problem solving and learning. So a comprehensive definition of intelligence in my view—informed by Richardson and Vygotsky—is that of a socially embedded cognitive capacity—characterized by intentionality—that encompasses diverse abilities and is continually shaped by an individual’s cultural and socialinteractions.
In essence, within this philosophical framework, intelligence is an intentional multifaceted cognitive capacity that is intricately connected to one’s cultural and social life and surroundings. It reflects the dynamic interplay of intentionality, cognition and socio-cultural influences. Thus is closely related to the concept of cognition in philosophy, which is concerned with how individuals process information, make sense of the world, acquire knowledge and engage in thought processes.
What IQ-ist conceptions of intelligence miss
The two concepts I’ll discuss are the two most oft-cited concepts that hereditarian IQ-ists talk about—that of Gottfredson’s “definition” of intelligence and Jensen’s attempt at relating g (the so-called general factor of intelligence) to PC1.
Gottfredson’s “definition” is the most-commonly cited one in the psychometric IQ-ist literature:
Intelligence is a very general mental capability that, among other things, involves the ability to reason, plan, solve problems, think abstractly, comprehend complex ideas, learn quickly and learn from experience. It is not merely book learning, a narrow academic skill, or test-taking smarts. Rather, it reflects a broader and deeper capability for comprehending our surroundings-“catching on,” “ making sense” of things, or “figuring out” what to do.
I have pointed out the nonsense that is her “definition” since she says it’s “not merely book learning, a narrow academic skill or test-taking smarts“, yet supposedly, IQ tests “measure” this, and it’s based on… Book learning, is an academic skill and knowledge of the items on the test. That this “definition” is cited as something that is related to IQ tests is laughable. A research paper from OpenAI even cited this “definition” in their paper Sparks of Artifical Intelligence: Early Experiments with GPT4” (Bubeck et al, 2023), but the reference was seemingly removed. Strange…
Spearman “discovered” gin 1903, but his g theory was refuted mere years later. (Nevermind the fact that Spearman saw what he wanted to see in his data; Schlinger, 2003.) In fact, Spearman’s g falsified in 1947 by Thurstone and then again in 1992 by Guttman (Heene, 2008). Then Jensen came along trying to revive the concept, and he likened it to PC1. Here are the steps that show the circularity in Jensen’s conception:
(1) If there is a general intelligence factor “g,” then it explains why people perform well on various cognitive tests.
(2) If “g” exists and explains test performance, the absence of “g” would mean that people do not perform well on these tests.
(3) We observe that people do perform well on various cognitive tests (i.e., test performance is generally positive).
(4) Therefore, since “g” would explain this positive test performance, we conclude that “g” exists.
Nonetheless, Jensen’s g is an unfalsifiable tautology—it’s circular. These are the “best” conceptions of intelligence the IQ-ists have and they’re either self-contradictory nonsense (Gottfredson’s), already falsified (Spearman’s) or unfalsifiable circular tautology (Jensen’s). What makes Spearman’s g even more nonsensical was that he posited g as a mental energy (Jensen, 1999), and more recently it has been proposed that this mental energy can be found in mitochondrial cells (Geary, 2018, 2019, 2020, 2021). Though I have also shown how this is nonsense.
Conclusion
In this article, I have conceptualized intelligence as a socially embedded and culturally-influenced cognitive capacity characterized by intentionality. It is a dynamic trait which encompasses diverse abilities and is continually shaped by an individual’s cultural and social context and social interactions. I explained Vygotsky’s theory and also explained how his three main concepts relate to the definition I have provided. I then discussed Richardson’s view of intelligence (which is also Vygotskian), and showed how IQ tests are merely an index of one’s distance from the cultural tools that are embedded on the IQ test.
In discussing my conception of intelligence, I then contrasted it with the two “best” most oft-cited conceptions of “intelligence” in the psychological/psychometric literature (Gottfredson’s and Spearman’s/Jensen’s). I then showed how they fail. My conception of intelligence isn’t reductionist like the IQ-ists (they try to reduce intelligence/IQ to genes or physiology or brain structure), but it is inherently holistic in recognizing how intelligence develops over the course of the lifespan, from birth to death. My definition recognizes intelligence as a dynamic, changing trait that’s not fixed like the hereditarians claim it is, and in my conception there is no use for IQ tests. At best, IQ tests merely show what kind of knowledge and experiences one was exposed to in their lives due to the cultural tools inherent on the test. So my inherently Vygotskian view shows how intelligence can be conceptualized and then developed during the course of the human lifespan.
Intelligence, as I have conceived of it, is a dynamic and constantly-developing trait, which evolved through our experiences, cultural backgrounds, and how we interact with the world. It is a multifaceted, context-sensitive capacity. Note that I am not claiming that this is measurable, it cannot be reduced to a single quantifiable measure. And since intentionality is inherent in the definition, this further underscores how it resists quantification and measurability.
In sum, the discussions here show that the IQ-ist concept is lacking—it’s empty. And how we should understand intelligence is that of an irreducible, socially and culturally-influenced, dynamic and constantly-developing trait, which is completely at-ends with the hereditarian conception. Thus, I have argued for intelligence without IQ, since IQ “theory” is empty and it doesn’t do what they claim it does (Nash, 1990). I have been arguing for the massive limitations in IQ for years, and my definition here presents a multidimensional view, highlights the cultural and contextual influence, and emphasizes it’s dynamic nature. The same cannot be said for reductionist hereditarian conceptions.
Rene Descartes proposed that the peneal gland was the point of contact—the interface—between the immaterial mind and physical body. He thought that the peneal gland in humans was different and special to that of nonhuman animals, where in humans the peneal gland was the seat of the soul (Finger, 1995). This view was eventually shown to be false. However, claims that the mental can causally interact with the physical (interactionist dualism) have been met with similar criticism. If the mental is irreducible to the physical and if the mental does in fact causally interact with the physical, then the mental must be identical with the physical; that is, the mental is reducible to the physical due to physical laws like conservation of energy. This seems to be an issue for the truth of an interactionist dualist theory. But there are solutions. Deny that causal closure of the physical (CCP) is true (the world isn’t causally closed), or argue that CCP is compatible with interactionist dualism, or argue that CCP is question-begging (assuming in a premise what it seeks to establish and conclude) and assumes without proper justification that all physical events must be due to physical causes, which thereby illogically excludes the possibility of mental causation.
In this article I will provide some reasons to believe that CCP is question-begging, and I will argue that mental causation is invisible (see Lowe, 2008). I will also argue that action potentials are the interface by which the mental and the physical interact and which would then lead a conscious decision to make a movement be possible. I will provide arguments that show that interactionist dualism is consistent with physics, while showing that action potentials are the interface that Descartes was looking for. Ultimately, I will show how the mental interacts with the physical for mental causation to be carried out and how this isn’t an issue for the CCP. The view I will argue for here I will call “cognitive interface dualism” since it centers on the influence of mental states on action potentials and on the physical realm, and it conveys the idea that mental processes interface with physical processes through the conduit of action potentials, without implying a reduction of the mental to the physical, making it a substance dualist position since it still adheres to the mental and the physical as two different substances.
Causal closure of the physical
It is claimed that the world is causally closed—this means that every event or occurrence is due to physical causes, all physical events must be due to physical causes. Basically, no non-physical (mental) factors can cause or influence physical events. Here’s the argument:
(1) Every event in the world has a cause. (2) Causes and effects within the physical world are governed by the laws of physics. (3) Non-physical factors or entities, by definition, don’t belong to the physical realm. (4) If a nonphysical factor were to influence a physical event, it would violate the laws of physics. (5) Thus, the world is causally closed, meaning that all causes and effects in it are governed by physical interactions and laws.
But the issue here for the physicalist who wants to use causal closure is the fact that mental events and states are qualitatively different from physical events and states. This is evidenced in Lowe’s distinction between intentional (mental) and event (physical) causation. Mental states like thoughts and consciousness possess qualitatively different properties than physical states. The causal closure argument assumes that physical events are the only causes of other physical events. But mental states appear to exert causal influence over physical events, for instance voluntary action based on conscious decision, like my action right now to write this article. So if M states do influence P events, then there must be interaction between the mental and physical realms. This interaction contradicts the idea of strict causal closure of the physical realm. Since mental causation is necessary to explain aspects of human action and consciousness, it then follows that the physical world may not be causally closed.
The problem of interaction for interactionist dualism is premised on the CCP. It supposedly violated the conservation of energy (CoE). If P energy is needed to do P work, then a convergence of mental into physical energy then results in an increase in energy that is inexplicable. I think there are many ways to attack this supposed knock-down argument against interactionist dualism, and I will make the case in an argument below, arguing that action potentials are where the brain and the mind interact to carry out intentions. However, there are no strong, non-question begging arguments for causal closure that don’t beg the question (eg see Bishop, 2005; Dimitrijevic, 2010; Gabbani, 2013; Gibb, 2015), and the inductive arguments commit a sampling error or non-sequiturs (Buhler, 2020). So the CCP is either question-begging or unsound (Menzies, 2015). I will discuss this issue before concluding this article, and I will argue that my argument that APs serve as the interface between the mental and the physical, along with the question-beggingness of causal closure actually strengthens my argument.
The argument for action potentials as the interface between the mind and the brain
The view that I will argue for here, I think, is unique and has never been argued for in the philosophical literature on mental causation. In the argument that follows, I will show how arguing that action potentials (APs) are the point of contact—the interface—between the mind and brain doesn’t violate the CCP nor does it violate CoE.
But the skeletal muscle will not contract unless the skeletal muscles are stimulated. The nervous system and the muscular system communicate, which is called neural activiation—defined as the contraction of muscle generated by neural stimulation. We have what are called “motor neurons”—neurons located in the CNS (central nervous system) which can send impulses to muscles to move them. This is done through a special synapse called the neuromuscular junction. A motor neuron that connects with muscle fibers is called a motor unit and the point where the muscle fiber and motor unit meet is callled the neuromuscular junction. It is a small gap between the nerve and muscle fiber called a synapse. Action potentials (electrical impulses) are sent down the axon of the motor neuron from the CNS and when the action potential reaches the end of the axon, hormones called neurotransmitters are then released. Neurotransmitters transport the electrical signal from the nerve to the muscle.
So action potentials (APs) are carried out at the junction between synapses. So, regarding acetylcholine, when it is released, it binds to the synapses (a small space which separates the muscle from the nerve) and it then binds onto the receptors of the muscle fibers. Now we know that, in order for a muscle to contract, the brain sends the chemical message (acetylcholine) across synapses which then initiates movement. So, as can be seen from the diagram above, the MMC refers to the chemo-electric connection between the motor cortex, the cortico-spinal column, peripheral nerves and the neuromuscular junction. A neuromuscular junction is a synapse formed by the contact between a motor neuron and a muscle fiber.
This explanation will set the basis for my argument on how action potentials are the interface—the point of contact—by which the mind and brain meet.
As I have already shown, APs are electrochemical events that transmit signals within the nervous system and are generated as the result of neural activity which can be influenced by mental states like thoughts and intentions. The brain operates in accordance with physical laws and obeys the CoE, the initiation of APs could be (and are, though not always) influenced by mental intentions and processes. Mental processes could modulate the threshold or likelihood of AP firing through complex biomechanical mechanisms that do not violate the CoE. Of course, the energy that is required for generating APs ultimately derives from metabolic processes within the body, which could be influenced by mental states like attention, intention and emotional states. This interaction between mental states does not violate the CoE, nor does it require a violation of the laws of physics, since it operates within the bounds of biochemical and electrochemical processes that respect the CoE. Therefore, APs serve as the point of controlled interaction between the mental and physical realms, allowing for mental causation without disrupting the overall energy balance in the physical world.
Lowe argued that mental causation is invisible, and so since it is invisible, it is not amenable to scientific investigation. This view can be integrated into my argument that APs serve as the interface between the two substances, mental and physical. APs are observable electrochemical events in a neuron which could be influenced by mental states. So as I argued above, mental processes could influence or modulate the veneration of APs. When it comes to the invisibility of mental causation, this refers to the idea that mental events like thoughts, intentions, and consciousness are not directly perceptible like physical objects or events are. Mental states are not observable in the same way that physical events or objects are. In my view, APs hold a dual role. They function as the interface between the mental and the physical, providing the means by which the mental can influence physical events while shaping APs, and they also act as the causal mechanism in connecting mental states to physical events.
Thus, given the distinction between physical events (like APs) and the subjective nature of mental states, the view I have argued for above is consistent with the invisibility of mental causation. Mental causation involves the idea that mental states can influence physical events, and that they have causal efficacy on the physical world. So our mental experiences can lead to physical changes in the world based on the actions we carry out. But since mental states aren’t observable like physical states are, it’s challenging to show how they could lead to effects on the physical world. We infer the influence of mental states on physical events through the effects on observable physical processes. We can’t directly observe intention, we infer it on the basis of one’s action. Mental states could influence physical events through complex chains of electrochemical and biochemical processes which would then make the causative relationship less apparent. So while APs serve as the interface, this doesn’t mean that mental states and APs are identical. This is because while the mental can’t be reduced to physiology (the physical), it encompasses a range of subjective experiences, emotions, thoughts, and intentions that transcend the mechanistic explanations of neural activity.
It is quite obviously an empirical fact that the mental can influence the physical. Think of the fight-or-flight response. When one sees something that they are fearful of (like, say, an animal), there is then a concurrent change in certain hormones. This simple example shows how the mental can have an effect on the physical—where the physical event of seeing something fearful (which would be also be a subjective experience) would then lead to a physical change. So the initial mental event of seeing something fearful is a subjective experience which occurs in the realm of consciousness and mental states. The subjective experience of fear then triggers the fight-or-flight response, which leads to the release of stress hormones like cortisol and adrenaline. These physiological changes are part of the body’s response to a perceived threat based on the subject’s personal subjective experience. So the release of stress hormones is a physical event, and these hormones then have a measurable effect on the body like an increase in heart rate, heightened alertness and energy mobilization which then prepares the subject for action. These physiological changes then prepare the subject to either fight or flee from the situation that caused them fear. This is a solid example on how the mental can influence the physical.
The only way, I think, that my view can be challenged is by arguing that the CCP is true. But if it is question-begging, then my proposition that mental states can influence APs is then less contentious. Furthermore, my argument on APs could be open to multiple interpretations of causal closure. So instead of strictly adhering to causal closure, my view could accommodate various interpretations that allow mental causation to have an effect in the physical realm. Thus, since I view causal closure as question begging, it provides a basis for my view that mental states can influence APs and by extension the physical world. And if the CCP is false, my view on action potentials is actually strengthened.
The view I have argued for here is a simplified perspective on the relationship between the mental and the physical. But my intention isn’t to offer a comprehensive account of all aspects of mental and physical interaction, rather, it is to highlight the role of APs as a point of connection between the mental and physical realms.
Cognitive interface dualism as a form of substance dualism
The view I have argued for here is a substance dualist position. Although it posits an intermediary in APs that facilitates interaction between the mental and physical realms, it still maintains the fundamental duality between mental and physical substances. Mental states are irreducible to physical states, and they interact though APs without collapsing into a single substance. Mental states involve subjective experiences, intentionality, and qualia which are fundamentally different from the objective and quantifiable nature of the physical realm, which I have argued before. APs serve as the bridge—the interface—between the mental and the physical realms, so my dualistic perspective allows for interaction while still preserving the unique properties of the mental and the physical.
Although APs serve as the bridge between the mental and the physical, the interaction between mental states and APs suggests that mental causation operates independently of physical processes. This, then, implies that the self which originates in mental states, isn’t confined to the physical realm, and that it isn’t reducible to the physical. The self’s subjective experiences, consciousness and self-awareness cannot be explained by physical or material processes, which indicates an immaterial substance beyond the physical. The unity of consciousness, which is the integrated sense of self and personal identity over time, are better accounted for by an immaterial self that transcends a change in physical states. Lastly mental states possess qualitative properties like qualia that defy reduction to physical properties. These qualities then, point to a distinct and immaterial self.
My view posits a form of non-reductive mental causation, where mental states influence APs, acknowledging the nonphysical influence on the mental to the physical. Interaction doesn’t imply reduction; mental states remain irreducible even though they impact physical processes. My view also accommodates consciousness, subjectivity, and intentionality which can’t be accounted for by material or physical processes. My view also addresses the explanatory gap between objective physical processes and subjective mental processes, which can’t be accounted for by reduction to physical brain (neural) processes.
Conclusion
The exploration of APs within the context of cognitive interface dualism offers a perspective on the interplay between the mental and physical substances. My view acknowledges APs as the bridge of interaction between the mental and the physical, and it fosters a deeper understanding of the role of mental causation in helping us understand reality.
Central to my view is recognizing that while APs do serve as the interface or conduit by which the mental and the physical interact, and how mental states can influence physical events, this does not entail that the mental is reducible to the physical. My cognitive interface dualism therefore presents a nuanced approach that navigates the interface between the seen and the unseen, the physical and the mental.
Traditional views of causal closure may raise questions about the feasibility of mental causation, the concept’s rigidity is challenged by the intermediary role of APs. While I do hold that the CCP is question-begging, the view I have argued for here explores an alternative avenue which seemingly transcends that limitation. So even if the strict view of the CCP were to fall, my view would remain strong.
This view is also inherently anti-reductionist, asserting that personal identity, consciousness, subjectivity and intentionality cannot be reduced to the physical. Thus, it doesn’t succumb to the traditional limitations of physicalism. Cognitive interface dualism also challenges the notion that we are reducible to our physical brains or our mental activity. The self—the bearer of mental states—isn’t confined to neural circuitry, although the physical is necessary for our mental lives, it isn’t a sufficient condition (Gabriel, 2018).
Lastly, of course this view means that since the mental is irreducible to the physical, then psychometrics isn’t a measurement enterprise. Any argument that espouses the view that the mental is irreducible to the physical would entail that psychometrics isn’t measurement. So by acknowledging that mental states, consciousness, and subjective experiences transcend the confines of physical quantification, cognitive interface dualism dismantles the assumption that the human mind can be measured and encapsulated using numerical metrics. This view holds that the mental resists quantification, since only the physical is quantifiable since only the physical have specified measured objects, objects of measurement and measurement units.
All in all, my view I title cognitive interface dualism explains how mental causation occurs through action potentials. It still holds that the mental is irreducible to the physical, but that the mental and physical interact without M being reduced to P. This view I have espoused, I think, is unique, and it shows how mental causation does occur, it shows how we perform actions.
In the realm of educational assessment and psychometrics, a distinction between IQ and achievement tests needs to be upheld. It is claimed that IQ is a measure of one’s potential learning ability, while achievement tests show what one has actually learned. However, this distinction is not strongly supported in my reading of this literature. IQ and achievement tests are merely different versions of the same evaluative tool. This is what I will argue in this article: That IQ and achievement tests are different versions of the same test, and so any attempt to “validate” IQ tests based not only on other IQ tests, achievement tests and job performance is circular, I will argue that, of course, the goal of psychometrics in measuring the mind is impossible. The hereditarian argument, when it comes to defending their concept and the claim that they are measuring some unitary and hypothetical variable, then, fails. At best, these tests show one’s distance from the middle class, since that’s the where most of the items on the test derive from. Thus, IQ and achievement tests are different versions of the same test and so, they merely show one’s “distance” from a certain kind of class-specific knowledge (Richardson, 2012), due to the cultural and psychologicaltools one must possess to score well on these tests (Richardson, 2002).
Circular IQ-ist arguments
IQ-ists have been using IQ tests since they were brought to America by Henry Goddard in 1913. But one major issue (one they still haven’t solved—and quite honestly never will) was that they didn’t have any way to ensure that the test was construct valid. So this is why, in 1923, Boring stated that “intelligence is what intelligence tests test“, while Jensen (1972: 76) said “intelligence, by definition, is what intelligence tests measure.” However, such statements are circular and they are circular because they don’t provide real evidence or explanation.
Boring’s claim that “intelligence is what intelligence tests test” is circular since it defines intelligence based on the outcome of “intelligence tests.” So if you ask “What is intelligence“, and I say “It’s what intelligence tests measure“, I haven’t actually provided a meaningful definition of intelligence. The claim merely rests on the assumption that “intelligence tests” measure intelligence, not telling us what it actually is.
Jensen’s (1976) claim that “intelligence, by definition, is what intelligence tests measure” is circular for similar reasons to Boring’s since it also defines intelligence by referring to “intelligence tests” and at the same time assumes that intelligence tests are accurately measuring intelligence. Neither claim actually provides an independent understanding of what intelligence is, it merely ties the concept of “intelligence” back to its “measurement” (by IQ tests). Jensen’s Spearman’s hypothesis on the nature of black-white differences has also been criticized as circular (Wilson, 1985). Not only was Jensen (and by extension Spearman) guilty of circular reasoning, so too was Sternberg (Schlinger, 2003). Such a circular claim was also made by Van der Mass, Kan, and Borsboom (2014).
But Jensen seemed to have changed his view, since in his 1998 book The g Factor, he argues that we should dispense with the term “intelligence”, but curiously that we should still study the g factor and assume identity between IQ and g… (Jensen made many more logical errors in his defense of “general intelligence”, like saying not to reify intelligence on one page and then a few pages later reifying it.) Circular arguments have been identified in not only Jensen’s writings Spearman’s hypothesis, but also in using construct validity to validate a measure (Gordon, Schonemann; Guttman, 1992: 192).
The same circularity can be seen when discussions of the correlation between IQ and achievement tests is brought up. “These two tests correlate so they’re measuring the same thing”, is an example one may come across. But the error here is assuming that mental measurement is possible and that IQ and achievement tests are independent of each other. However, IQ and achievement tests are different versions of the same test. This is an example of circular validation, which occurs when a test’s “validity” is established by the test itself, leading to a self-reinforcing loop.
IQ tests are often validated with other older editions of the test. For example, the newer version of the S-B would be “validated” against the older version of the test that the newer version was created to replace (Howe, 1997: 18; Richardson, 2002: 301), which not only leads to circular “validation”, but would also lead to the same assumptions from the older test constructors (like Terman) which would still then be alive in the test itself (since Terman assumed men and women should be equal in IQ and so this assumption is still there today). IQ tests are also often “validated” by comparing IQ test results to outcomes like job performance and academic performance. Richardson and Norgate (2015) have a critical review of the correlation between IQ and job performance, arguing that it’s inflated by “corrections”, while Sackett et al, 2023 show “a mean observed validity of .16, and a mean corrected for unreliability in the criterion and for range restriction of .23. Using this value drops cognitive ability’s rank among the set of predictors examined from 5th to 12th” for the correlation between “general cognitive ability” and job performance.
But this could lead to circular validation, in that if a high IQ is used as a predictor of success in school or work, then success in school or work would be used as evidence in validating the IQ test, which would then lead to a circular argument. The test’s validity is being supported by the outcome that it’s supposed to predict.
Achievement tests are destined to see what one had learned or achieved regarding a certain kind of subject matter. Achievement tests are often validated by correlating test scores with grades or other kinds of academic achievement (which would also be circular). But if high achievement test scores are used to validate the test and those scores are also used as evidence of academic achievement, then that would be circular. Achievement tests are “validated” on their relationship between IQ tests and grades. Heckman and Kautz (2013) note that “achievement tests are often validated using other standardized achievement tests or other measures of cognitive ability—surely a circular practice” and “Validating one measure of cognitive ability using other measures of cognitive ability is circular.” But it should also be noted that the correlation between college grades and job performance 6 or more years after college is only .05 (Armstrong, 2011).
Now what about the claim that IQ tests and achievement tests correlate so they measure the same thing? Richardson (2017) addressed this issue:
For example, IQ tests are so constructed as to predict school performance by testing for specific knowledge or text‐like rules—like those learned in school. But then, a circularity of logic makes the case that a correlation between IQ and school performance proves test validity. From the very way in which the tests are assembled, however, this is inevitable. Such circularity is also reflected in correlations between IQ and adult occupational levels, income, wealth, and so on. As education largely determines the entry level to the job market, correlations between IQ and occupation are, again, at least partly, self‐fulfilling
The circularity inherent in likening IQ and achievement tests has also been noted by Nash (1990). There is no distinction between IQ and achievement tests since there is no theory or definition of intelligence and how, then, this theory and definition would be likened to answering questions correctly on an IQ test.
But how, to put first things first, is the term ‘cognitive ability’ defined? If it is a hypothetical ability required to do well at school then an ability so theorised could be measured by an ordinary scholastic attainment test. IQ measures are the best measures of IQ we have because IQ is defined as ‘general cognitive ability’. Actually, as we have seen, IQ theory is compelled to maintain that IQ tests measure ‘cognitive ability’ by fiat, and it therefore follows that it is tautologous to claim that IQ tests are the best measures of IQ that we have. Unless IQ theory can protect the distinction it makes between IQ/ability tests and attainment/ achievement tests its argument is revealed as circular. IQ measures are the best measures of IQ we have because IQ is defined as ‘general cognitive ability’: IQ tests are the only measures of IQ.
The fact of the matter is, IQ “predicts” (is correlated with) school achievement since they are different versions of the same test (Schwartz, 1975; Beaujean et al, 2018). Since the main purpose of IQ tests in the modern day is to “predict” achievement (Kaufman et al, 2012), then if we correctly identify IQ and achievement tests as different versions of the same test, then we can rightly state that the “prediction” is itself a form of circular reasoning. What is the distinction between “intelligence” tests and achievement tests? They both have similar items on them, which is why they correlate so highly with each other. This, therefore, makes the comparison of the two in an attempt to “validate” one or the other circular.
I can now argue that the distinction between IQ and achievement tests is nonexistent. If IQ and achievement tests are different versions of the same test, then they share the same domain of assessing knowledge and skills. IQ and achievement tests contain similar informational content on them, and so they can both be considered knowledge tests—class-specific knowledge. IQ and achievement tests share the same domain of assessing knowledge and skills. Therefore, IQ and achievement tests are different versions of the same test. Put simply, if IQ and achievement tests are different versions of the same test, then they will have similar item content, and they do so we can correctly argue that they are different versions of the same test.
Moreover, even constructing tests has been criticized as circular:
Given the consistent use of teachers’ opinions as a primary criterion for validity of the Binet and Wechsler tests, it seems odd to claim then that such tests provide “objective alternatives to the subjective judgments of teachers and employers.” If the tests’ primary claim to predictive validity is that their results have strong correlations with academic success, one wonders how an objective test can predict performance in an acknowledged subjective environment? No one seems willing to acknowledge the circular and tortuous reasoning behind the development of tests that rely on the subjective judgments of secondary teachers in order to develop an assessment device that claims independence of those judgments so as to then be able to claim that it can objectively assess a student’s ability to gain the approval of subjective judgments of college professors. (And remember, these tests were used to validate the next generation of tests and those tests validated the following generation and so forth on down to the tests that are being given today.) Anastasi (1985) comes close to admitting that bias is inherent in the tests when he confesses the tests only measure what many anthropologists would called a culturally bound definition of intelligence. (Thorndike and Lohman, 1990)
Conclusion
It seems clear to me that almost the whole field of psychometrics is plagued with the problem of inferring causes from correlation and using circular arguments in an attempt to justify and validate the claim that IQ tests measure intelligence by using flawed arguments that relate IQ to job and academic performance. However this idea is very confused. Moreover, circular arguments aren’t only restricted to IQ and achievement tests, but also in twin studies (Joseph, 2014; Joseph et al, 2015). IQ and achievement tests merely show what one knows, not their learning potential, since they are general knowledge tests—tests of class-specific knowledge. So even Gottfredson’s “definition” of intelligence fails, since Gottfredson presumes IQ to be a measure of learning ability (nevermind the fact that the “definition” is so narrow and I struggle to think of a valid way to operationalize it to culture-bound tests).
The fact that newer versions of tests already in circulation are “validated” against other older versions of the same test means that the tests are circularly validated. The original test (say the S-B) was never itself validated, and so, they’re just “validating” the newer test on the assumption that the older one was valid. The newer test, in being compared to its predecessor, means that the “validation” is occuring on the other older test which has similar principles, assumptions, and content to the newer test. The issue of content overlap, too, is a problem, since some questions or tasks on the newer test could be identical to questions or tasks on the older test. The point is, both IQ and achievement tests are merely knowledge tests, not tests of a mythical general cognitive ability.
The IQ-ists are at it again. This time, PP is claiming that his little tests he created are on an absolute scale—meaning that they have a true 0 point. This has been the Achilles heel of psychometry for many decades. But abstract concepts don’t have true 0 points, and this is why “cognitive measurement” isn’t possible. I will conceptually analyze PP’s arguments for his “spatial intelligence test” and his “verbal intelligence test” and show that they aren’t on absolute scales. I will then use the IQ-ists favorite measurement—temperature (one they try to claim is like IQ)—and show the folly in his reasoning on claiming that these tests are on an absolute scale. I will then discuss the real reasons for score disparities and relate them to social class and one’s life experiences and the argue that the score results reflect merely environmental variables.
Fixed reference points and absolute scales
There are no fixed reference points for “IQ” like there are for temperature. IQ-ists have claimed for decades that temperature is like IQ while thermometers are like IQ tests (Nash, 1990). But I have shown the confused thinking of hereditarians on this issue. An absolute scale requires a fixed reference point or a true 0 point which can be objectively established. Physical quantities like distance, weight, and temperature have natural objective 0 points which can serve as fixed reference points. But nonphysical or abstract concepts lack inherent or universally agreed-upon 0 points which can serve as consistent reference points. So only physical quantities can truly be measured in an absolute scale, since they possess natural 0 points which provide a foundation for measurement.
If “spatial intelligence” is a unitary and objectively measureable cognitive trait, then all individuals’ spatial abilities should consistently align across various tasks. But individuals often exhibit significant variablity in their performance across spatial tasks, excelling in one aspect and not others. This variablity suggests that “spatial intelligence” isn’t a unitary concept. So the concept of a single, unitary, measurable “spatial intelligence” is questionable.
If the test is on an absolute scale for measuring “spatial intelligence”, then the scores obtained directly reflect the inherent “spatial intelligence” of individuals, without being influenced by factors like puzzle complexity, practice, or other variables. The scores are influenced by factors like puzzle complexity and practice effects (like doing similar things in the past). Since the scores are influenced by various factors, then it’s not on an absolute scale.
If a measurement is on an absolute scale, then it should produce consistent results across different contexts and scenarios, reflecting a stable and underlying trait. But cognitive abilities can be influenced by various external factors like stress, fatigue, motivation, and test-taking conditions. These external factors can lead to fluctuations in performance which aren’t indicative of the “trait” that’s attempting to be measured. It’s merely reflective of the circumstances of the moment one took the test in. So the concept of an absolute scale for measuring cognitive abilities fails to account for the impact of external variables which can introduce variability and inaccuracies in the “measurement.” This argument undermines the claim that this—or any test—is on an absolute scale, since motivation, stress and other socio-cognitive factors, like Richardson (2002: 287-288) notes:
the basic source of variation in IQ test scores is not entirely (or even mainly) cognitive, and what is cognitive is not general or unitary. It arises from a nexus of sociocognitive-affective factors determining individuals’ relative preparedness for the demands of the IQ test. These factors include (a) the extent to which people of different social classes and cultures have acquired a specific form of intelligence (or forms of knowledge and reasoning); (b) related variation in ‘academic orientation’ and ‘self-efficacy beliefs’; and (c) related variation in test anxiety, self-confidence, and so on, which affect performance in testing situations irrespective of actual ability.
Such factors, which influence test scores, merely show what one was exposed to in their lives, under my DEC framework. Socio-cognitive factors related to social class could introduce bias, since people from different backgrounds are exposed to different information, have unequal access to information and test prep, along with familiarity with item content. Thus, we can then look at these scores as mere social class surrogates.
If test scores are influenced by stress, anxiety, fatigue, motivation, familiarity, non-cognitive factors, and socio-cognitive factors due to social class, then the concept of an absolute scale for measuring cognitive abilities may not hold true. I have established that test scores can indeed be influenced by myriad external factors. So given that these factors affect test scores and undermine the assumption of an absolute scale, the concept of measuring cognitive ability on such a scale is challenged (don’t forget the irreducibility arguments). Further, the argument that “spatial intelligence” is not measurable on an absolute scale due to its nonphysical nature aligns with this perspective, which further supports the idea that the concept of an absolute scale isn’t applicable in these contexts. Thus, the implications for testing are profound, and so score differences are due to social class and one’s life experiences, nor any kind of “genotypic IQ” (which is an oxymoron).
Regarding vocabulary, this is influenced by the home environment—the types of words one is exposed to as they grow up (and can therefore also be integrated into the DEC). Kids from lower SES families here fewer words at home and in their neighborhoods (low SES children hear 30 million fewer words than higher SES children) (Brito, 2017). We know that word usage is the strongest determinant of child vocabulary growth, and that less educated parents use fewer words with less complex syntax (Perkins, Finegood, and Swain, 2013). The language quality that is addressed to children also matters (Golinkoff et al, 2023). We can then liken this to the Vygotskian More Knowledgeable Other (MKO). An MKO would have the knowledge that their dependent doesn’t. But if the MKO in this instance isn’t educated or low income, then they will use fewer words and they then will have this feature in their home. Such tests merely show what one was exposed to in their lives, not any underlying unitary “thing” like the IQ-ists claim.
Increasing both the amount and diversity of language within the home can positively influence language development, regardless of SES. Repeated exposure to words and phrases increases the child’s opportunity to learn and remember (McGregor, Sheng, & Ball, 2007). The complexity of grammar, the responsiveness of language to the child, and the use of questions all aid language development (Bornstein, Tamis-LeMonda, Hahn, & Haynes, 2008; Huttenlocher, Waterfall, Vasilyeva, Vevea, & Hedges, 2010). Besides frequency of language input, how caregivers communicate with children also affects children’s language skills. Children from higher SES families experience more gestures by their care-givers during parent–child interactions; these SES differences predict vocabulary differences at 54 months of age (Rowe & Goldin-Meadow, 2009). Parent–child interactions provide a context for language exposure and mold the child’s language development. Specific characteristics of the caregiver, including affect, responsiveness, and sensitivity predict children’s early and later language skills (Murray & Hornbaker, 1997; Tamis-LeMonda, Bornstein, Baumwell, & Melstein Damast, 1996). Maternal sensitivity partially explains links between SES and both children’s receptive and expressive language skills at age 3 years (Raviv, Kessenich, & Morrison, 2004). These differences also appear across culture (Mistry, Biesanz, Chien, Howes, & Benner, 2008). Maternal supportiveness partially explained the link between SES and language outcomes at 3 years of age, for both immigrant and native families in the United States. (Brito, 2017: 3-4)
The issue of temperature
This can be illustrated using the IQ-ists favorite (real) measurement—temperature. The Kelvin scale avoids the issues in the first argument. In the Kelvin scale, temperature is measured in relation to absolutel 0 (the point where molecular motion theoretically stops). It doesn’t involve factors like variability in measurement techniques, practice effects, or individual differences. The Kelvin scale has a consistent reference point—absolute 0—which provides a consistent and fixed baseline for temperature measurement. The values in the Kelvin scale are directly tied to a true 0 point.
There are no external influences on the measurement of temperature (beyond that which influences the mercury in the thermometer to move up or down), like the type of thermometer used or one’s familiarity with temperature measurement. External factors like these aren’t relevant to the Kelvin scale, unlike puzzle complexity and practice effects on the spatial abilities test.
Finally, temperature values on the Kelvin scale are universally applicable, which means that a specific temperature corresponds to the same level of molecular motion regardless of who performs the measurement, or what measurement instrument is used. So the Kelvin temperature scale doesn’t have the same issues as PP’s little “spatial intelligence” test. It has a clear and consistent measurement framework, where values directly represent the underlying physical phenomenon of molecular motion without being influenced by external factors or individual differences. When you think about actual, established measurements like temperature and then try to relate them to IQ, then the folly of “mental measurement” reveals itself.
Now, having said all of this, I can draw a parralel between the argument against an absolute scale for cognitive abilities and the concept of temperature.
Temperature measurements, while influenced by external factors (since this is what makes the mercury travel up or down in the thermometer) like atmospheric pressure and humidity, still have an absolute 0 point in the Kelvin scale which represents a complete absence of thermal energy. Unlike “spatial intelligence”, temperature has a fixed reference point which served as an objective 0 point, which allows it to be measured on an absolute scale. The external factors influencing temperature measurement are fundamentally different from the factors which influence one’s performance on a test, since they don’t introduce subjective variations in the same manner. So while temperature is influenced by external factors, it’s measurement is fundamentally different from nonphysical concepts due to the presence of an objective 0 point and the presence and distinct nature of influencing factors. This is put wonderfully by Nash (1990: 131):
First, the idea that the temperature scale is an interval scale is a myth and, second, a scale zero can be established for an intelligence scale by the same method of extrapolation used in defining absolute zero temperature. In this manner Eysenck (p. 16) concludes, ‘if the measurement of temperature is scientific (and who would doubt that it is?) then so is that of intelligence.’ It should hardly be necessary to point out that all of this is special pleading of the most unabashed sort. In order to measure temperature three requirements are necessary: (i) a scale, (ii) some thermometric property of an object and, (iii) fixed points of reference. Zero temperature is defined theoretically and successive interval points are fixed by the physical properties of material objects. As Byerly (p. 379) notes, that ‘the length of a column of mercury is a thermometric property presupposes a lawful relationship between the order of length and the temperature order under certain conditions.’ It is precisely this lawful relationship which does not exist between the normative IQ scale and any property of intelligence. The most obvious problem with the theory of IQ measurement is that although a scale of items held to test ‘intelligence’ can be constructed there are no fixed points of reference. If the ice point of water at one atmosphere fixes 276.16 K, what fixes 140 points of IQ? Fellows of the Royal Society? Ordinal scales are perfectly adequate for certain measurements, Moh’s scale of scratch hardness consists of ten fixed points, from talc to diamond, and is good enough for certain practical purposes. IQ scales (like attainment test scales) are ordinal scales, but this is not really to the point, for whatever the nature of the scale it could not provide evidence for the property IQ or, therefore, that IQ has been measured.
Conclusion
It’s quite obvious that IQ-ists have no leg to stand on, which is why they need to claim that their tests are on absolute scales even when it leads to an absurd conclusion. The fact that test performance is influenced by myriad non-cognitive traits due to one’s social class (Richardson, 2002) shows that these—and all tests—take place in certain cultural contexts, meaning that all tests are culture-bound, as argued by Cole (2004) with his West African Binet argument.
The fact of the matter is, “mental measurement” is impossible, and all these tests do is show the proximity to a certain kind of class-specific knowledge, not any kind of general cognitive “strength”. Taking a Vygotskian perspective on this issue will allow us to see how and why people score differently from each other, and it comes down to their home environment and what they learn in their lives.
Nevertheless, the claims from IQ-ists that they have a specified measured object, object of measurement and measurement unit for IQ or that their tests have a true 0 point are absurd, since these things are properties of physical objects, not non-physical, mental ones. The Vygotskian perspective will allow use to understand score variances between individuals and groups, as I have argued before. We don’t need to claim that there is an absolute scale for cognitive assessment nor do we need to claim that mental measurement is possible for this to be a truism. So, yet again, PP’s argument fails.