
Just-so Stories: The Brain Size Increase
1600 words
The increase in brain size in our species over the last 3 million years has been the subject of numerous articles and books. Over that time period, brain size increased from our ancestor Lucy, all the way to today. Many stories are proposed to explain how and why it exactly happened. The explanation is the same ol’ one: Those with bigger heads, and therefore bigger brains had more children and passed on their “brain genes” to the next generation until all that was left was bigger-brained individuals of that species. But there is a problem here, just like with all just-so stories. How do we know that selection ‘acted’ on brain size and thusly “selected-for” the ‘smarter’ individual?
Christopher Badcock, an evolutionary psychologist, as an intro to EP published in 2001, where he has a very balanced take on EP—noting its pitfalls and where, in his opinion, EP is useful. (Most may know my views on this already, see here.) In any case, Badcock cites R.D. Martin (1996: 155) who writes:
… when the effects of confounding variables such as body size and socio-economic status are excluded, no correlation is found between IQ and brain size among modern humans.
Badcock (2001: 48) also quotes George Williams—author of Adaptation and Natural Selection (1966; the precursor to Dawkins’ The Selfish Gene) where he writes:
Despite the arguments that have been advanced, I cannot readily accept the idea that advanced mental capabilities have ever been directly favored by selection. There is no reason for believing that a genius has ever been likely to leave more children than a man of somewhat below average intelligence. It has been suggested that a tribe that produces an occasional genius for its leadership is more likely to prevail in competition with tribes that lack this intellectual resource. This may well be true in the sense that a group with highly intelligent leaders is likely to gain political domination over less gifted groups, but political domination need not result in genetic domination, as indicated by the failure of many a ruling class to maintain its members.
In Adaptation and Natural Selection, Williams was much more cautious than adaptationists today, stating that adaptationism should be used only in very special cases. Too bad that adaptationists today did not get the memo. But what gives? Doesn’t it make sense that the “more intelligent” human 2 mya would be more successful when it comes to fitness than the “less intelligent” (whatever these words mean in this context) individual? Would a pre-historic Bill Gates have the most children due to his “high IQ” as PumpkinPerson has claimed in the past? I doubt it.
In any case, the increase in brain size—and therefore increase in intellectual ability in humans—has been the last stand for evolutionary progressionists. “Look at the increase in brain size”, the progressionist says “over the past 3mya. Doesn’t it look like there is a trend toward bigger, higher-quality brains in humans as our skills increased?” While it may look like that on its face, in fact, the real story is much more complicated.
Deacon (1990a) notes many fallacies that those who invoke the brain size increase across evolutionary history make, including: the evolutionary progression fallacy; the bigger-is-smarter fallacy; and the numerology fallacy. The evolutionary progression fallacy is simple enough. Deacon (1990a: 194) writes:
In theories of brain evolution, the concept of evolutionary progress finds implicit expression in the analysis of brain-size differences and presumed grade shifts in allometric brain/body size trends, in theories of comparative intelligence, in claims about the relative proportions of presumed advanced vs. primitive brain areas, in estimates of neural complexity, including the multiplication and differentiation of brain areas, and in the assessment of other species with respect to humans, as the presumed most advanced exemplar. Most of these accounts in some way or other are tied to problems of interpreting the correlates of brain size. The task that follows is to dispose of fallacious progressivist notions hidden in these analyses without ignoring the questions otherwise begged by the many enigmatic correlations of brain size in vertebrate evolution.
Of course, when it comes to the bigger-is-smarter fallacy, it’s quite obviously not true that bigger IS always better when it comes to brain size, as elephants and whales have larger brains than humans (also see Skoyles, 1999). But what they do not have more of than humans is cortical neurons (see Herculano-Houzel, 2009). Decon (1990a: 201) describes the numerology fallacy:
Numerology fallacies are apparent correlations that turn out to be artifacts of numerical oversimplification. Numerology fallacies in science, like their mystical counterparts, are likely to be committed when meaning is ascribed to some statistic merely by virtue of its numeric similarity to some other statistic, without supportive evidence from the empirical system that is being described.
While Deacon (1990a: 232) concludes that:
The idea, that there have been progressive trends of brain evolution, that include changes in the relative proportions of different structures (i.e., enlarging more “advanced” areas with respect to more primitive areas) and increased differentiation, interconnection, and overall complexity of neural circuits, is largely an artifact of misunderstanding the complex internal correlates of brain size. … Numerous statistical problems, arising from the difficulty of analyzing a system with so many interdependent scaling relationships, have served to reinforce these misconceptions, and have fostered the tacit assumption that intelligence, brain complexity, and brain size bear a simple relationship to one another.
Deacon (1990b: 255) notes how brains weren’t directly selected for, but bigger bodies (bigger bodies means bigger brains), and this does not lean near the natural selection fallacy theory for trait selection since this view is of the organism, not its trait:
I will argue that it is this remarkable parallelism, and not some progressive selection for increasing intelligence, that is responsible for many pseudoprogressive trends in mammalian brain evolution. Larger whole animals were being selected—not just larger brains—but along with the correlated brain enlargement in each lineage a multitude of parallel secondary internal adaptations followed.
Deacon (1990b: 697-698) notes that the large brain-to-body size ratio in humans compared to other primates is an illusion “a surface manifestation of a complex allometric reorganization within the brain” and that the brain itself is unlikely to be the object of selection. The correlated reorganization of the human brain, to Deacon, is what makes humans unique; not our “oversized” brains for our body. While Deacon (1990c) states that “To a great extent the apparent “progress” of mammalian brain evolution vanishes when the effects of brain size and functional specialization are taken into account.” (See also Deacon, 1997: chapter 5.)
So is there really progress in brain evolution, which would, in effect, lend credence to the idea that evolution is progressive? No, there is no progress in brain evolution; so-called size increases throughout human history are an artifact; when we take brain size and functional specialization into account (functional specialization is the claim that different areas in the brain are specialized to carry out different functions; see Mahon and Cantlon, 2014). Our brains only seem like they’ve increased; when we get down to the functional details, we can see that it’s just an artifact.
Skoyles and Sagan (2002: 240) note that erectus, for example, could have survived with much smaller brains and that the brain of erectus did not arise for the need for survival:
So how well equipped was Homo erectus? To throw some figures at you (calculations shown in the notes), easily well enough. Of Nariokotome boy’s 673 cc of cortex, 164 cc would have been prefrontal cortex, roughly the same as half-brained people. Nariokotome boy did not need the mental competence required by cotemporary hunter-gatherers. … Compared to that of our distant ancestors, Upper Paleolithic technology is high tech. And the organizational skills used in hunts greatly improved 400,000 years ago to 20,000 years ago. These skills, in terms of our species, are recent, occurring by some estimates in less than the last 1 percent of our 2.5 million year existence as people. Before then, hunting skills would have required less brain power, as they were less mentally demanding. If you do not make detailed forward plans, then you do not need as much mental planning abilities as those who do. This suggests that the brains of Homo erectus did not arise for reasons of survival. For what they did, they could have gotten away with much smaller, Daniel Lyon-sized brains.
In any case—irrespective of the problems that Deacon shows for arguments for increasing brain size—how would we be able to use the theory of natural selection to show what was selected-for, brain size or another correlated trait? The progressionist may say that it doesn’t matter which is selected-for, the brain size is still increasing even if the correlated trait—the free-rider—is being selected-for.
But, too bad for the progressionist: If the correlated non-fitness-enhancing trait is being selected-for and not brain size directly, then the progressionist cannot logically state that brain size—and along with it intelligence (as the implication always is)—is being directly selected-for. Deacon throws a wrench into such theories of evolutionary progress in regard to human brain size. Though, looking at erectus, it’s not clear that he really “needed” such a big brain for survival—it seems like he could have gotten away with a much smaller brain. And there is no reason, as George Williams notes, to attempt to argue that “high intelligence” was selected-for in our evolutionary history.
And so, Gould’s Full House argument still stands—there is no progress in evolution; bacteria occupy life’s mode; humans are insignificant to the number of bacteria on the planet, “big brains”, or not.
The Burakumin and the Koreans: The Japanese Underclass and Their Achievement
2350 words
Japan has a caste system just like India. Their lowest caste is called “the Burakumin”, a hereditary caste created in the 17th century—the descendants of tanners and butchers. (Buraku means ‘hamlet people’ in Japanese which took on a new meaning in the Meiji era.) Even though they gained “full rights” in 1871, they were still discriminated against in housing and work (only getting menial jobs). A Burakumin Liberation League has formed, to end discrimination against Buraku in 1922, protesting to end job discrimination by the dominant Ippan Japanese. Official numbers of the number of Buraku in Japan are about 1.2 million, but unofficial numbers bring it up to 6000 communities and 3 million Buraku.
Note the similarities here with black Americans. Black Americans got their freedom from American slavery in 1865. The Burakumin got theirs in 1865. Both groups get discriminated against—the things that the Burakumin face, the blacks in America have faced. De Vos (1973: 374) describes some employment statistics for Buraku and non-Buraku:
For instance, Mahara reports the employment statistics for 166 non-Buraku children and 83 Buraku children who were graduated in March 1859 from a junior high school in Kyoto. Those who were hired by small-scale enterprises employing fewer than ten workers numbered 29.8 percent of the Buraku and 13.1 percent of the non-Buraku children; 15.1 percent of non-Buraku children obtained work in large-scale industries employing more than one thousand workers, whereas only 1.5 percent of Buraku children did so.
Certain Japanese communities—in southwestern Japan—have a belief and tradition in having foxes as pets. Those who have the potential to have such foxes descends down the family line—there are “black” foxes and “white” foxes. So in this area in southwestern Japan, people are classified as either “white” or “black”, and marriage between these artificial color lines is forbidden. They believe that if someone from the “white” family marries someone from the “black” family that every other member of the “white” family becomes “black.”
Discrimination against the Buraku in Japan is so bad, that a 330 page list of Buraku names and community placements were sold to employers. Burakumin are also more likely to join the Yakuza criminal gang—most likely due to such opportunities they miss out on in their native land. (Note similarities between Buraku joining Yakuza and blacks joining their own ethnic gangs.) It was even declared that an “Eta” (the lowest of the Burakumin) was 1/7th of an ordinary person. This is eerily familiar to how blacks were treated in America with the three-fifths compromise—signifying that the population of slaves would be counted as three-fifths in total when being apportioned to votes for the Presidential electors, taxes and other representatives.
Now let’s get to the good stuff: “intelligence.” There is a gap in scores between “blacks”, “whites”, and Buraku. De Vos (1973: 377) describes score differences between “blacks”, “whites” and Buraku:
[Nomura] used two different kinds of “intelligence” tests, the nature of which are unfortunately unclear from his report. On both tests and in all three schools the results were uniform: “White” children averaged significantly higher than children from “black” families, and Buraku children, although not markedly lower than the “blacks,” averaged lowest.
According to Tojo, the results of a Tanaka-Binet Group I.Q. Test administered to 351 fifth- and sixth-grade children, including 77 Buraku children, at a school in Takatsuki City near Osaka shows that the I.Q. scores of the Buraku children are markedly lower than those of the non-Buraku children. [Here is the table from Sternberg and Grigorenko, 2001]
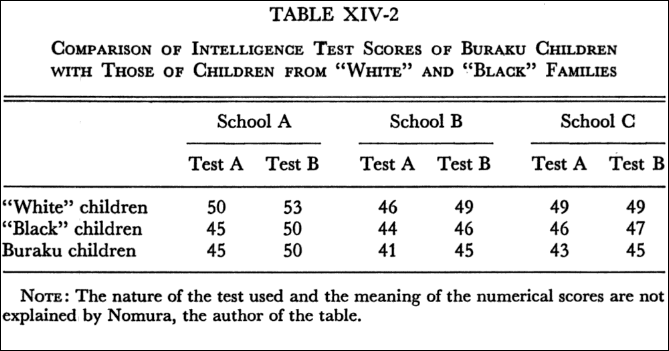
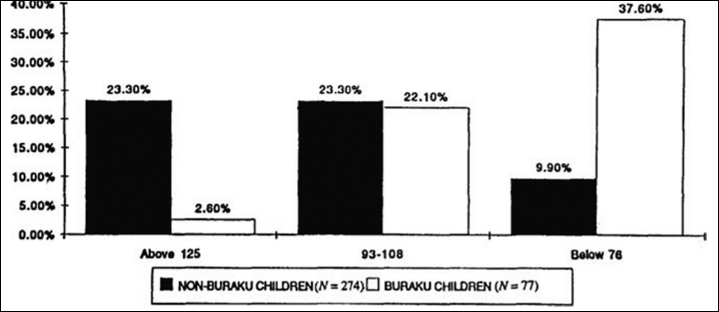
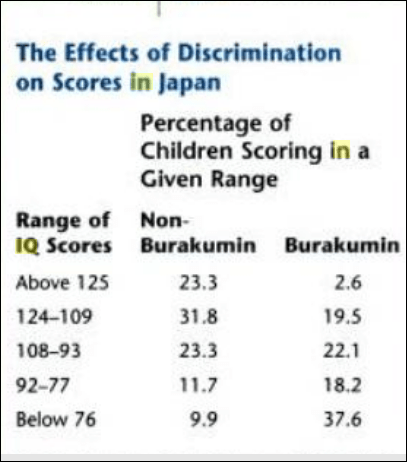
Also see the table from Hockenbury and Hockenbury’s textbook Psychology where they show IQ score differences between non-Buraku and Buraku people:
De Vos (1973: 376) also notes the similarities between Buraku and black and Mexican Americans:
Buraku school children are less successful compared with the majority group children. Their truancy rate is often high, as it is in California among black and Mexican-American minority groups. The situation in Japan also probably parallels the response to education by certain but not all minority groups in the United States.
How similar. There is another group in Japan that is an ethnic minority that is the same race as the Japanese—the Koreans. They came to Japan as forced labor during WWII—about 7.8 million Koreans were conscripted to the Japanese, men participating in the military while women were used as sex slaves. Most are born in Japan and speak no Korean, but they still face discrimination—just like the Buraku. There are no IQ test scores for Koreans in Japan, but there are standardized test scores. Koreans in America are more likely to have higher educational attainment than are native-born Americans (see the Pew data on Korean American educational attainment). But this is not the case in Japan. The following table is from Sternberg and Grigorenko (2001).
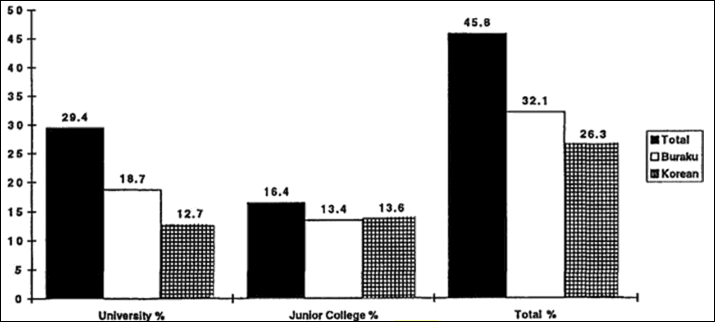
Just as Koreans do better than white Americans on standardized tests (and IQ tests), how weird is it for Koreans in Japan to score lower than ethnic Japanese and even the Burakumin? Sternberg and Grigorenko (2001) write:
Based on these cross-cultural comparison, we suggest that it is the manner in which caste and minority status combine rather than either minority position or low-caste status alone that lead to low cognitive or IQ test scores for low-status groups in complex, technological societies such as Japan and the United States. Often jobs and education require the adaptive intellectual skills of the dominant caste. In such societies, IQ tests discriminate against all minorities, but how the minority groups perform on the tests depends on whether they became minorities by immigration or choice (voluntary minorities) or were forced by the dominant group into minorities status (involuntary minorities). The evidence indicates that immigrant minority status and nonimmigrant status have different implications for IQ test performance.
The distinction between “voluntary” and “involuntary” minority is simple: voluntary minorities emigrate by choice, whereas involuntary minorities were forced against their will to be there. Black Americans, Native Hawaiians and Native Americans are involuntary minorities in America and, in the case of blacks, they face similar discrimination to the Buraku and there is a similar difference in test scores between the high and low castes (classes in America). (See the discussion in Ogbu and Simons (1998) on voluntary and involuntary minorities and also see Shimihara, (1984) for information on how the Burakumin are discriminated against.)
Ogbu and Simons (1988) explain the school performance of minorities using what Ogbu calls a “cultural-ecological theory” which considers societal and school factors along with community dynamics in minority communities. The first part of the theory is that minorities are discriminated against in terms of education, which Ogbu calls “the system.” The second part of the theory is how minorities respond to their treatment in the school system, which Ogbu calls “community forces.” See Figure 1 from Ogbu and Simons (1998: 156):

Ogbu and Simon (1998: 158) write about the Buraku and Koreans:
Consider that some minority groups, like the Buraku outcast in Japan, do poorly in school in their country of origin but do quite well in the United States, or that Koreans do well in school in China and in the United States but do poorly in Japan.
Ogbu (1981: 13) even notes that when Buraku are in America—since they do not look different from the Ippan—they are treated like regular Japanese-Americans who are not discriminated against in America as the Buraku are in Japan and, what do you know, they have similar outcomes to other Japanese:
The contrasting school experiences of the Buraku outcastes in Japan and in the United States are even more instructive. In Japan Buraku children continue massively to perform academically lower than the dominant Ippan children. But in the United States where the Buraku and the Ippan are treated alike by the American people, government and schools, the Buraku do just as well in school as the Ippan (DeVos 1973; Ito,1967; Ogbu, 1978a).
So, clearly, this gap between the Buraku and the Nippon disappears when they are not stratified in a dominant-subordinate relation. It’s because IQ testing and other tests of ability are culture-bound (Cole, 2004) and so, when Burakumin emigrate to America (as voluntary minorities), they are seen as and treated like any other Japanese since there are no physical differences between them and their educational attainment and IQs match the other non-Burakumin Japanese. The very items on these tests are biased towards the dominant (middle-)class—so when the Buraku and Koreans emigrate to America they then have the types of cultural and psychological tools (Richardson, 2002) to do well on the tests and so, their scores change from when they were in their other country.
Note the striking similarities between black Americans and Buraku and Korean-Japanese—all three groups are discriminated against in their countries, all three groups have lower levels of achievement than the majority population, two groups (the Buraku and black Americans, there is no IQ data for Koreans in Japan that I am aware of) show the same gap between them and the dominant group, the Buraku and black Americans got their freedom at around the same times but still face similar types of discrimination. However, when Buraku and Korean-Japanese people emigrate here to America, their IQ scores and educational attainment match that of other East Asian groups. To Americans, there is no difference between Buraku and non-Buraku Japanese people.
Koreans in Japan “endure a climate of hate“, according to The Japan Times. Koreans are heavily discriminated against in Japan. Korean-Japanese people, in any case, score worse than the Buraku. Though, as we all know, when Koreans emigrate to America they have higher test scores than whites do.
Note, though, IQ scores for “voluntary minorities” that came to the US in the 1920s. The Irish, Italians, and even Jews were screened as “low IQ” and were thusly barred entry into the country due to it. For example, Young (1922: 422) writes that:
Over 85 per cent. of the Italian group, more than 80 per cent. of the Polish group and 75 per cent. of the Greeks received their final letter grades from the beta or other performance examination.
While Young (1922) shows the results of an IQ test administered to Southern Europeans in certain areas (one of the studies was carried out in New York City):
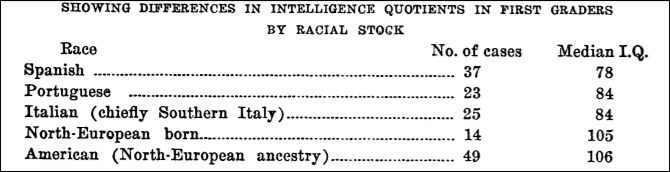


These types of score differentials are just like what these lower castes in Japan and America show today. Though, as Thomas Sowell noted in regard to the IQs of Jews, Polish, Italians, and Greeks:
Like fertility rates, IQ scores differ substantially among ethnic groups at a given time, and have changed substantially over time— reshuffling the relative standings of the groups. As of about World War I, Jews scored sufficiently low on mental tests to cause a leading “expert” of that era to claim that the test score results “disprove the popular belief that the Jew is highly intelligent.” At that time, IQ scores for many of the other more recently arrived groups—Italians, Greeks, Poles, Portuguese, and Slovaks—were virtually identical to those found today among blacks, Hispanics, and other disadvantaged groups. However, over the succeeding decades, as most of these immigrant groups became more acculturated and advanced socioeconomically, their IQ scores have risen by substantial amounts. Jewish IQs were already above the national average by the 1920s, and recent studies of Italian and Polish IQs show them to have reached or passed the national average in the post-World War II era. Polish IQs, which averaged eighty-five in the earlier studies—the same as that of blacks today—had risen to 109 by the 1970s. This twenty-four-point increase in two generations is greater than the current black-white difference (fifteen points). [See also here.]
Ron Unz notes that Sowell says about the Eastern and Southern European immigrants IQs: “Slovaks at 85.6, Greeks at 83, Poles at 85, Spaniards at 78, and Italians ranging between 78 and 85 in different studies.” And, of course, their IQs rose throughout the 20th century. Gould (1996: 227) showed that the average mental age for whites was 13.08, with anything between 8 and 12 being denoted a “moron.” Gould noted that the average Russian had a mental age of 11.34, while the Italian was at 11.01 and the Pole was at 10.74. This, of course, changed as these immigrants acclimated to American life.
For an interesting story for the creation of the term “moron”, see Dolmage’s (2018: 43) book Disabled Upon Arrival:
… Goddard’s invention of [the term moron] as a “signifier of tainted whiteness” was the “most important contribution to the concept of feeble-mindedness as a signifier of racial taint,” through the diagnosis of the menace of alien races, but also as a way to divide out the impure elements of the white race.
The Buraku are a cultural class—not a racial or ethnic group. Looking at America, the terms “black” and “white” are socialraces (Hardimon, 2017)—so could the same reasons for low Buraku educational attainment and IQ be the cause for black Americans’ low IQ and educational attainment? Time will tell, though there are no countries—to the best of my knowledge—that blacks have emigrated to and not been seen as an underclass or ‘inferior.’
The thesis by Ogbu is certainly interesting and has some explanatory power. The fact of the matter is that IQ and other tests of ability are bound by culture, and so, when the Buraku leave Japan and come to America, they are seen as regular Japanese (I’m not aware if Americans know about the Buraku/non-Buraku distinction) and they score just as well if not better than Americans and other non-Buraku Japanese. This points to discrimination and other environmental causes as the root of Buraku problems—noting that the Buraku became “full citizens” in 1871, 6 years after black slavery was ended in America. That Koreans in Japan also have similarly low educational attainment but high in America—higher than native-born Americans—is yet another point in favor of Ogbu’s thesis. The “system” and “community forces” seem to change when the two, previously low-scoring, high-crime group comes to America.
The increase in IQ of Southern and Eastern European immigrants, too, is another point in favor of Ogbu. Koreans and Buraku (indistinguishable from other native Japanese), when they leave Japan, are seen as any other Asians immigrants, and so, their outcomes are different.
In any case, the Buraku of Japan and Koreans who are Japanese citizens are an interesting look into how a group is treated can—and does—decrease test scores and social standing in Japan. Might the same hold true for blacks one day?
Rampant Adaptationism
1500 words
Adaptationism is the main school of evolutionary change, through “natural selection” (NS). That is the only way for adaptations to appear, says the adaptationist: traits that were conducive to reproductive success in past environments were selected-for their contribution to fitness and therefore became fixated in the organism in question. That’s adaptationism in a nutshell. It’s also vacuous and tells us nothing interesting. In any case, the school of thought called adaptationism has been the subject of much criticism, most importantly, Gould and Lewontin (1972), Fodor (2008) and Fodor and Piatteli-Palmarini (2010). So, I would say that adaptationism becomes “rampant” when clearly cultural changes are conflated as having an evolutionary history and are still around today due to being adaptations.
Take Bret Weinstein’s recent conversation with Richard Dawkins:
Weinstein: “Understood through the perspective of German genes, vile as these behaviors were, they were completely comprehensible at the level of fitness. It was abhorrent and unacceptable—but understandable—that Germany should have viewed its Jewish population as a source of resources if you viewed Jews as non-people. And the belief structures that cause people to step onto the battlefields and fight were clearly comprehensible as adaptations of the lineages in question.”
Dawkins: “I think nationalism may be an even greater evil than religion. And I’m not sure that it’s actually helpful to speak of it in Darwinian terms.”
I find it funny that Weinstein is more of a Dawkins-ist than Dawkins himself is (in regard to his “selfish gene theory”, see Noble, 2011). In any case, what a ridiculous claim. “Guys, the Nazis were bad because of their genes and their genes made them view Jews as non-people and resources. Their behaviors were completely understandable at the level of fitness. But, Nazis bad!”
What a ridiculous claim. I like how Dawkins quickly shot the bullshit down. This is just-so storytelling on steroids. I wonder what “belief structures that cause people to step onto battlefields” are “adaptations of the lineages in question”? Do German belief structure adaptations different from any other groups? Can one prove that there are “belief structures” that are “adaptations to the lineages in question”? Or is Weinstein just telling just-so stories—stories with little evidence and that “fit” and “make sense” with the data we have (despicable Nazi behavior towards Jews after WWI and before and during WWII).
There is a larger problem with adaptationism, though: adaptationist confuse adaptiveness with adaptation (a trait can be adaptive without being an adaptation), they overlook nonadaptationist explanations, and adaptationist hypotheses are hard to falsify since a new story can be erected to explain the feature in question if one story gets disproved. That’s the dodginess of adaptationism.
An adaptationist may look at an organism, look at its traits, then construct a story as to why they have the traits they do. They will attempt to think of its evolutionary history by thinking of the environment it is currently in and what the traits in question that it has are useful for now. But there is a danger here. We can create many stories for just one so-called adaptation. How do we distinguish between which stories explain the fixation of the trait and which do not? We can’t: there is no way for us to know which of the causal stories explains the fixation of the trait.
Gould and Lewontin (1972) fault:
the adaptationist programme for its failure to distinguish current utility from reasons for origin (male tyrannosaurs may have used their diminutive front legs to titillate female partners, but this will not explain why they got so small); for its unwillingness to consider alternatives to adaptive stories; for its reliance upon plausibility alone as a criterion for accepting speculative tales; and for its failure to consider adequately such competing themes as random fixation of alleles, production of nonadaptive structures by developmental correlation with selected features (allometry, pleiotropy, material compensation, mechanically forced correlation), the separability of adaptation and selection, multiple adaptive peaks, and current utility as an epiphenomenon of nonadaptive structures.
[…]
One must not confuse the fact that a structure is used in some way (consider again the spandrels, ceiling spaces, and Aztec bodies) with the primary evolutionary reason for its existence and conformation.
Of course, though, adaptationists (e.g., evolutionary psychologists) do confuse structure for function. This is fallacious reasoning. That a trait is useful in a current environment is in no way evidence that it is an adaptation nor is it evidence that that’s why the trait evolved (e.g., a trait being useful and adaptive in a current environment).
But there is a problem with looking to the ecology of the organism in question and attempting to construct historical narratives about the evolution of the so-called adaptation. As Fodor and Piatteli-Palmarini (2010) note, “if evolutionary problems are individuated post hoc, it’s hardly surprising that phenotypes are so good at solving them.” So of course if an organism fails to secure a niche then that means that the niche was not for that organism.
That organisms are so “fit” to their environment, like a puzzle piece to its surrounding pieces, is supposed to prove that “traits are selected-for their contribution to fitness in a given ecology”, and this is what the theory of natural selection attempts to explain. Organisms fit their ecologies because its their ecologies that “design” their traits. So it is no wonder that organisms and their environments have such a tight relationship.
Take it from Fodor and Piatelli-Palmarini (2010: 137):
You don’t, after all, need an adaptationist account of evolution in order to explain the fact that phenotypes are so often appropriate to ecologies, since, first impressions to the contrary notwithstanding, there is no such fact. It is just a tautology (if it isn’t dead) a creature’s phenotype is appropriate for its survival in the ecology that it inhabits.
So since the terms “ecology” and “phenotype” are interdefined, is it any wonder why an organism’s phenotype has such a “great fit” with its ecology? I don’t think it is. Fodor and Piatteli-Palmarini (2010) note how:
it is interesting and false that creatures are well adapted to their environments; on the other hand it’s true but not interesting that creatures are well adapted to their ecologies. What, them, is the interesting truth about the fitness of phenotypes that we require adaptationism in order to explain? We’ve tried and tried, but we haven’t been able to think of one.
So the argument here could be:
P1) Niches are individuated post hoc by reference to the phenotypes that live in said niche.
P2) If the organisms weren’t there, the niche would not be there either.
C) Therefore there is no fitness of phenotypes to lifestyles that explain said adaptation.
Fodor and Piatteli-Palmarini put it bluntly about how the organism “fits” to its ecology: “although it’s very often cited in defence of Darwinism, the ‘exquisite fit’ of phenotypes to their niches is either true but tautological or irrelevant to questions about how phenotypes evolve. In either case, it provides no evidence for adaptationism.”
The million-dollar question is this, though: what would be evidence that a trait is an adaptation? Knowing what we now know about the so-called fit to the ecology, how can we say that a trait is an adaptation for problem X when niches are individuated post hoc? That right there is the folly of adaptationism, along with the fact that it is unfalsifiable and leads to just-so storytelling (Smith, 2016).
Such stories are “plausible”, but that is only because they are selected to be so. When such adaptationism becomes entrenched in thought, many traits are looked at as adaptations and then stories are constructed as to how and why the trait became fixated in the organism. But, just like EP which uses the theory of natural selection as its basis, so too does adaptationism fail. Nevermind the problem of the fitting of species to ecologies to render evolutionary problems post hoc; nevermind the problem that there is no identifying criteria for identifying adaptations; do mind the fact that there is no possible way for natural selection to do what it does: distinguish between coextensive traits.
In sum, adaptationism is a failed paradigm and we need to dispense with it. The logical problems with it are more than enough to disregard it. Sure, the fitness of a phenotype, say, the claws of a mole do make sense in the ecology it is in. But we only claim that the claws of a mole are adaptations after the fact, obviously. One may say “It’s obvious that the claws of a mole are adaptations, look at how it lives!” But this betrays a notion that Gould and Lewontin (1972) made: do not confuse structure with an evolutionary reason for its existence, which, unfortunately, many people do (most glaringly, evolutionary psychologists). Weinstein’s ridiculous claims about Nazi actions during WWII are a great example of how rampant adaptationism has become: we can explain any and all traits as an adaptation, we just need to be creative with the stories we tell. But just because we can create a story that “makes sense” and explains the observation does not mean that the story is a likely explanation for the trait’s existence.
Just-so Stories: MCPH1 and ASPM
1350 words
“Microcephalin, a gene regulating brain size, continues to evolved adaptively in humans” (Evans et al, 2005) “Adaptive evolution of ASPM, a major determinant of cerebral cortical size in humans” (Evans et al, 2004) are two papers from the same research team which purport to show that both MCPH1 and ASPM are “adaptive” and therefore were “selected-for” (see Fodor, 2008; Fodor and Piatteli-Palmarini, 2010 for discussion). That there was “Darwinian selection” which “operated on” the ASPM gene (Evans et al, 2004), that we identified it was selected, along with its functional effect is evidence that it was supposedly “selected-for.” Though, the combination of functional effect along with signs of (supposedly) positive selection do not license the claim that the gene was “selected-for.”
One of the investigators who participated in these studies was one Bruce Lahn, who stated in an interview that MCPH1 “is clearly favored by natural selection.” Evans et al (2005) show specifically that the variant supposedly under selection (MCPH1) showed lower frequencies in Africans and the highest in Europeans.
But, unfortunately for IQ-ists, neither of these two alleles are associated with IQ. Mekel-Boborov et al (2007: 601) write that their “overall findings suggest that intelligence, as measured by these IQ tests, was not detectably associated with the D-allele of either ASPM or Microcephalin.” Timpson et al (2007: 1036A) found “no meaningful associations with brain size and various cognitive measures, which indicates that contrary to previous speculations, ASPM and MCPH1 have not been selected for brain-related effects” in genotyped 9,000 genotyped children. Rushton, Vernon, and Bons (2007) write that “No evidence was found of a relation between the two candidate genes ASPM and MCPH1 and individual differences in head circumference, GMA or social intelligence.” Bates et al’s (2008) analysis shows no relationship between IQ and MCPH1-derived genes.
But, to bring up Fodor’s critique, if MCPH1 is coextensive with another gene, and both enhance fitness, then how can there be direct selection on the gene in question? There is no way for selection to distinguish between the two linked genes. Take Mekel-Bobrov et al (2005: 1722) who write:
The recent selective history of ASPM in humans thus continues the trend of positive selection that has operated at this locus for millions of years in the hominid lineage. Although the age of haplogroup D and its geographic distribution across Eurasia roughly coincide with two important events in the cultural evolution of Eurasia—namely, the emergence and spread of domestication from the Middle East ~10,000 years ago and the rapid increase im population associated with the development of cities and written language 5000 to 6000 years ago around the Middle East—the signifigance of this correlation is not clear.
Surely both of these genetic variants have a hand in the dawn of these civilizations and behaviors of our ancestors; they are correlated, right? Though, they only did draw that from the research studies they reported on—these types of wild speculation are in the papers referenced above. Lahn and his colleagues, though, are engaging in very wild speculation—if these variants are under positive selection, that is.
So it seems that this research and the conclusions drawn from it are ripe for a just-so story. We need to do a just-so story check. Now let’s consult Smith’s (2016: 277-278) seven just-so story triggers:
1) proposing a theory-driven rather than a problem-driven explanation, 2) presenting an explanation for a change without providing a contrast for that change, 3) overlooking the limitations of evidence for distinguishing between alternative explanations (underdetermination), 4) assuming that current utility is the same as historical role, 5) misusing reverse engineering, 6) repurposing just-so stories as hypotheses rather than explanations, and 7) attempting to explain unique events that lack comparative data.
For example, take (1): a theory-driven explanation leads to a just-so story, as Shapiro (2002: 603) notes, “The theory-driven scholar commits to a sufficient account of a phenomenon, developing a “just so” story that might seem convincing to partisans of her theoretical priors. Others will see no more reason to believe it than a host of other “just so” stories that might have been developed, vindicating different theoretical priors.” That these two genes were “selected-for” means that, for Evans et al, it is a theory-driven explanation and therefore falls prey to the just-so story criticism.
Rasmus Nielsen (2009) has a paper on the thirty years of adaptationism after Gould and Lewontin’s (1972) Spandrels paper. In it, he critiques so-called examples of two genes being supposedly selected-for: a lactase gene, and MCPH1 and ASPM. Nielsen (2009) writes of MCPH1 and ASPM:
Deleterious mutations in ASPM and microcephalin may lead to reduced brain size, presumably because these genes are cell‐cycle regulators and very fast cell division is required for normal development of the fetal brain. Mutations in many different genes might cause microcephaly, but changes in these genes may not have been the underlying molecular cause for the increased brain size occurring during the evolution of man.
In any case, Currat et al (2006: 176a) show that “the high haplotype frequency, high levels of homozygosity, and spatial patterns observed by Mekel-Bobrov et al. (1) and Evans et al. (2) can be generated by demographic models of human history involving a founder effect out-of-Africa and a subsequent demographic or spatial population expansion, a very plausible scenario (5). Thus, there is insufficient evidence for ongoing selection acting on ASPM and microcephalin within humans.” McGowen et al (2011) show that there is “no evidence to support an association between MCPH1 evolution and the evolution of brain size in highly encephalized mammalian species. Our finding of significant positive selection in MCPH1 may be linked to other functions of the gene.”
Lastly, Richardson (2011: 429) writes that:
The force of acceptance of a theoretical framework for approaching the genetics of human intellectual differences may be assessed by the ease with which it is accepted despite the lack of original empirical studies – and ample contradictory evidence. In fact, there was no evidence of an association between the alleles and either IQ or brain size. Based on what was known about the actual role of the microcephaly gene loci in brain development in 2005, it was not appropriate to describe ASPM and microcephalin as genes controlling human brain size, or even as ‘brain genes’. The genes are not localized in expression or function to the brain, nor specifically to brain development, but are ubiquitous throughout the body. Their principal known function is in mitosis (cell division). The hypothesized reason that problems with the ASPM and microcephalin genes may lead to small brains is that early brain growth is contingent on rapid cell division of the neural stem cells; if this process is disrupted or asymmetric in some way, the brain will never grow to full size (Kouprina et al, 2004, p. 659; Ponting and Jackson, 2005, p. 246)
Now that we have a better picture of both of these alleles and what they are proposed to do, let’s now turn to Lahn’s comments on his studies. Lahn, of course, commented on “lactase” and “skin color” genes in defense of his assertion that such genes like ASPM and MCPH1 are linked to “intelligence” and thusly were selected-for just that purpose. However, as Nielsen (2009) shows, that a gene has a functional effect and shows signs of selection does not license the claim that the gene in question was selected-for. Therefore, Lahn and colleagues engaged in fallacious reasoning; they did not show that such genes were “selected-for”, while even studies done by some prominent hereditarians did not show that such genes were associated with IQ.
Like what we now know about the FOXP2 gene and how there is no evidence for recent positive or balancing selection (Atkinson et al, 2018), we can now say the same for such other evolutionary just-so stories that try to give an adaptive tinge to a trait. We cannot confuse selection and function as evidence for adaptation. Such just-so stories, like the one described above along with others on this blog, can be told about any trait or gene and explain why it was selected and stabilized in the organism in question. But historical narratives may be unfalsifiable. As Sterelny and Griffiths write in their book Sex and Death:
Whenever a particular adaptive story is discredited, the adaptationist makes up a new story, or just promises to look for one. The possibility that the trait is not an adaptation is never considered.
The “Fade-Out Effect”
2050 words
The “fade-out effect” occurs when interventions are given to children to increase their IQs, such as Head Start (HS) or other similar programs. In such instances when IQ gains are clear, hereditarians argue that the effect of the interventions “washes” away or “fades out.” Thus, when discussing such studies, hereditarians think they are standing in victory. That the effects from the intervention fade away is taken to be evidence for the hereditarian position and is taken to refute a developmental, interactionist position. However, that couldn’t be further from the truth.
Think about where the majority of HS individuals come from—poorer environments and which are more likely to have disadvantaged people in them. Since IQ tests—along with other tests of ability—are experience-dependent, then it logically follows that one who is not exposed to the test items or structure of the test, among other things, will be differentially prepared to take the test compared to, say, middle-class children who are exposed to such items daily.
When it comes to HS, for instance, whites who attend HS are “significantly more likely to complete high school, attend college, and possibly have higher earnings in their early twenties. African-Americans who participated in Head Start are less likely to have been booked or charged with a crime” (Garces, Thomas, and Currie, 2002). Deming (2009) shows many positive health outcomes in those who attend HS. This is beside the case, though (even if we accept the hereditarian hypothesis here, there are still many, many good reasons for programs such as HS).
Just as Protzko (2016) argues that IQ score gains “fade away” after adolescence, so, too, Chetty et al (2011) who write:
Students who were randomly assigned to higher quality classrooms in grades K–3—as measured by classmates’ end-of-class test scores—have higher earnings, college attendance rates, and other outcomes. Finally, the effects of class quality fade out on test scores in later grades, but gains in noncognitive measures persist.
So such gains “faded out”, therefore hereditarianism is a more favorable position, right? Wrong.
Think about test items, and testing as a whole. Then think about differing environments that social classes are in. Now, thinking about test items, think about how exposure to such items and similar questions would have an effect on the test-taking ability of the individual in question. Thus, since tests of ability are experience-dependent, then the logical position to hold is that if they are exposed to the knowledge and experience needed for successful test-taking then they will score higher. And this is what we see when such individuals are enrolled in the program, but when the program ends and the scores decrease, the hereditarian triumphs that it is another piece of the puzzle, another piece of evidence in favor of their position. Howe (1997: 53) explains this perfectly:
It is an almost universal characteristic of acquired competences that when their is a prolonged absence of opportunities to use, practise, and profit from them, they do indeed decline. It would therefore be highly surprising if acquired gains in intelligence did not fade or diminish. Indeed, had the research findings shown that IQs never fade or decline, that evidence would have provided some support for the view that measured intelligence possesses the inherent — rather than acquired — status that intelligence theorists and other writers within the psychometric position have believed it to have.
A similar claim is made by Sauce and Matzel (2018):
In simpler terms, the analysis of Protzko should not lead us to conclude that early intervention programs such as Head Start can have no long-term benefits. Rather, these results highlight the need to provide participants with continuing opportunities that would allow them to capitalize on what might otherwise be transient gains in cognitive abilities.
Now, if we think in the context of the HS and similar interventions, we can see why such stark differences in scores appear, and why some studies show a fade out effect. Such new knowledge and skills (what IQ tests are tests of; Richardson, 2002) are largely useless in those environments since they have little to no opportunity to hone their newly-acquired skills.
Take success in an action video game, weight-lifting, bodybuilding (muscle-gaining), or pole-vaulting. One who does well in any one of these three events will of course have countless of hours of training learning new techniques and skills. They continue this for a while. Then they abruptly stop. They are no longer honing (and practicing) their acquired skills so they begin to lose them. The “fade-out effect” has affected their performance and the reason is due to their environmental stimulation—the same holds for IQ test scores.
I’ll use the issue of muscle-building to illustrate the comparison. Imagine you’re 20 years old and just start going to the gym on a good program. The first few months you get what are termed “newbie gains”, as your body and central nervous system begins to adapt to the new stressor you’re placing on your body. Then after the initial beginning period, at about 2 to 3 months, these gains eventually stop and then you’ll have to be consistent with your training and diet or you won’t progress in weight lifted or body composition. But you are consistent with training and diet and you then have a satisfactory body composition and strength gains.
But then things change you stop going to the gym as often as you did before and you get lazy with your nutrition. Your body composition you worked so hard for along with your strength gains start to dissipate since you’re not placing your body under the stressor it was previously under. But there is something called “muscle memory” which occurs due to motor learning in the central nervous system.
The comparison here is clear: strength is IQ and lifting weights is doing tests/tasks to prepare for the tests (exposure to middle-class knowledge and skills). So when one leaves their “enriching environments” (in this case, the gym and a good nutritional environment), they then lose the gains they worked for. The parallel then becomes clear: leave the enriched environments and return to the baseline. This example I have just illustrated shows exactly how and why these gains “fade out” (though they don’t in all of these types of studies).
One objection to my comparison I can imagine an IQ-ist making is that training for strength (which is analogous to types of interventions in programs like HS), one can only get so strong as, for example, their frame allows, or that there is a limit to which one only get to a certain level of musculature. They may say that one can only get to a certain number of IQ and there, their “genetic potential” maxes out, as it would in the muscle-building and strength-gaining example. But the objection fails. Tests of ability (IQ tests) are cultural in nature. Since they are cultural in nature, then exposure to what’s on the test (middle-class knowledge and skills) will have one score better. That is, IQ tests are experience-dependent, as is body composition and strength, but such tests aren’t (1) construct valid and (2) such tests are biased due to the items selected to be on them. When looking at weights, we have an objective, valid measure. Sure, weight-lifting measures a whole slew of variables including, what it is intended to, strength. But it also measures a whole slew of other variables associated with weight training, dependent on numerous other variables.
Therefore, my example with weights illustrates that if one removes themselves from their enriching environments that allows X, then they will necessarily decline. But due to, in this example, muscle memory, they can quickly return to where they were. Such gains will “fade out” if, and only if, they discontinue their training and meal prep, among other things. The same is true for IQ in these intervention studies.
Howe (1997: 54-55) (this editorial here has the discussion, pulled directly from the book) discusses the study carried out by Zigler and Seitz. They measured the effects of a four year intervention program which emphasized math skills. They were inner-city children who were enrolled in the orgrwm at kindergarten. The program was successful, in that those who participated in the program were two years ahead of a control group, but a few heads after in a follow-up, they were only a year ahead. Howe (1997:54-55) explains why:
For instance, to score well at the achievement tests used with older children it is essential to have some knowledge of algebra and geometry, but Seitz found that while the majority of middle-class children were being taught these subjects, the disadvantaged pupils were not getting the necessary teaching. For that reason they could hardly be expected to do well. As Seitz perceived, the true picture was not one of fading ability but of diminishing use of it.
So in this case, the knowledge gained from the intervention was not lost. Do note, though, how middle-class knowledge continues to appear in these discussions. That’s because tests of ability are cultural in nature since culture-fair impossible (Cole, 2004). Cole imagines a West African Binet who constructs a test of Kpelle culture. Cole (2004) ends up concluding that:
tests of ability are inevitably cultural devices. This conclusion must seem dreary and disappointing to people who have been working to construct valid, culture-free tests. But from the perspective of history and logic, it simply confirms the fact, stated so clearly by Franz Boas half a century ago, that “mind, independent of experience, is inconceivable.”
So, in this case, the test would be testing Kpelle knowledge, and not middle-class cultural skills and knowledge, which proves that IQ tests are bound by culture and that culture-fair (“free”) tests are impossible. This, then, also shows why such gains in test scores decrease: they are not in the types of environments that are conducive to that type of culture-specific knowledge (see some examples of questions on IQ tests here).
The fact is the matter is this: that the individuals in such studies return to their “old” environments is why their IQ gains disappear. People just focus on the scores, say “They decreased”—hardly without thinking why. Why should test scores reflect the efficacy of the HS and similar programs and not the fact that outcomes for children in this program are substantially better than those who did not participate? For example:
HS compared to non-HS children faired better on cognitive and socio-emotive measures having fewer negative behaviors and (Zhai et al, 2011). Adults who were in the HS program are more likely to graduate high school, go to college and receive a seconday degree (Bauer and Schanzenbach, 2016). A pre-school program raised standardized test scores through grade 5. Those who attended HS were less likely to become incarcerated, become teen parents, and are more likely to finish high-school and enroll in college (Barr and Gibs, 2017).
The cause of the fading out of scores is simple: if you don’t use it you lose it, as can be seen with the examples given above. IQ scores can and do increase is evidenced by the Flynn effect, so that is not touched by the fade-out effect. But this “fading-out” (in most studies, see Howe for more information) of scores, in my opinion, is ancillary to the main point: those who attend HS and similar programs do have better outcomes in life than those who did not attend. The literature on the matter is vast. Therefore, the “fading-out” of test scores doesn’t matter, as outcomes for those who attended are better than outcomes for those who do not.
HS and similar programs show that IQ is, indeed, malleable and not “set” or “stable” as hereditarians claim. That IQ tests are experience-dependent implies that those who receive such interventions get a boost, but when they leave their abilities decrease, which is due to not learning any new ones along with returning to their previous, less-stimulating environments. The cause of the “fading-out” is therefore simple: During the intervention they are engrossed in an enriching environment, learning about, by proxy, middle-class knowledge and skills which helps with test performance. But after they’re done they return to their previous environments and so they do not put their skills to use and they therefore regress. Like with my muscle-building example: if you don’t use it, you lose it.
Test Validity, Test Bias, Test Construction, and Item Selection
3400 words
Validity for IQ tests is fleeting. IQ tests are said to be “validated” on the basis of performance with other IQ tests and that of job performance (see Richardson and Norgate, 2015). Further, IQ tests are claimed to not be biased against social class or racial group. Finally, through the process of “item selection”, test constructors make the types of distributions they want (normal) and get the results the want through the subjective procedure of removing items that don’t agree with their pre-conceived notions on who is or is not “intelligent.” Lastly, “intelligence” is descriptive measure, not an explanatory concept, and treating it like an explanatory measure can—and does—lead to circularity (of which is rife in the subject of IQ testing; see Richardson, 2017b and Taleb’s article IQ is largely a psuedoscientific swindle). This article will show that, on the basis of test construction, item analysis (selection and deselection of items) and the fact that there is no theory of what is being measured in so-called intelligence tests that they, in fact, do not test what they purport to.
Richardson (1991: 17) states that “To measure is to give … a more reliable sense of quantity than our senses alone can provide”, and that “sensed intelligence is not an objective quantity in the sense that the same hotness of a body will be felt by the same humans everywhere (given a few simple conditions); what, in experience, we choose to call ‘more’ intelligence, and what ‘less’ a social judgement that varies from people to people, employing different criteria or signals.” Richardson (1991: 17-18) goes on to say that:
Even if we arrive at a reliable instrument to parallel the experience of our senses, we can claim no more for it than that, without any underlying theory which relates differences in the measure to differences in some other, unobserved, phenomena responsible for those differences. Without such a theory we can never be sure that differences in the measure correspond with our sensed intelligence aren’t due to something else, perhaps something completely different. The phenomenon we at first imagine may not even exist. Instead, such verification most inventors and users of measures of intelligence … have simply constructed the source of differences in sensed intelligence as an underlying entity or force, rather in the way that children and naïve adults perceive hotness as a substance, or attribute the motion of objects to a fictitious impetus. What we have in cases like temperature, of course, are collateral criteria and measures that validate the theory, and thus the original measures. Without these, the assumed entity remains a fiction. This proved to be the case with impetus, and with many other naïve conceptions of nature, such as phlogiston (thought to account for differences in health and disease). How much greater such fictions are likely to be unobserved, dynamic and socially judged concepts like intelligence.
Richardson (1991: 32-35) then goes on to critique many of the old IQ tests, in that they had no way of being construct valid, and that the manuals did not even discuss the validity of the test—it was just assumed.
If we do not know what exactly is being measured when test constructors make and administer these tests, then how can we logically state that “IQ tests test intelligence”? Even Arthur Jensen admitted that psychometricians can create any type of distribution they please (1980: 71); he tacitly admits that tests are devised through the selection and deselection of items on IQ tests that correspond to the test constructors preconceived notions on what “intelligence” is. This, again, is even admitted by Jensen (1980: 147-148) who writes “The items must simply emerge arbitrarily from the heads of test constructors.”
We know, to build on Richardson’s temperature example, that we know exactly is what being measured when we look at the amount of mercury in a thermometer. That is, the concept of “temperature” and the instrument to measure it (the thermometer) were verified independently, without circular reliance on the thermometer itself (see Hasok Chang’s 2007 book Inventing Temperature). IQ tests, on the other hand, are, supposedly, “validated” through measures of job performance and correlations with other, previous tests assumed to be (construct) valid—but they were, of course, just assumed to be valid, it was never shown.
For another example (as I’ve shown with IQ many times) of a psychological construct that is not valid is ASD (autism spectrum disorder). Waterhouse, London, and Gilliberg (2016) write that “14 groups of findings reviewed in this paper that together argue that ASD lacks neurobiological and construct validity. No unitary ASD brain impairment or replicated unitary model of ASD brain impairment exists.” That a construct is valid—that is, it tests what it purports to, is of utmost importance to test measurement. Without it, we don’t know if we’re measuring something else completely different from what we hope—or purport—to.
There is another problem: the fact that, for one of the most-used IQ tests that there is no underlying theory of item selection, as seen in John Raven’s personal notes (see Carpenter, Just, and Shell, 1990). Items on the Raven were selected based on Raven’s intuition, and not any formal theory—the same can be said about, of course, modern-day IQ tests. Carpenter, Just, and Shell (1990) write that John Raven “used his intuition and clinical experience to rank order the difficulty of the six problem types . . . without regard to any underlying processing theory.”
These preconceived notions on what “intelligence” is, though, fail without (1) a theory of what intelligence is (which, as admitted by Ian Deary (2001), there is no theory of human intelligence like the way physics has theories); and (2) what ultimately is termed “construct validity”—that a test measures what it purports to. There are a few kinds of validity: and what IQ-ists claim the most is that IQ tests have predictive validity—that is, they can predict an individual’s outcome in life, and job performance (it is claimed). However, “intelligence” is “a descriptive measure, not an explanatory concept … [so] measures of intelligence level have little or no predictive value” (Howe, 1988).
Howe (1997: ix) also tells us that “Intelligence is … an outcome … not a cause. … Even the most confidently stated assertions about intelligence are often wrong, and the inferences that people have drawn from those assertions are unjustified.”
The correlation between IQ and school performance, according to Richardson (1991: 34) “may be a necessary aspect of the validity of tests, but is not a sufficient one. Such evidence, as already mentioned, requires a clear connection between a theory (a model of intelligence), and the values on the measure.” But, as Richardson (2017: 85) notes:
… it should come as no surprise that performance on them [IQ tests] is associated with school performance. As Robert L. Thorndike and Elizabeth P. Hagen explained in their leading textbook, Educational and Psychological Measurement, “From the very way in which the tests were assembled [such correlation] could hardly be otherwise.”
Gottfredson (2009) claims that the construct validity argument against IQ is “fallacious”, noting it as one of her “fallacies” on intelligence testing (one of her “fallacies” was the “interactionism fallacy”, which I have previously discussed). However, unfortunately for Gottfredson (2009), “the phenomena that testers aim to capture” are built into the test and, as noted here numerous times, preconceived by the constructors of the test. So, Gottfredson’s (2009) claim fails.
Such kinds of construction, too, come into the claim of a “normal distribution.” Just like with preconceptions of who is or is not “intelligent” on the basis of preconceived notions, the normal distribution, too, is an artifact of test construction, along the selection and deselection of items to conform with the test constructors’ presuppositions; the “bell curve” of IQ is created by the presuppositions that the test constructors have about people and society (Simon, 1997).
Charles Spearman, in the early 1900s, claims to have found a “general factor” that explains correlations between different tests. This positive manifold he termed “g” for “general intelligence.” Spearman stated “The (g) factor was taken, pending further information, to consist in something of the nature of an ‘energy’ or ‘power’…” (quoted in Richardson, 1991: 38). The refutation of “g” is a simple, logical, one: While a correlation between performances “may be a necessary requirement for a general factor … it is not a sufficient one.” This is because “it is quite possible for quite independent factors to produce a hierarchy of correlations without the existence of any underlying ‘general’ factor (Fancer, 1985a; Richardson and Bynner, 1984)” (Richardson, 1991: 38). The fact of the matter is, Spearman’s “g” has been refuted for decades (and was shown to be reified by Gould (1981), and further defenses of his concepts on “general intelligence”, like by Jensen (1998) have been refuted, most forcefully by Peter Schonemann. Though, “g” is something built into the test by way of test construction (Richardson, 2002).
Castles (2013: 93) notes that “Spearman did not simply discover g lurking in his data. Instead, he chose one peculiar interpretation of the relationships to demonstrate something in which he already believed—unitary, biologically based intelligence.”
So what explains differences in “g”? The same test construction noted above along with differences in social class, due to stress, self-confidence, test preparedness and other factors correlated with social class, termed the “sociocognitive-affective nexus” (Richardson, 2002).
Constance Hilliard, in her book Straightening the Bell Curve (Hilliard, 2012), notes that there were differences in IQ between rural and urban white South Africans. She notes that differences between those who spoke Afrikaans and those who spoke another language were completely removed through test construction (Hilliard, 2012: 116). Hilliard (2012) notes that if the tests that the constructors formulate don’t agree with their preconceived notions, they are then thrown out:
If the individuals who were supposed to come out on top didn’t score highly or, conversely, if the individuals who were assumed would be at the bottom of the scores didn’t end up there, then the test designers scrapped the test.
Sex differences in “intelligence” (IQ) have been the subject of some debate in the early-to-mid-1900s. Test constructors debated amongst themselves what to do about such differences between the sexes. Hilliard (2012) quotes Harrington (1984; in Perspectives on Bias in Mental Testing) who writes about normalizing test scores between men and women:
It was decided [by IQ test writers] a priori that the distribution of intelligence-test scores would be normal with a mean (X=100) and a standard deviation (SD=15), also that both sexes would have the same mean and distribution. To ensure the absence of sex differences, it was arranged to discard items on which the sexes differed. Then, if not enough items remained, when discarded items were reintroduced, they were balanced, i.e., for every item favoring males, another one favoring females was also introduced.
While Richardson (1998: 114) notes that test constructors had two choices when looking at sex differences in the items they administered to the sexes:
One who would construct a test for intellectual capacity has two possible methods of handling the problem of sex differences.
1 He may assume that all the sex differences yielded by his test items are about equally indicative of sex differences in native ability.
2 He may proceed on the hypothesis that large sex differences on items of the Binet type are likely to be factitious in the sense that they reflect sex differences in experience or training. To the extent that this assumption is valid, he will be justified in eliminating from his battery test items which yield large sex differences.
The authors of the New Revision have chosen the second of these alternatives and sought to avoid using test items showing large differences in percents passing. (McNemar 1942:56)
Change “sex differences” to “race” or “social class” differences and we can, too, change the distribution of the curve, along with notions of who is or is not “intelligent.” Previously low scorers can, by way of test construction, become high scorers, vice-versa for high scorers being made into low scorers. There is no logical—or empirical—justification for the inclusion of specific items on whatever IQ test is in question. That is, to put it another way, the inclusion of items on a test is subjective, which comes down to the test designers’ preconceived notions, and not an objective measure of what types of items should be on the test—as Raven stated, there is no type of underlying theory for the inclusion of items in the test, it is based on “intuition” (which is the same thing that modern-day test constructors do). These two quotes from IQ-ists in the early 20th century are paramount in the attack on the validity of IQ tests—and the causes for differences in scores between groups.
He and van de Vijver (2012: 7) write that “An item is biased when it has a different psychological meaning across cultures. More precisely, an item of a scale (e.g., measuring anxiety) is said to be biased if persons with the same trait, but coming from different cultures, are not equally likely to endorse the item (Van de Vijver & Leung, 1997).” Indeed, Reynolds and Suzuki (2012: 83) write that “Item bias due to“:
… “poor item translation, ambiguities in the original item, low familiarity/appropriateness of the item content in certain cultures, or influence of culture specifics such as nuisance factors or connotations associated with the item wording” (p. 127) (van de Vijver and Tanzer, 2004)
Drame and Ferguson (2017) note that their “Results indicate that use of the Ravens may substantially underestimate the intelligence of children in Mali” while the cause may be due to the fact that:
European and North American children may spend more time with play tasks such as jigsaw puzzles or connect the dots that have similarities with the Ravens and, thus, train on similar tasks more than do African children. If African children spend less time on similar tasks, they would have fewer opportunities to train for the Ravens (however unintentionally) reflecting in poorer scores. In this sense, verbal ability need not be the only pitfall in selecting culturally sensitive IQ testing approaches. Thus, differences in Ravens scores may be a cultural artifact rather than an indication of true intelligence differences. [Similar arguments can be found in Richardson, 2002: 291-293]
The same was also found by Dutton et al (2017) who write that “It is argued that the undeveloped nature of South Sudan means that a test based around shapes and analytic thinking is unsuitable. It is likely to heavily under-estimate their average intelligence.” So if the Raven has these problems cross-culturally (country), then it SHOULD have such biases within, say, America.
It is also true that the types of items on IQ tests are not as complex as everyday life (see Richardson and Norgate, 2014). Types of questions on IQ tests are, in effect, ones of middle-class knowledge and skills and, knowing how IQ tests are structured will make this claim clear (along with knowing the types of items that eventually make it onto the particular IQ test itself). Richardson (2002) has a few questions on modern-day IQ tests whereas Castles (2013), too, has a few questions from the Stanford-Binet. This, of course, is due to the social class of the test constructors. Some examples of some questions can be seen here:
‘What is the boiling point of water?’ ‘Who wrote Hamlet?’ ‘In what continent is Egypt?’ (Richardson, 2002: 289)
and
‘When anyone has offended you and asks you to excuse him—what ought you do?’ ‘What is the difference between esteem and affection?’ [this is from the Binet Scales, but “It is interesting to note that similar items are still found on most modern intelligence tests” (Castles, 2013).]]
Castles (2013: 150) further notes made-up examples of what is on the WAIS (since she cannot legally give questions away since she is a licensed psychologist), and she writes:
One section of the WAIS-III, for example, consists of arithmetic problems that the respondent must solve in his or her head. Others require test-takers to define a series of vocabulary words (many of which would be familiar only to skilled-readers), to answer school-related factual questions (e.g., “Who was the first president of the United States?” or “Who wrote the Canterbury Tales?”), and to recognize and endorse common cultural norms and values (e.g., “What should you do it a sale clerk accidentally gives you too much change?” or “Why does our Constitution call for division of powers?”). True, respondents are also given a few opportunities to solve novel problems (e.g., copying a series of abstract designs with colored blocks). But even these supposedly culture-fair items require an understanding of social conventions, familiarity with objects specific to American culture, and/or experience working with geometric shapes or symbols.
All of these factors coalesce into forming the claim—and the argument—that IQ tests are one of middle-class knowledge and skills. The thing is, contrary to the claims of IQ-ists, there is no such thing as a culture-free IQ test. Richardson (2002: 293) notes that “Since all human cognition takes place through the medium of cultural/psychological tools, the very idea of a culture-free test is, as Cole (1999) notes, ‘a contradiction in terms . . . by its very nature, IQ testing is culture bound’ (p. 646). Individuals are simply more or less prepared for dealing with the cognitive and linguistic structures built in to the particular items.”
Cole (1981) notes that “that the notion of a culture free IQ test is an absurdity” because “all higher psychological processes are shaped by our experiences and these experiences are culturally organized” (this is a point that Richardson has driven home for decades) while also—rightly—stating that “IQ tests sample school activities, and therefore, indirectly, valued social activities, in our culture.”
One of the last stands for the IQ-ist is to claim that IQ tests are useful for identifying at-risk individuals for learning disabilities (as Binet originally created the first IQ tests for). However, it is noted that IQ tests are not necessary—nor sufficient—for the identification of those with learning disabilities. Siegal (1989) states that “On logical and empirical grounds, IQ test scores are not necessary for the definition of learning disabilities.”
When Goddard brought the first IQ tests to America and translated them into English from French is when the IQ testing conglomerate really took off (see Zenderland, 1998 for a review). These tests were used to justify current social ranks. As Richardson (1991: 44) notes, “The measurement of intelligence in the twentieth century arose partly out of attempts to ‘prove’ or justify a particular world view, and partly for purposes of screening and social selection. It is hardly surprising that its subsequent fate has been one of uncertainty and controversy, nor that it has raised so many social and political issues (see, for example, Joynson 1989 for discussion of such issues).” So, what actual attempts at validation did the constructors of such tests need in the 20th century when they knew full-well what they wanted to show and, unsurprisingly, they observed it (since it was already going to happen since they construct the test to be that way)?
The conceptual arguments just given here point to a few things:
(1) IQ tests are not construct valid because there is no theory of intelligence, nor is there an underlying theory which relates differences in IQ (the unseen function) to, for example, a physiological variable. (See Uttal, 2012; 2014 for arguments against fMRI studies that purport to show differences in physiological variables cognition.)
(2) The fact that items on the tests are biased against certain classes/cultures; this obviously matters since, as noted above, there is no theory for the inclusion of items, it comes down to the subjective choice of the test designers, as noted by Jensen.
(3) ‘g’ is a reified mathematical abstraction; Spearman “discovered” nothing, he just chose the interpretation that, of course, went with his preconceived notion.
(4) The fact that sex differences in IQ scores were seen as a problem and, through item analysis, made to go away. This tells us that we can do the same for class/race differences in intelligence. Score differences are a function of test construction.
(5) The fact that the Raven has been shown to be biased in two African countries lends credence to the claims here.
So this then brings us to the ultimate claim of this article: IQ tests don’t test intelligence; they test middle-class knowledge and skills. Therefore, the scores on IQ tests are not that of intelligence, but of an index of one’s cultural knowledge of the middle class and its knowledge structure. This, IQ scores are, in actuality, “middle-class knowledge and skills” scores. So, contra Jensen (1980), there is bias in mental testing due to the items chosen for inclusion on the test (we have admission that score variances and distributions can change from IQ-ists themselves)
“Mongoloid Idiots”: Asians and Down Syndrome
1700 words
Look at a person with Down Syndrome (DS) and then look at an Asian. Do you see any similarities? Others, throughout the course of the 20th century have. DS is a disorder arising from chromosomal defects which causes mental and physical abnormalities, short stature, broad facial profile, and slanted eyes. Most likely, one suffering from DS has an extra copy of chromosome 21—which is why the disorder is called “trisomy 21” in the scientific literature.
I am not aware if most “HBDers” know this, but Asians in America were treated similarly to blacks in the mid-20th century (with similar claims made about genital and brain size). Whites used to be said to have the biggest brains out of all of the races but this changed sometime in the 20th century. Lieberman (2001: 72) writes that:
The shrinking of “Caucasoid” brains and cranial size and the rise of “Mongoloids” in the papers of J. Philippe Rushton began in the 1980s. Genes do not change as fast as the stock market, but the idea of “Caucasian” superiority seemed contradicted by emerging industrialization and capital growth in Japan, Taiwan, Hong Kong, Singapore, and Korea (Sautman 1995). Reversing the order of the first two races was not a strategic loss to raciocranial hereditarianism, since the major function of racial hierarchies is justifying the misery and lesser rights and opportunities of those at the bottom.
So Caucasian skulls began to shrink just as—coincidentally, I’m sure—Japan began to get out of its rut it got into after WWII. Morton noted that Caucasians had the biggest brains with Mongoloids in the middle and Africans with the smallest—then came Rushton to state that, in fact, it was East Asians who had the bigger brains. Hilliard (2012: 90-91) writes:
In the nineteenth century, Chinese, Japanese, and other Asian males were often portrayed in the popular press as a sexual danger to white females. Not surprising, as Lieberman pointed out, during this era, American race scientists concluded that Asians had smaller brains than whites did. At the same time, and most revealing, American children born with certain symptoms of mental retardation during this period were labeled “mongoloid idiots.” Because the symptoms of this condition, which we now call Down Syndrome, includes “slanting” eyes, the old label reinforced prejudices against Asians and assumptions that mental retardation was a peculiarly “mongoloid” racial characteristic.
[Hilliard also notes that “Scholars identified Asians as being less cognitively evolved and having smaller brains and larger penises than whites.” (pg 91)]
So, views on Asians were different back in the 19th and 20th centuries—it even being said that Asians had smaller brains and bigger penises than whites (weird…).
Mafrica and Fodale (2007) note that the history of the term “mongolism” began in 1866, with the author distinguishing between “idiotis”: the Ethiopian, the Caucasian, and the Mongoloid. What led Langdon (the author of the 1866 paper) to make this comparison was the almond-shaped eyes that DS people have as well. Though Mafrica and Fodale (2007: 439) note that it is possible that other traits could have forced him to make the comparison, “such as fine and straight hair, the distribution of apparatus piliferous, which appears to be sparse.” Mafrica and Fodale (2007: 439) also note more similarities between people with DS and Asians:
Down persons during waiting periods, when they get tired of standing up straight, crouch, squatting down, reminding us of the ‘‘squatting’’ position described by medical semeiotic which helps the venous return. They remain in this position for several minutes and only to rest themselves this position is the same taken by the Vietnamese, the Thai, the Cambodian, the Chinese, while they are waiting at a the bus stop, for instance, or while they are chatting.
There is another pose taken by Down subjects while they are sitting on a chair: they sit with their legs crossed while they are eating, writing, watching TV, as the Oriental peoples do.
Another, funnier, thing noted by Mafrica and Fodale (2007) is that people with DS may like to have a few plates across the table, while preferring foodstuffs that is high in MSG—monosodium glutamate. They also note that people with DS are more likely to have thyroid disorders—like hypothyroidism. There is an increased risk for congenital hypothyroidism in Asian families, too (Rosenthal, Addison, and Price, 1988). They also note that people with DS are likely “to carry out recreative–reabilitative activities, such as embroidery, wicker-working ceramics, book-binding, etc., that is renowned, remind the Chinese hand-crafts, which need a notable ability, such as Chinese vases or the use of chop-sticks employed for eating by Asiatic populations” (pg 439). They then state that “it may be interesting to know the gravity with which the Downs syndrome occurs in Asiatic population, especially in Chinese population.” How common is it and do they look any different from other races’ DS babies?
See, e.g., Table 2 from Emanuel et al (1968):
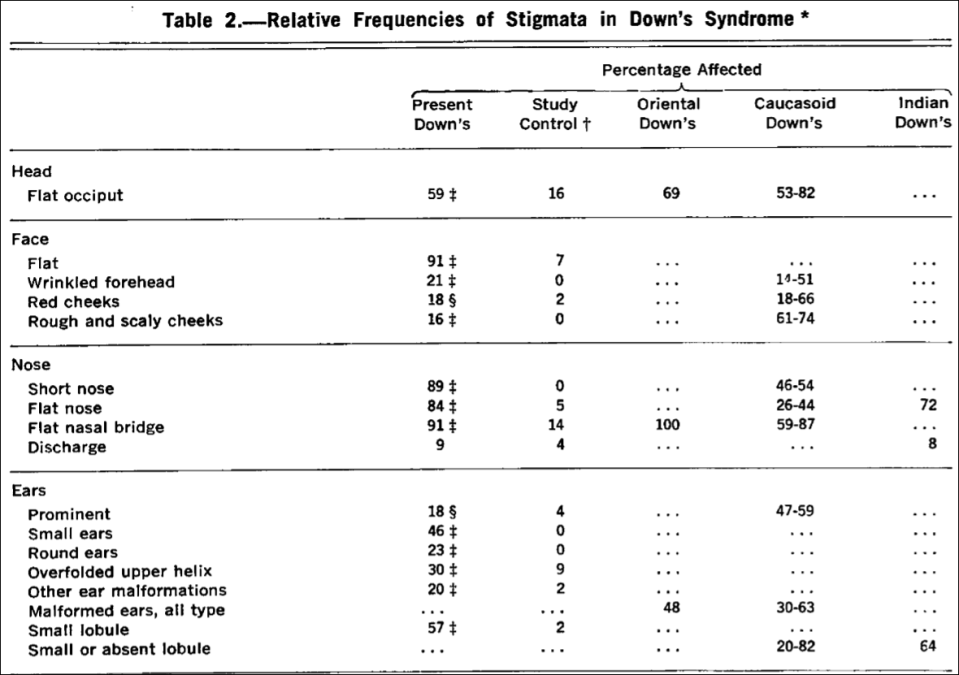
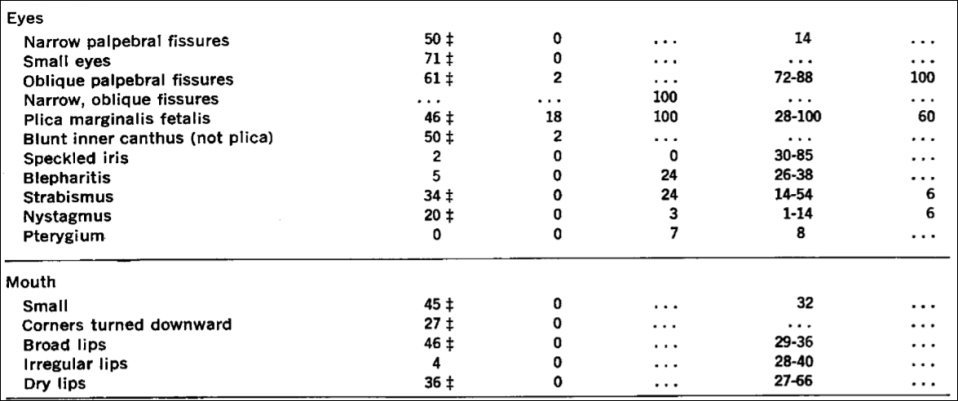
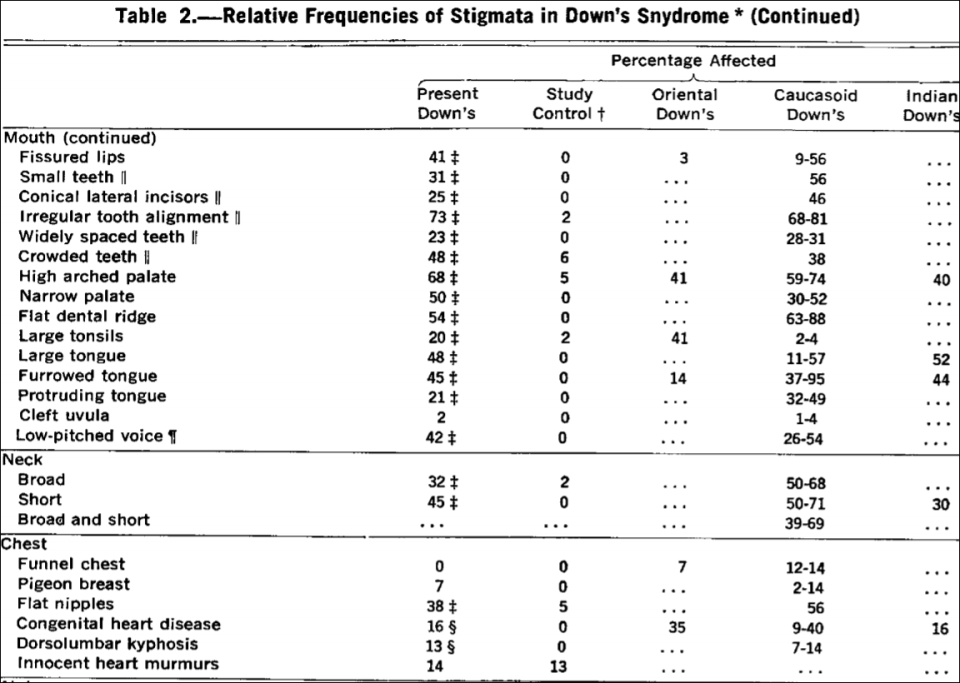
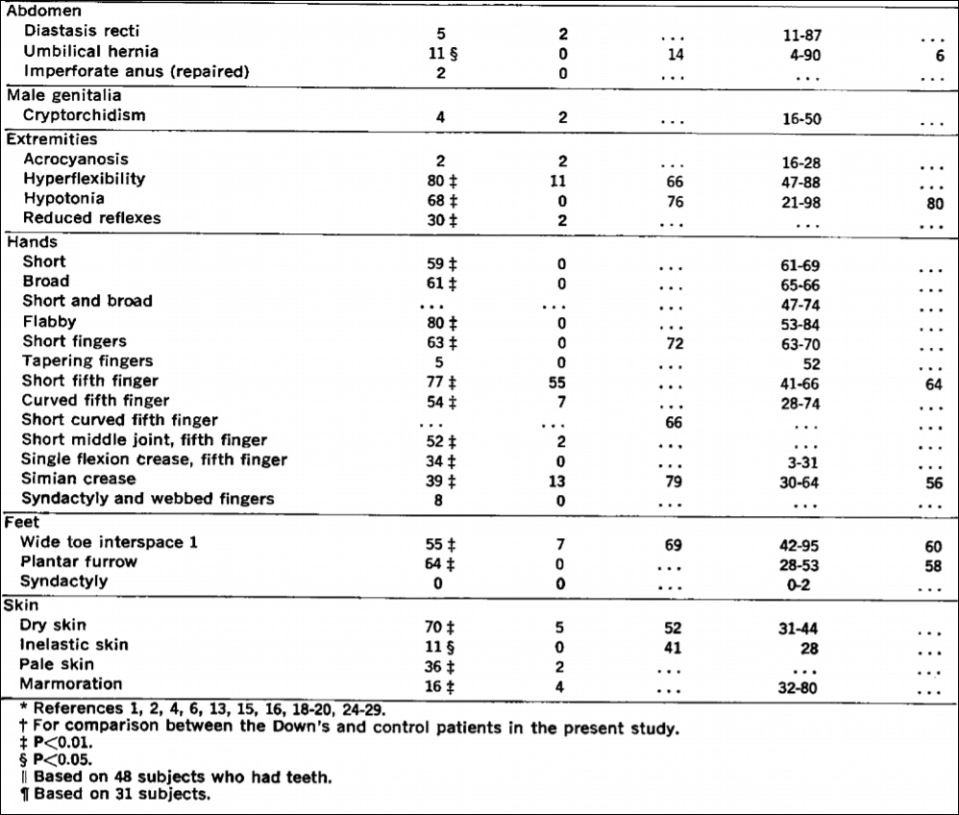
Emanuel et al (1968: 465) write that “Almost all of the stigmata of Down’s syndrome presented in Table 2 appear also to be of significance in this group of Chinese patients. The exceptions have been reported repeatedly, and they all probably occur in excess in Down’s syndrome.”
Examples such as this are great to show the contingencies of certain observations—like with racial differences in “intelligence.” Asians, today, are revered for “hard work”, being “very intelligent” and having “low crime rates.” But, even as recently as the mid 20th century—going back to the mid 18th century—Asians (or Mongoloids, as Rushton calls them) were said to have smaller brains and larger penises. Anti-miscegenation laws held for Asians, too of course, and so interracial marriage was forbidden with Asians and whites which was “to preserve the ‘racial integrity’ of whites” (Hilliard, 2012: 91).
Hilliard (2012) states that the effeminate, small-penis Asian man. Hilliard (2012: 86) writes:
However, it is also possible that establishing the racial supremacy of whites was not what drove this research on racial hierarchies. If so, the IQ researchers were probably justified in protesting their innocence, at least in regard to the charge of being racial supremacists, for in truth, the Asians’ top ranking might have unintentionally underscored that true sexual preoccupations underlying this research in the first place. It not seems that the real driving force behind such work was not racial bigotry so much as it was the masculine insecurities emanating from the unexamined sexual stereotypes still present within American popular culture. Scholars such as Rushton, Jensen, and Herrnstein provided a scientific vocabulary and mathematically dense charts and graphs to give intellectual polish to the preoccupations. Thus, it became useful to tout the Asians’ cognitive superiority but only so long as whites remained above blacks in the cognitive hierarchy.
Of course, by switching the racial hierarchy—but keeping the bottom the same—IQ researchers can say “We’re not racists! If we were, why would we state that Asians were better on trait T than we were!”, as has been noted by John Relethford (2001: 84) who writes that European-descended researchers “can now deflect charges of racism or ethnocentrism by pointing out that they no longer place themselves at the top. Lieberman aptly notes that this shift does not affect the major focus of many ideas regarding racial superiority that continue to place people of recent African descent at the bottom.” While biological anthropologist Fatima Jackson (2001: 83) states that “It is deemed acceptable for “Mongoloids” to have larger brains and better performance on intelligence tests than “Caucasoids,” since they are (presumably) sexually and reproductively compromised with small genitalia, low fertility, and delayed maturity.”
The main thesis of Straightening the Bell Curve is that preoccupations with brain and genital size is a driving part of these psychologists who study racial differences. Stating that Asians had smaller penises but larger heads though they were less likely to like sex while blacks had larger penises, smaller heads and were more likely to like sex while whites were, like Goldilocks, juuuuuust right—a penis size in-between Asians and blacks and a brain neither too big or too small. So, stating that X race had smaller brains and bigger penises seems, as Hilliard argues, to be a coping mechanism for certain researchers and to drive women away from that racial group.
In any case, how weird it is for Asians (“Mongoloids”) to be ridiculed as having small brains and large penises (a hilarious reversal of Rushton’s r/K bullshit) and then—all of a sudden—for them to come out on top over whites while whites are still over blacks in this racial hierarchy. How weird is it for the placements to change with certain economic events in a country’s history. Though, as many authors have noted, for instance Chua (1999), Asian men have faced emasculinazation and femininzation in American society. So, since they were seen to be “undersexed, they were thus perceived as minimal rivals to white men in the sexual competition for women” (Hilliard, 2012: 87).
So, just like the observation of racial/country IQ are contingent on the time and the place of the observation, so too is the observation of racial differences in certain traits and how they can be used for a political agenda. As Constance Hilliard (2012: 85) writes, referring to Professor Michael Billig’s article A dead idea that will not lie down (in reference to race science), “… scientific ideas did not develop in a vacuum but rather reflected underlying political and economic trends.“ And so, this is why “mongoloid idiots” and undersexed Asians appeared in American thought in the mid-20th century. So these ideas noted here—mongloidism, undersexed Asians, small penis, large penis, small brain, large brained Asians (based on the time and the place of the observation) show, again, the contingency of these racial hierarchies—which, of course, still stay with blacks on the bottom and whites above them. Is it not strange that whites moved a rung down on this hierarchy as soon as Rushton appeared in the picture? (Since, Morton noted that they had smaller heads than Caucasians, Lieberman, 2001.)
The origins of the term “mongloidism” are interesting—especially with how they tie into the origins of the term Down Syndrome and how they related to the “Asian look” along with all of the peculiarities of people with DS and (to Westerners), the peculiarities of Asian living. This is, of course, why one’s political motives, while not fully telling of their objectives and motivations, may—in a way—point one in the right direction as to why they are formulating such hypotheses and theories.
Just-so Stories: Sex Differences in Color Preferences
1550 words
“Women may be hardwired to prefer pink“, “Study: Why Girls Like Pink“, “Do girls like pink because of their berry-gathering female ancestors?“, “Pink for a girl and blue for a boy – and it’s all down to evolution” are some of the popular news headlines that came out 12 years ago when Hurlbert and Ling (2007) published their study Biological components of sex differences in color preference. They used 208 people, 171 British Caucasians, 79 of whom were male, 37 Han Chinese (19 of whom were male). Hurlbert and Ling (2007) found that “females prefer colors with ‘reddish’ contrast against the background, whereas males prefer the opposite.”
Both males and females have a preference for blueish and reddish hues, and so, women liking pink is an evolved trait, on top of having a preference for blue. The authors “speculate that this sex difference arose from sex-specific functional specializations in the evolutionary division of labour.” So specializing for gathering berries, the “female brain” evolved “trichromatic adaptations”—that is, three colors are seen—which is the cause for women preferring “redder” hues. Since women were gatherers—while men hunters—they needed to be able to discern redder/pinker hues to be able to gather berries. Hurlbert and Ling (2007) also state that there is an alternative explanation which “is the need to discriminate subtle changes in skin color due to emotional states and social-sexual signals [9]; again, females may have honed these adaptations for their roles as care-givers and ‘empathizers’ [10].”
The cause for sex differences in color preference are simple: men and women faced different adaptive problems in their evolutionary history—men being the hunters and women the gatherers—and this evolutionary history then shaped color preferences in the modern world. So women’s brains are more specialized for gathering-type tasks, as to be able to identify ripe fruits with a pinker hue, either purple or red. Whereas for males they preferred green or blue—implying that as men evolved, the preference for these colors was due to the colors that men encountered more frequently in their EEA (evolutionary environment of adaptedness).
He et al (2011) studied 436 Chinese college students from a Chinese university. They found that men preferred “blue > green > red > yellow > purple > orange > white > black > pink > gray > brown,” while women preferred “purple > blue > yellow > green > pink > white > red > orange > black > gray > brown” (He et al, 2011: 156). So men preferred blue and green while women preferred pink, purple and white. Here is the just-so story (He et al, 2011: 157-158):
According to the Hunter-Gatherer Theory, as a consequence of an adaptive survival strategy throughout the hunting-gathering environment, men are better at the hunter-related task, they need more patience but show lower anxiety or neuroticism, and, therefore would prefer calm colors such as blue and green; while women are more responsible to the gatherer-related task, sensitive to the food-related colors such as pink and purple, and show more maternal nurturing and peacefulness (e.g., by preferring white).
Just-so stories like this come from the usual suspects (e.g., Buss, 2005; Schmidt, 2005). Regan et al (2001) argue that “primate colour vision has been shaped by the need to find coloured fruits amongst foliage, and the fruits themselves have evolved to be salient to primates and so secure dissemination of their seeds.” Men are more sensitive to blue-green hues in these studies, and, according to Vining (2006), this is why men prefer these colors: it would have been easier for men to hunt if they could discern between blue and green hues; that men like these kinds of colors more than the other “feminine” colors is evidence in favor of the “hunter-gatherer” theory.
(Image from here.)
So, according to evolutionary psychologists, there is an evolutionary reason for these sex differences in color preferences. If men were more likely to like blueish-greenish hues over red ones, then we can say that it was a specific adaptation from the hunting days: men need to be able to ascertain color differences which would have them be better hunters—preferring blue for, among other reasons, the ability to notice sky and water, as they would be better hunters if they did. And so, according to the principle of evolution by natural selection, the men who could ascertain these colors and hues had better reproductive success over those that could not, and so those men passed their genes onto the next generation, which included those color-sensing genes. The same is true for women: that women prefer pinkish, purpleish hues is evidence that, in an evolutionary context, they needed to ascertain pinkish, purpleish colors as to identify ripe fruits. And so again, according to this principle of natural selection, these women who could better ascertain colors and hues more likely to be seen in berries passed their genes on to the next generation, too.
This theory hinges, though, on Man the Hunter and Woman the Gatherer. Men ventured out to hunt—which explains the man’s color preferences—while women stayed at the ‘home’ and took care of the children and looked to gather berries—which explains women color preferences (gathering pink berries, discriminating differences in skin color due to emotional states). So the hypothesis must have a solid evolutionary basis—it makes sense and comports to the data we have, so it must be true, right?
Here’s the thing: boys and girls didn’t always wear blue and pink respectively; this is something that has recently changed. Jasper Pickering, writing for The Business Insider explains this well in an interview with color expert Gavin Moore:
“In the early part of the 20th Century and the late part of the 19th Century, in particular, there were regular comments advising mothers that if you want your boy to grow up masculine, dress him in a masculine colour like pink and if you want your girl to grow up feminine dress her in a feminine colour like blue.”
“This was advice that was very widely dispensed with and there were some reasons for this. Blue in parts of Europe, at least, had long been associated as a feminine colour because of the supposed colour of the Virgin Mary’s outfit.”
“Pink was seen as a kind of boyish version of the masculine colour red. So it gradually started to change however in the mid-20th Century and eventually by about 1950, there was a huge advertising campaign by several advertising agencies pushing pink as an exclusively feminine colour and the change came very quickly at that point.”
While Smithsonian Magazine quotes the Earnshaw Infants Department (from 1918):
The generally accepted rule is pink for the boys, and blue for the girls. The reason is that pink , being a more decided and stronger color, is more suitable for the boy, while blue, which is more delicate and dainty, is prettier for the girl.
So, just like “differences” in “cognitive ability (i.e., how if modern-day “IQ” researchers would have been around in antiquity they would have formulated a completely different theory of intelligence and not used Cold Winters Theory), if these EP-minded researchers had been around in the early 20th century, they’d have seen the opposite of what they see today: boys wearing pink and girls wearing blue. What, then, could account for such observations? I’d guess something like “Boys like pink because it’s a hue of red and boys, evolved as hunters, had to like seeing red as they would be fighting either animals or other men and would be seeing blood a majority of the time.” As for girls liking blue, I’d guess something like “Girls had to be able to ascertain green leaves from the blue sky, and so, they were better able to gather berries while men were out hunting.”
That’s the thing with just-so stories: you can think of an adaptive story for any observation. As Joyner, Boros, and Fink (2018: 524) note for the Bajau diving story and the sweat gland story “since the dawn of the theory of evolution, humans have been incredibly creative in coming up with evolutionary and hence genetic narratives and explanations for just about every human trait that can be measured“, and this can most definitely be said for the sex differences in color preferences story. We humans are very clever at making everything an adaptive story when there isn’t one to be found. Even if it can be established that there are such things as “trichomatic adaptations” that evolved for men and women liking the colors they do, then, the combination of functional effect (women liking pink for better gathering and men liking blue and green for better hunting) and that the trait truly was “selected-for” does not license the claim that selection acted on the specific trait in question since we cannot “exclude the possibility that selection acted on some other pleiotropic effect of the mutation” (Nielsen, 2009).
In sum, the causes for sex differences in color preferences, today, makes no sense. These researchers are just looking for justification for current cultural/societal trends in which sex likes which colors and then weaving “intricate” adaptive stories in order to claim that part of this is due to men’s and women’s “different” evolutionary history—man as hunter and woman as gatherer. However, due to how quickly things change in culture and society, we can be asking questions we would not have asked before due to how quickly society changes, and then ascribe evolutionary causes for out observations. As Constance Hilliard (2012: 85) writes, referring to Professor Michael Billig’s article A dead idea that will not lie down (in reference to race science), “… scientific ideas did not develop in a vacuum but rather reflected underlying political and economic trends.“
The Argument in The Bell Curve
600 words
On Twitter, getting into discussions with Charles Murray acolytes, someone asked me to write a short piece describing the argument in The Bell Curve (TBC) by Herrnstein and Murray (H&M). This is because I was linking my short Twitter thread on the matter, which can be seen here:
In TBC, H&M argue that America is becoming increasingly stratified by social class, and the main reason is due to the “cognitive elite.” The assertion is that social class in America used to be determined by one’s social origin is now being determined by one’s cognitive ability as tested by IQ tests. H&M make 6 assertions in the beginning of the book:
(i) That there exists a general cognitive factor which explains differences in test scores between individuals;
(ii) That all standardized tests measure this general cognitive factor but IQ tests measure it best;
(iii) IQ scores match what most laymen mean by “intelligent”, “smart”, etc.;
(iv) Scores on IQ tests are stable, but not perfectly so, throughout one’s life;
(v) Administered properly, IQ tests are not biased against classes, races, or ethnic groups; and
(vi) Cognitive ability as measured by IQ tests is substantially heritable at 40-80%/
In the second part, H&M argue that high cognitive ability predicts desireable outcomes whereas low cognitve ability predicts undesireable outcomes. Using the NLSY, H&M show that IQ scores predict one’s life outcomes better than parental SES. All NLSY participants took the ASVAB, while others took IQ tests which were then correlated with the ASVAB and the correlation came out to .81.
They analyzed whether or not one has ever been incarcerated, unemployed for more than one month in the year; whether or not they dropped out of high-school; whether or not they were chronic welfare recipients; among other social variables. When they controlled for IQ in these analyses, most of the differences between ethnic groups, for example, disappeared.
Now, in the most controversial part of the book—the third part—they discuss ethnic differences in IQ scores, stating that Asians have higher IQs than whites who have higher IQs than ‘Hispanics’ who have higher IQs than blacks. H&M argue that the white-black IQ gap is not due to bias since they do not underpredict blacks’ school or job performance. H&M famously wrote about the nature of lower black IQ in comparison to whites:
If the reader is now convinced that either the genetic or environmental explanation has won out to the exclusion of the other, we have not done a sufficiently good job of presenting one side or the other. It seems highly likely to us that both genes and environment have something to do with racial differences. What might the mix be? We are resolutely agnostic on that issue; as far as we can determine, the evidence does not yet justify an estimate.
Finally, in the fourth and last section, H&M argue that efforts to raise cognitive ability through the alteration of the social and physical environment have failed, though we may one day find some things that do raise ability. They also argue that the educational experience in America neglects the small, intelligent minority and that we should begin to not neglect them as they will “greatly affect how well America does in the twenty-first century” (H&M, 1996: 387). They also argue forcefully against affirmative action, in the end arguing that equality of opportunity—over equality of outcome—should be the role of colleges and workplaces. They finally predict that this “cognitive elite” will continuously isolate themselves from society, widening the cognitive gap between them.
