
Home » IQ (Page 5)
Category Archives: IQ
“Definitions” of ‘Intelligence’ and its ‘Measurement’
1750 words
What ‘intelligence’ is and how, and if, we can measure it has puzzled us for the better part of 100 years. A few surveys have been done on what ‘intelligence’ is, and there has been little agreement on what it is and even if IQ tests measure ‘intelligence.’ Richardson (2002: 284) noted that:
Of the 25 attributes of intelligence mentioned, only 3 were mentioned by 25 per cent or more of respondents (half of the respondents mentioned ‘higher level components’; 25 per cent mentioned ‘executive processes’; and 29 per cent mentioned ‘that which is valued by culture’). Over a third of the attributes were mentioned by less than 10 per cent of respondents (only 8 per cent of the 1986 respondents mentioned ‘ability to learn’).
As can be seen, even IQ-ists today cannot agree upon a definition—indeed, even Ian Deary admits that “There is no such thing as a theory of human intelligence differences—not in the way that grown-up sciences like physics or chemistry have theories” (quoted in Richardson, 2012). (Also note that attempts of validity are circular, relying on correlations with other, similar tests; Richardson and Norgate, 2015; Richardson, 2017b.)
Linda Gottfredson, University of Delaware sociologist and well-known hereditarian, is a staunch defender of JP Rushton (Gottfredson, 2013) and the hereditarian hypothesis (Gottfredson, 2005, 2009). Her ‘definition’ of intelligence is one of the most-oft cited ones, eg, Gottfredson et al (1993: 13) notes that (my emphasis):
Intelligence is a very general mental capability that, among other things, involves the ability to reason, plan, solve problems, think abstractly, comprehend complex ideas, learn quickly and learn from experience. It is not merely book learning, a narrow academic skill, or test-taking smarts. Rather, it reflects a broader and deeper capability for comprehending our surroundings-“catching on,” “ making sense” of things, or “figuring out” what to do.
So ‘intelligence’ is “a very general mental capability”, its main ‘measure’ IQ tests (knowledge tests), but ‘intelligence’ “is not merely book learning, a narrow academic skill, or test-taking smarts.” Here’s some more hereditarian “reasoning” (which you can contrast with the hereditarian “reasoning” on race—just assume it exists). Gottfredson also argues that ‘intelligence’ or ‘g’ is learning ability. But, as Richardson (2017a: 100) notes, “it will always be quite impossible to measure ability with an instrument that depends on learning in one particular culture“—which he terms “the g paradox, or a general measurement paradox.”
Gottfredson (1997) also argues that the “active ingredient” in IQ testing is the “complexity” of the items—what makes one item more difficult than another, such as a 3×3 matrix item being more complex than a 2×2 matrix item and giving some examples of analogies which she believes to show a type of higher, more complex cognition in order to figure out the answer to the problem. (Also see Richardson and Norgate, 2014 for further critiques of Gottfredson.)
The trouble with this argument is that IQ test items are remarkably simple in their cognitive demands compared with, say, the cognitive demands of ordinary social life and other activities that the vast majority of children and adults can meet adequately every day.
For example, many test items demand little more than rote reproduction of factual knowledge most likely acquired from experience at home or by being taught in school. Opportunities and pressures for acquiring such valued pieces of information, from books in the home to parents’ interests and educational level, are more likely to be found in middle-class than in working-class homes. So the causes of differences could be causes in opportunities for such learning.
The same could be said about other frequently used items, such as “vocabulary” (or word definitions); “similarities” (describing how two things are the same); “comprehension” (explaining common phenomena, such as why doctors need more training). This helps explain why differences in home background correlate so highly with school performance—a common finding. In effect, such items could simply reflect the specific learning demanded by the items, rather than a more general cognitive strength. (Richardson, 2017a: 91)
IQ-ists, of course, would then state that there is utility in such “simple-looking” test items, but we have to remember that items on IQ tests are not selected based on a theoretical cognitive model, but are selected to give the desired distributions that the test constructors want (Mensh and Mensh, 1991). “… those items in IQ tests have been selected because they help produce the expected pattern of scores. A mere assertion of complexity about IQ test items is not good enough” (Richardson, 2017a: 93). “The items selected for inclusion [on Binet’s test] were those that in the judgment of the teachers distinguished bright from dull students” (Castles, 2012: 88). It seems that all hereditarians do is “assert” or “assume” things—like the equal environments assumption (EEA), the existence of race, and now, the existence of “intelligence”. Just presuppose what you want and, unsurprisingly, you get what you wanted. The IQ-ist then triumphs that the test did its job—sorting high- and low-quality thinkers on the basis of their IQ scores. But that’s exactly the problem: prior assumptions on the nature of ‘intelligence’ and its distribution dictate the construction of the tests in question.
Mensh and Mensh (1991: 30) state that “The [IQ] tests do what their construction dictates; they correlate a group’s mental worth with its place in the social hierarchy.” That is, who is or is not “intelligent” is already presupposed. There has been ample admission of such presumptions affecting the distribution of scores, as some critics have documented (e.g., Hilliard, 2012’s documentation of test norming for two different white cultural groups in South Africa and that Terman equalized scores on his 1937 revision of the Stanford-Binet).
Herrnstein and Murray (1994: 1) write that:
That the word intelligence describes something real and that it varies from person to person is as universal and ancient as any understanding about the state of being human. Literate cultures everywhere and throughout history have had words for saying that some people are smarter than others. Given the survival value of intelligence, the concept must be still older than that. Gossip about who in the tribe is cleverest has probably been a topic of conversation around the fire since fires, and conversation, were invented.
Castles (2012: 83) responds to these assertions stating that “the concept of intelligence is indeed a “brashing modern notion.” 1” Herrnstein and Murray, of course, are in the “Of COURSE intelligence exists!” camp, for, to them, it conferred survival advantages and so, it must exist and we can, therefore, measure it in humans.
Howe (1997), in his book IQ in Question, asks us to imagine someone asking to construct a vanity test. Vanity, like ‘intelligence’, has no agreed-upon definition which states how it should be measured nor anything that makes it possible to check that we are measuring the supposed construct correctly. So the one who wants to assess vanity needs to construct a test with questions he presumes tests vanity. So if the questions he asks relates to how others perceive vanity, then the ‘vanity test’ has been successfully constructed and the test constructor can then believe that he’s measuring “differences in” vanity. But, of course, selecting items on a test is a subjective matter; there is no objective way for this to occur. We can say, with length for instance, that line A is twice as long as line B. But we could not, then, state that person A is twice as vain as person B—nor could we say that person A is twice as intelligent as person B (on the basis of IQ scores)—for what would it mean for someone to be twice as vain as someone else, just like what would it mean for someone to be twice as intelligent as someone else?
Howe (1997: 6) writes:
The measurement of intelligence is bedeviled by the same problems that make it virtually impossible to measure vanity. It is of course possible to construct intelligence tests, and the tests can be useful in a number of ways for assessing human mental abilities, but it is wrong to assume that such tests have the capability of measuring an underlying quality of intelligence, if by ‘measuring’ we have in mind the same operations that are involved in the measurement of a physical quality such as length. A psychological test score is no more than an indication of how well someone has performed at a number of questions that have been chosen for largely practical reasons. Nothing is genuinely being measured.
But if “A psychological test score is no more an indication of how well someone has performed at a number of questions that have been chosen largely for practical reasons”, then it follows that knowledge exposure explains outcomes in psychological test scores. Richardson (1998: 127) writes:
The most reasonable answer to the question “What is being measured?”, then, is ‘degree of cultural affiliation’: to the culture of test constructors, school teachers and school curricula. It is (unconsciously) to conceal this that all the manipulations of item selection, evasions about test validities, and searches for post hoc theoretical underpinning seem to be about. What is being measured is certainly not genetically constrained complexity of general reasoning ability as such,
Mensh and Mensh (1991: 73) note that “In reality — which is precisely the opposite of what Jensen claims it to be — test discrimination among individuals within any group is the incidental by-product of tests constructed to discriminate between groups. Because the tests’ class and racial bias ensures that some groups will be higher and others lower in the scoring hierarchy, the status of an individual member of a group is as a rule predetermined by the status of that group.”
In sum, what these tests test is what the test constructors presume—mainly, class and racial bias—so they get what they want to see. If the test does not match their presuppositions, the test gets discarded or reconstructed to fit with their biases. Thus, definitions of ‘intelligence’ will always be, as Castles (2012: 29), “intelligence is a cultural construct, specific to a certain time and place.” The definition from Gottfredson doesn’t make sense, as the “test-taking smarts” is the main “measure” of ‘intelligence’, and so intelligence’s “main measure” is the IQ test—which presupposes the distribution of scores as developed by the test constructors (Mensh and Mensh, 1991). Herrnstein and Murray’s definition does not make sense either, as the concept of “intelligence” is a modern notion.
At best, IQ test scores measure the degree of cultural acquisition of knowledge; they do not, nor can they, measure ‘intelligence’—which is a cultural concept which changes with the times. The tests are inherently biased against certain groups; looking at the history and construction of IQ testing will make that clear. The tests are middle-class knowledge tests; not tests of ‘intelligence.’
The “World’s Smartest Man” Christopher Langan on Koko the Gorilla’s IQ
1500 words
Christopher Langan is purported to have the highest IQ in the world, at 195—though comparisons to Wittgenstein (“estimated IQ” of 190), da Vinci, and Descartes on their “IQs” are unfounded. He and others are responsible for starting the high IQ society the Mega foundation for people with IQs of 164 or above. For a man with one of the highest IQs in the world, he lived on a poverty wage at less than $10,000 per year in 2001. He has also been a bouncer for the past twenty years.
Koko is one of the world’s most famous gorillas, most-known for crying when she was told her cat got hit by a car and being friends with Robin Williams, also apparently expressing sadness upon learning of his death. Koko’s IQ, as measured by an infant IQ test, was said to be on-par or higher than some of the (shoddy) national IQ scores from Richard Lynn (Richardson, 2004; Morse, 2008). This then prompted white nationalist/alt-right groups to compare Koko’s IQ scores with that of certain nationalities and proclaim that Koko was more ‘intelligent’ than those nationalities on the basis of her IQ score. But, unfortunately for them, the claims do not hold up.
The “World’s Smartest Man” Christopher Langan is one who falls prey to this kind of thinking. He was “banned from” Facebook for writing a post comparing Koko’s IQ scores to that of Somalians, asking why we don’t admit gorillas into our civilization if we are letting Somalian refugees into the West:
“According to the “30 point rule” of psychometrics (as proposed by pioneering psychometrician Leta S. Holingsworth), Koko’s elevated level of thought would have been all but incomprehensible to nearly half the population of Somalia (average IQ 68). Yet the nation’s of Europe and North America are being flooded with millions of unvetted Somalian refugees who are not (initially) kept in cages despite what appears to be the world’s highest rate of violent crime.
Obviously, this raises the question: Why is Western Civilization not admitting gorillas? They too are from Africa, and probably have a group mean IQ at least equal to that of Somalia. In addition, they have peaceful and environmentally friendly cultures, commit far less violent crime than Somalians…”
I presume that Langan is working off the assumption that Koko’s IQ is 95. I also presume that he has seen memes such as this one floating around:

There are a few problems with Langan’s claims, however. (1) The notion of a “30-point IQ point communication” rule—that one’s own IQ, plus or minus 30 points, denotes where two people can understand each other; and (2) bringing up Koko’s IQ and the comparing it to “Somalians.”
It seems intuitive to the IQ-ist that a large, 2 SD gap in IQ between people will mean that more often than not there will be little understanding between them if they talk, as well as the kinds of interests they have. Neuroskeptic looked into the origins of the claim of the communication gap in IQ, found it to be attributed to Leta Hollingworth and elucidated by Grady Towers. Towers noted that “a leadership pattern will not form—or it will break up—when a discrepancy of more than about 30 points comes to exist between leader and lead.” Neuroskeptic comments:
This seems to me a significant logical leap. Hollingworth was writing specifically about leadership, and in childen [sic], but Towers extrapolates the point to claim that any kind of ‘genuine’ communication is impossible across a 30 IQ point gap.
It is worth noting that although Hollingworth was an academic psychologist, her remark about leadership does not seem to have been stated as a scientific conclusion from research, but simply as an ‘observation’.
[…]
So as far as I can see the ‘communication range’ is just an idea someone came up with. It’s not based on data. The reference to specific numbers (“+/- 2 standard deviations, 30 points”) gives the illusion of scientific precision, but these numbers were plucked from the air.
The notion that Koko had an “elevated level of thought [that] would have been all but incomprehensible to nearly half the population of Somalia (average IQ 68)” (Langan) is therefore laughable, not only for the reason that a so-called communication gap is false, but for the simple fact that Koko’s IQ was tested using the Cattell Infant Intelligence Scales (CIIS) (Patterson and Linden,1981: 100). It seems to me that Langan has not read the book that Koko’s handlers wrote about her—The Education of Koko (Patterson and Linden, 1981)—since they describe why Koko’s score should not be compared with human infants, so it follows that her score cannot be compared with human adults.
The CIIS was developed “to a downward extension of the Stanford-Binet” (Hooper, Conner, and Umansky, 1986), and so, it must correlate highly with the Stanford-Binet in order to be “valid” (the psychometric benchmark for validity—correlating a new test with the most up-to-date test which had assumed validity; Richardson, 1991, 2000, 2017; Howe, 1997). Hooper, Conner, and Umansky (1986: 160) note in their review of the CIIS, “Given these few strengths and numerous shortcomings, salvaging the Cattell would be a major undertaking with questionable yield. . . . Nonetheless, without more research investigating this instrument, and with the advent of psychometrically superior measures of infant development, the Cattell may be relegated to the role of an historical antecedent.” Items selected for the CIIS—like all IQ tests—“followed a quasi-statistical approach with many items being accepted and rejected subjectively.” They state that many of the items on the CIIS need to be updated with “objective” item analysis—but, as Jensen notes, items emerge arbitrarily from the heads of the test’s constructors.
Patterson—the woman who raised Koko—notes that she “tried to gauge [Koko’s] performance by every available yardstick, and this meant administering infant IQ tests” (Patterson and Linden, 1981: 96). Patterson and Linden (1981: 100) note that Koko did better than human counterparts of her age in certain tasks over others, for example “her ability to complete logical progressions like the Ravens Progressive Matrices test” since she pointed to the answer with no hesitation.
Koko generally performed worse than children when a verbal rather than a pointing response was required. When tasks involved detailed drawings, such as penciling a path through a maze, or precise coordination, such as fitting puzzle pieces together. Koko’s performance was distinctly inferior to that of children.
[…]
It is hard to draw any firm conclusions about the gorilla’s intelligence as compared to that of the human child. Because infant intelligence tests have so much to do with motor control, results tend to get skewed. Gorillas and chimps seem to gain general control over their bodies earlier than humans, although ultimately children far outpace both in the fine coordination required in drawing or writing. In problems involving more abstract reasoning, Koko, when she is willing to play the game, is capable of solving relatively complex problems. If nothing else, the increase in Koko’s mental age shows that she is capable of understanding a number of the principles that are the foundation of what we call abstract thought. (Patterson and Linden, 1981: 100-101)
They conclude that “it is specious to compare her IQ directly with that of a human infant” since gorillas develop motor skills earlier than human infants. So if it is “specious” to compare Koko’s IQ with an infant, then it is “specious” to compare Koko’s IQ with the average Somalian—as Langan does.
There have been many critics of Koko, and similar apes, of course. One criticism was that Koko was coaxed into signing the word she signed by asking Koko certain questions, to Robert Sapolsky stating that Patterson corrected Koko’s signs. She, therefore, would not actually know what she was signing, she was just doing what she was told. Of course, caregivers of primates with the supposed extraordinary ability for complex (humanlike) cognition will defend their interpretations of their observations since they are emotionally invested in the interpretations. Patterson’s Ph.D. research was on Koko and her supposed capabilities for language, too.
Perhaps the strongest criticism of these kinds of interpretations of Koko comes from Terrace et al (1979). Terrace et al (1979: 899) write:
The Nova film, which also shows Ally (Nim’s full brother) and Koko, reveals a similar tendency for the teacher to sign before the ape signs. Ninety-two percent of Ally’s, and all of Koko’s, signs were signed by the teacher immediately before Ally and Koko signed.
It seems that Langan has never done any kind of reading on Koko, the tests she was administered, nor the problems in comparing them to humans (infants). The fact that Koko seemed to be influenced by her handlers to “sign” what they wanted her to sign, too, makes interpretations of her IQ scores problematic. For if Koko were influenced what to sign, then we, therefore, cannot trust her scores on the CIIS. The false claims of Langan are laughable knowing the truth about Koko’s IQ, what her handlers said about her IQ, and knowing what critics have said about Koko and her sign language. In any case, Langan did not show his “high IQ” with such idiotic statements.
The History and Construction of IQ Tests
4100 words
The [IQ] tests do what their construction dictates; they correlate a group’s mental worth with its place in the social hierarchy. (Mensh and Mensh, 1991, The IQ Mythology, pg 30)
We have been attempting to measure “intelligence” in humans for over 100 years. Mental testing began with Galton and then shifted over to Binet, which then became the most-well-known IQ tests today—Stanford-Binet and the WAIS/WISC. But the history of IQ testing is rife with unethical conclusions derived from their use, along with such conclusions they drew actually being carried out (i.e., the sterilization of “morons”; see Wilson, 2017’s The Eugenic Mind Project).
History of IQ testing
Any history of ‘intelligence’ testing will, of course, include Francis Galton’s contributions to the creation of psychological tests (in terms of statistical analyses, the construction of some tests, among other things) to the field. Galton was, in effect, one of the first behavioral geneticists.
Galton (1869: 37) asked “Is reputation a fair test of natural ability?“, to which he answered, “it is the only one I can employ.” Galton, for example, stated that, theoretically or intuitively, there is a relationship between reaction time and intelligence (Khodadi et al, 2014). Galton then devised tests of “reaction time, discrimination in sight and hearing, judgment of length, and so on, and applied them to groups of volunteers, with the aim of obtaining a more reliable and ‘pure’ measure of his socially judged intelligence” (Richardson, 1991: 19). But there was little to no relationship between Galton’s proposed proxies for intelligence and social class.
In 1890, Galton, publishing in the journal Mind coined the term “mental test (Castles, 2012: 85), while Cattell then got Galton to move to Columbia and got him permission to use his “mental tests” to all of the entering students. This was about two decades before Goddard brought the test to America—Galton and Cattell were just getting America warmed up for the testing process.
Yet others still attempted to create tests that were purported to measure intelligence, using similar kinds of parameters as Galton. For instance, Miller, 1962 provides a list (quoted in Richardson, 1991: 19):
1 Dynamotor pressure How tightly can the hand squeeze?
2 Rate of movement How quickly can the hand move through a distance of 30 cms?
3 Sensation areas How far apart must two points be on the skin to be recognised as two rather than one?
4 Pressure causing pain How much pressure on the forehead is necessary to cause pain?
5 Least noticeable difference in weight How large must the difference be between two weights before it is reliably detected?
6 Reaction-time for sound How quickly can the hand be moved at the onset of an auditory signal?
7 Time for naming colours How long does it take to name a strop of ten colored papers?
8 Bisection on a 10 cm line How accurately can onr point to the centre of an ebony rule?
9 Judgment of 10 sec time How accurately can an interval of 10 secs be judged?
10 Number of letters remembered on once hearing How many letters, ordered at random, can be repeated exactly after one presentation?
Individuals differed on these measures, but when they were used to compare social classes, Cattell stated that they were “disappointingly low” (quoted in Richardson, 1991: 20). So-called mental tests, Richardson (1991: 20) states, were “not [a] measurement for a straightforward, objective scientific investigation. The theory was there, but it was hardly a scientific one, but one derived largely from common intuition; what we described earlier as a popular or informal theory. And the theory had strong social implications. Measurement was devised mainly as a way of applying the theory in accordance with the prejudices it entailed.”
It wasn’t until 1903 when Alfred Binet was tasked to construct a test that identified slow learners in grade-school. In 1904, Binet was appointed a member of a commission on special classes in schools (Murphy, 1949: 354). In fact, Binet constructed his test in order to limit the role of psychiatrists in making decisions on whether or not healthy children—but ‘abnormal’—children should be excluded from the standard material used in regular schools (Nicolas et al, 2013). (See Nicolas et al, 2013 for a full overview of the history of intelligence in Psychology and a fuller overview of Binet and Simon’s test and why they constructed it. Also see Fancher, 1985 and )
The way Binet constructed his tests were in a way to identify children who were not learning what the average child their age knew. But the tests must distinguish between the lazy from the mentally deficient. So in 1905, Binet teamed up with Simon, and they published their first IQ test, with items arranged from the simplest to the most difficult (but with no standardization). A few of these items include: naming objects, completing sentences, comparing lines, comprehending questions, and repeating digits. Their test consisted of 30 items, which increased in difficulty from easiest to hardest and the items were chosen on the basis of teacher assessment and checking the items and seeing which discriminated which child and that also agreed with the constructors’ presuppositions.
Richardson (2000: 32) discusses how IQ tests are constructed:
In this regard, the construction of IQ tests is perhaps best thought of as a reformatting exercise: ranks in one format (teachers’ estimates) are converted into ranks in another format (test scores, see figure 2.1).
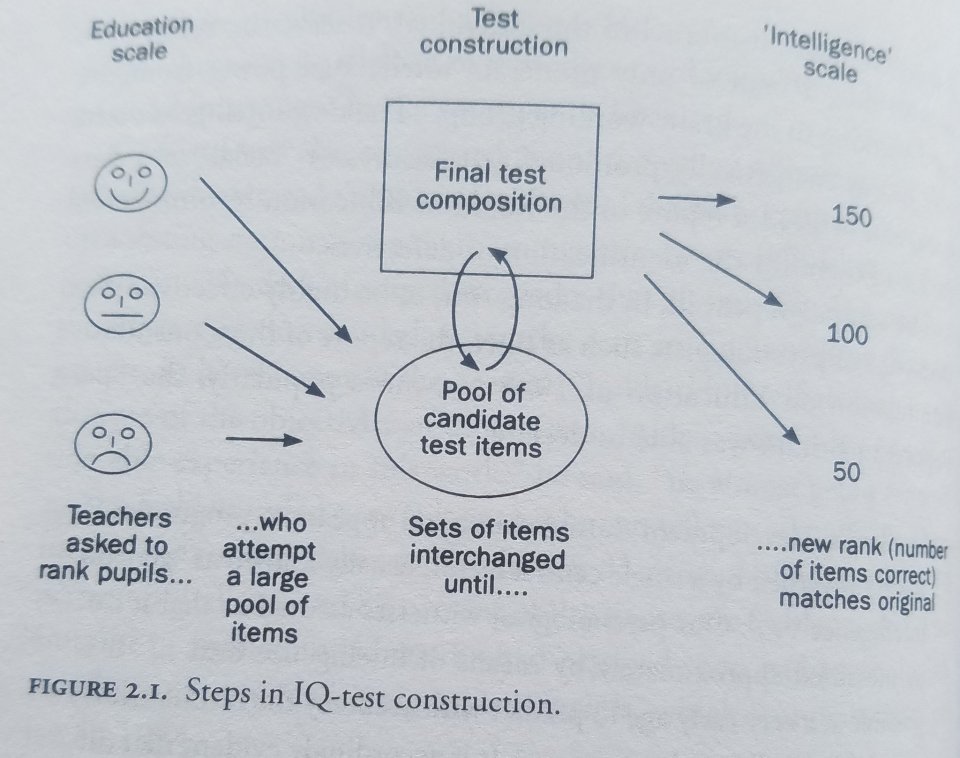
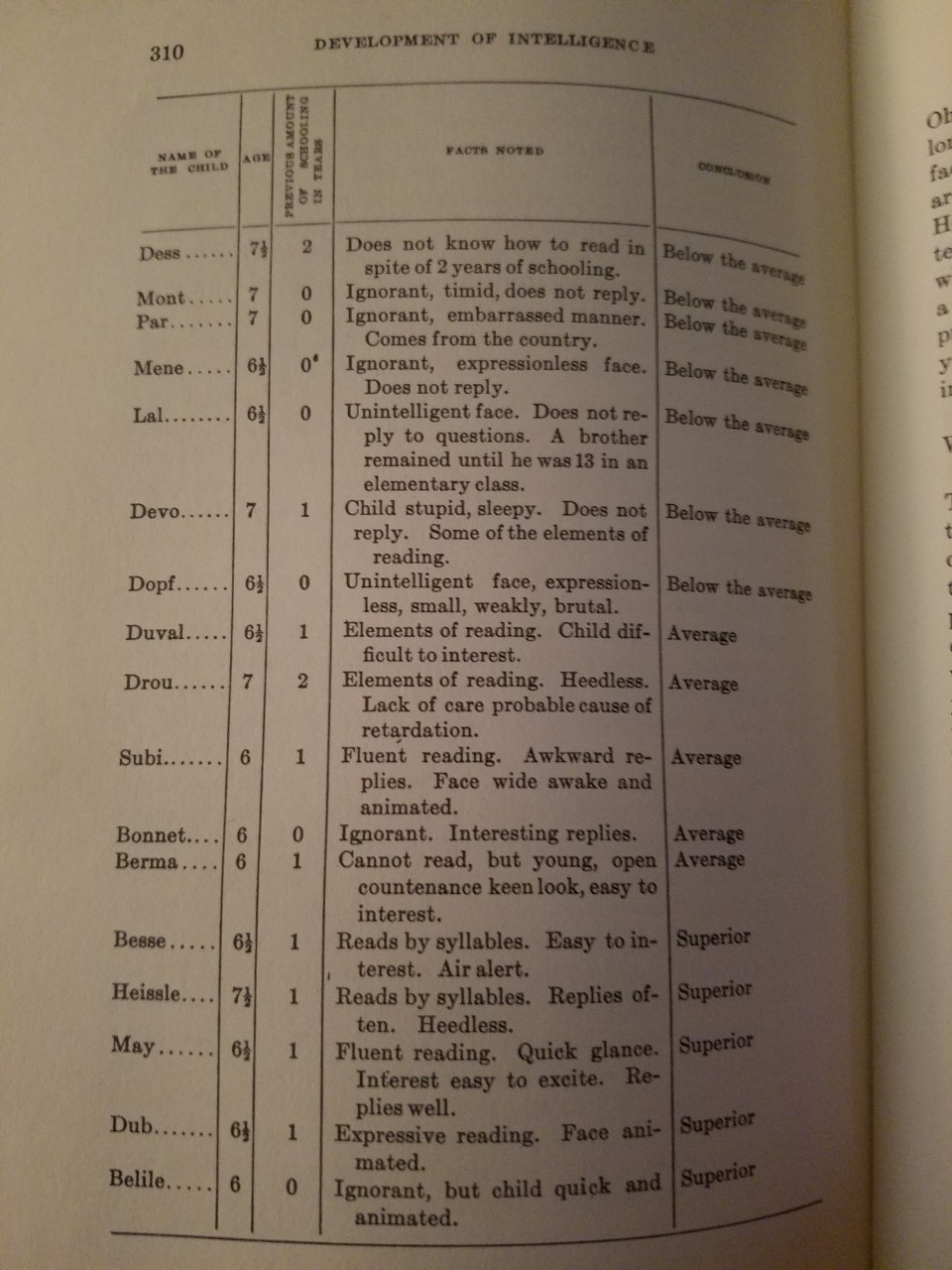
In The Development of Intelligence in Children, Binet and Simon (1916: 309) discuss how teachers assessed students:
A teacher , whom I know, who is methodical and considerate, has given an account of the habits he has formed for studying his pupils; he has analysed his methods, and sent them to me. They have nothing original, which makes them all the more important. He instructs children from five and a half to seven and a half years old; they are 35 in number; they have come to his class after having passed a prepatory course, where they have commenced to learn to read. For judging each child, the teacher takes account of his age, his previous schooling (the child may have been one year, two years in the prepatory class, or else was never passed through the division at all), of his expression of countenance, his state of health, his knowledge, his attitude in class, and his replies. From thes diverse elements he forms his opinion. I have transcribed some of these notes on the following page.
In reading his judgments one can see how his opinion was formed, and of how many elements it took account; it seems to us that this detail is interesting; perhaps if one attempted to make it precise by giving coefficients to all of these remarks, one would realize still greater exactitude. But is it possible to define precisely an attitude, a physiognomy, interesting replies, animated eyes? It seems that in all this the best element of diagnosis is furnished by the degree of reading which the child has attained after a given number of months, and the rest remains constantly vague.
Binet chose the items used on his tests for practical, not theoretical reasons. They then learned that some of their tests were harder, and others were easier, so they then arranged their tests by age levels: how well the average child for that age could complete the test in question. For example, if the average child could complete 10/20 for their age group, then they were average for that age. Then, if they scored below that, they were below average and above that they were higher than average. So the “mental age” for the child in question was calculated with the following formula: IQ=MA/CA*100. So if one’s MA (mental age) was 13 and their chronological age was 9, then their IQ would be 144.
Before Binet’s death in 1911, he revised his and Simon’s previous test. Intelligence, to Binet, is “the ability to understand directions, to maintain a mental set, and to apply “autocriticism” (the correction of one’s own errors)” (Murphy, 1949: 355). Binet measured subnormality by subtracting mental age from chronological age. (If mental and chronological age are equal, then IQ is 100.) To Binet, relative retardation was important. But William Stern, in 1912, thought that relative retardation was not important, but relative retardation was, and so he proposed to divide the mental age by the chronological age and multiply by 100. This, he showed, was stable in most children.
Binet termed his new scale a test of intelligence. It is interesting to note that the primary connotation of the French term l’intelligence in Binet’s time was what we might call “school brightness,” and Binet himself claimed no function for his scales beyond that of measuring academic aptitude.
In 1908, Henry Goddard went on a trip to Europe, heard of Binet’s test, and brought home an original version to try out on his students at the Vineland Training School. He translated Binet’s 1908 edition of his test from French to English in 1909. Castles (2012: 90) notes that “American psychology would never be the same.” Goddard was also the one who coined the term “moron” (Dolmage, 2018) for any adult with a mental age between 8 and 13. In 1912, Goddard administered tests to immigrants who landed at Ellis Island and found that 87 percent of Russians, 83 percent of Jews, 80 percent of Hungarians, and 79 percent of Italians were “feebleminded.” Deportations soon picked up, with Goddard reporting a 350 percent increase in 1913 and a 570 percent increase in 1914 (Mensh and Mensh, 1991: 26).
Then, in 1916, Terman published his revision of the Binet-Simon scale, which he termed the Stanford-Binet intelligence scale, based on a sample of 1,000 subjects and standardized for ages ranging from 3-18—the tests for 16-year-olds being were for adults, whereas the tests for 18-year-olds were for ‘superior’ adults (Murphy, 1949: 355). (Terman’s test was revised in 1937, when the question of sex differences came up, see below, and in 1960.) Murphy (1949: 355) goes on to write:
Many of Binet’s tests were placed at higher or lower age levels than those at which Binet had placed them, and new tests were added. Each age level was represented by a battery of tests, each test being assigned a certain number of month credits. It was possible, therefore, to reckon the subject’s intelligence quotient, as Stern had suggested, in terms of the ratio of mental age to chronological age. A child attaining a score of 120 months, but only 100 months old, would have an IQ of 120 (the decimal point omitted).
It wasn’t until 1917 that psychologists devised the Army Alpha test for literate test-takers and the Army Beta test for illiterate test-takers and non-English speakers. Examples for items on the Alpha and the Beta can be found below:
1. The Percheron is a kind of
(a) goat, (b) horse, (c) cow, (d) sheep.
2. The most prominent industry of Gloucester is
(a) fishing, (b) packing, (c) brewing, (d) automobiles.
3. “There’s a reason” is an advertisement for
(a) drink, (b) revolver, (c) flour, (d) cleanser.
4. The Knight engine is used in the
(a) drink, (b) Stearns, (c) Lozier, (d) Pierce Arrow.
5. The Stanchion is used in
(a) fishing, (b) hunting, (c) farming, (d) motoring. (Heine, 2017: 187)

Mensh and Mensh (1991: 31) tell us that
… the tests’ very lack of effect on the placement of [army] personnel provides the clue to their use. The tests were used to justify, not alter, the army’s traditional personnel policy, which called for the selection of officers from among relatively affluent whites and the assignment of white of lower socioeconomic status go lower-status roles and African-Americans at the bottom rung.
Meanwhile, while Binet was devising his Binet scales at the beginning of the 20th century, Spearman was devising his theory of g over in Europe. Spearman noted in 1904 that children who did well or poorly on certain types of tests did well or poorly on all of them—they were correlated. Spearman’s discovery was that correlated scores reflect a common ability, and this ability is called ‘general intelligence’ or ‘g’ (which has been widely criticized).
In sum, the conception of ‘intelligence tests’ began as a way to attempt to justify the class/race hierarchy by constructing the tests in a way to agree with the constructors’ presuppositions of who is or is not intelligent—which will be covered below.
Test construction
When tests are standardized, a whole slew of candidate items are pooled together and used in the construction of the test. For an item to be used for the final test, it must agree with the a priori assumptions of the test’s constructors on who is or is not “intelligent.”
Andrew Strenio, author of The Testing Trap states exactly how IQ tests are constructed, writing:
We look at individual questions and see how many people get them right and who gets them right. … We consciously and deliberately select questions so that the kind of people who scored low on the pretest will score low on subsequent tests. We do the same for middle or high scorers. We are imposing our will on the outcome. (pg 95, quoted in Mensh and Mensh, 1991)
Richardson (2017a: 82) writes that IQ tests—and the items on them—are:
still based on the basic assumption of knowing in advance who is or is not intelligent and making up and selecting items accordingly. Items are invented by test designers themselves or sent out to other psychologists, educators, or other “experts” to come up with ideas. As described above, initial batches are then refined using some intuitive guidelines.
This is strange… I thought that IQ tests were “objective”? Well, this shows that they are anything but objective—they are, very clearly, subjective in their construction which leads to what the constructors of the test assumed—their score hierarchy. The test’s constructors assume that their preconceptions on who is or is not intelligent is true and that differences in intelligence are the cause for differences in social class, so the IQ test was created to justify the existing social hierarchy. (Nevermind the fact that IQ scores are an index of social class, Richardson, 2017b.)
Mensh and Mensh (1991: 5) write that:
Nor are the [IQ] tests objective in any scientific sense. In the special vocabulary of psychometrics, this term refers to the way standardized tests are graded, i.e., according to the answers designated “right” or “wrong” when the questions are written. This definition not only overlooks that the tests contain items of opinion, which cannot be answered according to universal standards of true/false, but also overlooks that the selection of items is an arbitrary or subjective matter.
Nor do the tests “allocate benefits.” Rather, because of their class and racial biases, they sort the test takers in a way that conforms to the existing allocation, thus justifying it. This is why the tests are so vehemently defended by some and so strongly opposed by others.
When it comes to Terman and his reconstruction of the Binet-Simon—which he called the Stanford-Binet—something must be noted.
There are negligible differences in IQ between men and women. In 1916, Terman thought that the sexes should be equal in IQ. So he constructed his test to mirror his assumption. Others (e.g., Yerkes) thought that whatever differences materialized between the sexes on the test should be kept and boys and girls should have different norms. Terman, though, to reflect his assumption, specifically constructed his test by including subtests in which sex differences were eliminated. This assumption is still used today. (See Richardson, 1998; Hilliard, 2012.) Richardson (2017a: 82) puts this into context:
It is in this context that we need to assess claims about social class and racial differences in IQ. These could be exaggerated, reduced, or eliminated in exactly the same way. That they are allowed to persist is a matter of social prejudice, not scientific fact. In all these ways, then, we find that the IQ testing movement is not merely describing properties of people—it has largely created them.
This is outright admission from the test’s constructors themselves that IQ differences can be built into and out of the test. It further shows that these tests are not “objective”, as they claim. In reality, they are subjective, based on prior assumptions. Take what Hilliard (2012: 115-116) noted about two white South African groups and differences in IQ between them:
A consistent 15- to 20-point IQ differential existed between the more economically privileged, better educated, urban-based, English-speaking whites and the lower-scoring, rural-based, poor, white Afrikaners. To avoid comparisons that would have led to political tensions between the two white groups, South African IQ testers squelched discussion about genetic differences between the two European ethnicities. They solved the problem by composing a modified version of the IQ test in Afrikaans. In this way they were able to normalize scores between the two white cultural groups.
The SAT suffers from the same problems. Mensh and Mensh (1991: 69) note that “the SAT has been weighted to widen a gender scoring differential that from the start favored males.” They note that, since the SAT’s inception, men have score higher than women, but the gap was due primarily to men’s scores on the math subtest “which was partially offset until 1972 by women’s higher scores on the verbal subtest.” But by 1986 men outscored women on the verbal portion, with the ETS stating that they created a “better balance for the scores between sexes” (quoted in Mensh and Mensh, 1991: 69). What they did, though, was exactly what Terman did: they added items where the context favored men and eliminated those that favored women. This prompts Hilliard (2012: 118) to ask “How then could they insist with such force that no cultural biases existed in the IQ tests given blacks, who scored 15 points below whites?”
When it comes to test bias, Mensh and Mensh (1991: 51) write that:
From a functional standpoint, there is no distinction between crassly biased IQ-test items and those that appear to be non-biased. Because all types of test items are biased (if not explicitly, then implicitly, or in some combination thereof), and because the tests’ racial and class biased correspond to the society’s, each element of a test plays its part in ranking children in the way their respective groups are ranked in the social order.
This, then, returns to the normal distribution—the Gaussian distribution or bell curve.
The normal distribution is assumed. Items are selected to conform with the normal curve after the fact by trying out a whole slew of items for which Jensen (1980: 147-148) states that “items must simply emerge arbitrarily from the heads of test constructors.” Items that show little correlation with the testers’ expectations are then removed from the final test. Fischer et al (1996), Simon (1997), Richardson (1991; 1998; 2017) also discuss the myth of the normal distribution and how it is constructed by IQ test-makers. Further, Jensen brings up an important point about items emerging “arbitrarily from the heads of test constructors.” That is, test constructors have their idea in their head on who is or is not ‘intelligent’, they then try out a whole slew of items, and, unsurprisingly, they get the type of score distribution they want! Howe (1997: 20) writes that:
However, it is wrongly assumed that the fact that IQ scores have a bell-shaped distribution implies that differing intelligence levels of individuals are ‘naturally’ distributed in that way. This is incorrect: the bell-shaped distribution of IQ scores is an artifical product that results from test-makers initially assuming that intelligence is normally distributed, and then matchinig IQ scores to differing levels of test performance in a manner that results in a bell-shaped curve.
Richardson (1991) notes that the normal distribution “is achieved in the IQ test by the simple decision of including more items on which an average number of the trial group performed well, and relatively fewer on which either a substantial majority or a minority of subjects did well. Richardson (1991) also states that “if the bell-shaped curve is the myth it seems to be—for IQ as for much else—then it is devastating for nearly all discussion surrounding it.” Even Jensen (1980: 71) states that “It is claimed that the psychometrist can make up a test that will yield any kind of score distribution he pleases. This is roughly true, but some types of distributions are much easier to obtain than others.”
The [IQ test] items are, after all, devised by test designers from a very narrow social class and culture, based on intuitions about intelligence and variation in it, and on a technology of item selection which builds in the required degree of convergence of performance. (Richardson, 1991)
Micceri (1988) examined score distributions from 400 tests administered all over the US in workplaces, universities, and schools. He found significant non-normal distributions of test scores. The same can be said about physiological processes, as well.
Candidate items are administered to a sample population, and to be selected for the final test, the question must establish the scoring norm for the whole group, along with subtest norms which is supposed to replicate when the test is then released for general use. So an item must play the role in creating a distribution of scores that places each subgroup (of people) in its predetermined place on the (artifact of test construction’s) normal curve. It is then how Hilliard (2012: 118) notes:
Validating a newly drawn-up IQ exam involved giving it to a prescribed sample population to determine whether it measured what it was designed to assess. The scores were then correlated, that is, compared with the test designers’ presumptions. If the individuals who were supposed to come out on top didn’t score highly or, conversely, if the individuals who were assumed would be at the bottom of the scores didn’t end up there, then the designers would scrap the test.
Howe (1997: 6) states that “A psychological test score is no more than an indication of how well someone has performed at a number of questions that have been chosen for largely practical reasons. Nothing is genuinely being measured.” Howe (1997: 17) also noted that:
Because their construction has never been guided by any formal definition of what intelligence is, intelligence tests are strikingly different from genuine measuring instruments. Binet and Simon’s choice of items to include as the problems that made up their test was based purely on practical considerations.
IQ tests are ‘validated’ against older tests such as the Stanford-Binet, but the older tests were never validated themselves (see Richardson, 2002: 301.) Howe (1997: 18) continues:
In the case of the Binet and Simon test, since their main purpose was to help establish whether or not a child was capable of coping with the conventional school cirriculum, they sensibly chose items that seemed to assess a child’s capacity to succeed at the kinds of mental problems that are encountered in the classroom. Importantly, the content of the first intelligence test was decided by largely pragmatic considerations rather than being constrained by a formal definition of intelligence. That remains largely true of the tests that are used even now. As the early tests were revised and new assessment batteries constructed, the main benchmark for believing a new test to be adequate was its degree of agreement with the older ones. Each new test was assummed to be a proper measure of intelligence if the distributions of people’s scores at it matched the pattern of scores at a previous test, a line of reasoning that conveniently ignored the fact that the earlier ‘measures’ of intelligence that provided the basis for confirming the quality of the subsequent ones were never actually measures of anything. In reality … intelligence tests are very different from true measures (Nash, 1990). For instance, with a measure such as height it is clear that a particular quantity is the same irrespective of where it occurs. The 5 cm difference between 40 cm and 45 cm is the same as the 5 cm difference between 115 cm and 120 cm, but the same cannot be said about differing scores gained in a psychological test.
Conclusion
This discussion of the construction of IQ tests and the history of IQ testing can lead us to one conclusion: that differences in scores can be built into and out of the tests based on the prior assumptions of the test’s constructors; the history of IQ testing is rife with these same assumptions; and all newer tests are ‘validated’ on their agreement with older—still non-valid!—tests. The genesis of IQ testing beginning with social prejudices, constructing the tests to agree with the current hierarchy, however, does indeed damn the conclusions of the tests—that group A outscores group B does not mean that A is more ‘intelligent’ than B; it only means that A was exposed to more of the knowledge on the test.
The normal distribution, too, is a result of the same item addition/elimination to get the expected scores—the scores that then agree with the constructors’ racial and class biases. Bias in mental testing does exist, contra Jensen (1980). It exists due to carefully selected items to distinguish between different racial groups and social classes.
This critique in IQ testing I have mounted is not an ‘environmentalist’ critique, either. It is a methodological one.
Jews, IQ, Genes, and Culture
1500 words
Jewish IQ is one of the most-talked-about things in the hereditarian sphere. Jews have higher IQs, Cochran, Hardy, and Harpending (2006: 2) argue due to “the unique demography and sociology of Ashkenazim in medieval Europe selected for intelligence.” To IQ-ists, IQ is influenced/caused by genetic factors—while environment accounts for only a small portion.
In The Chosen People: A Study of Jewish Intelligence, Lynn (2011) discusses one explanation for higher Jewish IQ—that of “pushy Jewish mothers” (Marjoribanks, 1972).
“Fourth, other environmentalists such as Majoribanks (1972) have argued that the high intelligence of the Ashkenazi Jews is attributable to the typical “pushy Jewish mother”. In a study carried out in Canada he compared 100 Jewish boys aged 11 years with 100 Protestant white gentile boys and 100 white French Canadians and assessed their mothers for “Press for Achievement”, i.e. the extent to which mothers put pressure on their sons to achieve. He found that the Jewish mothers scored higher on “Press for Achievement” than Protestant mothers by 5 SD units and higher than French Canadian mothers by 8 SD units and argued that this explains the high IQ of the children. But this inference does not follow. There is no general acceptance of the thesis that pushy mothers can raise the IQs of their children. Indeed, the contemporary consensus is that family environmental factors have no long term effect on the intelligence of children (Rowe, 1994).
The inference is a modus ponens:
P1 If p, then q.
P2 p.
C Therefore q.
Let p be “Jewish mothers scored higher on “Press for Achievement” by X SDs” and let q be “then this explains the high IQ of the children.”
So now we have:
Premise 1: If “Jewish mothers scored higher on “Press for Achievement” by X SDs”, then “this explains the high IQ of the children.”
Premise 2: “Jewish mothers scores higher on “Press for Achievement” by X SDs.”
Conclusion: Therefore, “Jewish mothers scoring higher on “Press for Achievement” by X SDs” so “this explains the high IQ of the children.”
Vaughn (2008: 12) notes that an inference is “reasoning from a premise or premises to … conclusions based on those premises.” The conclusion follows from the two premises, so how does the inference not follow?
IQ tests are tests of specific knowledge and skills. It, therefore, follows that, for example, if a “mother is pushy” and being pushy leads to studying more then the IQ of the child can be raised.
Looking at Lynn’s claim that “family environmental factors have no long term effect on the intelligence of children” is puzzling. Rowe relies heavily on twin and adoption studies which have false assumptions underlying them, as noted by Richardson and Norgate (2005), Moore (2006), Joseph (2014), Fosse, Joseph, and Richardson (2015), Joseph et al (2015). The EEA is false so we, therefore, cannot accept the genetic conclusions from twin studies.
Lynn and Kanazawa (2008: 807) argue that their “results clearly support the high intelligence theory of Jewish achievement while at the same time provide no support for the cultural values theory as an explanation for Jewish success.” They are positing “intelligence” as an explanatory concept, though Howe (1988) notes that “intelligence” is “a descriptive measure, not an explanatory concept.” “Intelligence, says Howe (1997: ix) “is … an outcome … not a cause.” More specifically, it is an outcome of development from infancy all the way up to adulthood and being exposed to the items on the test. Lynn has claimed for decades that high intelligence explains Jewish achievement. But whence came intelligence? Intelligence develops throughout the life cycle—from infancy to adolescence to adulthood (Moore, 2014).
Ogbu and Simon (1998: 164) notes that Jews are “autonomous minorities”—groups with a small number. They note that “Although [Jews, the Amish, and Mormons] may suffer discrimination, they are not totally dominated and oppressed, and their school achievement is no different from the dominant group (Ogbu 1978)” (Ogbu and Simon, 1998: 164). Jews are voluntary minorities, and voluntary minorities, according to Ogbu (2002: 250-251; in Race and Intelligence: Separating Science from Myth) suggests five reasons for good test performance from these types of minorities:
- Their preimmigration experience: Some do well since they were exposed to the items and structure of the tests in their native countries.
- They are cognitively acculturated: They acquired the cognitive skills of the white middle-class when they began to participate in their culture, schools, and economy.
- The history and incentive of motivation: They are motivated to score well on the tests as they have this “preimmigration expectation” in which high test scores are necessary to achieve their goals for why they emigrated along with a “positive frame of reference” in which becoming successful in America is better than becoming successful at home, and the “folk theory of getting ahead in the United States”, that their chance of success is better in the US and the key to success is a good education—which they then equate with high test scores.
So if ‘intelligence’ is a test of specific culturally-specific knowledge and skills, and if certain groups are exposed more to this knowledge, it then follows that certain groups of people are better-prepared for test-taking—specifically IQ tests.
The IQ-ists attempt to argue that differences in IQ are due, largely, to differences in ‘genes for’ IQ, and this explanation is supposed to explain Jewish IQ, and, along with it, Jewish achievement. (See also Gilman, 2008 and Ferguson, 2008 for responses to the just-so storytelling from Cochran, Hardy, and Harpending, 2006.) Lynn, purportedly, is invoking ‘genetic confounding’—he is presupposing that Jews have ‘high IQ genes’ and this is what explains the “pushiness” of Jewish mothers. The Jewish mothers then pass on their “genes for” high IQ—according to Lynn. But the evolutionary accounts (just-so stories) explaining Jewish IQ fail. Ferguson (2008) shows how “there is no good reason to believe that the argument of [Cochran, Hardy, and Harpending, 2006] is likely, or even reasonably possible.” The tall-tale explanations for Jewish IQ, too, fail.
Prinz (2014: 68) notes that Cochran et al have “a seductive story” (aren’t all just-so stories seductive since they are selected to comport with the observation? Smith, 2016), while continuing (pg 71):
The very fact that the Utah researchers use to argue for a genetic difference actually points to a cultural difference between Ashkenazim and other groups. Ashkenazi Jews may have encouraged their children to study maths because it was the only way to get ahead. The emphasis remains widespread today, and it may be the major source of performance on IQ tests. In arguing that Ashkenazim are genetically different, the Utah researchers identify a major cultural difference, and that cultural difference is sufficient to explain the pattern of academic achievement. There is no solid evidence for thinking that the Ashkenazim advantage in IQ tests is genetically, as opposed to culturally, caused.
Nisbett (2008: 146) notes other problems with the theory—most notably Sephardic over-achievement under Islam:
It is also important to the Cochran theory that Sephardic Jews not be terribly accomplished, since they did not pass through the genetic filter of occupations that demanded high intelligence. Contemporary Sephardic Jews in fact do not seem to haave unusally high IQs. But Sephardic Jews under Islam achieved at very high levels. Fifteen percent of all scientists in the period AD 1150-1300 were Jewish—far out of proportion to their presence in the world population, or even the population of the Islamic world—and these scientists were overwhelmingly Sephardic. Cochran and company are left with only a cultural explanation of this Sephardic efflorescence, and it is not congenial to their genetic theory of Jewish intelligence.
Finally, Berg and Belmont (1990: 106) note that “The purpose of the present study was to clarify a possible misinterpretation of the results of Lesser et al’s (1965) influential study that suggested that existence of a “Jewish” pattern of mental abilities. In establishing that Jewish children of different socio-cultural backgrounds display different patterns of mental abilities, which tend to cluster by socio-cultural group, this study confirms Lesser et al’s position that intellectual patterns are, in large part, culturally derived.” Cultural differences exist; cultural differences have an effect on psychological traits; if cultural differences exist and cultural differences have an effect on psychological traits (with culture influencing a population’s beliefs and values) and IQ tests are culturally-/class-specific knowledge tests, then it necessarily follows that IQ differences are cultural/social in nature, not ‘genetic.’
In sum, Lynn’s claim that the inference does not follow is ridiculous. The argument provided is a modus ponens, so the inference does follow. Similarly, Lynn’s claim that “pushy Jewish mothers” don’t explain the high IQs of Jews doesn’t follow. If IQ tests are tests of middle-class knowledge and skills and they are exposed to the structure and items on them, then it follows that being “pushy” with children—that is, getting them to study and whatnot—would explain higher IQs. Lynn’s and Kanazawa’s assertion that “high intelligence is the most promising explanation of Jewish achievement” also fails since intelligence is not an explanatory concept—a cause—it is a descriptive measure that develops across the lifespan.
Knowledge, Culture, Logic, and IQ
5050 words
… what IQ tests actually assess is not some universal scale of cognitive strength but the presence of skills and knowledge structures more likely to be acquired in some groups than in others. (Richardson, 2017: 98)
For the past 100 years, the black-white IQ gap has puzzled psychometricians. There are two camps—hereditarians (those who believe that individual and group differences in IQ are due largely to genetics) and environmentalists/interactionists (those who believe that individual and group differences in IQ are largely due to differences in learning, exposure to knowledge, culture and immediate environment).
Knowledge
However, one of the most forceful arguments for the environmentalist (i.e., that the cause for differences in IQ are due to the cultural and social environment; note that an interactionist framework can be used here, too) side is one from Fagan and Holland (2007). They show that half of the questions on IQ tests had no racial bias, whereas other problems on the test were solvable with only a specific type of knowledge – knowledge that is found specifically in the middle class. So if blacks are more likely to be lower class than whites, then what explains lower test scores for blacks is differential exposure to knowledge – specifically, the knowledge to complete the items on the test.
But some hereditarians say otherwise – they claim that since knowledge is easily accessible for everyone, then therefore, everyone who wants to learn something will learn it and thus, the access to information has nothing to do with cultural/social effects.
A hereditarian can, for instance, state that anyone who wants to can learn the types of knowledge that are on IQ tests and that they are widely available everywhere. But racial gaps in IQ stay the same, even though all racial groups have the same access to the specific types of cultural knowledge on IQ tests. Therefore, differences in IQ are not due to differences in one’s immediate environment and what they are exposed to—differences in IQ are due to some innate, genetic differences between blacks and whites. Put into premise and conclusion form, the argument goes something like this:
P1 If racial gaps in IQ were due specifically to differences in knowledge, then anyone who wants to and is able to learn the stuff on the tests can do so for free on the Internet.
P2 Anyone who wants to and is able to learn stuff can do so for free on the Internet.
P3 Blacks score lower than whites on IQ tests, even though they have the same access to information if they would like to seek it out.
C Therefore, differences in IQ between races are due to innate, genetic factors, not any environmental ones.
This argument is strange. One would have to assume that blacks and whites have the same access to knowledge—we know that lower-income people have less access to knowledge in virtue of the environments they live in. For instance, they may have libraries with low funding or bad schools with teachers who do not care enough to teach the students what they need to succeed on these standardized tests (IQ tests, the SAT, etc are all different versions of the same test). (2) One would have to assume that everyone has the same type of motivation to learn what amounts to answers for questions on a test that have no real-world implications. And (3) the type of knowledge that one is exposed to dictates what one can tap into while they are attempting to solve a problem. All three of these reasons can cascade in causing the racial performance in IQ.
Familiarity with the items on the tests influences a faster processing of information, allowing one to correctly identify an answer in a shorter period of time. If we look at IQ tests as tests of middle-class knowledge of skills, and we rightly observe that blacks are lower class than whites who are more likely to be middle class, then it logically follows that the cause of differences in IQ between blacks and whites are cultural – and not genetic – in origin. This paper – and others – solves the century-old debate on racial IQ differences – what accounts for differences in IQ scores is differential exposure to knowledge. Claiming that people have the same type of access to knowledge and, thusly, won’t learn it if they won’t seek it out does not make sense.
Differing experiences lead to differing amounts of knowledge. If differing experiences lead to differing amounts of knowledge, and IQ tests are tests of knowledge—culturally-specific knowledge—then those who are not exposed to the knowledge on the test will score lower than those who are exposed to the knowledge. Therefore, Jensen’s Default Hypothesis is false (Fagan and Holland, 2002). Fagan and Holland (2002) compared blacks and whites on for their knowledge of the meaning of words, which are highly “g”-loaded and shows black-white differences. They review research showing that blacks have lower exposure to words and are therefore unfamiliar with certain words (keep this in mind for the end). They mixed in novel words with previously-known words to see if there was a difference.
Fagan and Holland (2002) picked out random words from the dictionary, then putting them into a sentence to attempt to give the testee some context. They carried out five experiments in all, and each one showed that, when equal opportunity was given to the groups, they were “equal in knowledge” (IQ). So, whites were more likely to know the items more likely to be found on IQ tests. Thus, there were no racial differences between blacks and whites when looked at from an information-processing point of view. Therefore, to expain racial differences in IQ, we must look to differences in the cultural/social environment. Fagan (2000) for instance, states that “Cultures may differ in the types of knowledge their members have but not in how well they process. Cultures may account for racial differences in IQ.”
The results of Fagan and Holland (2002) are completely at-ends with Jensen’s Default Hypothesis—that the 15-point gap in IQ is due to the same environmental and cultural factors that underlie individual differences in the group. However, as Fagan and Holland (2002: 382) show that:
Contrary to what the default hypothesis would predict, however, the within racial group analyses in our study stand in sharp contrast to our between racial group findings. Specifically, individuals within a racial group who differed in general knowledge of word meanings also differed in performance when equal exposure to the information to be tested was provided. Thus, our results suggest that the average difference of 15 IQ points between Blacks and Whites is not due to the same genetic and environmental factors, in the same ratio, that account for differences among individuals within a racial group in IQ.
Exposure to information is critical, in fact. For instance, Ceci (1996) shows that familiarity with words dictates speed of processing to use in identifying the correct answer to the problem. In regard to differences in IQ, Ceci (1996) does not deny the role of biology—indeed, it’s a part of his bio-ecological model of IQ, which is a theory that postulates the development of intelligence as an interaction between biological dispositions and the environment in which those dispositions manifest themselves. Ceci (1996) does note that there are biological constraints on intelligence, but that “… individual differences in biological constraints on specific cognitive abilities are not necessarily (or even probably) directly responsible for producing the individual differences that have been reported in the psychometric literature.” That such potentials, though may be “genetic” in origin, of course, does not license the claim that genetic factors contribute to variance in IQ. “Everyone may possess them to the same degree, and the variance may be due to environment and/or motivations that led to their differential crystallization.” (Ceci, 1996: 171)
Ceci (1996) also further shows that people can differ in intellectual performance due to 3 things: (1) the efficiency of underlying cognitive potentials that are relevant to the cognitive ability in question; (2) the structure of knowledge relevant to the performance; and (3) contextual/motivational factors relevant to crystallize the underlying potentials gained through one’s knowledge. Thus, if one is lacking in the knowledge of the items on the test due to what they learned in school, then the test will be biased against them since they did not learn the relevant information on the tests.
Cahan and Cohen (1989) note that nine-year-olds in fourth grade had higher IQs than nine-year-olds in third grade. This is to be expected, if we take IQ scores as indices of—cultural-specific—knowledge and skills and this is because fourth-graders have been exposed to more information than third-graders. In virtue of being exposed to more information than their same-age cohort in different grades, they then score higher on IQ tests because they are exposed to more information.
Cockroft et al (2015) studied South African and British undergrads on the WAIS-III. They conclude that “the majority of the subtests in the WAIS-III hold cross-cultural biases“, while this is “most evident in tasks which tap crystallized, long-term learning, irrespective of whether the format is verbal or non-verbal” so “This challenges the view that visuo-spatial and non-verbal tests tend to be culturally fairer than verbal ones (Rosselli and Ardila, 2003)”.
IQ tests “simply reflect the different kinds of learning by children from different (sub)cultures: in other words, a measure of learning, not learning ability, and are merely a redescription of the class structure of society, not its causes … it will always be quite impossible to measure such ability with an instrument that depends on learning in one particular culture” (Richardson, 2017: 99-100). This is the logical position to hold: for if IQ tests test class-specific type of knowledge and certain classes are not exposed to said items, then they will score lower. Therefore, since IQ tests are tests of a certain kind of knowledge, IQ tests cannot be “a measure of learning ability” and so, contra Gottfredson, ‘g’ or ‘intelligence’ (IQ test scores) cannot be called “basic learning ability” since we cannot create culture—knowledge—free tests because all human cognizing takes place in a cultural context which it cannot be divorced from.
Since all human cognition takes place through the medium of cultural/psychological tools, the very idea of a culture-free test is, as Cole (1999) notes, ‘a contradiction in terms . . . by its very nature, IQ testing is culture bound’ (p. 646). Individuals are simply more or less prepared for dealing with the cognitive and linguistic structures built in to the particular items. (Richardson, 2002: 293)
Heine (2017: 187) gives some examples of the World War I Alpha Test:
1. The Percheron is a kind of
(a) goat, (b) horse, (c) cow, (d) sheep.
2. The most prominent industry of Gloucester is
(a) fishing, (b) packing, (c) brewing, (d) automobiles.
3. “There’s a reason” is an advertisement for
(a) drink, (b) revolver, (c) flour, (d) cleanser.
4. The Knight engine is used in the
(a) drink, (b) Stearns, (c) Lozier, (d) Pierce Arrow.
5. The Stanchion is used in
(a) fishing, (b) hunting, (c) farming, (d) motoring.
Such test items are similar to what are on modern-day IQ tests. See, for example, Castles (2013: 150) who writes:
One section of the WAIS-III, for example, consists of arithmetic problems that the respondent must solve in his or her head. Others require test-takers to define a series of vocabulary words (many of which would be familiar only to skilled-readers), to answer school-related factual questions (e.g., “Who was the first president of the United States?” or “Who wrote the Canterbury Tales?”), and to recognize and endorse common cultural norms and values (e.g., “What should you do it a sale clerk accidentally gives you too much change?” or “Why does our Constitution call for division of powers?”). True, respondents are also given a few opportunities to solve novel problems (e.g., copying a series of abstract designs with colored blocks). But even these supposedly culture-fair items require an understanding of social conventions, familiarity with objects specific to American culture, and/or experience working with geometric shapes or symbols. [Since this is questions found on the WAIS-III, then go back and read Cockroft et al, 2015 since they used the British version which, of course, is similar.]
If one is not exposed to the structure of the test along with the items and information on them, how, then, can we say that the test is ‘fair’ to other cultural groups (social classes included)? For, if all tests are culture-bound and different groups of people have different cultures, histories, etc, then they will score differently by virtue of what they know. This is why it is ridiculous to state so confidently that IQ tests—however imperfectly—test “intelligence.” They test certain skills and knowledge more likely to be found in certain groups/classes over others—specifically in the dominant group. So what dictates IQ scores is differential access to knowledge (i.e., cultural tools) and how to use such cultural tools (which then become psychological tools.)
Lastly, take an Amazonian people called The Pirah. They have a different counting system than we do in the West called the “one-two-many system, where quantities beyond two are not counted but are simply referred to as “many”” (Gordon, 2005: 496). A Pirah adult was shown an empty can. Then the investigator put six nuts into the can and took five out, one at a time. The investigator then asked the adult if there were any nuts remaining in the can—the man answered that he had no idea. Everett (2005: 622) notes that “Piraha is the only language known without number, numerals, or a concept of counting. It also lacks terms for quantification such as “all,” “each,” “every,” “most,” and “some.””
(hbdchick, quite stupidly, on Twitter wrote “remember when supermisdreavus suggested that the tsimane (who only count to s’thing like two and beyond that it’s “many”) maybe went down an evolutionary pathway in which they *lost* such numbers genes?” Riiiight. Surely the Tsimane “went down an evolutionary pathway in which they *lost* such numbers genes.” This is the idiocy of “HBDers” in action. Of course, I wouldn’t expect them to read the actual literature beyond knowing something basic (Tsimane numbers beyond “two” are known as “many”) and the positing a just-so story for why they don’t count above “two.”
Non-verbal tests
Take a non-verbal test, such as the Bender-Gestalt test. There are nine index cards which have different geometrical designs on them, and the testee needs to copy what he saw before the next card is shown. The testee is then scored on how accurate his recreation of the index card is. Seems culture-fair, no? It’s just shapes and other similar things, how would that be influenced by class and culture? One would, on a cursory basis, claim that such tests have no basis in knowledge structure and exposure and so would rightly be called “culture-free.” While the shapes that come on Ravens tests are novel, the rules governing them are not.
Hoffmann (1966) studied 80 children (20 Kickapoo Indians (KIs), 20 low SES blacks (LSBs), 20 low SES whites (LSWs), and 20 middle-class whites (MCWs)) on the Bender-Gestalt test. The Kickapoo were selected from 5 urban schools; 20 blacks from majority-black elementary schools in Oklahoma City; 20 whites in low SES areas of Oklahoma; and 20 whites from middle-schools in Oklahoma from majority-white schools. All of the children were aged 8-10 years of age and in the third grade, while all had IQs in the range of 90-110. They were matched on a whole slew of different variables. Hoffman (1966: 52) states “that variations in cultural and socio-economic background affect Bender Gestalt reproduction.”
Hoffman (1966: 86) writes that:
since the four groups were shown to exhibit no significant differences in motor, or perceptual discrimination ability it follows that differences among the four groups of boys in Bender Gestalt performance are assignable to interpretative factors. Furthermore, significant differences among the four groups in Bender performance illustrates that the Bender Gestalt test is indeed not a so called “culture-free” test.
Hoffman concluded that MCWs, KIs, LSBs, and LSWs did not differ in copying ability, nor did they differ significantly in discriminating in different phases in the Bender-Gestalt; there also was no bias in figures that had two of the different sexes on them. They did differ in their reproductions of Bender-Gestalt designs, and their differing performance can be, of course, interpreted differently by different people. If we start from the assumption that all IQ tests are culture-bound (Cole, 2004), then living in a different culture from the majority culture will have one score differently by virtue of having differing—culture-specific knowledge and experience. The four groups looked at the test in different ways, too. Thus, the main conclusion is that:
The Bender Gestalt test is not a “culture-free” test. Cultural and socio-economic background appear to significantly affect Bender Gestalt reproduction. (Hoffman, 1966: 88)
Drame and Ferguson (2017) and Dutton et al (2017) also show that there is bias in the Raven’s test in Mali and Sudan. This, of course, is due to the exposure to the types of problems on the items (Richardson, 2002: 291-293). Thus, their cultures do not allow exposure to the items on the test and they will, therefore, score lower in virtue of not being exposed to the items on the test. Richardson (1991) took 10 of the hardest Raven’s items and couched them in familiar terms with familiar, non-geometric, objects. Twenty eleven-year-olds performed way better with the new items than the original ones, even though they used the same exact logic in the problems that Richardson (1991) devised. This, obviously, shows that the Raven is not a “culture-free” measure of inductive and deductive logic.
The Raven is administered in a testing environment, which is a cultural device. They are then handed a paper with black and white figures ordered from left to right. Note that Abel-Kalek and Raven (2006: 171) write that Raven’s items “were transposed to read from right to left following the custom of Arabic writing.” So this is another way that the tests are biased and therefore not “culture-free.”) Richardson (2000: 164) writes that:
For example, one rule simply consists of the addition or subtraction of a figure as we move along a row or down a column; another might consist of substituting elements. My point is that these are emphatically culture-loaded, in the sense that they reflect further information-handling tools for storing and extracting information from the text, from tables of figures, from accounts or timetables, and so on, all of which are more prominent in some cultures and subcultures than others.
Richardson (1991: 83) quotes Keating and Maclean (1987: 243) who argue that tests like the Raven “tap highly formal and specific school skills related to text processing and decontextualized rule application, and are thus the most systematically acculturated tests” (their emphasis). Keating and Maclean (1987: 244) also state that the variation in scores between individuals is due to “the degree of acculturation to the mainstream school skills of Western society” (their emphasis). That’s the thing: all types of testing is biased towards a certain culture in virtue of the kinds of things they are exposed to—not being exposed to the items and structure of the test means that it is in effect biased against certain cultural/social groups.
Davis (2014) studied the Tsimane, a people from Bolivia, on the Raven. Average eleven-year-olds scored 78 percent or more of the questions correct whereas lower-performing individuals answered 47 percent correct. The eleven-year-old Tsimane, though, only answered 31 percent correct. There was another group of Tsimane who went to school and lived in villages—not living in the rainforest like the other group of Tsimane. They ended up scoring 72 percent correct, compared to the unschooled Tsimane who scored only 31 percent correct. “… the cognitive skills of the Tsimane have developed to master the challenges that their environment places on them, and the Raven’s test simply does not tap into those skills. It’s not a reflection of some kind of true universal intelligence; it just reflects how well they can answer those items” (Heine, 2017: 189). Thus, measures of “intelligence” are not an innate skill, but are learned through experience—what we learn from our environments.
Heine (2017: 190) discusses as-of-yet-to-be-published results on the Hadza who are known as “the most cognitively complex foragers on Earth.” So, “the most cognitively complex foragers on Earth” should be pretty “smart”, right? Well, the Hadza were given six-piece jigsaw puzzles to complete—the kinds of puzzles that American four-year-olds do for fun. They had never seen such puzzles before and so were stumped as to how to complete them. Even those who were able to complete them took several minutes to complete them. Is the conclusion then licensed that “Hadza are less smart than four-year-old American children?” No! As that is a specific cultural tool that the Hadza have never seen before and so, their performance mirrored their ignorance to the test.
Logic
The term “logical” comes from the Greek term logos, meaning “reason, idea, or word.” So, “logical reasoning” is based on reason and sound ideas, irrespective of bias and emotion. A simple syllogistic structure could be:
If X, then Y
X
∴ Y
We can substitute terms, too, for instance:
If it rains today, then I must bring an umbrella.
It’s raining today.
∴ I must bring an umbrella.
Richardson (2000: 161) notes how cross-cultural studies show that what is or is not logical thinking is not objective nor simple, but “comes in socially determined forms.” He notes how cross-cultural psychologist Sylvia Scribner showed some syllogisms to Kpelle farmers, which were couched in terms that were familiar to them. One syllogism given to them was:
All Kpelle men are rice farmers
Mr. Smith is not a rice farmer
Is he a Kpelle man? (Richardson, 2002: 162)
The individual then continuously replied that he did not know Mr. Smith, so how could he know whether or not he was a Kpelle man? Another example was:
All people who own a house pay a house tax
Boima does not pay a house tax
Does Boima own a house? (Richardson, 2000: 162)
The answer here was that Boima did not have any money to pay a house tax.
In regard to the first syllogism, Mr. Smith is not a rice farmer so he is not a Kpelle man. Regarding the second, Boima does not pay a house tax, so Boima does not own a house. The individual could give a syllogism that is something like:
All the deductions I can make are about individuals I know.
I do not know Mr. Smith.
Therefore I cannot make a deduction about Mr. Smith. (Richardson, 2000: 162)
They are using what are familiar terms to them, and so, they get the answer right for their culture based on the knowledge that they have. These examples, therefore, show that what can pass for “logical reasoning” is based on the time and place where it is said. The deductions the Kpelle made were perfectly valid, though they were not what the syllogism-designers had in mind. In fact, I would say that there are many—equally valid—ways of answering such syllogisms, and such answers will vary by culture and custom.
The bio-ecological framework, culture, and social class
The bio-ecological model of Ceci and Bronfenbrenner is a model of human development that relies on gene and environment interactions. The model is a Vygotskian one—in that learning is a social process where the support from parents, teachers, and all of society play an important role in the ontogeny of higher psychological functioning. (For a good primer on Vygotskian theory, see Vygotsky and the Social Formation of Mind, Wertsch, 1985.) Thus, it is a model of human development that, most hereditarians would say, that “they use too.” Though this is of course, contested by Ceci who compares his bio-ecological framework with other theories (Ceci, 1996: 220, table 10.1):
Cognition (thinking) is extremely context-sensitive. Along with many ecological influences, individual differences in cognition are understood best with the bio-ecological framework which consists of three components: (1) ‘g’ doesn’t exist, but multiple cognitive potentials do; (2) motivational forces and social/physical aspects of a task or setting, how elaborate a knowledge domain is not only important in the development of the human, but also, of course, during testing; and (3) knowledge and aptitude are inseparable “such that cognitive potentials continuously access one’s knowledge base in the cascading process of producing cognitions, which in turn alter the contents and structure of the knowledge base” (Ceci, 1996: 123).
Block (1995) notes that “Blacks and Whites are to some extent separate cultural groups.” Sternberg (2004) defines culture as “the set of attitudes, values, beliefs and behaviors shared by a group of people, communicated from one generation to the next via language or some other means of communication.” In regard to social class—blacks and whites differ in social class (a form of culture), Richardson (2002: 298) notes that “Social class is a compound of the cultural tools (knowledge and cognitive and psycholingustic structures) individuals are exposed to; and beliefs, values, academic orientations, self-efficacy beliefs, and so on.” The APA notes that “Social status isn’t just about the cars we drive, the money we make or the schools we attend — it’s also about how we feel, think and act …” And the APS notes that social class can be seen as a form of culture. Since culture is a set of attitudes, beliefs and behaviors shared by a group of people, social classes, therefore, are forms of culture as different classes have different attitudes, beliefs and behaviors.
Ceci (1996 119) notes that:
large-scale cultural differences are likely to affect cognition in important ways. One’s way of thinking about things is determined in the course of interactions with others of the same culture; that is, the meaning of a cultural context is always negotiated between people of that culture. This, in turn, modifies both culture and thought.
While Manstead (2018) argues that:
There is solid evidence that the material circumstances in which people develop and live their lives have a profound influence on the ways in which they construe themselves and their social environments. The resulting differences in the ways that working‐class and middle‐ and upper‐class people think and act serve to reinforce these influences of social class background, making it harder for working‐class individuals to benefit from the kinds of educational and employment opportunities that would increase social mobility and thereby improve their material circumstances.
In fact, the bio-ecological model of human development (and IQ) is a developmental systems-type model. The types of things that go into the model are just like Richardson’s (2002) “sociocognitive affective nexus.” Richardson (2002) posits that the sources of IQ variation are mostly non-cognitive, writing that such factors include (pg 288):
(a) the extent to which people of different social classes and cultures have acquired a specific form of intelligence (or forms of knowledge and reasoning); (b) related variation in ‘academic orientation’ and ‘self-efficacy beliefs’; and (c) related variation in test anxiety, self-confidence, and so on, which affect performance in testing situations irrespective of actual ability
Cole (2004) concludes that:
Our imagined study of cross-cultural test construction makes it clear that tests of ability are inevitably cultural devices. This conclusion must seem dreary and disappointing to people who have been working to construct valid, culture-free tests. But from the perspective of history and logic, it simply confirms the fact, stated so clearly by Franz Boas half a century ago, that “mind, independent of experience, is inconceivable.”
The role of context is huge—and most psychometricians ignore it, as Ceci (1996: 107) quotes Bronfenbrenner (1989: 207) who writes:
It is a noteworthy feature of all preceding (cognitive approaches) that they make no reference whatsoever to the environment in which the person actually lives and grows. The implicit assumption is that the attributes in question are constant across place; the person carries them with her wherever she goes. Stating the issue more theoretically, the assumption is that the nature of the attribute does not change, irrespective of the context in which one finds one’s self.
Such contextual differences can be found in the intrinsic and extrinsic motivations of the individual in question. Self-efficacy, what one learns and how they learn it, motivation instilled from parents, all form part of the context of the specific individual and how they develop which then influences IQ scores (middle-class knowledge and skills scores).
(For a primer on the bio-ecological model, see Armour-Thomas and Gopaul-Mcnicel, 1997; Papierno et al, 2005; Bronfenbrenner and Morris, 2007; and O’Toole, 2016.)
Conclusion
If blacks and whites are, to some extent, different cultural groups, then they will—by definition—have differing cultures. So “cultural differences are known to exist, and cultural differences can have an impact on psychological traits [also in the knowledge one acquires which then is one part of dictating test scores] (see Prinz, 2014: 67, Beyond Human Nature). If blacks and whites are “separate cultural groups” (Block, 1995) and if they have different experiences by virtue of being cultural groups, then they will score differently on any test of ability (including IQ; see Fagan and Holland, 2002, 2007) as all tests of ability are culture-bound (see Cole, 2004).
1 Blacks and whites are different cultural groups.
2 If (1), then they will have different experiences by virtue of being different cultural groups.
3 So blacks and whites, being different cultural groups, will score differently on tests of ability, since they are exposed to different knowledge structures due to their different cultures.
So, what accounts for the intercorrelations between tests of “cognitive ability”? They validate the new test with older, ‘more established’ tests so “based on this it is unlikely that a measure unrelated to g will emerge as a winner in current practice … [so] it is no wonder that the intelligence hierarchy for different racial/ethnic groups remains consistent across different measures. The tests are highly correlated among each other and are similar in item structure and format” (Suzuki and Aronson, 2005: 321).
Therefore, what accounts for differences in IQ is not intellectual ability, but cultural/social exposure to information—specifically the type of information used in the construction of IQ tests—along with the test constructors attempting to construct new tests that correlate with the old tests, and so, they get the foregone conclusion of their being racial differences, for example, in IQ which they trumpet as evidence for a “biological cause”—but it is anything but: such differences are built into the test (Simon, 1997). (Note that Fagan and Holland, 2002 also found evidence for test bias as well.)
Thus, we should take the logical conclusion: what explains racial IQ differences are not biological factors, but environmental ones—specifically in the exposure of knowledge—along with how new tests are created (see Suzuki and . All human cognizing takes place in specific cultural contexts—therefore “culture-free tests” (i.e., tests devoid of cultural knowledge and context) are an impossibility. IQ tests are experience-dependent so if one is not exposed to the relevant experiences to do well in a testing situation, then they will score lower than they would have if they were to have the requisite culturally-specific knowledge to perform well on the test.
The Burakumin and the Koreans: The Japanese Underclass and Their Achievement
2350 words
Japan has a caste system just like India. Their lowest caste is called “the Burakumin”, a hereditary caste created in the 17th century—the descendants of tanners and butchers. (Buraku means ‘hamlet people’ in Japanese which took on a new meaning in the Meiji era.) Even though they gained “full rights” in 1871, they were still discriminated against in housing and work (only getting menial jobs). A Burakumin Liberation League has formed, to end discrimination against Buraku in 1922, protesting to end job discrimination by the dominant Ippan Japanese. Official numbers of the number of Buraku in Japan are about 1.2 million, but unofficial numbers bring it up to 6000 communities and 3 million Buraku.
Note the similarities here with black Americans. Black Americans got their freedom from American slavery in 1865. The Burakumin got theirs in 1865. Both groups get discriminated against—the things that the Burakumin face, the blacks in America have faced. De Vos (1973: 374) describes some employment statistics for Buraku and non-Buraku:
For instance, Mahara reports the employment statistics for 166 non-Buraku children and 83 Buraku children who were graduated in March 1859 from a junior high school in Kyoto. Those who were hired by small-scale enterprises employing fewer than ten workers numbered 29.8 percent of the Buraku and 13.1 percent of the non-Buraku children; 15.1 percent of non-Buraku children obtained work in large-scale industries employing more than one thousand workers, whereas only 1.5 percent of Buraku children did so.
Certain Japanese communities—in southwestern Japan—have a belief and tradition in having foxes as pets. Those who have the potential to have such foxes descends down the family line—there are “black” foxes and “white” foxes. So in this area in southwestern Japan, people are classified as either “white” or “black”, and marriage between these artificial color lines is forbidden. They believe that if someone from the “white” family marries someone from the “black” family that every other member of the “white” family becomes “black.”
Discrimination against the Buraku in Japan is so bad, that a 330 page list of Buraku names and community placements were sold to employers. Burakumin are also more likely to join the Yakuza criminal gang—most likely due to such opportunities they miss out on in their native land. (Note similarities between Buraku joining Yakuza and blacks joining their own ethnic gangs.) It was even declared that an “Eta” (the lowest of the Burakumin) was 1/7th of an ordinary person. This is eerily familiar to how blacks were treated in America with the three-fifths compromise—signifying that the population of slaves would be counted as three-fifths in total when being apportioned to votes for the Presidential electors, taxes and other representatives.
Now let’s get to the good stuff: “intelligence.” There is a gap in scores between “blacks”, “whites”, and Buraku. De Vos (1973: 377) describes score differences between “blacks”, “whites” and Buraku:
[Nomura] used two different kinds of “intelligence” tests, the nature of which are unfortunately unclear from his report. On both tests and in all three schools the results were uniform: “White” children averaged significantly higher than children from “black” families, and Buraku children, although not markedly lower than the “blacks,” averaged lowest.
According to Tojo, the results of a Tanaka-Binet Group I.Q. Test administered to 351 fifth- and sixth-grade children, including 77 Buraku children, at a school in Takatsuki City near Osaka shows that the I.Q. scores of the Buraku children are markedly lower than those of the non-Buraku children. [Here is the table from Sternberg and Grigorenko, 2001]
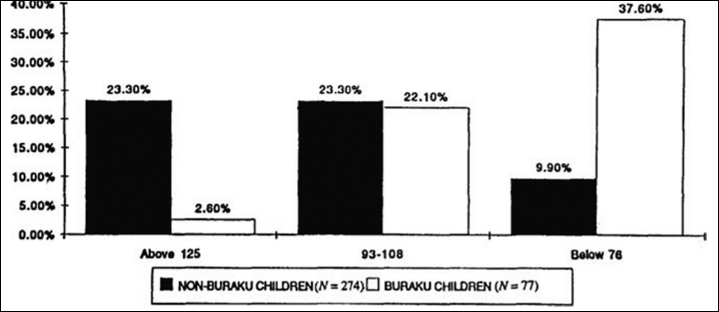
Also see the table from Hockenbury and Hockenbury’s textbook Psychology where they show IQ score differences between non-Buraku and Buraku people:
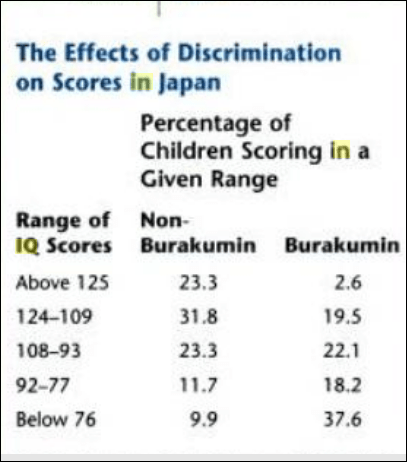
De Vos (1973: 376) also notes the similarities between Buraku and black and Mexican Americans:
Buraku school children are less successful compared with the majority group children. Their truancy rate is often high, as it is in California among black and Mexican-American minority groups. The situation in Japan also probably parallels the response to education by certain but not all minority groups in the United States.
How similar. There is another group in Japan that is an ethnic minority that is the same race as the Japanese—the Koreans. They came to Japan as forced labor during WWII—about 7.8 million Koreans were conscripted to the Japanese, men participating in the military while women were used as sex slaves. Most are born in Japan and speak no Korean, but they still face discrimination—just like the Buraku. There are no IQ test scores for Koreans in Japan, but there are standardized test scores. Koreans in America are more likely to have higher educational attainment than are native-born Americans (see the Pew data on Korean American educational attainment). But this is not the case in Japan. The following table is from Sternberg and Grigorenko (2001).
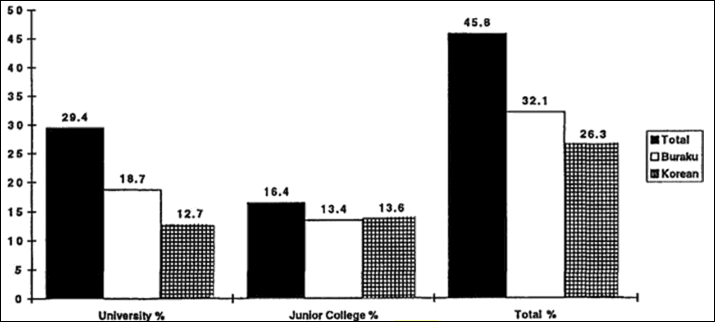
Just as Koreans do better than white Americans on standardized tests (and IQ tests), how weird is it for Koreans in Japan to score lower than ethnic Japanese and even the Burakumin? Sternberg and Grigorenko (2001) write:
Based on these cross-cultural comparison, we suggest that it is the manner in which caste and minority status combine rather than either minority position or low-caste status alone that lead to low cognitive or IQ test scores for low-status groups in complex, technological societies such as Japan and the United States. Often jobs and education require the adaptive intellectual skills of the dominant caste. In such societies, IQ tests discriminate against all minorities, but how the minority groups perform on the tests depends on whether they became minorities by immigration or choice (voluntary minorities) or were forced by the dominant group into minorities status (involuntary minorities). The evidence indicates that immigrant minority status and nonimmigrant status have different implications for IQ test performance.
The distinction between “voluntary” and “involuntary” minority is simple: voluntary minorities emigrate by choice, whereas involuntary minorities were forced against their will to be there. Black Americans, Native Hawaiians and Native Americans are involuntary minorities in America and, in the case of blacks, they face similar discrimination to the Buraku and there is a similar difference in test scores between the high and low castes (classes in America). (See the discussion in Ogbu and Simons (1998) on voluntary and involuntary minorities and also see Shimihara, (1984) for information on how the Burakumin are discriminated against.)
Ogbu and Simons (1988) explain the school performance of minorities using what Ogbu calls a “cultural-ecological theory” which considers societal and school factors along with community dynamics in minority communities. The first part of the theory is that minorities are discriminated against in terms of education, which Ogbu calls “the system.” The second part of the theory is how minorities respond to their treatment in the school system, which Ogbu calls “community forces.” See Figure 1 from Ogbu and Simons (1998: 156):

Ogbu and Simon (1998: 158) write about the Buraku and Koreans:
Consider that some minority groups, like the Buraku outcast in Japan, do poorly in school in their country of origin but do quite well in the United States, or that Koreans do well in school in China and in the United States but do poorly in Japan.
Ogbu (1981: 13) even notes that when Buraku are in America—since they do not look different from the Ippan—they are treated like regular Japanese-Americans who are not discriminated against in America as the Buraku are in Japan and, what do you know, they have similar outcomes to other Japanese:
The contrasting school experiences of the Buraku outcastes in Japan and in the United States are even more instructive. In Japan Buraku children continue massively to perform academically lower than the dominant Ippan children. But in the United States where the Buraku and the Ippan are treated alike by the American people, government and schools, the Buraku do just as well in school as the Ippan (DeVos 1973; Ito,1967; Ogbu, 1978a).
So, clearly, this gap between the Buraku and the Nippon disappears when they are not stratified in a dominant-subordinate relation. It’s because IQ testing and other tests of ability are culture-bound (Cole, 2004) and so, when Burakumin emigrate to America (as voluntary minorities), they are seen as and treated like any other Japanese since there are no physical differences between them and their educational attainment and IQs match the other non-Burakumin Japanese. The very items on these tests are biased towards the dominant (middle-)class—so when the Buraku and Koreans emigrate to America they then have the types of cultural and psychological tools (Richardson, 2002) to do well on the tests and so, their scores change from when they were in their other country.
Note the striking similarities between black Americans and Buraku and Korean-Japanese—all three groups are discriminated against in their countries, all three groups have lower levels of achievement than the majority population, two groups (the Buraku and black Americans, there is no IQ data for Koreans in Japan that I am aware of) show the same gap between them and the dominant group, the Buraku and black Americans got their freedom at around the same times but still face similar types of discrimination. However, when Buraku and Korean-Japanese people emigrate here to America, their IQ scores and educational attainment match that of other East Asian groups. To Americans, there is no difference between Buraku and non-Buraku Japanese people.
Koreans in Japan “endure a climate of hate“, according to The Japan Times. Koreans are heavily discriminated against in Japan. Korean-Japanese people, in any case, score worse than the Buraku. Though, as we all know, when Koreans emigrate to America they have higher test scores than whites do.
Note, though, IQ scores for “voluntary minorities” that came to the US in the 1920s. The Irish, Italians, and even Jews were screened as “low IQ” and were thusly barred entry into the country due to it. For example, Young (1922: 422) writes that:
Over 85 per cent. of the Italian group, more than 80 per cent. of the Polish group and 75 per cent. of the Greeks received their final letter grades from the beta or other performance examination.
While Young (1922) shows the results of an IQ test administered to Southern Europeans in certain areas (one of the studies was carried out in New York City):
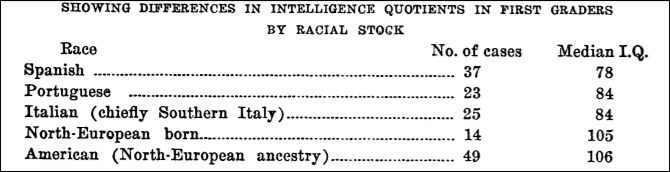


These types of score differentials are just like what these lower castes in Japan and America show today. Though, as Thomas Sowell noted in regard to the IQs of Jews, Polish, Italians, and Greeks:
Like fertility rates, IQ scores differ substantially among ethnic groups at a given time, and have changed substantially over time— reshuffling the relative standings of the groups. As of about World War I, Jews scored sufficiently low on mental tests to cause a leading “expert” of that era to claim that the test score results “disprove the popular belief that the Jew is highly intelligent.” At that time, IQ scores for many of the other more recently arrived groups—Italians, Greeks, Poles, Portuguese, and Slovaks—were virtually identical to those found today among blacks, Hispanics, and other disadvantaged groups. However, over the succeeding decades, as most of these immigrant groups became more acculturated and advanced socioeconomically, their IQ scores have risen by substantial amounts. Jewish IQs were already above the national average by the 1920s, and recent studies of Italian and Polish IQs show them to have reached or passed the national average in the post-World War II era. Polish IQs, which averaged eighty-five in the earlier studies—the same as that of blacks today—had risen to 109 by the 1970s. This twenty-four-point increase in two generations is greater than the current black-white difference (fifteen points). [See also here.]
Ron Unz notes that Sowell says about the Eastern and Southern European immigrants IQs: “Slovaks at 85.6, Greeks at 83, Poles at 85, Spaniards at 78, and Italians ranging between 78 and 85 in different studies.” And, of course, their IQs rose throughout the 20th century. Gould (1996: 227) showed that the average mental age for whites was 13.08, with anything between 8 and 12 being denoted a “moron.” Gould noted that the average Russian had a mental age of 11.34, while the Italian was at 11.01 and the Pole was at 10.74. This, of course, changed as these immigrants acclimated to American life.
For an interesting story for the creation of the term “moron”, see Dolmage’s (2018: 43) book Disabled Upon Arrival:
… Goddard’s invention of [the term moron] as a “signifier of tainted whiteness” was the “most important contribution to the concept of feeble-mindedness as a signifier of racial taint,” through the diagnosis of the menace of alien races, but also as a way to divide out the impure elements of the white race.
The Buraku are a cultural class—not a racial or ethnic group. Looking at America, the terms “black” and “white” are socialraces (Hardimon, 2017)—so could the same reasons for low Buraku educational attainment and IQ be the cause for black Americans’ low IQ and educational attainment? Time will tell, though there are no countries—to the best of my knowledge—that blacks have emigrated to and not been seen as an underclass or ‘inferior.’
The thesis by Ogbu is certainly interesting and has some explanatory power. The fact of the matter is that IQ and other tests of ability are bound by culture, and so, when the Buraku leave Japan and come to America, they are seen as regular Japanese (I’m not aware if Americans know about the Buraku/non-Buraku distinction) and they score just as well if not better than Americans and other non-Buraku Japanese. This points to discrimination and other environmental causes as the root of Buraku problems—noting that the Buraku became “full citizens” in 1871, 6 years after black slavery was ended in America. That Koreans in Japan also have similarly low educational attainment but high in America—higher than native-born Americans—is yet another point in favor of Ogbu’s thesis. The “system” and “community forces” seem to change when the two, previously low-scoring, high-crime group comes to America.
The increase in IQ of Southern and Eastern European immigrants, too, is another point in favor of Ogbu. Koreans and Buraku (indistinguishable from other native Japanese), when they leave Japan, are seen as any other Asians immigrants, and so, their outcomes are different.
In any case, the Buraku of Japan and Koreans who are Japanese citizens are an interesting look into how a group is treated can—and does—decrease test scores and social standing in Japan. Might the same hold true for blacks one day?
The “Fade-Out Effect”
2050 words
The “fade-out effect” occurs when interventions are given to children to increase their IQs, such as Head Start (HS) or other similar programs. In such instances when IQ gains are clear, hereditarians argue that the effect of the interventions “washes” away or “fades out.” Thus, when discussing such studies, hereditarians think they are standing in victory. That the effects from the intervention fade away is taken to be evidence for the hereditarian position and is taken to refute a developmental, interactionist position. However, that couldn’t be further from the truth.
Think about where the majority of HS individuals come from—poorer environments and which are more likely to have disadvantaged people in them. Since IQ tests—along with other tests of ability—are experience-dependent, then it logically follows that one who is not exposed to the test items or structure of the test, among other things, will be differentially prepared to take the test compared to, say, middle-class children who are exposed to such items daily.
When it comes to HS, for instance, whites who attend HS are “significantly more likely to complete high school, attend college, and possibly have higher earnings in their early twenties. African-Americans who participated in Head Start are less likely to have been booked or charged with a crime” (Garces, Thomas, and Currie, 2002). Deming (2009) shows many positive health outcomes in those who attend HS. This is beside the case, though (even if we accept the hereditarian hypothesis here, there are still many, many good reasons for programs such as HS).
Just as Protzko (2016) argues that IQ score gains “fade away” after adolescence, so, too, Chetty et al (2011) who write:
Students who were randomly assigned to higher quality classrooms in grades K–3—as measured by classmates’ end-of-class test scores—have higher earnings, college attendance rates, and other outcomes. Finally, the effects of class quality fade out on test scores in later grades, but gains in noncognitive measures persist.
So such gains “faded out”, therefore hereditarianism is a more favorable position, right? Wrong.
Think about test items, and testing as a whole. Then think about differing environments that social classes are in. Now, thinking about test items, think about how exposure to such items and similar questions would have an effect on the test-taking ability of the individual in question. Thus, since tests of ability are experience-dependent, then the logical position to hold is that if they are exposed to the knowledge and experience needed for successful test-taking then they will score higher. And this is what we see when such individuals are enrolled in the program, but when the program ends and the scores decrease, the hereditarian triumphs that it is another piece of the puzzle, another piece of evidence in favor of their position. Howe (1997: 53) explains this perfectly:
It is an almost universal characteristic of acquired competences that when their is a prolonged absence of opportunities to use, practise, and profit from them, they do indeed decline. It would therefore be highly surprising if acquired gains in intelligence did not fade or diminish. Indeed, had the research findings shown that IQs never fade or decline, that evidence would have provided some support for the view that measured intelligence possesses the inherent — rather than acquired — status that intelligence theorists and other writers within the psychometric position have believed it to have.
A similar claim is made by Sauce and Matzel (2018):
In simpler terms, the analysis of Protzko should not lead us to conclude that early intervention programs such as Head Start can have no long-term benefits. Rather, these results highlight the need to provide participants with continuing opportunities that would allow them to capitalize on what might otherwise be transient gains in cognitive abilities.
Now, if we think in the context of the HS and similar interventions, we can see why such stark differences in scores appear, and why some studies show a fade out effect. Such new knowledge and skills (what IQ tests are tests of; Richardson, 2002) are largely useless in those environments since they have little to no opportunity to hone their newly-acquired skills.
Take success in an action video game, weight-lifting, bodybuilding (muscle-gaining), or pole-vaulting. One who does well in any one of these three events will of course have countless of hours of training learning new techniques and skills. They continue this for a while. Then they abruptly stop. They are no longer honing (and practicing) their acquired skills so they begin to lose them. The “fade-out effect” has affected their performance and the reason is due to their environmental stimulation—the same holds for IQ test scores.
I’ll use the issue of muscle-building to illustrate the comparison. Imagine you’re 20 years old and just start going to the gym on a good program. The first few months you get what are termed “newbie gains”, as your body and central nervous system begins to adapt to the new stressor you’re placing on your body. Then after the initial beginning period, at about 2 to 3 months, these gains eventually stop and then you’ll have to be consistent with your training and diet or you won’t progress in weight lifted or body composition. But you are consistent with training and diet and you then have a satisfactory body composition and strength gains.
But then things change you stop going to the gym as often as you did before and you get lazy with your nutrition. Your body composition you worked so hard for along with your strength gains start to dissipate since you’re not placing your body under the stressor it was previously under. But there is something called “muscle memory” which occurs due to motor learning in the central nervous system.
The comparison here is clear: strength is IQ and lifting weights is doing tests/tasks to prepare for the tests (exposure to middle-class knowledge and skills). So when one leaves their “enriching environments” (in this case, the gym and a good nutritional environment), they then lose the gains they worked for. The parallel then becomes clear: leave the enriched environments and return to the baseline. This example I have just illustrated shows exactly how and why these gains “fade out” (though they don’t in all of these types of studies).
One objection to my comparison I can imagine an IQ-ist making is that training for strength (which is analogous to types of interventions in programs like HS), one can only get so strong as, for example, their frame allows, or that there is a limit to which one only get to a certain level of musculature. They may say that one can only get to a certain number of IQ and there, their “genetic potential” maxes out, as it would in the muscle-building and strength-gaining example. But the objection fails. Tests of ability (IQ tests) are cultural in nature. Since they are cultural in nature, then exposure to what’s on the test (middle-class knowledge and skills) will have one score better. That is, IQ tests are experience-dependent, as is body composition and strength, but such tests aren’t (1) construct valid and (2) such tests are biased due to the items selected to be on them. When looking at weights, we have an objective, valid measure. Sure, weight-lifting measures a whole slew of variables including, what it is intended to, strength. But it also measures a whole slew of other variables associated with weight training, dependent on numerous other variables.
Therefore, my example with weights illustrates that if one removes themselves from their enriching environments that allows X, then they will necessarily decline. But due to, in this example, muscle memory, they can quickly return to where they were. Such gains will “fade out” if, and only if, they discontinue their training and meal prep, among other things. The same is true for IQ in these intervention studies.
Howe (1997: 54-55) (this editorial here has the discussion, pulled directly from the book) discusses the study carried out by Zigler and Seitz. They measured the effects of a four year intervention program which emphasized math skills. They were inner-city children who were enrolled in the orgrwm at kindergarten. The program was successful, in that those who participated in the program were two years ahead of a control group, but a few heads after in a follow-up, they were only a year ahead. Howe (1997:54-55) explains why:
For instance, to score well at the achievement tests used with older children it is essential to have some knowledge of algebra and geometry, but Seitz found that while the majority of middle-class children were being taught these subjects, the disadvantaged pupils were not getting the necessary teaching. For that reason they could hardly be expected to do well. As Seitz perceived, the true picture was not one of fading ability but of diminishing use of it.
So in this case, the knowledge gained from the intervention was not lost. Do note, though, how middle-class knowledge continues to appear in these discussions. That’s because tests of ability are cultural in nature since culture-fair impossible (Cole, 2004). Cole imagines a West African Binet who constructs a test of Kpelle culture. Cole (2004) ends up concluding that:
tests of ability are inevitably cultural devices. This conclusion must seem dreary and disappointing to people who have been working to construct valid, culture-free tests. But from the perspective of history and logic, it simply confirms the fact, stated so clearly by Franz Boas half a century ago, that “mind, independent of experience, is inconceivable.”
So, in this case, the test would be testing Kpelle knowledge, and not middle-class cultural skills and knowledge, which proves that IQ tests are bound by culture and that culture-fair (“free”) tests are impossible. This, then, also shows why such gains in test scores decrease: they are not in the types of environments that are conducive to that type of culture-specific knowledge (see some examples of questions on IQ tests here).
The fact is the matter is this: that the individuals in such studies return to their “old” environments is why their IQ gains disappear. People just focus on the scores, say “They decreased”—hardly without thinking why. Why should test scores reflect the efficacy of the HS and similar programs and not the fact that outcomes for children in this program are substantially better than those who did not participate? For example:
HS compared to non-HS children faired better on cognitive and socio-emotive measures having fewer negative behaviors and (Zhai et al, 2011). Adults who were in the HS program are more likely to graduate high school, go to college and receive a seconday degree (Bauer and Schanzenbach, 2016). A pre-school program raised standardized test scores through grade 5. Those who attended HS were less likely to become incarcerated, become teen parents, and are more likely to finish high-school and enroll in college (Barr and Gibs, 2017).
The cause of the fading out of scores is simple: if you don’t use it you lose it, as can be seen with the examples given above. IQ scores can and do increase is evidenced by the Flynn effect, so that is not touched by the fade-out effect. But this “fading-out” (in most studies, see Howe for more information) of scores, in my opinion, is ancillary to the main point: those who attend HS and similar programs do have better outcomes in life than those who did not attend. The literature on the matter is vast. Therefore, the “fading-out” of test scores doesn’t matter, as outcomes for those who attended are better than outcomes for those who do not.
HS and similar programs show that IQ is, indeed, malleable and not “set” or “stable” as hereditarians claim. That IQ tests are experience-dependent implies that those who receive such interventions get a boost, but when they leave their abilities decrease, which is due to not learning any new ones along with returning to their previous, less-stimulating environments. The cause of the “fading-out” is therefore simple: During the intervention they are engrossed in an enriching environment, learning about, by proxy, middle-class knowledge and skills which helps with test performance. But after they’re done they return to their previous environments and so they do not put their skills to use and they therefore regress. Like with my muscle-building example: if you don’t use it, you lose it.
Test Validity, Test Bias, Test Construction, and Item Selection
3400 words
Validity for IQ tests is fleeting. IQ tests are said to be “validated” on the basis of performance with other IQ tests and that of job performance (see Richardson and Norgate, 2015). Further, IQ tests are claimed to not be biased against social class or racial group. Finally, through the process of “item selection”, test constructors make the types of distributions they want (normal) and get the results the want through the subjective procedure of removing items that don’t agree with their pre-conceived notions on who is or is not “intelligent.” Lastly, “intelligence” is descriptive measure, not an explanatory concept, and treating it like an explanatory measure can—and does—lead to circularity (of which is rife in the subject of IQ testing; see Richardson, 2017b and Taleb’s article IQ is largely a psuedoscientific swindle). This article will show that, on the basis of test construction, item analysis (selection and deselection of items) and the fact that there is no theory of what is being measured in so-called intelligence tests that they, in fact, do not test what they purport to.
Richardson (1991: 17) states that “To measure is to give … a more reliable sense of quantity than our senses alone can provide”, and that “sensed intelligence is not an objective quantity in the sense that the same hotness of a body will be felt by the same humans everywhere (given a few simple conditions); what, in experience, we choose to call ‘more’ intelligence, and what ‘less’ a social judgement that varies from people to people, employing different criteria or signals.” Richardson (1991: 17-18) goes on to say that:
Even if we arrive at a reliable instrument to parallel the experience of our senses, we can claim no more for it than that, without any underlying theory which relates differences in the measure to differences in some other, unobserved, phenomena responsible for those differences. Without such a theory we can never be sure that differences in the measure correspond with our sensed intelligence aren’t due to something else, perhaps something completely different. The phenomenon we at first imagine may not even exist. Instead, such verification most inventors and users of measures of intelligence … have simply constructed the source of differences in sensed intelligence as an underlying entity or force, rather in the way that children and naïve adults perceive hotness as a substance, or attribute the motion of objects to a fictitious impetus. What we have in cases like temperature, of course, are collateral criteria and measures that validate the theory, and thus the original measures. Without these, the assumed entity remains a fiction. This proved to be the case with impetus, and with many other naïve conceptions of nature, such as phlogiston (thought to account for differences in health and disease). How much greater such fictions are likely to be unobserved, dynamic and socially judged concepts like intelligence.
Richardson (1991: 32-35) then goes on to critique many of the old IQ tests, in that they had no way of being construct valid, and that the manuals did not even discuss the validity of the test—it was just assumed.
If we do not know what exactly is being measured when test constructors make and administer these tests, then how can we logically state that “IQ tests test intelligence”? Even Arthur Jensen admitted that psychometricians can create any type of distribution they please (1980: 71); he tacitly admits that tests are devised through the selection and deselection of items on IQ tests that correspond to the test constructors preconceived notions on what “intelligence” is. This, again, is even admitted by Jensen (1980: 147-148) who writes “The items must simply emerge arbitrarily from the heads of test constructors.”
We know, to build on Richardson’s temperature example, that we know exactly is what being measured when we look at the amount of mercury in a thermometer. That is, the concept of “temperature” and the instrument to measure it (the thermometer) were verified independently, without circular reliance on the thermometer itself (see Hasok Chang’s 2007 book Inventing Temperature). IQ tests, on the other hand, are, supposedly, “validated” through measures of job performance and correlations with other, previous tests assumed to be (construct) valid—but they were, of course, just assumed to be valid, it was never shown.
For another example (as I’ve shown with IQ many times) of a psychological construct that is not valid is ASD (autism spectrum disorder). Waterhouse, London, and Gilliberg (2016) write that “14 groups of findings reviewed in this paper that together argue that ASD lacks neurobiological and construct validity. No unitary ASD brain impairment or replicated unitary model of ASD brain impairment exists.” That a construct is valid—that is, it tests what it purports to, is of utmost importance to test measurement. Without it, we don’t know if we’re measuring something else completely different from what we hope—or purport—to.
There is another problem: the fact that, for one of the most-used IQ tests that there is no underlying theory of item selection, as seen in John Raven’s personal notes (see Carpenter, Just, and Shell, 1990). Items on the Raven were selected based on Raven’s intuition, and not any formal theory—the same can be said about, of course, modern-day IQ tests. Carpenter, Just, and Shell (1990) write that John Raven “used his intuition and clinical experience to rank order the difficulty of the six problem types . . . without regard to any underlying processing theory.”
These preconceived notions on what “intelligence” is, though, fail without (1) a theory of what intelligence is (which, as admitted by Ian Deary (2001), there is no theory of human intelligence like the way physics has theories); and (2) what ultimately is termed “construct validity”—that a test measures what it purports to. There are a few kinds of validity: and what IQ-ists claim the most is that IQ tests have predictive validity—that is, they can predict an individual’s outcome in life, and job performance (it is claimed). However, “intelligence” is “a descriptive measure, not an explanatory concept … [so] measures of intelligence level have little or no predictive value” (Howe, 1988).
Howe (1997: ix) also tells us that “Intelligence is … an outcome … not a cause. … Even the most confidently stated assertions about intelligence are often wrong, and the inferences that people have drawn from those assertions are unjustified.”
The correlation between IQ and school performance, according to Richardson (1991: 34) “may be a necessary aspect of the validity of tests, but is not a sufficient one. Such evidence, as already mentioned, requires a clear connection between a theory (a model of intelligence), and the values on the measure.” But, as Richardson (2017: 85) notes:
… it should come as no surprise that performance on them [IQ tests] is associated with school performance. As Robert L. Thorndike and Elizabeth P. Hagen explained in their leading textbook, Educational and Psychological Measurement, “From the very way in which the tests were assembled [such correlation] could hardly be otherwise.”
Gottfredson (2009) claims that the construct validity argument against IQ is “fallacious”, noting it as one of her “fallacies” on intelligence testing (one of her “fallacies” was the “interactionism fallacy”, which I have previously discussed). However, unfortunately for Gottfredson (2009), “the phenomena that testers aim to capture” are built into the test and, as noted here numerous times, preconceived by the constructors of the test. So, Gottfredson’s (2009) claim fails.
Such kinds of construction, too, come into the claim of a “normal distribution.” Just like with preconceptions of who is or is not “intelligent” on the basis of preconceived notions, the normal distribution, too, is an artifact of test construction, along the selection and deselection of items to conform with the test constructors’ presuppositions; the “bell curve” of IQ is created by the presuppositions that the test constructors have about people and society (Simon, 1997).
Charles Spearman, in the early 1900s, claims to have found a “general factor” that explains correlations between different tests. This positive manifold he termed “g” for “general intelligence.” Spearman stated “The (g) factor was taken, pending further information, to consist in something of the nature of an ‘energy’ or ‘power’…” (quoted in Richardson, 1991: 38). The refutation of “g” is a simple, logical, one: While a correlation between performances “may be a necessary requirement for a general factor … it is not a sufficient one.” This is because “it is quite possible for quite independent factors to produce a hierarchy of correlations without the existence of any underlying ‘general’ factor (Fancer, 1985a; Richardson and Bynner, 1984)” (Richardson, 1991: 38). The fact of the matter is, Spearman’s “g” has been refuted for decades (and was shown to be reified by Gould (1981), and further defenses of his concepts on “general intelligence”, like by Jensen (1998) have been refuted, most forcefully by Peter Schonemann. Though, “g” is something built into the test by way of test construction (Richardson, 2002).
Castles (2013: 93) notes that “Spearman did not simply discover g lurking in his data. Instead, he chose one peculiar interpretation of the relationships to demonstrate something in which he already believed—unitary, biologically based intelligence.”
So what explains differences in “g”? The same test construction noted above along with differences in social class, due to stress, self-confidence, test preparedness and other factors correlated with social class, termed the “sociocognitive-affective nexus” (Richardson, 2002).
Constance Hilliard, in her book Straightening the Bell Curve (Hilliard, 2012), notes that there were differences in IQ between rural and urban white South Africans. She notes that differences between those who spoke Afrikaans and those who spoke another language were completely removed through test construction (Hilliard, 2012: 116). Hilliard (2012) notes that if the tests that the constructors formulate don’t agree with their preconceived notions, they are then thrown out:
If the individuals who were supposed to come out on top didn’t score highly or, conversely, if the individuals who were assumed would be at the bottom of the scores didn’t end up there, then the test designers scrapped the test.
Sex differences in “intelligence” (IQ) have been the subject of some debate in the early-to-mid-1900s. Test constructors debated amongst themselves what to do about such differences between the sexes. Hilliard (2012) quotes Harrington (1984; in Perspectives on Bias in Mental Testing) who writes about normalizing test scores between men and women:
It was decided [by IQ test writers] a priori that the distribution of intelligence-test scores would be normal with a mean (X=100) and a standard deviation (SD=15), also that both sexes would have the same mean and distribution. To ensure the absence of sex differences, it was arranged to discard items on which the sexes differed. Then, if not enough items remained, when discarded items were reintroduced, they were balanced, i.e., for every item favoring males, another one favoring females was also introduced.
While Richardson (1998: 114) notes that test constructors had two choices when looking at sex differences in the items they administered to the sexes:
One who would construct a test for intellectual capacity has two possible methods of handling the problem of sex differences.
1 He may assume that all the sex differences yielded by his test items are about equally indicative of sex differences in native ability.
2 He may proceed on the hypothesis that large sex differences on items of the Binet type are likely to be factitious in the sense that they reflect sex differences in experience or training. To the extent that this assumption is valid, he will be justified in eliminating from his battery test items which yield large sex differences.
The authors of the New Revision have chosen the second of these alternatives and sought to avoid using test items showing large differences in percents passing. (McNemar 1942:56)
Change “sex differences” to “race” or “social class” differences and we can, too, change the distribution of the curve, along with notions of who is or is not “intelligent.” Previously low scorers can, by way of test construction, become high scorers, vice-versa for high scorers being made into low scorers. There is no logical—or empirical—justification for the inclusion of specific items on whatever IQ test is in question. That is, to put it another way, the inclusion of items on a test is subjective, which comes down to the test designers’ preconceived notions, and not an objective measure of what types of items should be on the test—as Raven stated, there is no type of underlying theory for the inclusion of items in the test, it is based on “intuition” (which is the same thing that modern-day test constructors do). These two quotes from IQ-ists in the early 20th century are paramount in the attack on the validity of IQ tests—and the causes for differences in scores between groups.
He and van de Vijver (2012: 7) write that “An item is biased when it has a different psychological meaning across cultures. More precisely, an item of a scale (e.g., measuring anxiety) is said to be biased if persons with the same trait, but coming from different cultures, are not equally likely to endorse the item (Van de Vijver & Leung, 1997).” Indeed, Reynolds and Suzuki (2012: 83) write that “Item bias due to“:
… “poor item translation, ambiguities in the original item, low familiarity/appropriateness of the item content in certain cultures, or influence of culture specifics such as nuisance factors or connotations associated with the item wording” (p. 127) (van de Vijver and Tanzer, 2004)
Drame and Ferguson (2017) note that their “Results indicate that use of the Ravens may substantially underestimate the intelligence of children in Mali” while the cause may be due to the fact that:
European and North American children may spend more time with play tasks such as jigsaw puzzles or connect the dots that have similarities with the Ravens and, thus, train on similar tasks more than do African children. If African children spend less time on similar tasks, they would have fewer opportunities to train for the Ravens (however unintentionally) reflecting in poorer scores. In this sense, verbal ability need not be the only pitfall in selecting culturally sensitive IQ testing approaches. Thus, differences in Ravens scores may be a cultural artifact rather than an indication of true intelligence differences. [Similar arguments can be found in Richardson, 2002: 291-293]
The same was also found by Dutton et al (2017) who write that “It is argued that the undeveloped nature of South Sudan means that a test based around shapes and analytic thinking is unsuitable. It is likely to heavily under-estimate their average intelligence.” So if the Raven has these problems cross-culturally (country), then it SHOULD have such biases within, say, America.
It is also true that the types of items on IQ tests are not as complex as everyday life (see Richardson and Norgate, 2014). Types of questions on IQ tests are, in effect, ones of middle-class knowledge and skills and, knowing how IQ tests are structured will make this claim clear (along with knowing the types of items that eventually make it onto the particular IQ test itself). Richardson (2002) has a few questions on modern-day IQ tests whereas Castles (2013), too, has a few questions from the Stanford-Binet. This, of course, is due to the social class of the test constructors. Some examples of some questions can be seen here:
‘What is the boiling point of water?’ ‘Who wrote Hamlet?’ ‘In what continent is Egypt?’ (Richardson, 2002: 289)
and
‘When anyone has offended you and asks you to excuse him—what ought you do?’ ‘What is the difference between esteem and affection?’ [this is from the Binet Scales, but “It is interesting to note that similar items are still found on most modern intelligence tests” (Castles, 2013).]]
Castles (2013: 150) further notes made-up examples of what is on the WAIS (since she cannot legally give questions away since she is a licensed psychologist), and she writes:
One section of the WAIS-III, for example, consists of arithmetic problems that the respondent must solve in his or her head. Others require test-takers to define a series of vocabulary words (many of which would be familiar only to skilled-readers), to answer school-related factual questions (e.g., “Who was the first president of the United States?” or “Who wrote the Canterbury Tales?”), and to recognize and endorse common cultural norms and values (e.g., “What should you do it a sale clerk accidentally gives you too much change?” or “Why does our Constitution call for division of powers?”). True, respondents are also given a few opportunities to solve novel problems (e.g., copying a series of abstract designs with colored blocks). But even these supposedly culture-fair items require an understanding of social conventions, familiarity with objects specific to American culture, and/or experience working with geometric shapes or symbols.
All of these factors coalesce into forming the claim—and the argument—that IQ tests are one of middle-class knowledge and skills. The thing is, contrary to the claims of IQ-ists, there is no such thing as a culture-free IQ test. Richardson (2002: 293) notes that “Since all human cognition takes place through the medium of cultural/psychological tools, the very idea of a culture-free test is, as Cole (1999) notes, ‘a contradiction in terms . . . by its very nature, IQ testing is culture bound’ (p. 646). Individuals are simply more or less prepared for dealing with the cognitive and linguistic structures built in to the particular items.”
Cole (1981) notes that “that the notion of a culture free IQ test is an absurdity” because “all higher psychological processes are shaped by our experiences and these experiences are culturally organized” (this is a point that Richardson has driven home for decades) while also—rightly—stating that “IQ tests sample school activities, and therefore, indirectly, valued social activities, in our culture.”
One of the last stands for the IQ-ist is to claim that IQ tests are useful for identifying at-risk individuals for learning disabilities (as Binet originally created the first IQ tests for). However, it is noted that IQ tests are not necessary—nor sufficient—for the identification of those with learning disabilities. Siegal (1989) states that “On logical and empirical grounds, IQ test scores are not necessary for the definition of learning disabilities.”
When Goddard brought the first IQ tests to America and translated them into English from French is when the IQ testing conglomerate really took off (see Zenderland, 1998 for a review). These tests were used to justify current social ranks. As Richardson (1991: 44) notes, “The measurement of intelligence in the twentieth century arose partly out of attempts to ‘prove’ or justify a particular world view, and partly for purposes of screening and social selection. It is hardly surprising that its subsequent fate has been one of uncertainty and controversy, nor that it has raised so many social and political issues (see, for example, Joynson 1989 for discussion of such issues).” So, what actual attempts at validation did the constructors of such tests need in the 20th century when they knew full-well what they wanted to show and, unsurprisingly, they observed it (since it was already going to happen since they construct the test to be that way)?
The conceptual arguments just given here point to a few things:
(1) IQ tests are not construct valid because there is no theory of intelligence, nor is there an underlying theory which relates differences in IQ (the unseen function) to, for example, a physiological variable. (See Uttal, 2012; 2014 for arguments against fMRI studies that purport to show differences in physiological variables cognition.)
(2) The fact that items on the tests are biased against certain classes/cultures; this obviously matters since, as noted above, there is no theory for the inclusion of items, it comes down to the subjective choice of the test designers, as noted by Jensen.
(3) ‘g’ is a reified mathematical abstraction; Spearman “discovered” nothing, he just chose the interpretation that, of course, went with his preconceived notion.
(4) The fact that sex differences in IQ scores were seen as a problem and, through item analysis, made to go away. This tells us that we can do the same for class/race differences in intelligence. Score differences are a function of test construction.
(5) The fact that the Raven has been shown to be biased in two African countries lends credence to the claims here.
So this then brings us to the ultimate claim of this article: IQ tests don’t test intelligence; they test middle-class knowledge and skills. Therefore, the scores on IQ tests are not that of intelligence, but of an index of one’s cultural knowledge of the middle class and its knowledge structure. This, IQ scores are, in actuality, “middle-class knowledge and skills” scores. So, contra Jensen (1980), there is bias in mental testing due to the items chosen for inclusion on the test (we have admission that score variances and distributions can change from IQ-ists themselves)
The Argument in The Bell Curve
600 words
On Twitter, getting into discussions with Charles Murray acolytes, someone asked me to write a short piece describing the argument in The Bell Curve (TBC) by Herrnstein and Murray (H&M). This is because I was linking my short Twitter thread on the matter, which can be seen here:
In TBC, H&M argue that America is becoming increasingly stratified by social class, and the main reason is due to the “cognitive elite.” The assertion is that social class in America used to be determined by one’s social origin is now being determined by one’s cognitive ability as tested by IQ tests. H&M make 6 assertions in the beginning of the book:
(i) That there exists a general cognitive factor which explains differences in test scores between individuals;
(ii) That all standardized tests measure this general cognitive factor but IQ tests measure it best;
(iii) IQ scores match what most laymen mean by “intelligent”, “smart”, etc.;
(iv) Scores on IQ tests are stable, but not perfectly so, throughout one’s life;
(v) Administered properly, IQ tests are not biased against classes, races, or ethnic groups; and
(vi) Cognitive ability as measured by IQ tests is substantially heritable at 40-80%/
In the second part, H&M argue that high cognitive ability predicts desireable outcomes whereas low cognitve ability predicts undesireable outcomes. Using the NLSY, H&M show that IQ scores predict one’s life outcomes better than parental SES. All NLSY participants took the ASVAB, while others took IQ tests which were then correlated with the ASVAB and the correlation came out to .81.
They analyzed whether or not one has ever been incarcerated, unemployed for more than one month in the year; whether or not they dropped out of high-school; whether or not they were chronic welfare recipients; among other social variables. When they controlled for IQ in these analyses, most of the differences between ethnic groups, for example, disappeared.
Now, in the most controversial part of the book—the third part—they discuss ethnic differences in IQ scores, stating that Asians have higher IQs than whites who have higher IQs than ‘Hispanics’ who have higher IQs than blacks. H&M argue that the white-black IQ gap is not due to bias since they do not underpredict blacks’ school or job performance. H&M famously wrote about the nature of lower black IQ in comparison to whites:
If the reader is now convinced that either the genetic or environmental explanation has won out to the exclusion of the other, we have not done a sufficiently good job of presenting one side or the other. It seems highly likely to us that both genes and environment have something to do with racial differences. What might the mix be? We are resolutely agnostic on that issue; as far as we can determine, the evidence does not yet justify an estimate.
Finally, in the fourth and last section, H&M argue that efforts to raise cognitive ability through the alteration of the social and physical environment have failed, though we may one day find some things that do raise ability. They also argue that the educational experience in America neglects the small, intelligent minority and that we should begin to not neglect them as they will “greatly affect how well America does in the twenty-first century” (H&M, 1996: 387). They also argue forcefully against affirmative action, in the end arguing that equality of opportunity—over equality of outcome—should be the role of colleges and workplaces. They finally predict that this “cognitive elite” will continuously isolate themselves from society, widening the cognitive gap between them.
The Malleability of IQ
1700 words
1843 Magazine published an article back in July titled The Curse of Genius, stating that “Within a few points either way, IQ is fixed throughout your life …” How true is this claim? How much is “a few points”? Would it account for any substantial increase or decrease? A few studies do look at IQ scores in one sample longitudinally. So, if this is the case, then IQ is not “like height”, as most hereditarians claim—it being “like height” since height is “stable” at adulthood (like IQ) and only certain events can decrease height (like IQ). But these claims fail.
IQ is, supposedly, a stable trait—that is, like height, at a certain age, it does not change. (Other than sufficient life events, such as having a bad back injury that causes one to slouch over, causing a decrease in height, or getting a traumatic brain injury—though that does not always decrease IQ scores). IQ tests supposedly measure a stable biological trait—“g” or general intelligence (which is built into the test, see Richardson, 2002 and see Schonemann’s papers for refutations on Jensen’s and Spearman’s “g“).
IQ levels are expected to stick to people like their blood group or their height. But imagine a measure of a real, stable bodily function of an individual that is different at different times. You’d probably think what a strange kind of measure. IQ is just such a measure. (Richardson, 2017: 102)
Neuroscientist Allyson Mackey’s team, for example, found “that after just eight weeks of playing these games the kids showed a pretty big IQ change – an improvement of about 30% or about 10 points in IQ.” Looking at a sample of 7-9 year olds, Mackey et al (2011) recruited children from low SES backgrounds to participate in cognitive training programs for an hour a day, 2 days a week. They predicted that children from a lower SES would benefit more from such cognitive/environmental enrichment (indeed, think of the differences between lower and middle SES people).
Mackey et al (2011) tested the children on their processing speed (PS), working memory (WM), and fluid reasoning (FR). Assessing FR, they used a matrix reasoning task with two versions (for the retest after the 8 week training). For PS, they used a cross-out test where “one must rapidly identify and put a line through each instance of a specific symbol in a row of similar symbols” (Mackey et al, 2011: 584). While the coding “is a timed test in which one must rapidly translate digits into symbols by identifying the corresponding symbol for a digit provided in a legend” (ibid.) which is a part of the WISC IV. Working memory was assessed through digit and spatial span tests from the Wechsler Memory Scale.
The kinds of games they used were computerized and non-computerized (like using a Nintendo DS). Mackey et al (2011: 585) write:
Both programs incorporated a mix of commercially available computerized and non-computerized games, as well as a mix of games that were played individually or in small groups. Games selected for reasoning training demanded the joint consideration of several task rules, relations, or steps required to solve a problem. Games selected for speed training involved rapid visual processing and rapid motor responding based on simple task rules.
So at the end of the 8-week program, cognitive abilities increased in both groups. For the children in the reasoning training, they solved an average of 4.5 more matrices than their previous try. Mackey et al (585-586) write:
Before training, children in the reasoning group had an average score of 96.3 points on the TONI, which is normed with a mean of 100 and a standard deviation of 15. After training, they had an average score of 106.2 points. This gain of 9.9 points brought the reasoning ability of the group from below average for their age. [But such gains were not significant on the test of nonverbal intelligence, showing an increase of 3.5 points.]
One of the biggest surprises was that 4 out of the 20 children in the reasoning training showed an increase of over 20 points. This, of course, refutes the claim that such “ability” is “fixed”, as hereditarians have claimed. Mackey et al (2011: 587) writes that “the very existence and widespread use of IQ tests rests on the assumption that tests of FR measure an individual’s innate capacity to learn.” This, quite obviously, is a false claim. (This claim comes from Cattell, no less.) This buttresses the claim that IQ tests are, of course, experience dependent.
This study shows that IQ is not malleable and that exposure to certain cultural tools leads to increases in test scores, as hypothesized (Richardson, 2002, 2017).
Salthouse (2013) writes that:
results from different types of approaches are converging on a conclusion that practice or retest contributions to change in several cognitive abilities appear to be nearly the same magnitude in healthy adults between about 20 and 80 years of age. These findings imply that age comparisons of longitudinal change are not confounded with differences in the influences of retest and maturational components of change, and that measures of longitudinal change may be underestimates of the maturational component of change at all ages.
Moreno et al (2011) show that after 20 days of computerized training, children in the music group showed enhanced scores on a measure of verbal ability—90 percent of the sample showed the same improvement. They further write that “the fact that only one of the groups showed a positive correlation between brain plasticity (P2) and verbal IQ changes suggests a link between the specific training and the verbal IQ outcome, rather than improvement due to repeated testing.”
Schellenberg (2004) describes how there was an advertisement looking for 6 year olds to enroll them in art lessons. There were 112 children enrolled into four groups: two groups received music lessons for a year, on either a standard keyboard or they had Kodaly voice training while the other two groups received either drama training or no training at all. Schellenberg (2004: 3) writes that “Children in the control groups had average
increases in IQ of 4.3 points (SD = 7.3), whereas the music groups had increases of 7.0 points (SD = 8.6).” So, compared to either drama training or no training at all, the children in the music training gained 2.7 IQ points more.
(Figure 1 from Schellenberg, 2004)
Ramsden et al (2011: 3-4) write:
The wide range of abilities in our sample was confirmed as follows: FSIQ ranged from 77 to 135 at time 1 and from 87 to 143 at time 2, with averages of 112 and 113 at times 1 and 2, respectively, and a tight correlation across testing points (r 5 0.79; P , 0.001). Our interest was in the considerable variation observed between testing points at the individual level, which ranged from 220 to 123 for VIQ, 218 to 117 for PIQ and 218 to 121 for FSIQ. Even if the extreme values of the published 90% confidence intervals are used on both occasions, 39% of the sample showed a clear change in VIQ, 21% in PIQ and 33% in FSIQ. In terms of the overall distribution, 21% of our sample showed a shift of at least one population standard deviation (15) in the VIQ measure, and 18% in the PIQ measure. [Also see The Guardian article on this paper.[
Richardson (2017: 102) writes “Carol Sigelman and Elizabeth Rider reported the IQs of one group of children tested at regular intervals between the ages of two years and seventeen years. The average difference between a child’s highest and lowest scores was 28.5 points, with almost one-third showing changes of more than 30 points (mean IQ is 100). This is sufficient to move an individual from the bottom to the top 10 percent or vice versa.” [See also the page in Sigelman and Rider, 2011.]
Mortensen et al (2003) show that IQ remains stable in mid- to young adulthood in low birthweight samples. Schwartz et al (1975: 693) write that “Individual variations in patterns of IQ changes (including no changes over time) appeared to be related to overall level of adjustment and integration and, as such, represent a sensitive barometer of coping responses. Thus, it is difficult to accept the notion of IQ as a stable, constant characteristic of the individual that, once measured, determines cognitive functioning for any age level for any test.”
There is even instability in IQ seen in high SES Guatemalans born between 1941-1953 (Mansukoski et al, 2019). Mansukoski et al’s (2019) analysis “highlight[s] the complicated nature of measuring and interpreting IQ at different ages, and the many factors that can introduce variation in the results. Large variation in the pre-adult test scores seems to be more of a norm than a one-off event.” Possible reasons for the change could be due to “adverse life events, larger than expected deviations of individual developmental level at the time of the testing and differences between the testing instruments” (Mansukoski et al, 2019). They also found that “IQ scores did not significantly correlate with age, implying there is no straightforward developmental cause behind the findings“, how weird…
Summarizing such studies that show an increase in IQ scores in children and teenagers, Richardson (2017: 103) writes:
Such results suggest that we have no right to pin such individual differences on biology without the obvious, but impossible, experiment. That would entail swapping the circumstances of upper-and lower-class newborns—parents’ inherited wealth, personalities, stresses of poverty, social self-perception, and so on—and following them up, not just over years or decades, but also over generations (remembering the effects of maternal stress on children, mentioned above). And it would require unrigged tests based on proper cognitive theory.
In sum, the claim that IQ is stable at a certain age like another physical trait is clearly false. Numerous interventions and reasons can increase or decrease one’s IQ score. The results discussed in this article show that familiarity to certain types of cultural tools increases one’s score (like in the low SES group tested in Mackey et al, 2011). Although the n is low (which I know is one of the first things I will hear), I’m not worried about that. What I am worried about is the individual change in IQ at certain ages, and they show that. So the results here show support for Richardson’s (2002) thesis that “IQ scores might be more an index of individuals’ distance from the cultural tools making up the test than performance on a singular strength variable” (Richardson, 2012).
IQ is not stable; IQ is malleable, whether through exposure to certain cultural/class tools or through certain aspects that one is exposed to that are more likely to be included in certain classes over others. Indeed, this lends credence to Castles’ (2013) claim that “Intelligence is in fact a cultural construct, specific to a certain time and place.“
