
Recent Comments
Answering Common “Criticisms” of the Theory of African American Offending
4150 words
Introduction
Back in September I published an article arguing that since the theory of African American offending (TAAO) makes successful novel predictions and hereditarian explanations don’t, that we should accept the TAAO over hereditarian explanations. I then published a follow-up arguing that crime is bad and racism causes crime so racism is bad (and I also argued that stereotypes lead to self-fulfilling prophecies which then cause the black-white crime gap). The TAAO combines general strain theory, social control theory, social disorganization theory, learning theory, and low self control theory in order to better explain and predict crime in black Americans (Unnever, 2014).
For if a theory makes successful novel predictions, therefore that raises the probability that the theory is true. Take T1 and T2. T1 makes successful novel predictions. T2 doesn’t. So if T1 and T2 both try to explain the same things, then it’s only logical to accept T1 over T2. That’s the basis of the argument against hereditarian explanations of crime—the main ones all fail. Although some attempt at a theory has been made integrating hereditarian explanations (Ellis’ 2017 evolutionary neuroandrogenic theory), it doesn’t make any novel predictions. I’ve recently argued that that’s a death knell for hereditarian theories—there are no novel predictions of any kind for hereditarianism.
But since I published my comparison of the successes of the TAAO over hereditarian explanations, I’ve come across a few “responses” and they all follow the same trend: “What about Africa, Britain, and other places where blacks commit more crime? Why doesn’t racism cause other groups to commit more crime?” or “So blacks don’t have agency?” or “Despite what you argued against hereditarian explanations what about as-of-yet-to-be-discovered genes or hormonal influences that lead to higher crime in blacks compared to whites?” or “What about IQ and it’s relationship to crime?” or “What control groups are there for TAAO studies?” or “The black-white crime gap was lower during Jim Crow, how is this possible if the TAAO is true?” or “Unnever and Gabbidon are just making excuses for blacks with their TAAO” or “The so-called ‘novel predictions’ you reference aren’t novel at all.” I will answer these in turn and then provide a few more novel predictions of the TAAO.
“What about Africa, Britain, and other places where blacks commit more crime? Why doesn’t racism cause other groups to commit more crime?“
For some reason, TAAO detractors think these are some kind of knock-down questions for the TAAO and think that they disprove it. These are easily answered and they don’t threaten the theory at all.
For one, the theory of AFRICAN AMERICAN offending is irrelevant places that… Aren’t America. It’s a specific theory to explain why blacks commit crime at a higher rate IN AMERICA, therefore other countries are irrelevant. There would need to be a specific theory of crime for each of those places and contexts. So this question doesn’t hurt the theory. So going off of the first question, the answer to the second question also addresses it—it’s a theory that’s specifically formulated to explain and predict crime in a certain population in a certain place.
For two, why would a theory that’s specifically formulated to explain crime using the unique experiences of black Americans matter for other American groups? Blacks went through 400 years of slavery and then after that went through segregation and Jim Crow, so why would it mean anything that other groups face discrimination but then don’t have higher rates of crime compared to the average? Since the theory has specific focus on understanding the unique experiences and dynamics of crime in the black American population, it’s obvious that asking about other groups is just irrelevant. Other racial and ethnic groups aren’t the primary focus—since it aims to address historical and contemporary factors that lead to higher crime in the black American population. It’s in the name of the theory—so why would other racial groups matter? Unnever and Gabbidon (2011: 37) even explicitly addressed this point:
Our work builds upon the fundamental assumption made by Afrocentists that an understanding of black offending can only be attained if their behavior is situated within the lived experiences of being African American in a conflicted, racially stratified society. We assert that any criminological theory that aims to explain black offending must place the black experience and their unique worldview at the core of its foundation. Our theory places the history and lived experiences of African American people at its center. We also fully embrace the Afrocentric assumption that African American offending is related to racial subordination. Thus, our work does not attempt to create a “general” theory of crime that applies to every American; instead, our theory explains how the unique experiences and worldview of blacks in America are related to their offending. In short, our theory draws on the strengths of both Afrocentricity and the Eurocentric canon.
“So blacks don’t have agency?”
The theory doesn’t say that blacks lack agency (the capacity to make decisions and choices) at all. What the theory does say is that systemic factors like racism, socioeconomic disparities, and historical and contemporary marginalization can influence one’s choices and opportunities. So while individuals have agency, their choices are shaped by the social context they find themselves in. So if one has a choice to do X or ~X but they physical CAN’T do X, then they do not have a choice—they have an illusion of choice. The TAAO acknowledges that choices are constrained by poverty, racism, and social inequity. So while blacks—as all humans do—have agency, some “choices” are constrained, giving the illusion of choice. Thus, constraints should also be considered while analyzing why blacks offend more. This, too, is not a knock-down question.
“Despite what you argued against hereditarian explanations what about as-of-yet-to-be-discovered genes or hormonal influences that lead to higher crime in blacks compared to whites?”
Over the years I’d say I’ve done a good job of arguing against hereditarian theories of crime. (Like testosterone increasing aggression and blacks having higher levels of testosterone, the AR gene, and MAOA.) They’re just not tenable. The genetic explanation makes no sense. (Talk about disregarding agency…) But one response is that we could find some as-of-yet-to-be-discovered genes, gene networks, or neurohormonal influences which explain the higher crime rates in black Americans. This is just like the “five years away” claim that hereditarians love to use. We just need to wait X amount of years for the magic evidence, yet five years never comes since five years away is always five years away.
“What about IQ and it’s relationship to crime?”
Of course the IQ-ists love this question. The assumption is that lower IQ people are more likely to commit crime. So low is means more crime and high IQ means less crime. Ignoring the fact that IQ is not a cause of anything but an outcome of one’s life experiences, we know that the correlation between IQ and crime is -0.01 within family (Frisell, Pawitan, and Langstrom, 2012). So that, too, is an irrelevant question. The relationship just isn’t there.
“What control groups are there for TAAO studies?”
Other than the first question about why don’t other groups who experience racism commit more crime and what about blacks in other countries, this one takes the cake. The TAAO doesn’t need control groups in TAAO tests since it focuses specifically on understanding the unique factors that contribute to crime in America. So instead of comparing different racial or ethnic groups, the TAAO seeks to identify and analyze specific historical, social, and systemic factors which shape the experiences and behaviors of black Americans within the context of American society.
“The black-white crime gap was lower during Jim Crow, why? How is this possible if the TAAO is true?”
Between 1950 and 1963, non-whites made up 11 percent of the US population, 90 percent of which were black. In 1950 for whites the murder rate was 2 to 3 deaths per 100,000 while for non-whites the rate was 28 deaths per 100,000 (28 times the US average) which then fell to 21 per 100,000 in 1961 which was still about 8 times that of the white murder rate while the rate raised again between 1962 and 1964 (Langberg, 1967). Langan (1992) showed a steady increase in the incarcerated black population from 1926 (21 percent) to 1986 (44 percent). But demographic factors account for this, like increases in the sentencing of blacks, the increase in the black population, and increase on black arrest rates—furthermore, there is evidence for increased discrimination between 1973 and 1982 that would explain the 70s-80s incarceration rates (Harding and Winship, 2016). Harding and Winship also showed that differential population growth can account for one-third of the increase in the prison population difference while the rest can be accounted for by differences in sentencing and arrest rates between 1960 and 1980. So the black population increased more in states that had higher incarceration rates. Nonetheless, the TAAO isn’t supposed to retroactively explain trends.
Therefore, the disparity between whites and blacks remained, even pre-1964. This question, too, isn’t a knockdown for the TAAO either. These questions that are asked when one is provided with the successful novel predictions of the TAAO are just cope since hereditarian explanations don’t make novel predictions and their explanations fail (like the ENA theory).
“Unnever and Gabbidon are just making excuses for blacks with their TAAO.”
This is not what they’re doing with their theory at all. A theory is a well-substantiated explanation of some aspect of the natural word that’s based on observation, empirical data, and evidence. They provide testable hypotheses that can be empirically tested. They also make predictions based on their proposed explanations. Predictive capacity is a hallmark of scientific theories. And it’s clear and I’ve shown that the TAAO makes successful novel predictions. Therefore the ability of a theory to make predictions—especially risky and novel ones—lends credibility to the validity of the theory.
The claim that the TAAO is a mere excuse for black crime is ridiculous. Because if that’s true, then all theories of crime are excuses for criminal activity. The TAAO should be evaluated on its predictive power—it’s ability to make successful novel predictions. Claims that the theory is a mere “excuse” for black crime is ridiculous, especially since the theory makes successful novel predictions. It’s clearly a valuable framework for understanding black crime in America.
“The so-called ‘novel predictions’ you reference aren’t novel at all”
We need to understand what the TAAO actually is. It’s a theory of crime that considers the African American “peerless” worldview. “Peerless” means “incomparable.” They have the worldview they do due to the 400 years of slavery and oppression like Jim Crow laws and segregation. Therefore, to explain black crime we need to understand the peerless African American experience. That’s a main premise of the theory. So the TAAO has one main premise, and it’s from this premise that the predictions of the TAAO are derived.
The peerless worldview of African Americans This premise recognizes the unique historical, contemporary, social, and cultural experiences of African Americans including their experiences of racial discrimination, social marginalization, and racial identity. This premise, then, lays the key groundwork for understanding black crime. This core premise of the TAAO then centers the theory within the context of the African American experience. Each of the predictions below are derived from the core premise of the TAAO—that of the peerless worldview of African Americans without relying on the predictions as premises used for the construction of the theory. Each of the predictions follows from the core premise, and they reflect how the African American experiences of racial discrimination, social marginalization and racial identity influence their likelihood of experiencing racial discrimination. Unnever and Gabbidon gave many arguments and references that this is indeed the case. The predictions, then, weren’t used as premise to construct the TAAO but they indeed are derived from—indeed they emerge from—the foundational experiences of African Americans and then serve as testable hypotheses which are derived from that understanding.
Thus, the predictions follow from the TAAO and they are derived from the foundational premise of the TAAO, without being used in the construction of the theory itself, qualifying as novel predictions according to Musgrave (1988): “a predicted fact is a novel fact for a theory if it was not used to construct that theory — where a fact is used to construct a theory if it figures in the premises from which that theory was deduced” and Beerbower: “the purpose of science is to enable accurate predictions and that, in fact, science cannot actually achieve more than that...The test of an explanatory theory, therefore, is its success at prediction, at forecasting. This view need not be limited to actual predictions of future, yet to happen events; it can accommodate theories that are able to generate results that have already been observed or, if not observed, have already occurred...it must have some reach beyond the data used to construct the theory“
More novel predictions of the TAAO
Therefore, since the TAAO has success in its predictions and hereditarian ones don’t (they don’t even make any novel predictions), it’s only rational to accept the theory that makes successful novel predictions over the one that doesn’t. The only reason one would accept the hereditarian explanations over the TAAO is due to bias and ignorance (racism), since the TAAO is a much more robust theory that actually has explanatory AND predictive power. So the issue here is quite clear—since we know the causes of black crime due to the successful novel predictions that the TAAO generates, then there are clear and actionable things we can do to try to mitigate the crime rate. This is something that hereditarian theories don’t do, most importantly because they don’t make any novel predictions. Since the TAAO makes successful risky novel predictions—predictions that, if they didn’t hold, they would then refute the theory—and since the predictions hold, then the theory is more likely to be true than not. The TAAO not only accommodates, but it makes predictions, and we can’t say the same for hereditarianism.
The issue is that so-called “race-neutral” theories of crime need to assume that racial discrimination isn’t a cause of black American offending because this would then limit it only to black Americans. Therefore race-neutral theories of crime don’t have the same predictive and explanatory power as a race-centric theory of crime—which is what the TAAO is. It’s clear that: the TAAO makes successful novel predictions, the predictions aren’t used as premises in the TAAO, the TAAO is a race-centric, country-specific theory of crime (and not a general theory of crime), racism and stereotypes don’t explain offending for non-African Americans, the theory doesn’t say that blacks lack agency, IQ doesn’t explain crime within families, and cope from hereditarians that one day we will find genes or neurohormonal influences which lead to crime in black Americans is just cope. It’s clear that the TAAO is the superior theory of crime because it does what scientific theories are supposed to do: successfully predict novel facts of the matter, something that hereditarianism just does not do which is why I’m justified in calling it a racist movement. Basically since there are unique characters of a demographic that require perspectives that are solely related to that group, then we need group-centric theories of crime due to the unique experiences of thsg group, and this is what the TAAO does.
Now that I’ve answered common criticisms of the TAAO, I have a few more successful novel predictions of the theory. In my original article I cited 3 novel predictions, how they followed from the theory, and then the references that confirmed the predictions:
(Prediction 1) Black Americans with a stronger sense of racial identity are less likely to engage in criminal behavior than black Americans with a weak sense of racial identity. How does this prediction follow from the theory? TAAO suggests that a strong racial identity can act as a protective factor against criminal involvement. Those with a stronger sense of racial identity may be less likely to engage in criminal behavior as a way to cope with racial discrimination and societal marginalization. (Burt, Simons, and Gibbons, 2013; Burt, Lei, and Simons, 2017; Gaston and Doherty, 2018; Scott and Seal, 2019)
(Prediction 2) Experiencing racial discrimination increases the likelihood of black Americans engaging in criminal actions. How does this follow from the theory? TAAO posits that racial discrimination can lead to feelings of frustration and marginalization, and to cope with these stressors, some individuals may resort to committing criminal acts as a way to exert power or control in response to their experiences of racial discrimination. (Unnever, 2014; Unnever, Cullen, and Barnes, 2016; Herda, 2016, 2018; Scott and Seal, 2019)
(Prediction 3) Black Americans who feel socially marginalized and disadvantaged are more prone to committing crime as a coping mechanism and have weakened school bonds. How does this follow from the theory? TAAO suggests that those who experience social exclusion and disadvantage may turn to crime as a way to address their negative life circumstances. and feelings of agency. (Unnever, 2014; Unnever, Cullen, and Barnes, 2016)
(Prediction 4) Black people who experience microaggreesions and perceive injustices in the criminal justice system are more likely to engage in serious and violent offending. How does this follow from the theory? Experiences of racial discrimination and marginalization can lead to negative emotions like anger and depression among black people. These negative emotions, which are then exacerbated by microaggreesions and perceptions of injustice in the criminal justice system, may increase the likelihood of engaging in serious and violent offending as a coping mechanism or means of asserting power. But, again, those with a stronger racial identity may be more resilient to the effect of discrimination (Isom, 2015).
(Prediction 5) Black Americans who perceive a lack of opportunity for socioeconomic advancement due to systemic barriers are more inclined to engage in criminal activity as a means of economic survival and social mobility. How does this follow from the theory? Perceptions of limited opportunities and systemic injustices can drive individuals to engage in criminal behaviors as a response to inequality (Vargas, 2023).
The fact that the TAAO generates these novel and successful predictions is evidence that we should accept the theory.
We also know that perceptions of criminal injustice predict offending (Bouffard and Piquero, 2013), we know that blacks are more likely than whites to perceive criminal injustice (Brunson and Weitzer, 2009) and we know that there are small differences among blacks and their perception of criminal injustice (Unnever, Gabbidon, and Higgins, 2011). So knowing this, more blacks should offend, right? Wrong. The vast majority of blacks don’t offend even though they share the same belief about the injustices of the criminal justice system. So how can we explain that? “Positive ethnic-racial socialization buffers the effect of weak school bonds on adolescent substance use and adult offending” (Gaston and Doherty, 2018). So the discrimination that black Americans have erodes their trust in social institutions like the school system, and then these weakened school bonds then increase the risk of offending.
Supporting a major tenet of TAAO and prior research on the protective ability of ethnic-racial socialization, the analyses showed that Black males who received positive ethnic-racial socialization messages in childhood develop resilience to the criminogenic effect of weak school bonds and face a lower risk for offending over the life course. (Gaston and Doherty, 2018)
One factor that is salient in the TAAO is racial subordination. We know that black people don’t commit crime because they are black, but we know that their offending is related to socio-environmental context like poverty, bad schools (while racism and stereotypes weaken school bonds blacks have, which makes them more likely to offend), broken families, and lead exposure (Butler, 2010) of which the TAAO addresses. We also know that there is no such thing as a “safe” level of lead exposure and that the relationship between lead and crime is robust and replicated across different countries and cultures. We also know that blacks were used as an experiment of sorts, where they were knowingly exposed to lead paint in subsidized homes.
This environmental racism (Washington, 2019), then, is another aspect of the racial subordination of blacks. And from 1976 to 2005, blacks were 7 times more likely than whites to commit murder. The fact of the matter is, the black-white murder gap has been large for over 100 years. And in discussing environmental racism, Unnever and Gabbidon (2011: 188) are explicit about the so-called genetic hypothesis of crime: “We want to be perfectly clear that our argument in no way is related to the thesis that there is a genetic cause to African American offending.” Therefore, this question doesn’t strike the heart of the TAAO and is just an attempt at evading the successful novel predictions the theory generates.
Conclusion
I’ve shown that the common “criticisms” of the TAAO are anything but and are easily answered. I then gave more successful predictions of the TAAO. It’s quite clear that one should accept the TAAO over hereditarian explanations. We also know that black isolation is a predictor of crime as well—even in 1996 blacks accounted for over 50 percent of murders and two-thirds of robberies (Shihadeh and Flynn, 1996). In 2020, blacks were six times more likely to be arrested for murder than whites. We also know that the belief by blacks in the violent stereotype predicts their offending and their adherence to the stereotype predicts crime and self control (Unnever, 2014). Therefore, a kind of stereotype threat arises here and has effects during police encounters like wkth height (Hester and Gray, 2018)(Najdowski, Bottoms, and Goff, 2015; Strine, 2018; Najdowski, 2012, 2023) , with one argument that race stereotypes track ecology, not race, (Williams, 2023) (just like for IQ; Steele and Aronson, 1995; Thames et al, 2014). We know that stereotype threats weaken school bonds and that weakened school bonds are related to offending, therefore we can infer that stereotype threats lead to an increase in crime (Unnever and Gabbidon, 2011).
Unnever and Gabbidon were quite clear and explicit in their argument and the hypotheses and predictions they made based on their theory. So when tested, if they were found not to hold then the theory would be falsified. But the theories held under empirical examination. Unnever and Gabbidon (2011: 98) were explicit in their theory and what it meant:
Put simply, we hypothesize that the probability of African American offending increases as blacks become more aware of toxic stereotypes, encounter stereotype threats, and are discriminated against because of their race. Our theory additionally posits that these forms of racism impact offending because they undermine the ability of African Americans to develop strong ties with conventional institutions. The extant literature indicates that stereotype threats and personal experiences of racial discrimination negatively impact the strength of the bonds (attachment, involvement, commitment) that black students have with their schools (Smalls, White, Chavous, and Sellers, 2007; Thomas, Caldwell, Faison, and Jackson, 2009). And, the research is clear; weak social bonds increase the probability of black offending (Carswell, 2007).
The worldview shared by black Americans is a consequence of the experience they and their ancestors had in America. This then explains their offending patterns, and why they commit more crime than whites. The socio-historical context that the TAAO looks to explain black crime is robust. Since the TAAO is successful in what it sets out to do, then, I wouldn’t doubt that there should be other race-centric theories of crime that try to explain and predict offending in those populations. The empirical successes of the TAAO’s predictions attest to the fact that other theories of crime for other races would be fruitful in predicting and explaining crime in those groups.
Hereditarians dream of having a theory that enjoys the empirical support that the TAAO has. The fact that the TAAO makes successful novel predictions and hereditarianism doesn’t is reason enough to reject hereditarian explanations and accept the TAAO. Accepting a theory that makes novel predictions is rational since it speaks to the theory’s predictive power. So by generating predictions that were previously unknown or untested and them confirming them through empirical evidence, the theory therefore shows its ability to predict and anticipate real-world phenomena. This then strengthens confidence in the theory’s underlying principles which provides a framework for understanding complex phenomena. Further, the ability of a theory to make such predictions suggests that the theory is robust and adaptable, meaning that it’s capable of accommodating new data while refining our understanding over time.
Hereditarians would love nothing more than to reduce black criminality to their genes or hormones, but reality tells a different story, and it’s one where the TAAO exists and makes successful novel predictions.
Can Racist Attitudes Be Reconciled with Christian Beliefs? On the Hypocrisy of Racist Christians
2050 words
Introduction
I’ve recently come across a lot of Christians who have “Christ is King” in their bio on Twitter. When you begin looking at their tweets, you can see that they’re not practicing what Jesus preached, since you can see some very racist beliefs they hold. What would Jesus think about that? Why are Christians more racist than non-Christians? We know that Puritan beliefs and IQ are similar. So let’s start there, and then let’s try to figure out why Christians are so racist, seemingly going against Christ’s teachings. Because by looking at the Bible and what Jesus said about treating people who are different to ourselves, we can see that Christians who hold to such beliefs on race and who hold such racist attitudes are contradicting themselves, and there is no way to reconcile the contradiction. It seems that, to these Christians at least, their race is their religion as their race comes first, not their religion, since some of them would not accept a non-white in their congregation.
Racism and religion
Christians are more likely to hold racist beliefs than non-Christians. White Christians are also more likely to deny that structural racism exists. Attending church doesn’t make white Christians less racist (See this article.) We know that there is a correlation between people identifying as Christian and believing that blacks lack willpower and also that economic differences between whites and blacks aren’t due to discrimination (Applegate and Maples, 2021). We also know that “warmth toward conservative Christians are not related to favorable racial attitudes among black Americans” (Yancey, 2024). There are also forms of implicit racism in Christianity (Bae, 2016). Why may this be?
“Paradoxically”, white supremacism has historical roots in Christianity. There is a Pew poll which has asks whether there is racism where none exists or people overlook racism where it exists. Fifty-three percent of Americans stated that people not seeing racism where it doesn’t exist is a problem while 45 percent said seeing racism where it doesn’t exist is more of a problem. But white Christians were more likely to believe that racism was seen where it didn’t exist—72 percent of white evangelicals, 60 percent of white Catholics, and 54 percent of white mainline protestants. But 10 percent of black protestants, 35 percent of unaffiliated Americans, and 31 percent of non-Christian religious Americans stated that seeing racism where it didn’t exist was a bigger problem. However 88 percent of black Protestants, 69 percent of non-Christian religious Americans, and 60 percent of “Hispanic” Catholics stated that not seeing racism where it did exist was a problem while 27 percent of white evangelicals, 44 percent of white mainline Protestants, and 39 percent of white Catholics held the belief. (See the WaPo article on the Pew poll.) At the end of the day, white Christian theology is “infected with racism” (Norris, 2020). Though some have argued that white supremacy matters more than religion and Christianity became the “white religion” (McMahon, 2022).
Eugenics and Christianity are also linked. Eugenics itself also has theological foundations, as does hereditarianism. Dozono (2023) writes:
The link between eugenics and modernity was further intertwined through Christian thought,1 exemplified in Hegel’s framing of Christian Europe as the highest principle. Keel (2018) traced the roots of racial science to Christian thought, asserting that modern science’s universal narratives of human development concealed their foundation in Christian European beliefs.
We also know that hereditarianism has its roots in Puritan ideology, and that the “intelligence men” were influenced by the religious beliefs around them.
People could intertwine their cultural beliefs and identity with their religious identity and have their prejudiced, biased ideals mesh with their religious ideals. They also could see their religious identity as inseparable from their cultural background which then has them persist in their racist beliefs despite the teachings of their religion. Some could also experience cognitive dissonance in that they hold contradictory beliefs of hate for other groups while espousing values like “Christ is King.”
So what would Jesus think about people who say “Christ is King” while spouting some virulent racism?
The phrase “Christ is King” refers to the Christian belief that Jesus is the ruler over all of creation. Jesus said he remembers what it was like with God (John 8:38-42) so this would imply that Christ would indeed be ruler over all creation. So how would Jesus feel about the fact that there are people who say he is King while professing such hateful rhetoric about His other children? What would happen if Jesus came back tomorrow and saw and confronted these people who hold these two contradictory beliefs?
Jesus would more than likely strongly oppose racism and prejudiced views. I think it’s quite obvious—based on His teachings—that He would strongly oppose such hypocrisy and the use of His name while such hate was espoused. His teachings and actions espoused loving and accepting people regardless of their background. In the Gospels, Jesus showed compassion to people who were considered outcasts of society, sinners, Samaritans, and gentiles. Jesus’s encounter with the Samaritan woman at the well is a good example of this.
In John (4: 1-42) Jesus came across a Samaritan woman at a well. Samaritans and Jews hated each other at the time, which traced back to Babylonian times. Although there are a few theories on the origin of Samaritans, like them not being Israelites but descendants of Mesopotamians to descendants of Judes who didn’t go into exile, at the time Jesus was alive, there was a clear divide between the two groups. So Jesus went through Samaria and got to a well. At the well, Jesus asked a Samaritan woman for a drink from the well, to which the woman stated “You are a Jew and I am a Samaritan woman. How can you ask me for a drink?” Talking with a woman in public at the time was restricted, and men didn’t talk to women in public especially when they were alone. So by initiating a conversation with not only a Samaritan but also a woman Jesus broke down cultural norms. He then let her know that He was the Messiah which showed Jesus’s willingness to engage with outcasts of society. The parable demonstrates the inclusivity of heaven, and that despite cultural/ethnic barriers, Jesus extended salvation through Him to all people.
Matthew (8: 5-13) also demonstrates the inclusivity of God’s kingdom in heaven. Jews viewed Roman’s as oppressors and themselves as the oppressed during Jesus’s time, yet despite the cultural divide the Roman centurion still approached Jesus to heal his servant. Jesus just uttered the words and his servant was healed. This is yet another instance of cultural barriers being broken and Jesus going against social norms of the time.
One of the most famous stories in the Bible is that of the good Samaritan (Luke 10: 25-37). Jesus was talking to a lawyer, and the lawyer asked him “Who is my neighbor?” and Jesus replied “What is written in the Law?“, to which the lawyer replied “Love your neighbor as you love yourself“, to which Jesus answered in the affirmative. The lawyer then asked “And who is my neighbor?” Jesus then told a story about a man going to Jerusalem from Jericho who was then attacked by robbers, stripped naked and left for dead. Both a priest and a Levite saw the man but passed by him. Then a Samaritan riding on a donkey saw him, gave him some oil and wine and took him to an inn. He paid the innkeeper and then said to him that he would come back and pay him any extra costs he would incur over the time spent taking care of the man. Jesus then asked the lawyer to tell him which of the three men was a neighbor to the beaten man? Jesus then told the lawyer to go and do likewise. So the message here is to be kind to everyone even if they have a different background from you. The message here is “Love your neighbor as you love yourself” (Mathew, 22: 39).
In Acts 10, a Roman centurion converted die to being visited by an angel. Peter was then shown a vision and the Spirit told him that three men would be looking for him. After the Roman explained his vision, Peter stated “I now realize how true it is that God does not show favoritism but accepts from every nation the one who fears him and does what is right.”
Finally we have Matthew (15: 21-28). Some have read this as Jesus being a racist, since he refers to the Caananite woman as a “dog.” But based on the sincerity of the woman’s faith, Jesus was willing to heal the woman’s daughter. This parable shows Jesus: willingness to confront his own prejudices.
These five passages have a few things in common. They talk about the importance of being inclusive, not being prejudiced, recognizing Jesus’s authority, and breaking down social barriers.
American society is racist, the church is part of the society, ergo, the church has problems with race. (The Left Behind: Why Are White American Christians So Racist?)
The above argument is a transitive property. Here it is spelled out more fully.
American society (A) causes racism (B). Racism (B) causes problems with race in society like church (C). Problems with race in society like church (C) cause internal racial issues/conflict (D). American society (A) causes internal racial issues/conflict in church (D). This argument highlights the systemic nature of racism and it’s various impacts on society, including of course the church.
Conclusion
I have discussed religion, racism, and societal attitudes. People who hold racist beliefs may identify as Christian and there are many reasons for the phenomenon, like selective interpretation of scripture, cultural influence, politics, and the historical legacies of racism. Further, there is a known relationship between Christian beliefs and racist attitudes.
I then analyzed some Bible passages which have similar messages of inclusivity, compassion, and the offer of salvation no matter ones lot in life or their racial/ethnic background. These stories show that Jesus sought to love people, not to viciously hate as some Christians do. These stories call on us to love our neighbors as we love ourselves. But some Christians hold racist beliefs so how can that be reconciled? They can’t—they are contradictory beliefs.
In fact, Galatians (3: 28) states “There is neither Jew nor Gentile, neither slave nor free, nor is there male and female, for you are all one in Christ Jesus.” This means that in Christ we are all the same—we are all equal to one another. So how can the racist Christian reconcile these two quite clearly contradictory beliefs? Again, they can’t. This verse espouses the belief in equality of all believers in Christ. So why, then, are Christians such racists, even towards people who hold the same or similar beliefs? Clearly they are just “cafeteria Christians“—where they pick and choose which scripture to follow and which they won’t. I then gave an argument that since American society is racist so too are it’s institutions, of course one of which are churches.
There are racial differences in the belief of an afterlife, and blacks are more likely to believe in heaven compared to whites. Some have claimed that racial phenotypes would exist in heaven and hell, while others claim that it’s an open question as to whether or not races will exist in heaven (Placencia, 2021).
But at the end of the day, it is a contradiction to believe in Christ so hard, believe his is King, believe in heaven but then hold to racist beliefs and attitudes towards different people. Even when Jesus himself helped others of different backgrounds and told stories of helping your neighbor and treating your neighbor as you want to be treated. All in all, this hypocrisy from some Christians cannot be reconciled with what is in the New Testament. The views are clearly contradictory and only cognitive dissonance allows one to hold the dissimilar views in the first place.
So if someone holds Christian beliefs, then they cannot hold racist attitudes. Therefore if someone holds racist attitudes then they cannot hold Christian beliefs. It’s a contradiction to hold Christian beliefs and profess racist attitudes.
Abolishing Whiteness Doesn’t Entail Abolishing White People
1450 words
Introduction
In recent years the concept of “whiteness” has been talked about more and more. With the rise of whiteness studies, this has gotten into the lens of the alt-right, and seem to take offense at the phrase “Abolish whiteness”, taking it to mean that they must mean they want to abolish whites. But this is a confusion based on what whiteness means and it’s relationship to white people. Contrary to these misconceptions, abolishing whiteness doesn’t entail abolishing white people. It, instead, seeks to deconstruct the social constructs and privileges which are tied to the concept whiteness. So by exploring a thought experiment, I will show why abolishing whiteness doesn’t entail abolishing white people. It’s quite clear that, once the concept of whiteness is understood and how it is distinct from white people themselves, this is just based on a scare-tactic.
Why abolishing whiteness doesn’t entail abolishing white people
I’ve seen what is obviously a fake quote from Noel Ignatiev going around a lot recently, which states:
If you are a white male, you don’t deserve to live. You are a cancer, you’re a disease, white males have never contributed anything positive to the world!
I searched for any reference I could but I couldn’t find it… Weird, almost as if it’s fabricated. Nonetheless, Ignatiev was a co-founder of the magazine Race Traitor, and it’s tagline was “Treason to whiteness is loyalty to humanity.” Bernstine Singley, in his book When Race Becomes Real: Black and White Writers Confront Their Personal Histories, writes:
The goal of abolishing the white race is on its face so desirable that some may find it hard to believe that it could incur any opposition other than from committed white supremacists.
Whoa, case closed, right? Not at all. Because the next paragraph is explicit by what is meant by “Abolish whiteness”:
Our standard response is to draw an analogy with anti-royalism: to oppose monarchy does not mean killing the king; it means getting rid of crowns, thrones, royal titles, etc….
That makes more sense. Because “Abolishing whiteness” doesn’t entail “Abolishing whites.” The two passages taken in context entails that the goal is abolishing the concept and privileges associated with the white race, not the abolishing of white people.
Monarchy symbolizes hierarchical power structures, and so to does whiteness—it represents a system of privilege that confers advantages to certain groups while marginalizing others. Clearly, the comparison with anti-royalism, where opposition of the monarch doesn’t entail the murder of individuals, but it refers to dismantling the structures and symbols associated with it. Therefore, in the context of race, it suggests challenging the social constructs and systems which perpetuate racial hierarchies, rather than targeting individuals and genociding a group. So it’s about challenging and abolishing systems of oppression.
Now white privilege is an apt concept to talk about here, but we need to be specific and talk about white class privilege. So by acknowledging this concept, it shifts the focus to encompass broader systems of inequality. White privilege refers to the unearned advantages and benefits that white people experience in virtue of their racial identity. White privilege intersects with other forms of privilege to shape an individual’s experiences and opportunities within a society. So recognizing white privilege is imperative in abolishing the concept of whiteness.
A simple thought experiment will explain why abolishing whiteness doesn’t entail abolishing white people.
Imagine a world where skin color and other racial traits are randomly assigned at birth, effectively eliminating the color/racial distinction for racial designations. So everyone, regardless of their family or ancestral background, can be born with any combination of racial traits, including skin color hair texture, facial features, and other physical characteristics traditionally associated with racial groups. This will show that abolishing the concept of whiteness would lose its social and historical significance.
In this society, racial identity is entirely arbitrary, and it has no correlation with one’s ancestry or generic heritage. People may be born with traits traditionally thought of as “white”, “black” “Asian”, “Native American”, or “Pacific Islander” traits, or any combination of them, irregardless of their actual family background. So in this society, “whiteness” completely loses its traditional meaning since there is no longer a fixed group of people who possess exclusively “white” racial traits. Instead, anyone from any background can potentially possess these traits, which then blurs the line between racial categories.
But despite reassigning and shuffling racial traits, the existence of people with “white” traits remains unchanged. These people may have fair skin, certain facial features, or other physical characteristics traditionally associated with the white racial group, even though these traits are now randomly assigned to individuals.
But what significantly changes is the social and cultural significance given to those traits. In a society where racial traits are randomly assigned, no longer would there be a hierarchy or system of privilege based on racial identity. Thus, the concept of whiteness no longer carries the same weight or privilege it used to because racial traits aren’t correlated with superiority or inferiority.
Therefore, abolishing whiteness in this thought experiment doesn’t entail abolishing white people. It instead involves dismantling the social constructs and structures which have historically been associated with the concept of whiteness. It’s about challenging the inequities perpetuated by racial hierarchies rather than targeting or eliminating individuals on the basis of their racial identity. So abolishing whiteness doesn’t entail abolishing white people.
Conclusion
As can be seen from this discussion, abolishing whiteness doesn’t entail abolishing white people. Such delusions comes from white nationalists and reading into “Abolish whiteness” and inferring that it must mean “Abolishing white people.” This then can be likened with the so-called “great replacement theory“, where abolishing whiteness is being carried out through, great replacement. So the phrase “Abolish whiteness”, along with the fabricated Ignatiev quote and fears of an intentional great replacement, serves to radicalize white people to hating Jews (becoming anti-Semites). Some may see the fabricated quote and say something like “Oh of course a Jew is saying that about Whites.” But this fails to understand race in America, since Jews are white (along with MENA people).
All in all, this stems from the paranoia of being intentionally replaced by migrants with higher TFRs, and implicating Jews and other elites into the plan to eradicate whiteness. But as I’ve shown here, there is no entailment that abolishing whiteness means abolishing white people. It’s the same with the so-called great replacement—there’s no entailment from the 2 accepted premises to the conclusion.
Nonetheless, by actually reading what people write and the surrounding context without quote-mining, you’ll be able to see the argument they’re making and be able to understand the argument being made. That’s a novel concept I know, but some need to hear this.
I don’t even think such an endeavor is achievable and possible since race is so engrained in the fabric of American life. No matter where we go, we see race, we hear about race, and it’s observed through one’s phenotype due to the social construction. But my goal here was to show that when one says they want to abolish whiteness it doesn’t entail that they want to abolish white people.
3/12/24 Addendum: “RR, what about abolishing blackness, Jewishness, Italianess and other ‘nesses’? Doesn’t that entail X, Y, Z?” There is one key difference here: As I argued, whiteness has been socially constructed to confer power, privilege, and superiority in the West. This construction has been used to justify countless acts of systemic oppression. Consequently, these other groups lack the power to confer such systemic oppression. Whiteness is deeply intertwined with systems of privilege, but abolishing the aforementioned identifies doesn’t have the same implications for systemic inequalities. Whiteness is a social construct based on racial identity, whereas the aforementioned “nesses” have distinct cultural, identifies with their own languages, cultures, and traditions. So saying that accepting the argument I made here entails the abolishing of the aforementioned identities entails erasing or suppressing those identities which is fundamentally different from arguing to abolish the concept of whiteness. Finally, trying to argue that accepting the argument I made entails that we should also abolish the aforementioned identities infringes on one’s right to religious/cultural freedom and self-determination while also eventually leading toward cultural erasure. Therefore, since abolishing whiteness doesn’t entail abolishing whites as I argued—only abolishing systems of oppression—then abolishing whiteness doesn’t entail abolishing the identities of the aforementioned groups (who are also white themselves).
(P1) If advocating for the abolition of whiteness means advocating harm against white people, then abolishing whiteness entails abolishing white people.
(P2) Abolishing whiteness doesn’t entail abolishing white people.
(C) Thus, advocating for the abolition of whiteness doesn’t entail advocating abolishing white people.
Personality Changes and Organ Transplants
2200 words
Introduction
People who have received organ transplants have reported stark changes in their personalities. Some (truly outrageous) stories claim that people who receive organs from people then get some of their donor’s personality traits. There are a few explanations like cellular memory, psychological, physiological, neurological,, immunological, DNA/RNA/epigenetic explanations. I think that the cases of personality change post-transplant are the same as twin studies, reporting only where there is remarkable similarity. Nonetheless, I’m skeptical of such claims. And I don’t think that, even if they’re true, that dualism is harmed. I will conclude with a discussion of my cognitive interface dualism and how even if the proposed mechanisms to explain observed personality changes in organ transplant receivers would hold it wouldn’t undermine my theory of dualism.
Proposed explanations for personality change post-transplant
Psychological explanations—The psychological impact of receiving a new organ could lead to a change in behavior. They may feel a sense of gratitude or connection to the donor which could change their behavior. The emotional experience of having a transplantat could profoundly affect the patient’s personality before and after surgery. If people receive a heart from someone who was outgoing or adventurous and they then become adventurous, this is then attributed to the organ transplant, specifically in a kind of cellular memory (reviewed below). So the chain goes like this: transplant -> connection to donor -> change in personally
Physiological explanation—Medication used to prevent organ rejection could affect personality in virtue of affecting brain chemistry. People who are to undergo a transplant are given immunosuppressive medication, to prevent the rejection of the transplanted organ. These medications suppress the recipient’s immune system which then could have various effects on the body. Some could also pass the blood-brain barrier. Certain medications, too, could also influence neurotransmitter production like serotonin, norepinephrine, and dopamine. Having an organ transplant is a major surgery, and the body becomes inflamed after. So the physiological response to stress could affect organ systems after the transplant. So along with the stress on the body of organ transplantation along with immunosuppressive medications, both of these could lead to changes in hormonal levels and signaling pathways. The trauma of surgery and recovery could also affect a person’s mental states. Here’s the chain: immunosuppressive medication -> altered brain functioning -> brain chemistry/function changes could alter personality
Neurological explanation—Organ transplants can lead to trauma of surrounding tissue. The transplantation process along with the medications one had to take can then influence neurochemical activity in the brain. Surgical, pharmacological, immunological and psychological factors could interact to cause personality change. Here’s the chain: after transplantation, signals from organ interact with recipient nervous system -> the signals could affect neural networks associated with specific traits/memories -> over time these interactions compound to change personality.
Immunological explanation—Bidirectional communication between the immune system and CNS—known as neuroimmune crosstalk (Tian et al, 2012)—could also be responsible. Organ transplants and immunosuppressive medication could disrupt this crosstalk. Further, inflammation could also affect neural functioning. Here’s the chain: suppressed immune system so organ isn’t rejected -> immune cells could interact with CNS -> immunological interaction could make changes to brain physiology which leads to personality change.
There are quite a few explanations for why personality changes occur that don’t rely on cellular memory. Each of the proposed explanations offers potential mechanisms to explain observed personality changes. Whole the psychological explanation emphasizes the emotional and psychological aspects of organ transplantation, while the physiological explanation focuses on the broader physiological effects of transplantation on the recipient’s body. The neurological explanation goes into the direct effect of transplantation while the immunological explanation highlights the role of immune-mediated processes in influencing brain physiology.
Cellular memory—This is where organs, cells or tissues retain memories or information from their previous host which then influence the behavior of the new recipient of the organ. Of course this is a very speculative idea and there isn’t really much scientific evidence for the claim. I can see someone trying to say that the neurons in the transplanted organ somehow had an effect on the personality change.
Based on anecdotal reports along with case studies of organ recipients who claimed to have acquired new skills, personalities, or preferences following their transplants, such stories capture the imagination of people. Such reports often involve cases in which the recipient exhibits behaviors or preferences that are seemingly unrelated to past personal experiences but are related to their organ donor. (I will quote some people below on this and their experiences.) So these cases have pushed along the claim that cellular memories can be transferred along with transplanted organs.
One hypothesis is neural network transfer. Memories or information stored in the brain of the organ donor could be transferred to the recipient through neural connections which are established through the transplantation process. So neural networks associated with memories or learned behaviors could be preserved within the transplanted organ leading to an influence in the recipient’s brain functioning.
A small number of donor cells could persist in the transplanted organ, which then could involve microchimerism. The donor cells could then interact with the recipient’s tissues and cells and then influence behavioral or physiological characteristics.
Epigenetic modifications which regulate gene expression without a change to the genome could play a role in cellular memory. Changes in gene expression patterns could persist in the recipient which then leads to behavioral changes.
Finally, psychological changes like the placebo effect and expectations could contribute to the perception of cellular memory. They could unconsciously or consciously adopt behaviors of the organ donor due to psychological or social influence.
But the anecdotal reports of cellular memory fall prey to post hoc rationalization, the placebo effect, and selective reporting. Moreover, neural network transfer and microchimerism lack evidentiary support to substantiate their role in the behavioral changes in the donor. There is a lack of a causal relationship between recipient experiences and donor characteristics. Factors like the recipient’s pre-existing beliefs, psychological adjustment to transplantation and social support networks more than likely play a significant role in shaping the post-transplant experiences of the donor.
One study found that 3 patients reported changes in their personality post-heart transplant (Bunzel et al, 1992). One online survey of 47 transplant recipients (23 heart and 24 organ) found that 89 percent of the donor’s experienced personality changes (Carter et al, 2024) (which was substantially higher than that of the results of Bunzel et al).
One white man was given a heart from a black kid who was gunned down in a drive-by shooting, and he loved classical music. After the man’s transplant, he began liking classical music after previously hating it. He stated that he know it wasn’t his heart because “a black guy from the ‘hood wouldn’t be into that’…and now [classical music] calms my heart” (Christopher, 2024). The recipient’s wife then said that the donor was socializing more with black coworkers at work and he began to love classifical music post-transplant. She said “He even whistles classical music songs that he could never know. How does he know them? You’d think he’d like rap music or something because of his black heart.”
In another case, a 19 year old woman was killed in a car accident. She was also a vegetarian and owned a health food restaurant. As she was dying, she said to her mother that she could feel the impact of the car hitting her. So the organ recipient was a 29 test old women who reported two things occurring post-transplant—she said she could feel the impact of the accident on her chest and she began hating meat after her surgery, saying that “now meat makes me throw up” (Christopher, 2024). Before her transplant she was a lesbian and then after, she was into men.
A 3 year old died in an accident at a family pool. The recipient—a 8 year old—loved the water before his surgery but after it, according to his mother, he was “now deathly afraid of water” (Christopher, 2024).
A 14 year old girl died in a gymnastics accident, and per her mother she had a “silly little giggle”. She was also kind of anorexic with food. Her recipient was a 47 year old man. After his surgery, the recipient’s brother states that he was acting “like a teenager” and that he’s “like a kid.” He also reported that when they went bowling he “yells and jumps like a girl” and that he “had a girls laugh.” He was also nauseous all the time and his doctor had a concern about his Wright (Christopher, 2024).
In the last case Christopher (2024) discussed, a cop was murdered by a drug dealer after being shot in the face. In his mug shot, the cop’s wife stated that the drug dealer looked like some depictions of Jesus. After the heart transplant, the donor stated that he would have dreams of seeing a “flash of light right in my face and my face gets real, real hot. It actually burns. Just before that time, I would get a glimpse of Jesus. I’ve had these dreams and now daydreams ever since: Jesus and then a flash” (Christopher, 2024). Finally a girl received a transplant from a teenage boy who died in a motorcycle accident. After her surgery her mother stated that she began liking KFC, “walking like a man“, and she wanted to drink beer. Come to find out, these were some things the boy who died liked to do. There is also a recent article on Psychology Today talking about cellular memory.
All of these cases could simply be an artifact of selective reporting or coincidence.
Conclusion
While these cases are no doubt interesting and if true means that we need to propose different mechanisms of the like as in with cellular, DNA/RNA, epigenetic and protein memory (Pearsall, Schwartz, and Russek, 2000), I think current evidence points it to be just coincidences or post hoc rationalization. Now of course, if these cases were proven to be genuine then we should revisit them and think about mechanisms like the above in this paragraph.
As can be seen, anecdotal reports and studies suggest the possibility of behavioral changes that mirror, in some cases, that of the donor. But the concept of cellular memory is currently speculative and lacks empirical evidence. We could have controlled studies on animal models to see whether behavioral or physiological traits associated with the donor are transferred to the recipient. We could also analyze gene expression, epigenetic modification, RNA expression, DNA methylation, and protein levels within transplanted tissues or organs from donors to recipients. We could then male comparisons between tissues and organs from donors and recipients to ascertain any kind of differences or similarity which could be indicative of memory transfer. These are but a few empirical tests I can think of that we can begin to carry out to test this if it’s more than coincidence or post hoc rationalization.
Lastly, in August of 2023 I formulated a theory of dualism I call cognitive interface dualism which argues that action potentials are the interface that Descartes was looking for. (I had an A&P professor state that out of the whole textbook he taught out of that muscle movement was some of the only conscious activity that could be done. Then that dawned on me and I formulated my dualist framework.) Dualism posits that mind and body are two separate, substances with mind being irreducible to body/brain. So even if there is a personality change, that doesn’t entail that the mind has changed. In cognitive interface dualism, interactions between the mind and body occur through action potentials (APs). Personality changes could occur through the interface of the interactions, but changes in physical organs like the brain do alter the fundamental nature of the immaterial mind. (Of course damage to the brain can influence the mind since the brain is a necessary pre-condition for human mindedness, but that’s different.) Even if a person’s personality undergoes changes after a transplant, their underlying sense of self, consciousness, and subjective experiences remain intact. It doesn’t necessarily imply a direct alteration of mind,
The other explanations I discussed above are also on different levels of explanation than dualism. Dualism is about ontological explanation whereas the other explanations operate at the physiological and molecular levels. Cellular mechanisms could influence certain aspects of behavior or experience, but it doesn’t undermine the existence of a separate, irreducible mental realm. Dualism and biology can also be complimentary, where biology would address any possible mechanisms like cellular memory, RNA/DNA/epigenetic expression while dualism addresses questions of consciousness, the nature of the mind and subjective experience. Even if cellular memory would be shown to be true this wouldn’t undermine my theory, since the core aspects of one’s consciousness, self, and subjective experiences remain intact. So these would offer complimentary perspectives.
In sum, while this is an interesting area to look at, I am a skeptic. I won’t completely discount it being true, but I have proposed some empirical tests to see if it does hold. And if it does, it doesn’t have any implications for dualist theories, including my cognitive interface dualism.
Evaluating Heritability in an Imagined Metabolic Ward Study of Twins
2000 words
Introduction
For the better part of 100 years, twin studies have been used to prove that there is a genetic influence to all traits. The claim is that “all human traits are heritable”, which is the “first law of behavioral genetics” as stated by Turkheimer. Using twin, family, and adoption studies, it is claimed that some traits are “more genetic than others”, especially IQ. But a meta-analysis 10 years ago found that heritability was 49 percent for all traits (Polderman et al, 2014; see here for critique). However due to the falsity of the EEA—which holds that environments are similar for both MZ and DZ twins—the so-called heritability is shared environment (h2=c2). (See Joseph, 2014 for arguments against twin interpretations and Joseph 2022, 2023 for arguments against Thomas Bouchard’s twin studies. See Bouchard 2023 for response to Joseph 2022, and Joseph 2023 is Joseph’s response.)
But imagine we could bypass such devestating issues for twin studies that invalidates them for their stated aims. What would we find? Here, I will create a thought experiment in which 100 MZs and 100 DZs were placed in a metabolic ward immediately after birth. In this scenario, every single aspect of the environment is meticulously controlled—as is the case in animal breeding studies—which would then eliminate shared environmental influences and therefore would give us a “real look” into the (obviously context-dependent) heritability of traits.
However unethical this study is, though, even if it were possible there are a slew of conceptual and empirical issues that would still invalidate the estimates. The issues include the limitations of assuming additive genetic effects, the presence of GxE, the non-representative nature of twins, and the missing heritability problem. The argument I will mount here will show that even with perfectly controllable environments, we still wouldn’t be able to “estimate heritability” and furthermore due to the interaction problem that this study still wouldn’t overcome, that would further make any such results meaningless.
The unethical twin metabolic ward study
A metabolic ward is a controlled environment which is usually found in a hospital, research facility or clinic in which the participant’s can be closely monitored and their metabolic processes studied under tightly regulated conditions. Researchers can control diet, diet quality, sleep, physical activity, and environmental influences to investigate nutrient absorption, energy expenditure, hormone regulation and metabolic disorders. Controlled settings like this allow researchers to get precise measurements, ensure that a participant is following a diet correctly as to study their metabolic processes on that diet, and understand the physiological mechanisms better. (See Hodges and Bean, 1960.)
Now imagine all of that but imagine that 100 MZ twins and 100 DZ twins were—after birth—immediately whisked away to a metabolic ward and from that moment on, they were in a tightly regulated environment as to attempt to minimize or completely eliminate shared environmental influences. What would happen?
We could learn about the genetic influence of genetics on metabolic processes, like the influence of genes on nutrient absorption, energy expenditure, hormone regulation and metabolic disorders. So by comparing MZ and DZ twins on the similarity and differences in these traits, we could then ascertain the genetic influence that underlies the variability between them. This would also allow researchers to completely control sleep, eating, physical activity levels and other environmental exposures which would then allow researchers to tease a part the relative influenced of genes and environment. This would also allow us to see how GxE affects a trait. We could learn about how genetic predispositions interact with dietary factors or how lifestyle choices modulate metabolic health outcomes and disease risk. It could also give us insights into individual variability so we can give individualized metabolic approaches.
However, even if IRB can be passed, there are of course potential psychological and social implications for those studied. The issue is, we have minds and we therefore react differently to things independently of our genetic makeup. So although we could potentially learn some interesting things about human metabolic processes, when it comes to psychological ones, due to the unrepresentative environment, these will be less valid than metabolic processes.
We technically do “measure” heritability of traits now, but they’re heavily confounded, and even though—intuitively—it may seem like such an experiment would be valid and show “true heritability” (whatever that means), we know that h2 is context-dependent and not useful for individuals. Such a study would be about perfectly controlling every aspect of the environment as best we could to decrease whatever environmental effect would bias the h2 upwards. But I think a slew of conceptual issues would still even then invalidate such interpretations.
Cattle and humans are quite obviously different in their propensities, and even then, if we could pass IRB ethics and lock 100 MZs and 100 DZs in a metabolic ward and perfectly control every aspect of the environment, the issue there would be our experiences in society and our interactions with others are extremely meaningful to how we develop as humans. So if that kind of experiment were possible, then the h2s would be way lower than twin, family and adoption studies give us (we see this in animal breeding studies—way lower h2 in those traits than for IQ, see Schonemann, 1997).
There are also further conceptual issues like the falsity of the addivitiy assumption, GxE, GxG (Zuk et al, 2011), psychological distress, and the fact that we become human and gain our minds through our interactions with people in broader society would also further confound such interpretations. Furthermore, since the EEA is false, h2 equals c2, meaning the heritability is shared environment. That’s the best interpretation we have of twin studies. And the missing heritability issue that plagues GWAS and other molecular approaches to trait heritability further throws a wrench in this, since it’s completely possible that GxE (and other interactions) contribute to trait variance, and this—along with epigenetic and non-genetic factors—aren’t accounted for by h2 estimates (since they assume additive independent genetic effects). So even if such an experiment were possible and the conceptual issues I raised weren’t an issue, that alone would invalidate the study.
One big issue is the fact that twins aren’t representative of the population at large. For example we know that twins have a higher chance of having low birth weights, are more likely to be born premature than non-twins (Isakkson, Ruchkin, and Ljungstrom, 2023). Low birth weight is also predictive of health outcomes in adulthood (Hassan et al, 2021). Twins are also more likely to experience complications during pregnancy and childbirth like preterm birth, intrauterine birth restriction and childbirth trauma. The intrauterine birth restrictions could also influence their metabolic development and responses within the ward, which This then would influence their outcomes in adulthood compared to non-twins. We also know that there are a slew of environmental effects that increase the chance for DZ twinning between groups (MZ twinning is relatively the same between them). Moreover, due to the complications that twins face before, during, and after childbirth, this could then affect their metabolic health and responses within the metabolic ward. Therefore, while this thought experiment proposes ways in which researchers can use a metabolic ward to study the relative influence of genes and environment on traits (assuming that there are no other conceptual issues with such an endeavor), researchers would still need to take into account the ways in which twins differ from the general population which would then influence the results that would be observed in the metabolic ward study.
Joseph (2009) proposed an interesting thought experiment:
Finally, we could conduct a thought experiment on political behavior and social attitude correlations among reared-apart MZ twin pairs who, while genetically identical, grow up in truly uncorrelated environments in different eras. Suppose one male MZA twin is placed at birth in an aristocratic Japanese family in 1802. The other male MZA twin is placed at birth in a poor peasant family living in the highlands of El Salvador in 1965. Unlike previous TRA studies, inwhich the investigators calculate correlations among partially reared-apart twins sharing many cultural influences, in our thought experiment we eliminate cultural influences such as family (which most MZAs share to some extent), mutual association and influence (which most MZAs also share to some extent), nation, region, ethnic, religion, economic class, and birth cohort (of course, they would still be the same sex).75 I conclude this thought experiment by posing the following question: Would we expect a study of genetically identical pairs of this type to find sizable correlations for political behavior and social attitudes?
The correct conclusion to draw here is that although the twins share genetic makeup (to whatever degree they do), but they are raised in different environments and different time periods, the divergence in their experiences shows that heritability can’t fully capture the role of environment in capturing in shaping not only these traits but all traits studied by twin researchers.
Conclusion
In the end, if such a study were logistically possible and ethical, it wouldn’t show h2 anywhere near twin, family and adoption studies. We’ve basically reached an upper bound on molecular h2 estimates. And of course twins aren’t representative of the general population at large (since they have lower birth weights/injuries and a higher mortality rate). And even then, twins in these studies aren’t even representative of all twins. This is, yet again, a conceptual failure of hereditarianism—the assumption that twin studies will tell us anything about “the genetic architecture” of traits merely due to genetic similarity and being so-called “reared apart.”
Even if such a study were possible, there would be a lack of generalizability due to the fact that the observations occurred during rightly controlled conditions. Such a study is fraught with conceptual, empirical and ethical issues. Biases in sample selection, the health differences between twins and non-twins, prenatal and peri-natal factors, psychological and social dynamics and the lack of generalizability highlight why twins aren’t a representative of the population at large. Moreover, the complexity of metabolic traits and the assumption of genetic independence further complicate interpretations in the ward setting—especially since DNA interacts with all other developmental resources (Noble, 2012).
But even in a possible world where such limitations can be addressed and made meaningless, there are still inherent limitations of heritability estimates as a measure of the genetic determination of traits (in the popular culture, see Moore et al, 2016 for a critique if the heritability concept). Heritability estimates are context-dependent and subject to numerous confounding factors.
But disregarding this thought experiment and looking to the real world, we know that there is no way to estimate interactions in population studies. The so-called solution is to assume that there are NO gene-environment and gene-gene interactions, and this therefore biases such estimates upwards (Ho, 2013). This shows that the assumption of additive effects and no GxG or GxE interactions would still pose a problem—an insurmountable one. Thus, even estimates from this study would still be subject to upward bias due to the nature of the assumptions of heritability. This shows that even in a perfectly controlled environment that measuring h2 is impossible due to the disregarded biological facts inherent in the heritability formula. Joseph and Richardson (2024) also show that Herrnstein and Murray (1994) didn’t give any valid evidence that genes influence IQ scores within groups.
So the conclusion here is very simple—since heritability studies can’t tell us anything about the relative contributions of genes and environments due to the inherent nature of the heritability formula which disregards interactions, and due to the whole slew of other conceptual and empirical issues raised here, even in a perfectly controlled environment we still wouldn’t be able to get “true h2” estimates of any kind of trait in the metabolic ward. So the goal of behavioral genetics is an impossible one.
Race and Racial Identity in the US
2300 words
Introduction
The concept of RACE is both a biological and social construct. In the US, there are 5 racial groups, and every 10 years the Census Bureau attempts to get a tally of the breakdown of racial identity in the US. The Census defers to the OMB, who in 1997 updated their racial classification. So race is identities culturally, socially, and historically. But racial identity goes beyond the US Census survey and encompasses one’s experiences, beliefs and perceptions which shape their identity and how they understand themselves and the society in which they live.
In the US we have whites, blacks (or African American), East Asian (or Asian), Native American or Alaskan Native, and Native Hawaiian or other Pacific Islander. Each of these racial categories represents not only a demographic group, but also an amalgamation of historical, social, and cultural contexts which then influence how an individual navigates and forms their racial identity. Here, I will discuss which groups fall under which racial categories in the US, why Hispanics/Latinos and Arabs (MENA people) aren’t a race and the relationship between the self and racial identity.
Race in the US
The Census Bureau defers to the Office of Management and Budget (OMB) on matters of race. In 1997, the OMB separated Asians and Pacific Islanders and changed the term “Hispanic” to “Hispanic or Latino” (OMB, 1997). But in this discussion, they stated that there are 5 races: white, black, Native American, East Asian and Pacific Islander. The US Census Bureau has to defer to the OMB, and the OMB defines race as a socio-political category. Below are the 5 minimum reporting categories (races) as designated by the OMB.
White – A person having origins in any of the original peoples of Europe, the Middle East, or North Africa.
Black or African American – A person having origins in any of the Black racial groups of Africa.
American Indian or Alaska Native – A person having origins in any of the original peoples of North and South America (including Central America) and who maintains tribal affiliation or community attachment.
Asian – A person having origins in any of the original peoples of the Far East, Southeast Asia, or the Indian subcontinent including, for example, Cambodia, China, India, Japan, Korea, Malaysia, Pakistan, the Philippine Islands, Thailand, and Vietnam.
Native Hawaiian or Other Pacific Islander – A person having origins in any of the original peoples of Hawaii, Guam, Samoa, or other Pacific Islands. (About the Topic of Race)
Race in America is based on self-identification, and the OMB allows one to put that they are of one or more racial groups. They also allow write ins of “Some Other Race”, which I will get to below. For now, I will elaborate on each racial category, and begin with the—controversial to white nationalists—definition of “white” that designates MENA people as white.
White racial designation—I showed the 5 minimum reporting categories (racial groups) above, and there has been discussion of adding a MENA minimum reporting category per the Federal Register. Such a move would be because they don’t identify as white, they aren’t perceived as white (Maghbouleh, Schachter, Flores, 2022) and and don’t have the same lived experiences as white Europeans. But we know that in OMB racetalk, white isn’t a narrow group that refers only to Europeans, it’s a broad group that refers to the ME/NA (yes, even Ashkenazi Jews). For instance, in the 2000 Census, 80 percent of Arabs self-identified as only white (de la Cruz and Brittingham, 2003). Obviously, Arabs intend to use the white category in the same ah that the OMB uses it. Even then, we know that the aftermath of 9/11 hasn’t changed the self-reported race of around 63 percent of Arab Americans (Spencer, 2019). Further, know that those who feel that the term “Arab American” doesn’t describe them are more likely to identify as white and that some Arab Americans both report strong ethnic ties, identify as white, and reject the Arab American label (Ajrouch and Jamal, 2007). They aren’t afforded minority status in the US even though they account for 2 to 6 percent of the US population, and this is because of their designation as white. This isn’t to deny, though, the fact that they do experience discrimination and that they do have health inequalities (see Abboud, Chebli, and Rabelais, 2019), I just don’t think that they comprise a racial group, and at best they are an ethnicity in the overall white race—the fact that Arab Americans are discriminated against doesn’t justify their being a separate racial category (Jews, the Irish and Italians were also discriminated against upon arrival to the US but they were always politically and socially white; Yang and Koshy, 2016.) Arab Americans (and all MENA people) are simply like Italians, Irish British, Jews, and Poles in America—there is no need for an Arab/MENA racial category; the fact that they’re discriminated against and have differences in health from whites is irrelevant, because you can find both of these things in other ethnic groups labeled as white yet they don’t deserve a special racial status.
Of course, the term white in America also refers to people of European origin like Italians, Germans, Russians, Fins, and others and this designation has stayed relatively the same. Thus, the white race in American racetalk is designated for European and MENA people. (This would also hold for some “Hispanics/Latinos, see below.)
Black or African American racial designation—This category refers to black Americans (“African American”, AfAm “Foundational Black Americans” FBA, or “American Descendants of Slavery”, ADOS). For instance, the overlap between US race terms in the OMB and Blumenbacian racial designations is 1.0 for black or African (Spencer, 2014). Spencer (2019) noted one problem with the OMB’s definition of black or African American—that it would designate all people as black or African American since it says “A person having origins in any of the black racial groups of Africa.” But this can be avoided if we say they the way the OMB uses the term race is just it’s referent—it’s a set of categories or population groups (Spencer, 2014). So this racial designation just means any individual who can trace their ancestry back to Africa—which would comprise, say, Cubans/Puerto Ricans/Dominicans and other “Hispanics/Latinos” with African ancestry, black Americans, and immigrants from Africa who have sub-Saharan African ancestry.
American Indian or Alaskan Native racial designation—About 5.2 million people in America identify using this category (Nora, Vines, and Hoeffel, 2012). (This fell to 3.7 million in 2020.) This designation captures not only American Indians, but people who have Native ancestry from Central and South America, like the Maya, Aztec, Inca (which is referred to as “Latin American Indian”) and others. This also includes Alaskan Natives such as Yup’ik, Inuit, and other Natives such as Chippewa and Indians living on reservations. When it comes to American Indians, one must be able to prove their tribal affiliations, by showing that they or an ancestry had tribal affiliation, has an established “lineal ancestor“, or providing documentation that they have a relationship to a person using vital records.
Asian racial designation—This encompasses the far East, the Indian subcontinent and South East Asia. Before 1997, Asians and Pacific Islanders (PIs) were grouped together. For instance, in 1977 the OMB had 4 racial classifications since Asians and PIs were grouped together (and they still noted “Hispanics” as an ethnicity, with the option to identify as Hispanic or non-Hispanic). Thus, if one has ancestry to East Asia, South East Asia and the Indian subcontinent, they are therefore Asian.
Native Hawaiian or other Pacific Islander racial designation—As noted above, this group was split off from a broader “Asian or Pacific Islander” category. This designation refers to people Native Hawaiians and Oceanians. We know that the overlap between “Pacific Islander” and “Oceanian” is 1.0 (Spencer, 2014). Australian Aboriginals also fall under this category. Along with designating Native Hawaiians and Australian Aboriginals in this category, it also refers to people from other Pacific islands Samoa and other Pacific Islands like Melanesia, Guam, and Papua New Guinea (OMB, 1997). So the breaking up of the “Asian and or Pacific Islander” category is valid.
The question of “Latinos/Hispanics”—Back in August of 2020, I argued that “Latinos/Hispanics” were a group I called “HLS” or “Hispanics/Latinos/Spanish” people (OMB notes that these terms are and can be used interchangeably). This is because, at least where I grew up, people referred to Spanish speakers as one homogenous group, irregardless of their phenotype. So they would group together say Puerto Ricans and Salvadorians with Argentineans, Chileans and Cubans. However, these countries have radically different racial admixtures and culture based on what occurred there after 1492. But the issue is this—HLS isn’t a racial group. To me, it’s a socio-linguistic cultural group, since they share a language and some cultural customs. The category “Latin American is a social designation. But the thing is, the OMB rightly notes that” Hispanics or Latinos “are not a racial group, they are an ethnic group. In 1997 the OMB changed “Hispanic”to “Hispanic or Latino.” The OMB stated that the definition should be unchanged, but that the “Latino” qualifier should also be added. This category would comprise Cubans, Puerto Ricans, Mexicans, Central and South Americans and other Spanish culture or origins REGARDLESS OF RACE. Indeed the Census (who defer to the OMB) is quite clear: “Hispanics and Latinos may be of any race…People who identify their origin as Hispanic, Latino, or Spanish may be of any race.” Further, as noted above, the category “American Indian or Alaskan Native” also encompasses Latin American Indians (which some think of when they think of “Latinos or Hispanics”).
Furthermore, Spencer (2019: 98) notes that “Conducting a linear regression analysis shows that the average Caucasian ancestry of a Hispanic American national origin group positively and highly correlates (r=+0.864) with the proportion of that group that self-reported ‘White’ alone on the 2010 US Census questionnaire. Quite clearly, “white Hispanics” exist, and this is because as noted by the OMB, Hispanics aren’t a racial group. Forty percent of Central Americans identified as “some other race”, while 85 percent of Cubans, 53 percent of Puerto Ricans, and 35 percent of Dominicans identified as white in 2010; both Puerto Ricans and Dominicans were also more likely to identify as black or report multiple races (Ennis, Rios-Vargas, and Albert, 2011). HLS is clearly not a homogeneous group.
Therefore, phrases like “white Hispanic”, “Afro Latino/a” aren’t a contradiction of terms.
Throughout this discussion, I have shown that there is a relationship between racial identity and one’s self-identification. We also know—consistent with the TAAO—that moderate racial and ethnic identification for blacks and Asians acts as a buffer for racial discrimination while for whites, American Indians and Latinos it exacerbates it (Woo et al, 2019).
One final consideration leaves me with clustering studies. When K is set to 5, there are 5 clusters (Rosenberg et al, 2002). These are what Spencer calls human continental populations or Blumenbacian partitions. These clusters correspond to whites, blacks, Asians, Native Americans and Pacific Islanders. But “Hispanics”, being a recent amalgamation of admixed groups clustered in between other clusters and didn’t form their own cluster (Risch et al, 2002). Defenses of this study to show the biological reality of race can be found in Spencer (2014, 2019) and Hardimon (2017).
Conclusion
I have discussed what race means in the American context (it’s version of racetalk), it’s definition as defined by the OMB, and changes to the categories over the years. I don’t think they MENA people should be a separate racial category, since many of them identify as white, and although some do identify as Arab American and some are discriminated against, this isn’t relevant for their status as a racial category since Jews, the Irish and Italians were discriminated against upon their arrival to America and they also have a qualifier as well; this category also refers to European descendants. Black and African Americans refer to people with ancestry to Africa, so this could encompass many people like American blacks, certain Brazilians, Dominicans, and Puerto Ricans.
Native American or Alaskan Native refers to not only North American Indians and people native to Alaska but also Latin American Indians (Maya, Pima and others). Asian and Pacific Islanders were split in 1997, since before then (in 1977) there were only 4 racial groups per the OMB. The Asian category refers to South East Asia, East Asia and the Indian subcontinent. The Native Hawaiian or other Pacific Islander category refers to people native to Hawaii along with other Pacific Islands like Guam, Samoa and Papua New Guinea. Lastly, HLSs are not a racial designation and can be of any race. I showed that while many Caribbean Hispanics identify with different racial groups, they don’t themselves designate a separate racial group from their self-identification. Hispanics or Latinos can be of any race (like for example the former president of Peru Alberto Fujimori who had Japanese ancestry but was born in Peru, he’d be Hispanic as well, but his race is Asian).
I then showed that there are defenses of what is termed “cluster realism” (Kaplan and Winther, 2009), and that Hispanics aren’t in these clusters. This is a stark difference from hereditarians like Charles Murray who merely assume that race exists without an argument.
Therefore, since racial pluralism is true, there are a plurality of race concepts that hold across time and place (like with how race is defined in Brazil and South Africa). But for the context of this discussion, in America, race is a social construct of a biological reality and there are 5 racial groups and all theories of race are based off of the premise that race is a social construct. Spencer’s racial identity argument is true.
HBD and (the Lack of) Novel Predictions
2250 words
a predicted fact is a novel fact for a theory if it was not used to construct that theory — where a fact is used to construct a theory if it figures in the premises from which that theory was deduced. (Musgrave, 1988; cf Mayo, 1991: 524)
Introduction
Previously I demonstrated that the HBD movement is a racist movement. I showed this by arguing that it perfectly tracks with John Lovchik’s definition of racism, which is where “racism is a system of ranking human beings for the purpose of gaining and justifying an unequal distribution of political and economic power.” There is, however, a different issue—an issue that comes from the philosophy of science. So a theory is scientific if and only if it is based on empirical evidence, subject to falsifiability and testability, open to modification or rejection based on further experimentation or observation and—perhaps most importantly—is capable of generating novel predictions, where a novel prediction goes beyond existing knowledge and expectation and can be verified through empirical testing.
Here I will show that HBD doesn’t make any novel predictions, and I will also discuss one old attempt at showing that it does and that it is an example of a degenerative research programme. Effectively, I will argue that contrary to what is claimed, HBD is a degenerating research programme.
On so-called novel predictions
HBD and evolutionary psychology falls prey to the same issues that invalidate both of them. They both rely on ad hoc and post hoc storytelling. In a previous article on novel predictions, I stated:
A risky, novel prediction refers to a prediction made by a scientific theory or hypothesis that goes beyond what is expected or already known within an existing framework (novelness). It involves making a specific claim about a future observation or empirical result that, if confirmed, would provide considerable evidence in support of the scientific theory or hypothesis.
So EP and HBD are cut from the same cloth. John Beerbower (2016) puts the issue succinctly:
At this point, it seems appropriate to address explicitly one debate in the philosophy of science—that is, whether science can, or should try to, do more than predict consequences. One view that held considerable influence during the first half of the twentieth century is called the predictivist thesis: that the purpose of science is to enable accurate predictions and that, in fact, science cannot actually achieve more than that. The test of an explanatory theory, therefore, is its success at prediction, at forecasting. This view need not be limited to actual predictions of future, yet to happen events; it can accommodate theories that are able to generate results that have already been observed or, if not observed, have already occurred. Of course, in such cases, care must be taken that the theory has not simply been retrofitted to the observations that have already been made—it must have some reach beyond the data used to construct the theory.
HBDers promote the tenets that intelligence (IQ), along with behavior and socioeconomic outcomes are strongly associated with genetic differences among individuals and groups. They also use the cold winter theory (CWT) to try to intersect these tenets and show how they evolved over time. According to the CWT, the challenges of surviving in colder climates such as the need to hunt, plan ahead, and cooperate exerted selective pressures which favored genes which fostered higher intelligence in populations that inhabited these regions. I have previously shown years back that the CWT lacks novel predictive power, and that there are devastating response to the CWT which show the invalidity of the theory. Rushton used it in his long-refuted r/K selection theory for human races. Further, for example Jablonski and Chaplin (2000) successfully predicted that “multiple convergences of light skin evolved in different modern human populations and separately in Neanderthals” (Chaplin and Jablonski, 2009: 457). This was a successfully predicted novel fact, something that HBD doesn’t do.
Urbach (1974) (see Deakin, 1976 for response) in criticizing “environmentalism” and contrasting it with “hereditarianism”, claimed that hereditarianism made novel predictions. He also claimed that the “hard core” of the hereditarian research programme was that (1) cognitive ability of all people is due to general intelligence and individual and (2) group differences are due to heredity. We know that (1) is false, since general intelligence is a myth and we know that (2) is false since group differences are due to environmental factors since Jensen’s default hypothesis is false (along with the fact that Asians are a selected population). Further Urbach (1974: 134-135) writes that 4 novel facts of hereditarianism are “(i) of the degree of family resemblances in IQ, (ii) of IQ-related social mobility, (iii) of the distribution of IQ’s, and (iv) of the differences in sibling regression for American Negroes and whites.”
But the above aren’t novel predictions.
(i) Hereditarianism predicts that intelligence has a significant hereditary component, leading to similarities in IQ scores among family members. (Nevermind the fact that environments are inherited by these family members as well.) The prediction appears specific, but it’s not novel in the framework of hereditarianism. The idea that IQ is heritable and that family members share similarities in IQ has been a main tenet of hereditarianism for decades, even in 1974 at the time of publication of Urbach’s paper,rather than offering a new or unexpected insight.
(ii) Hereditarianism also suggests that differences in IQ also have implications for social mobility, with people with higher IQs having a greater change for more upward social mobility. This, too, isn’t novel within the hereditarian framework since even in 1974 and the decades before then this was known.
(iii) Hereditarianism also predicts that IQ scores follow a normal distribution, with a majority of people clustering around the middle. This, too, isn’t a novel prediction, since even Binet unconsciously built his test to have a normal distribution (Nash, 1987: 71). (Also note that Binet knew that his scales weren’t measures but thought that for practical measures they were; Michell, 2012.) Terman constructed his test to also have it. Urbach (1974: 131) states that “even if researchers had set out to obtain a particular distribution of IQ’s, there was no divine guarantee that their efforts would have been successful.” But we know that the process of building a normal distribution is done by choosing only items that conform to the normal distribution are selected, since items most are likely to get right are kept while on both ends items are also kept. In their psychometrics textbook, Rusk and Golombok (2009: 85) state that “it is common practice to carry out item analysis in such a way that only items that contribute to normality are selected.” Jensen (1980: 71) even stated “It is claimed that the psychometrist can make up a test that will yield any kind of score distribution he pleases. This is roughly true, but some types of distributions are much easier to obtain than others.”
(iv) Lastly, hereditarianism predicts that differences in sibling regression or the extent to which sibling IQ scores deviate from the population mean could vary between racial and ethnic groups. The prediction seems specific, but it reflects assumptions of genetic influences on psychological trait—which already were assumptions of hereditarian thought at that time and even today. Thus, it’s not a new or unexpected insight.
Therefore, the so-called novel predictions referenced by Urbach are anything but and reflect existing assumptions and concepts in the field at the time of publication, or he’s outright wrong (as is the case with the normal distribution).
Modern day hereditarians may claim that the correlation between genetics and IQ/educational attainment validates their theories and therefore counts as novel. However, the claim that genes would correlate with IQ has been a central tenet in this field for literally 100 years. Thus, a prediction that there would be a relationship between genes and IQ isn’t new. Nevermind the fact that correlations are spurious and meaningless (Richardson, 2017; Richardson and Jones, 2019) along with the missing heritability problem. Also note that as sample size increase, so to does the chance for spurious correlations, (Calude and Longo, 2016). The hereditarian may also claim that predicting group differences in IQ based on genetic and environmental factors is a novel prediction. Yet again, the idea that these contribute to IQ has been known for decades. The general prediction isn’t novel at all.
So quite obviously, using the above definition of “novel fact” from Musgrave, HBD doesn’t make any novel predictions of previously unknown facts not used in the construction of the theory. The same, then, would hold true for an HBDer who may say something along the lines of “I predict that a West African descendant will win the 100m dash at the next Olympics.” This doesn’t qualify as a novel prediction of a novel fact, either. This is because it relies on existing knowledge related to athletics and racial/ethnic demographics. It’s based in historical data and trends of West African descendants having been successful at previous 100m dash events at the Olympics. Therefore, since it’s not a novel insight that goes beyond the bounds of the theory, it doesn’t qualify as “novel” for the theory.
Why novel predictions matter
Science thrives on progress, so without theories/hypotheses that make novel predictions, a scientific program would stagnate. The inability of hereditarianism to generate risky, novel predictions severely limits it’s ability in explaining human behavior. Novel predictions also provide opportunities for empirical testing, so without novel predictions, hereditarianism lacks the opportunity for rigorous empirical testing. But a proponent could say that whether or not the predictions are novel, there are still predictions that come to pass based on hereditarian ideas.
Without novel prediction, hereditarianism is confined to testing hypotheses that are well-known or widely accepted in the framework or the field itself. This then results in a narrow focus, where researchers merely confirm their pre-existing beliefs instead of challenging them. Further, constantly testing beliefs that aren’t novel leads to confirmation bias where researchers selectively seek out what agrees with them while ignoring what doesn’t (Rushton was guilty of this with his r/K selection theory). Without the generation of novel predictions, hereditarianism lacks innovation. Lastly, the non-existence of novel predictions raises questions about the progressiveness of the framework. True scientific progress is predicated on the formulation of testing novel hypotheses which challenge existing paradigms. Merely claiming that a field generates testable and successful novel predictions and therefore that field is a progressive one is unfounded.
Thus, all hereditarianism does is accommodate, there is no true novel predictive power from it. So instead of generating risky, novel predictions that could potentially falsity the framework, hereditarians merely resort to post-hoc explanations, better known as just-so stories to fit their preconceived notions about human behavior and diversity. HBD claims are also vague and lack the detail needed for rigorous testing—the neck isn’t stuck out far enough for where if the prediction fails that the framework would be refuted. That’s because the predictions are based on assumptions they already know. Thus, HBD is merely narrative construction, and we can construct narratives about any kind of trait we observe today have the story conform with the fact that the trait still exists today. Therefore hereditarianism is in the same bad way as evolutionary psychology.
I have previously compared and contrasted hereditarian explanations of crime with the Unnever-Gabbidon theory of African American offending (TAAO) (Unnever and Gabbidon, 2011). I showed how hereditarian explanations of crime not only fail, but that hereditarian explanations lack novel predictive power. On the other hand, Unnever and Gabbidon explicitly state hypotheses and predictions which would follow from. The TAAO, and when they were tested they were found to hold validating the TAAO.
Conclusion
In this discussion I have tried to show that hereditarian/HBD theories make no novel predictions. They are merely narrative construction. The proposed evolutionary explanation for racial differences in IQ relying on the CWT is ad hoc, meaning it’s a just-so story. Lynn even had to add in something about population size and mutation rates since Arctic people, who have the biggest brain size, don’t have the highest IQ which is nothing more than special pleading.
Urbach’s (1974) four so-called novel predictions of hereditarianism are anything but, since they are based on assumptions already held by hereditarianism. They represent extensions or reformulation of existing assumptions, while also relying on retrospective storytelling.
I have provided a theory (the TAAO) which does make novel predictions. If the predictions wouldn’t have held, then the theory would have been falsified. However, tests of the theory found that they hold (Burt, Simons, and Gibbons, 2013; Unnever, 2014; Unnever, Cullen, and Barnes, 2016; Herda, 2016, 2018; Burt, Lei, and Simons, 2017; Gaston and Doherty, 2018; Scott and Seal, 2019). The hereditarian dream of having the predictive and explanatory power that the TAAO does quite obviously fails.
Therefore, the failure of hereditarianism to produce successful, risky novel predictions should rightly raise concerns about its scientific validity and the scientific credibility of the program. So the only rational view is to reject hereditarianism as a scientific enterprise, since it doesn’t make novel predictions and it’s merely, quite obviously, a way to make prejudices scientific. Clearly, based on what a novel prediction of a novel fact entails, HBD/hereditarian theory doesn’t make any such predictions of novel facts.
Strengthening My Argument that Black Americans Deserve Reparations
2350 words
Introduction
In February of last year I constructed an argument that argued since the US government has a history of giving reparations to people who have suffered injustices brought about by the US government (like the Japanese, Natives and victims of sterilization), and since black Americans have suffered injustices brought about by the US government (slavery, Jim Crow, segregation), then it follows that black Americans deserve reparations. But while discussing the argument on Twitter, someone pointed out to me that I can’t derive an ought from an is—which is known as the naturalistic fallacy. Though one can do so if they have an empirical premise and a normative premise which would guarantee a normative conclusion. The normative premise is implicit in the argument. Then, before we derive the conclusion that black Americans deserve reparations, we need a premise that justifies that a rectification of the historical injustices entails that reparations need to be given in order to rectify the historical injustices. I will give the revised argument below, then I will give the argument in formal notation, defend the premises, the validity and soundness of the argument, and show that black Americans indeed deserve reparations from the US government to right the historical wrongs that were inflicted upon them.
(P1) The US government has a history of giving reparations to people who have suffered injustices brought above by them (like the Japanese and Natives).
(P2) The US government has a moral obligation to rectify historical injustices.
(P3) Black Americans have historically suggested from slavery, Jim Crow laws, segregation (systemic along with individual discrimination).
(C) So black Americans deserve reparations from the US government.
Constructing the argument and defending the premises
Variables:
R: Black Americans deserve reparations.
J: Japanese Americans have recreational reparations.
N: Native Americans have received reparations.
O: The US government has a history of giving reparations to people who have suffered injustices.
M: The US government has a moral obligation to rectify historical injustices.
S: Black Americans have historically suffered from slavery, Jim Crow laws, and segregation.
So here’s the argument:
(P1) (J^N) -> O
(P2) M
(P3) S
(C) R
P1 asserts that if Japanese Americans and Native Americans have received reparations, then the US government has a history of giving reparations to people who have suffered injustices—specifically people who have suffered injustices brought about by the US government. This premise is based on historical evidence. Since they have received reparations, then the premise is true. P2 asserts that the US government has a moral obligation to rectify historical injustices. Many believe that the US government has a moral obligation to rectify historical injustices and past harms, and since we have the historical precedence of past harms being rectified by the US government, then there is an argument to be made that black Americans deserve reparations from the US government. P3 asserts that black Americans have suffered injustices brought about by the US government like slavery, Jim Crow, and segregation (which is a combination of individual and systemic racism). Like P1, this premise, too, is supported by historical evidence. Thus, given that the premises are true then the conclusion necessarily follows—black Americans deserve reparations from the US government.
“But wait RR, how is P2 true?” P1 states that J and N have received reparations, so the US government has a history of giving reparations to people it has wronged in the past. There is obviously a moral precedent embedded in P1: If a group of people have suffered injustices, and the US government has provided them reparations, then there is a historical precedent or acknowledgment that rectifying past wrongs is a legitimate action. So P2 builds on this moral principle—it posits that the US government has a moral obligation to rectify historical injustices, and that the obligation arises from the recognition that historical injustices have occurred while having been redressed through reparations for other groups which was indicated in P1.
It can also be put like this: X1 and X2 received reparations because they were wronged. Y was wronged. So Y deserves reparations. Y experienced similar to worse injustices. So due to the precedent set for X1 and X2, Y therefore deserves reparations. I can also further strengthen the argument with a sub-argument for P2 that goes like this:
(P1) If a group has been wronged by a governmental body, then there is a moral obligation for the government to rectify the harm caused.
(P2) If there is a moral obligation for the government to rectify the harm caused, then reparations are necessary to address the wrong.
(C)Thus,if a group has been wronged by a governmental body, then reparations are necessary to rectify the harm caused.
“But wait RR, doesn’t the argument commit the naturalistic fallacy (the is-ought fallacy) since it derives a normative conclusion from empirical premises?” No, it doesn’t. As I argued recently in my article that crime is bad and racism causes crime so racism is morally wrong, if there is an empirical premise and a normative premise, one can derive a normative conclusion and that’s what I did. The argument doesn’t directly derive an ought from an is; it presents the moral premise (the US government has a moral obligation to rectify historical injustices) and factual premises (historical instances of reparations given to other groups and the historical suffering of black Americans), which then allows me to derive the normative conclusion. So the naturalistic fallacy occurs when someone attempts to derive a moral or normative conclusion solely from descriptive or factual premises without any moral premise to bridge the gap. So the moral premise (P2) serves as the bridge between the empirical premises which then allows me to infer the normative conclusion.
So each premise contributes to supporting the conclusion and the logical connections between them guarantee the validity of the argument. Further, not only is the argument valid but it is also sound since it has all true premises. Each premise is well-supported and grounded in historical and ethical considerations which then guarantees the conclusion that black Americans deserve reparations.
I can also put it like this:
(1) If Japanese and Native Americans received reparations, then the US government has a history of giving reparations to people who have suffered injustices.
(2) The US government has a moral obligation to rectify historical injustices.
(3) Since Japanese and Native Americans received reparations, it implies that the US government indeed gives reparations to those who have suffered injustices (conclusion from 1 and 2).
(4) Given that black Americans historically suffered from slavery, Jim Crow laws and segregation, they are included among people who have suffered injustices.
(5) Therefore, based on the established pattern of reparations given by the US government and the moral obligation to rectify historical injustices, black Americans deserve reparations (conclusion from 3 and 4).
For example, Howard-Hassmann (2022) states that “all political entities and all citizens should be willing to offer reparations for activities that would now be considered horrendous crimes, even if they occurred in the far distant past.” While Muhammad (2020: 124-125) states that “apologies are also necessary components of reconciliation, the reality is that monetary compensation is also of vital African nations which participated in the Trans-Atlantic Slave trade have similar legal obligations as European nation states to provide reparations.” I agree with both of these arguments, and they only strengthen my initial argument on reparations for black Americans due to slavery and the US government’s role in the Trade.
Therefore, due to these considerations, reparations are not only a matter of justice but also a response to the persistent legacy of historical racial discrimination in America along with the legacy of slavery. Although there are some arguments that the US should pay Africa reparations for the slave trade, while acknowledging that other groups like Africans themselves and Arabs also participated in the slave trade, (Howard-Hassmann, 2022) and that African nations should pay reparations to black Americans (Muhammad, 2020), it’s not relevant to my argument (although I do agree with both of these arguments) that the US government should pay reparations.
Post-traumatic slave syndrome and intergenerational effects of slavery and Jim Crow
The impact of slavery not only had effects on contemporary birth weights of African Americans (Jasienska, 2009; also see Jasienska’s 2013 book The Fragile Wisdom for an in depth discussion on slavery and it’s intergenerationally-transmitted effects). Furthermore, Jasienska (2013: 117) states that her hypothesis “is that too few generations have elapsed for African Americans living in improved energetic status to counteract the tragic multigenerational effects of nutritional deprivation.” Jasienska (2013: 116) explains:
African Americans suffered nutritional deprivation that lasted much longer, both within each generation and across generations. Even though their caloric intake was higher than that of women during the Dutch famine, slaves’ levels of energy expenditure were extreme. Hard work alone during pregnancy is capable of reducing an infant’s birth weight, regardless of the mother’s caloric intake. Multigenerational exposure to harsh energy-related conditions may change the maternal physiology’s assessment of the quality of environmental conditions. Even when the mother is well nourished herself, as an organism she receives an additional intergenerational signal. The signal may be integrated into her own maternal metabolic processes, and it may cause her organism to follow a specific physiological strategy. This strategy results in the reduced birth weight of her children.
There are a few possible causal physiological mechanisms which may have come into play here that have caused this. For example, epigenetic modifications due to exposure to adverse environmental conditions of slavery like their nutrient deprived environments, the stress they underwent, and the associated inflammatory responses could persist which then influences the intrauterine environment and feral development which ultimately affects birth weight. This then can be exacerbated by post-traumatic slave syndrome (PTSS).
Slavery also led to psychological harm like PTSS—it also makes predictions above violence and health (Halloran, 2018). So quite obviously, there is a body of evidence of the intergenerationally-transmitted effects of slavery and Jim Crow (see Krieger et al, 2013, 2014; Lee et al, 2023). Thus, quite obviously, there are effects of slavery and Jim Crow which have persisted across the generations and—for descendants of both these groups—reparations is a valid way to address these historical wrongs brought about by the US government. This combined with PTSS is yet more evidence that there are grievances which are the outcomes of slavery which led to inequitable outcomes in the modern day, and that reparations can—while not actually fixing the issues (which is up to public health)—can serve as a form of acknowledgement, redress, and restitution for the historical injustices experienced by black American slaves and their descendants.
Conclusion
I have restructured my argument that black Americans deserve reparations by adding a normative premise which bypasses a claim that the argument is guilty of the naturalistic fallacy. I then provided a sub-argument which justifies P2. The sub-argument breaks down the broader concept of moral obligation into specific premises, which makes the argument clearer and more comprehensive. So by explicitly outlining the logical steps in justifying and establishing moral obligation, the sub-argument strengthens the overall argument by addressing a specific objection while clarifying the underlying reasoning. It also highlights the logical connection between moral obligation and the necessity of reparations by showing that if there is a moral imperative to rectify historical injustices, then reparations become a necessary means to fulfill the obligation. This linkage, then, helps to solidify the conclusion that black Americans deserve reparations from the US government.
So the argument for reparations for black Americans rests on a solid foundation of empirical and moral principles. I’ve established that the historical precedent for other marginalized groups establishes a pattern of governmental acknowledgement and rectification of past wrongs. Therefore, this historical context—combined with the moral imperative for the US government to address past systemic injustices—shows the necessity of reparations as a means for redress. So by synthesizing ethical and empirical premises the argument transcends mere appeals for sentiment and political expediency. It represents a genuine recognition of historical injustices—which was shown in P1—and a commitment to address the historical wrongs—historical wrongs that quite clearly have had effects that we see today in America today like low birth weight of black American babies and the effects of PTSS.
Reparations is about the rectification of past wrongs like systemic discrimination against blacks along with attempting to right the wrongs of 400 years of slavery. While descendants of American slavery have inherited psychological, economic, and social burden of their ancestors slavery and oppression along with the injustices of what occurred after (segregation, Jim Crow), there are obviously 2 groups of individuals who deserve such restitution. One group who can trace their ancestry back to American chattel slavery and others who were victims of Jim Crow and segregation.
So providing reparations to black Americans isn’t only a matter of righting past wrongs, it is also a crucial step in addressing the deep-rooted historical injustices that still plague black Americans today. This would then right some wrongs on wealth accumulation as well. One Pew poll shows that 57 percent of black Americans report that their ancestors were enslaved. The Wikipedia article African Americans states that most African Americans are descendants of slavery. Obviously the argument isn’t just about people who self-identify as black Americans, since that implies immigrants would be valid recipients of reparations from the US government. But, if and only if one can show they are descendants of American chattel slavery, and if and only if one identifies as a black American should one be able to be considered for reparations.
So while reparations may not directly address all inequities that derive from slavery and Jim Crow, they can therefore symbolize a commitment to rectifying past wrongs. I have tried, with the renewed argument I made along with the reasoning for my premises, to show that there are indeed effects of slavery and Jim Crow that persist today. Therefore, if one can show they are descendants of either of these two groups then they deserve reparations.
Racism Disguised as Science: Why the HBD Movement is Racist
2600 words
Introduction
Over the last 10 years or so, claims from the human biodiversity (HBD) movement have been gaining more and more traction. Proponents of HBD may say something like “we’re not racists, we’re ‘Noticers'” (to use Steve Sailer terminology – more on him below). The thing is, the HBD movement is a racist movement for the following reasons: it promotes and justifies racial hierarchies, inequities, is justified by pseudoscience, and it’s historical connections to the eugenics movement which sought to use pseudoscientific theories of racial superiority to justify oppression and discrimination.
But ever since 1969, Arthur Jensen and others have tried to intellectualize such a position, the discussion around racism has moved on to things like not only overt examples of racism but to systemic inequities along with unconscious biases which perpetuate racial hierarchies. But despite a veneer of scientific objectivity, the underlying motivation appears to be that of upholding some groups as “better” and others “worse.” This is like when hereditarians like Rushton tried to argue in the 90s that they can’t be racist since they say Asians (who are a selected population) are better than whites who are better than blacks on trait X. We know that views on Asians have changed over the years, for example with the use of the term “Mongoloid idiot.” Nonetheless, it’s obvious that the HBD movement purports a racial hierarchy. Knowing this, I will show how HBD is a racist movement.
Why HBD is racist
I have previously provided 6 definitions of racism. In that article I discussed how racism “gets into the body” and causes negative health outcomes for black women. I have since written more about why racism and stereotypes are bad since they cause the black-white crime gap through the perpetuation of self-fulfilling prophecies and they also cause psychological and physiological harm.
One of the definitions of “racism” I gave came from John Lovchik in his book Racism: Reality Built on a Myth (2018: 12), where he wrote that “racism is a system of ranking human beings for the purpose of gaining and justifying an unequal distribution of political and economic power.” Using this definition, it is clear that the HBD movement is a racist movement since it attempts to justify this ranking or human beings to justify and gain different kinds of power. This definition from Lovchik encompasses both systemic racism and overt acts of discrimination.
HBD proponents believe they we can delineate races not only based on physical appearance but also genetic differences. This is inherent in their system of ranking. But I think the same. Spencer’s (2014, 2021) OMB race theory (to which I hold to) states that race is a referent denoting a proper name to population groups. But that’s where the similarities end; OMB race theory is nothing like HBD. The key distinction between the two is in the interpretation of said differences. While both perspectives hold that population groups can be sorted into distinct groups, there is a divergence in their intentions and conclusions regarding the significance of said racial categorization.
Spencer’s OMB race theory emphasizes the declination of races based on physical differences as well as genetic ones using K=5 and how the OMB defines race in America—as a proper name for population groups. But Spencer (2014: 1036) explicitly states that his theory has no normative conclusion in it, since “the genetic evidence that supports the theory comes from noncoding DNA sequences. Thus, if individuals wish to make claims about one race being superior to another in some respect, they will have to look elsewhere for that evidence.” So the theory focuses solely on genetic ancestry without any normative judgements or hierarchical ranking of the races.
Conversely, the HBD movement, despite also genetically delineating races, differs in the application and interpretation of the evidence. Unlike Spencer’s OMB race theory, HBD states that genetic differences between groups contribute to differences in intelligence, social outcomes and behavior. HBD proponents use genetic analyses like GWAS to show that a trait has some kind of genetic influence and that, since there is a phenotypic difference in the trait between certain racial groups that it then follows that there is a genetic difference between certain racial groups when it comes to the phenotypic trait in question.
So this distinction that I have outlined shows the principle ways in which OMB race theory is nothing like HBD theory. So while both ideas involve genetic delineation of races, Spencer’s doesn’t support racist ideologies or hierarchical rankings among the races while the HBD movement does. Thus, the distinction shows the relationship between genetic analysis, racism and racial categorization is nuanced and that, just because one believes that human races exist, it doesn’t necessarily follow that they are a racist.
Furthermore, the attribution of social outcomes/inequality to biological/genetic differences is yet another reason why HBD is racist. They argue that most differences (read: outcomes/inequalities) between groups can come down mostly to genes, still leaving room for an environmental component. (This is also one of Bailey’s 1997 hereditarian fallacies.) It is this claim that socially-valued differences between groups are genetic in nature which then leads to systemic discrimination. So by attributing differences in outcome and resources, to biological differences, HBD attempts to perpetuate and legitimate systemic discrimination against certain racial groups. “It’s in their genes, nothing can be done.” Therefore, by ranking humans based on race and attributing differences in outcomes between groups—in part—to biological differences, the HBD movement justifies and perpetuates systemic discrimination against certain races, making HBD a racist movement.
Eugenic thinking arose in the late 1800s and began to be put into action in the 1900s. From sterilization to certain people deemed inferior, to advocating the enhancement of humanity through selective breeding of certain groups of people, some of the ideas from the eugenics movement are inherent in HBD-type thinking. The HBD movement then emerged as a more “respectable” iteration of the eugenics movement and they draw on similar themes. But why does this connection matter? It matters since the historical connection between the two shows how such pernicious thinking can penetrate social thought.
Lastly the HBD movement relies on pseudoscience. They often distort or misrepresent scientific findings. Most obvious is J. P. Rushton. In his discussion of Gould’s (1978) reanalysis of Morton’s skull collection, Rushton miscited Gould’s results in a way that jived with Rushton’s racial hierarchies (Cain and Vanderwolf, 1990). Rushton also misrepresented the skull data from Beals et al (1984). Rushton is the perfect example of this, since he misrepresented and ignored a ton of contrary data so that his theory could be more important. Rushton’s cherry-picking, misrepresentation of data, and ignoring contrary evidence while not responding to devestating critiques (Anderson, 1991; Graves 2002a, b) show this perfectly. This is the perfect example of confirmation bias.
They also rely on simplistic and reductionist interpretation of genetic research. By doing this, they also perpetuate stereotypes which can then have real-world consequences, like people committing horrific mass murder (the Buffalo shooter made reference to such genetic studies, which is why science communication is so important).
In his 2020 book Human Diversity the infamous Charles Murray made a statement about inferiority and superiority in reference to classes, races, and sexes, writing:
To say that groups of people differ genetically in ways that bear on cognitive repertoires (as this book does) guarantees accusations that I am misusing science in the service of bigotry and oppression. Let me therefore state explicitly that I reject claims that groups of people, be they sexes or races or classes, can be ranked from superior to inferior. I reject claims that differences among groups have any relevance to human worth or dignity.
Seeing as Chuck is most famous for his book The Bell Curve, this passage needs to be taken in context. So although he claims to reject such claims of inferiority and superiority, his previous work has contributed to such notions, and thus, it is implicit in his work. Furthermore, the language he used in the passage also implies hierarchical distinctions. When he made reference to “groups of people [who] differ genetically in ways that bear on cognitive repertoires“, there is a subtle suggestion that groups may possess inherent advantages or disadvantages in cognitive ability, thusly implying a form of hierarchy.
Murray’s work has been used by alt-right and white nationalist groups, and we know that white nationalist groups use such information for their own gain (Panofsky, Dasgupta, and Iturriaga, 2020; Bird, Jackson, and Winston, 2023). Panofsky and his coauthors write that “the claims that genetics defines racial groups and makes them different, that IQ and cultural differences among racial groups are caused by genes, and that racial inequalities within and between nations are the inevitable outcome of long evolutionary processes are neither new nor supported by science (either old or new). They’re the basic, tired evergreens of ancient racist thought.“
Next we have Steve Sailer. He may claim that he is merely observing (or as he says “Noticing”) and discussing empirical data. So his focus on racial differences and how they are driven mainly by genetic differences aligns with Lovchik’s definition of racism, since it involves the ranking of races based on perceived genetic differences, in both IQ and crime. Therefore, by emphasizing these differences and their purported implications for socially-relevant traits and their so-called implications for social hierarchies, Sailer’s work can be seen as justifying social inequalities and therefore justifying systemic discrimination.
Lastly, we have Bo Winegard’s Aporia Magazine essay titled What is a racist? In the article he forwards 5 definitions (while giving a 10-point scale, I will bracket the score he gives each):
Flawed:
1: Somebody who believes that race is a real, biological phenomenon and that races are different from each other. [1/10]
2: Somebody who believes that some races have higher average socially desirable traits such as intelligence and self-control than others. [3/10]3: Somebody who treats members of one race differently from members of another race. [5/10]
Plausible:
4: Somebody who dislikes members of other races. [8/10]
5: Somebody who advocates for differential treatment under the law for different races. [10/10]
Note that the first 2 encompass what, for the purposes of this article, I call racist in the HBD parlance. Nonetheless, I have tried to sufficiently argue that those 2 do constitute racism and I think I have shown how. In the first, if it is used to justify and legitimate social hierarchies, it is indeed racist. For the second, if someone holds the belief that races differ on socially values traits and that it is genetically caused, then it could perpetuate racist stereotypes and the continuation of racist ideologies. The third and fourth constitute racial discrimination. These 2 could also be known as hearts and minds racism, which operate at the level of individual beliefs, attitudes, and behavior. But the fifth definition that Bo forwarded is the most interesting one, since it has certain implications.
About the fifth definition, Bo wrote that (my emphasis) “a racist is somebody who advocates for differential treatment under the law for different races, [it] is the most incontrovertible and therefore paradigmatic definition of racist that I can imagine.” This is interesting. If it is not able to be denied, disputed, and serves as a typical example of the referent of racism, then this has implications for the views of certain hereditarians and the people they ran with.
We know that Jensen ran with actual racists and that he lent his name to their cause. (Jackson, 2022; see also Jackson and Winston, 2020 for a discussion). We know that hereditarians, despite their protestations, ignore evolutionary theory (Roseman and Bird, 2023). Nonetheless, we know that there is no support for the hereditarian hypothesis (Bird, 2021). But the issue here is the fifth definition that Bo said isn’t indisputable.
In his 2020 article Research on group differences in intelligence: A defense of free inquiry, philosopher Nathan Cofnas noted that hereditarians call for a kind of “tailored training program“, which John Jackson took to be “a two-tiered education system.” Although Cofnas didn’t say it, he cited hereditarians who DID say it. Thus, he showed how they ARE racists. And Cofnas states that we can’t know what would happen if race differences in intelligence would be found to have a genetic basis. But I argued before that since the hereditarian hypothesis is false and if we believe it is true then it could—and has—caused harm, so we should thusly ban IQ tests. Nonetheless, Cofnas’ passage in his article can be seen as racist under Lovchik’s definition, since he advocates for tailored training programs, which could result in unequal distribution of resources and further entrench inequities based on genetic differences between groups in their so-called intelligence which hereditarians argue is partly genetic in nature.
Prominent hereditarians Shockley and Cattell said some overtly racist things, Cattell even creating a religion called “Beyondism” (Tucker, 2009). Shockley called for the voluntary sterilization of black women (Thorp, 2022) and proposed a sterilization plan to pay anyone with an IQ a sum of money to get sterilized. I have also further documented the eugenic thinking of IQists and criminologists. It seems that this field is and has been a hole for racists ever since it’s inception.
Conclusion
Throughout this discussion, I have argued that the HBD movement is a racist one. Most importantly, a lot of their research was bankrolled by the Nazi Pioneer Fund. So financial support from a racist organization is pivotal in this matter, since these researchers were doing work that would justify the conclusions of the racist Fund (see Tucker 1996, 2002). So since the Fund had a history of funding research into eugenics, and of promoting research which could—implicitly—be seen as justification for racial superiorityp and inferiority, and therefore attempting to justify existing inequities.
Relying on John Lovchik’s definition of racism, I’ve shown how the HBD movement is a racist movement since it seeks to justify existing inequalities between racial groups and since it is a system of ranking human beings. I’ve also shown that mere belief in the existence of race isn’t enough for one to be rightly called a racist, since theories of race like Spencer’s (2014) OMB race theory is nothing like HBD theory since it doesn’t rank the races, nor does it argue that the genetic differences between races are causal for the socially important differences that hereditarians discuss. Racism isn’t only about individual attitudes, but also about systemic structures and institutional practices which perpetuate racial hierarchies and inequities.
I showed how, despite his protestations, Murray believes that races, classes, and sexes can be ranked—which is a form of hierarchy. I also showed how Steve “The Noticer” Sailer is a racist. Both of these men’s views are racist. I then discussed Winegard’s definitions, showing that they are all good definitions of the term under discussion. I then turned to how Jensen ran with racist Nazis and how Cofnas cited researchers who called for tailored training programs.
That the HBD movement promotes the idea that differences in socially valued traits are genetic in nature through pseudoscientific theories along with the fact that it quite obviously is an attempt at justifying a human hierarchy of socially valued traits means that there is no question about it—the HBD movement is a racist movement.
(P1) If the HBD movement promotes and justifies racial hierarchies and inequities, then it is a racist movement.
(P2) The HBD movement promotes and justifies racial hierarchies and inequities.
(C) So the HBD movement is a racist movement.
Strategies for Achieving Racial Health Equity: An Argument for When Health Inequalities are Health Inequities
2100 words
Introduction
Health can be defined as “a relative state in which one is able to function well physically, mentally, socially, and spiritually to express the full range of one’s unique potentialities within the environment in which one lives” (Svalastog et al, 2017). Health, clearly, is a multi-dimensional concept (Barr, 2014). Since there are many kinds of referents to the word “health”, it is therefore essential to understand and consider the context and perspective of each person and group when discussing health-related issues and also while implementing healthcare policies and practices.
Inequality exists everywhere on earth and it manifests in numerous forms like in income, health, education, and healthcare access. So the existence of inequality is undeniable, since we can see it with our own eyes, but understanding the mechanisms that lead to inequality should be multifaceted. Central to the understanding of inequality is the relationship between inequality, unfairness and the role of empirical investigations in uncovering not only the implications for societal outcomes, but also in discerning what is an inequity (which is a kind of inequality that is avoidable, unfair and unjust). According to Braveman, (2003: 182):
Health inequities are disparities in health or its social determinants that favour the social groups that were already more advantaged. Inequity does not refer generically to just any inequalities between any population groups, but very specifically to disparities between groups of people categorized a priori according to some important features of their underlying social position.
Talking about health is the best way to understand what inequity actually is. The issue is, true equality of health is impossible, but what is possible is addressing the actual social determinants of health (SDoH). What is also important is understanding what equity is and what equity isn’t, as I have argued in the past. Grifters like James Lindsay and Chris Rufo (along with well-meaning but still wrong institutions) believe that equity is ensuring equal outcomes. This is incorrect. What equity means—in the health sphere—is when “the opportunity to ‘attain their full health potential’ and no one is ‘disadvantaged from achieving this potential because of their social position or other socially determined circumstance’” (Braveman, quoted by the CDC).Therefore, health equity is when everyone has the chance to reach their fill potential, unabated by social determinants. Social conditions and policies strongly influence the health of both individuals and groups and it’s the result of unequal distribution of resources and opportunities. Empirical investigation is pivotal in understanding if a certain inequality is an inequity. And although inequities are a kind of inequality, “inequality” and “inequity” are conceptually distinct (Braveman, 2003).
In this article I will discuss the SDoH, give my argument that we can identify inequity (a kind of inequality) through empirical investigations (meaning that they are avoidable, unfair and unjust). I will then pivot to a real-world example of my argument—that of low birth weight in black American newborns and argue that racism and historical injustices can explain that since non-American black women have children with higher mean birth weights. I will then discuss how blacks who have doctors of of the same race report better care and have higher life expectancies. I will then discuss what can be done about this—and the answer is to educate people on genetic essentialism which leads to racism and racist attitudes.
On SDoH
SDoH include the lack of education, racism, lack of access to health care and poverty. Barr (2011: 64) had a helpful flow chart to understand this issue.
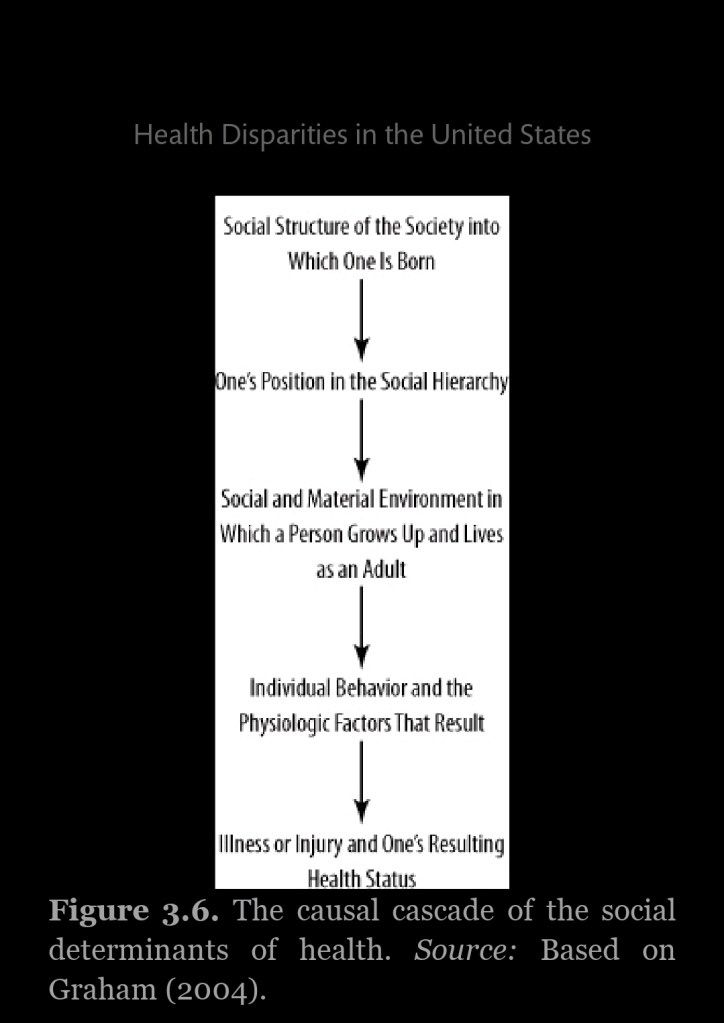
So when it comes to variation in health outcomes, we know that only 20 percent can be attributed to access to medical care, while a whooping 80 percent is attributable to the SDoH:
(Ratcliffe, 2017 also states that about 20 percent of the health of nation is attributed to medical care, 5 percent the result of biology and genes, 20 percent the result of individual action, and 50 percent due to the SDoH.)
The WHO (2010) also has a Commission on the Social Determinants of Health (CSDH) with a conceptual framework:
This is staggering. For if the social determinants of health are causal for health outcomes, then it comes down to how society is structured along with how we treat certain people and groups. This also could come down to environmental racism—which is the disproportionate exposure of minority groups to environmental hazards. One pertinent example is lead in paint uses in houses in the 80s, where groups actually used blacks as a kind of experiment in seeing the effects of lead. The issue was further exacerbated by Big Lead in trying to argue that the families had a “history of low intelligence” and that it couldn’t be proven that lead had the damaging effects on the children. Not only does environmental racism cause negative health effects, but so does individual racism which is known to have a negative effect on black women. (Racism and stereotypes which lead to self-fulfilling prophecies also cause the black-white crime gap.)
So empirical research—grounded in data and evidence—can help us in understanding whether a given inequality is an inequity. Certain disparities could reflect historical disadvantages which then perpetuate cycles of disadvantage which then reinforce existing power structures and further continue to marginalize certain communities.
The argument
I have constructed an argument that shows what I am talking about:
UO: Unequal outcome
I: Inequality
A: Avoidable
F: Unfair
J: Unjust
E: Empirical investigation
I involves A, F, J. E may reveal instances where I leads to UO and I is associated with F, J, and A.
Premise 1: E -> (A^F^J)
Premise 2: I -> (A^F^J)
Conclusion: E -> ((I -> UO) ^ (A^F^J))
(P1) If empirical investigations (E) reveal instances where avoidable factors (A), unfairness (F) and injustice (J) are present, and (P2) if inequality (I) leads to conditions involving avoidability (A), unfairness (F) and injustice (J), then (Conclusion) empirical investigations (E) could reveal instances where inequality leads to unequal outcomes (UO), and whether or not they are avoidable (A), unfair (F) or unjust (J). Effectively, since inequities are a kind of inequality, then this can identify inequities where they are, and then we can work to fix them.
For instance, birth weight has decreased recently and the effect is more pronounced for black women (Catov et al, 2016) and racism could as well be a culprit (Collins Jr., et al, 2004). There is also evidence that structural racism in the workplace can and has attributed to this (Chantarat et al, 2022). It’s quite clear that racism can explain birth outcome disparities (Dominguez et al, 2010; Alhusen et al, 2016; Dreyer, 2021). Not only does racism contribute to adverse birth outcomes but so too do factors related to environmental racism (Burris and Hacker, 2018). This also has a historical precedent: slavery (Jasienska, 2009). Hereditarians may try to argue that (as always) this difference has a genetic basis. But we know that African women born in Africa are heavier than African American women; black women born in Africa have children with higher mean birth weights than African American women (David and Collins, 1997). Cabral et al (1991) also found the same—non-American black women birthed children that weighed 135 more grams than American black women. Thus, the difference isn’t genetic in nature—it is environmentally caused and it partly stems from slavery. Clearly this discussion shows that my argument has a real-world basis.
How do we reverse these inequities?
Clearly, racism has societal consequences not only for crime and mental illness, but also low birth weight in black American women. The difference can’t be genetic in nature, so it’s obviously environmental/social in nature due to racism, environmental racism. So how can we alleviate this? There are a few ways.
We can improve access to pre-natal care. By ensuring equitable access to pre-natal care, and by expanding Medicaid coverage, we can the begin to address the issue of low black birth weight. We know that when black newborns are cared for by black doctors, they have a better survival rate (Greenwood et al, 2020). We also have an RCT showing that black doctors could reduce the black-white cardiovascular mortality rate by 19 percent (Alsan, Garrick, and Grasiani, 2019). We also know that a higher percentage of black doctors leads to lower mortality rate and better life expectancy (Peek, 2023; Snyder et al, 2023). This isn’t a new finding—we’ve known this since the 90s (Komaramy et al, 1996; Saha et al, 1999). We also know that people who have same-race doctors are more likely to accept much-needed preventative care (LaVeist, Nuru-Jeter, and Jones, 2003). This could then lead to less systemic bias in healthcare, since we know that some of the difference is systemic in nature (Reschovsky and O’Malley 2008: 229, 230). We also know that bias, stereotyping, and prejudice also play a part (Smedley et al, 2003). Such stereotypes are also sometimes unconscious (Williams and Rucker, 2000). The medical system contributes to said disparities (Bird and Clinton, 2001). Blacks who perceived more racism in healthcare felt more comfortable with a black doctor (Chen et al, 2005)—minorities also trust the healthcare system less than whites (Boulware et al, 2003). Lastly, black and white doctors agree that race is a medically relevant data point, but they don’t agree on why (Bonham et al, 2009).
We know that systemic and structural racism exists and that it impacts health outcomes (Braveman et al, 2022). Some may say that systemic and structural racism don’t exist, but this claim is clearly false. They are “are forms of racism that are pervasively and deeply embedded in and throughout systems, laws, written or unwritten policies, entrenched practices, and established beliefs and attitudes that produce, condone, and perpetuate widespread unfair treatment of people of color. They reflect both ongoing and historical injustices” (Braveman et al, 2022). Perhaps the most important way that systemic racism can harm health is through placing people at an economic disadvantage and stress. Environmental racism then compounds this, and then unfair treatment then leads to higher levels of stress which then leads to negative health outcomes.
Lastly a key issue here is the prevalence of racism. We know that it has a slew of negative health effects and that it affects the incidence of the black-white crime gap. But what can be done to alleviate racist attitudes?
Since many racist ideas have a genetically essentialist tilt, then we can use education to ameliorate racist attitudes (Donovan, 2022). We also know that racial essentialist attitudes are related to the belief that evolution has an intentional tilt and that it’s negatively correlated with biology grades (Donovan, 2015). Much of Donovan’s work shows that education can ameliorate racist attitudes which are due to genetic essentialism. We also know that such essentialist thinking is related to misconceptions about heredity and evolution and is correlated with low grades at the end of the semester in beginner biology course (Donovan, 2016). Thus, by providing accurate and understandable education on race, genetics, and evolution, people may be less likely to hold racial essentialist attitudes and more likely to reject racist ideologies. So there are actionable things we can do to combat racism which leads to crime and negative health outcomes for minority groups.
Conclusion
The SDoH play a pivotal role in shaping the health outcomes while perpetuating health inequities. We can, through empirical investigations, ascertain when an inequality is avoidable, unfair and unjust (meaning, when it is an inequity). We can then understand how historical injustices like racism impact marginalized communities which then contribute to negative health outcomes like low birth weight of black American babies. We know that it’s not a genetic difference since non-American black women have children with higher mean birth weights than black American women, and this suggests thar historical injustices and racism are a cause (as Jasienska argues). Further, studies show that when black patients have black doctors, they report better care and have higher life expectancies. Research has also shown that education can play a role in ameliorating genetic essentialist and racist attitudes which then, as I’ve shown, lead to negative health outcomes. The argument I’ve made here has a real-world basis in the case of low birth weight of black American babies.
In sum, committing to social and racial justice can help to change these inequities, and for that, we will have a better and more inclusive society where people’s negative health outcomes aren’t caused by social goings-on. To achieve racial health equity, we must address the avoidable, unfair and unjust factors that contribute to these inequities.
